Learning Weakly Supervised Semantic Segmentation Through Cross-Supervision and Contrasting of Pixel-Level Pseudo-Labels
VISAPP 2025
Lucas David lucas.david@ic.unicamp.br
Helio Pedrini helio@ic.unicamp.br
Zanoni Dias zanoni@ic.unicamp.br
University of Campinas
Institute of Computing
Summary
- Introduction & Related Works
- Methodology
- Results
- Conclusion
¹ O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein and A.C. Berg. Imagenet Large Scale Visual Recognition Challenge.
In International Journal of Computer Vision, 115, pp.211-252, 2015.
Representation Learning Introduction
Representation Learning Introduction
¹ N. Burkart, and M.F. Huber. A survey on the explainability of supervised machine learning. In Journal of Artificial Intelligence Research, 70, pp.245-317., 73, pp.1-15. 2018.
² M. Tan, and Q. Le. EfficientNet: Rethinking model scaling for convolutional neural networks. In International conference on machine learning. PMLR. 2019.
Figure 2: Models of various architectures, pre-trained over ImageNet. Source: Tan and Le².
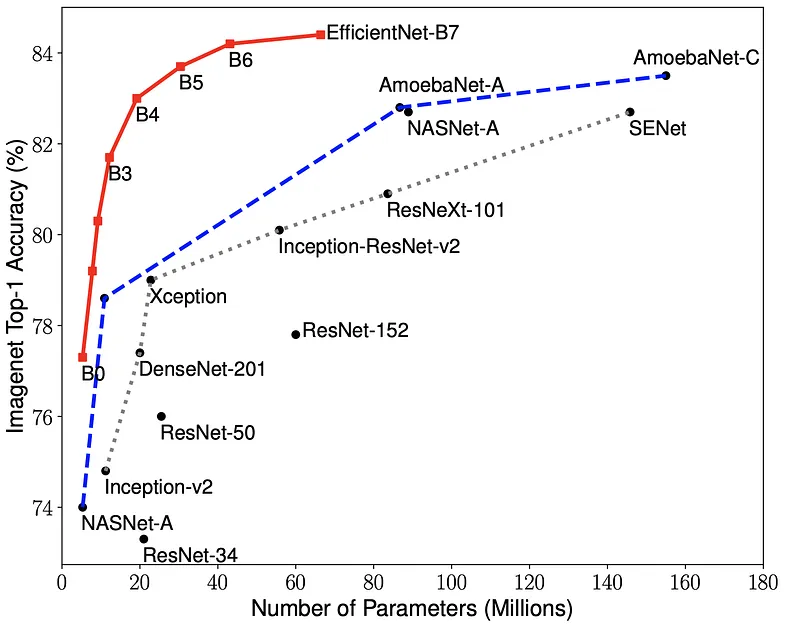
- Models with millions (or billions) of parameters are now the standard;
- Models are easily overfitted;
- Training requires huge datasets with annotated information;
Segmentation Representation Learning
¹ H. Xiao, D. Li, H. Xu, S. Fu, D. Yan, K. Song, and C. Peng. Semi-Supervised Semantic Segmentation with Cross Teacher Training. Neurocomputing, 508, pp.36-46. 2022.
² H. Zhao, X. Qi, X. Shen, J. Shi, and J. Jia. ICNet for Real-Time Semantic Segmentation on High-Resolution Images. In European Conference on Computer Vision (ECCV), pp. 405-420. 2018.
³ L. Chan, M.S. Hosseini. and K.N. Plataniotis. A Comprehensive Analysis of Weakly-Supervised Semantic Segmentation in Different Image Domains. In International Journal of Computer Vision, 129, pp.361-384. 2021.
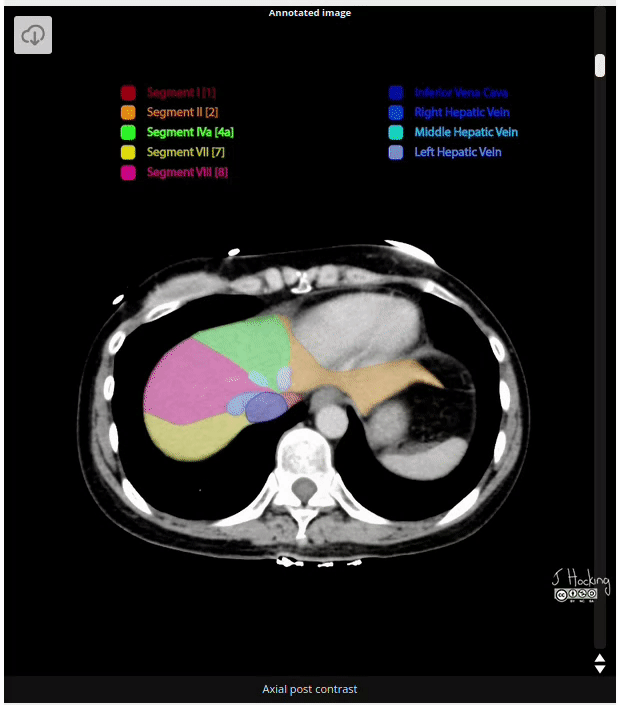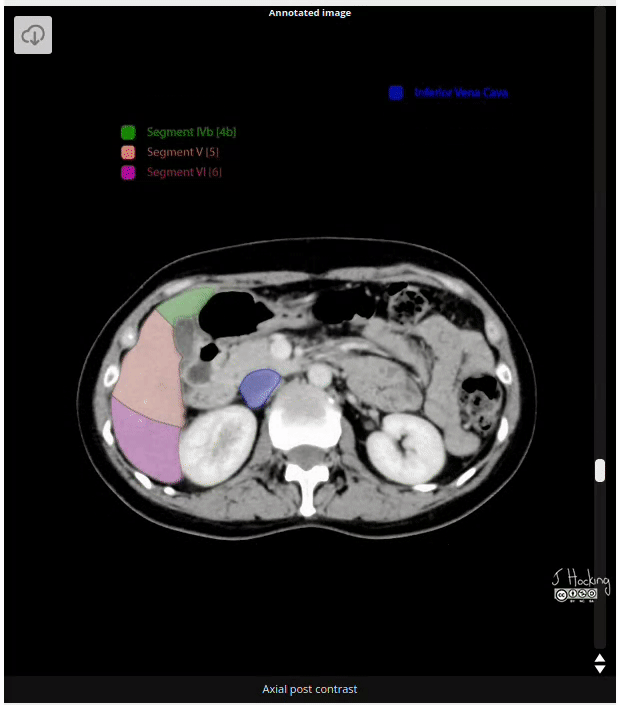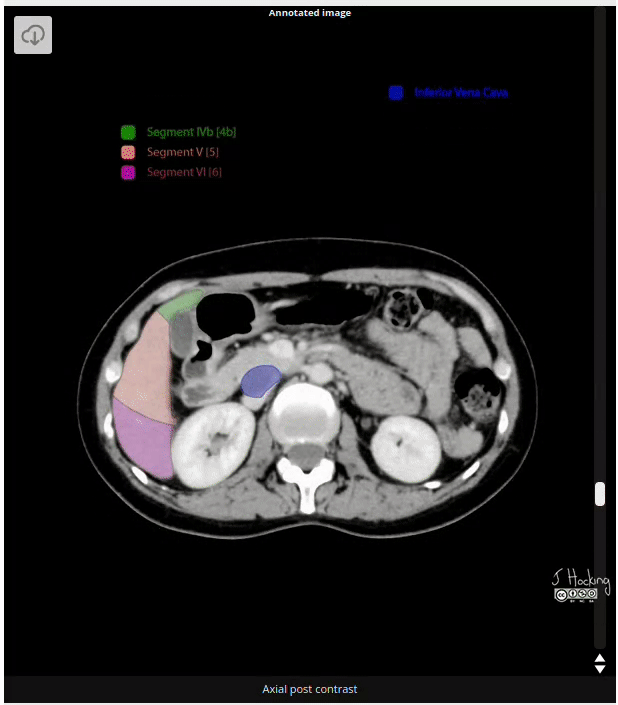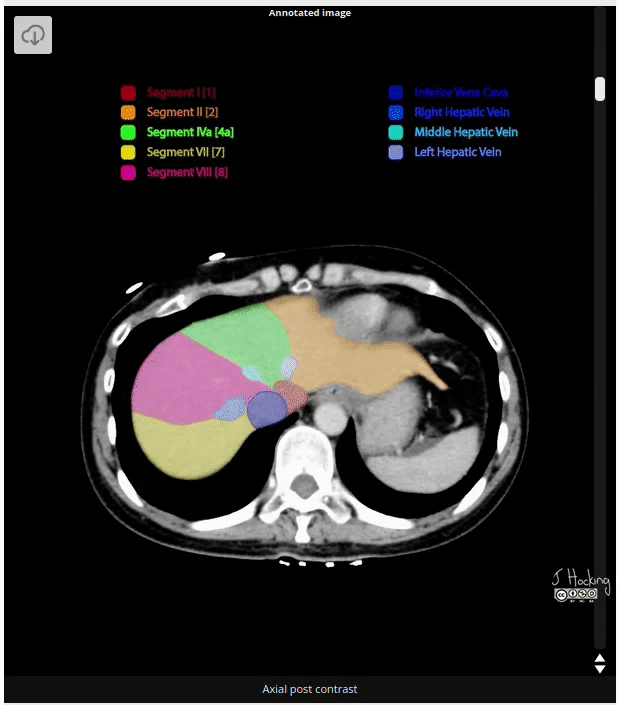
Figure 8: Example of annotated CT Scan image. Source: https://radiopaedia.org/cases/liver-segments-annotated-ct-1

Figure 6: Example of road segmentation in SpaceNet dataset. Source: https://www.v7labs.com/open-datasets/spacenet
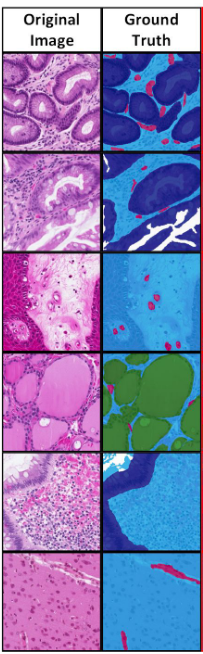
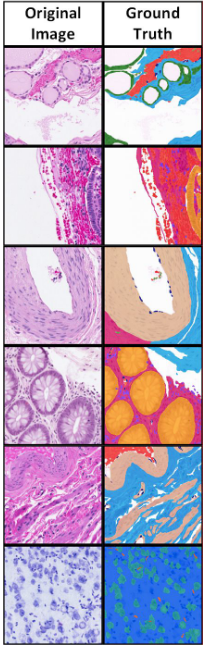
Figure 7: Example of (a) morphological and (b) functional segmentation of samples in the Atlas of Digital Pathology dataset. Source: L. Chan et al.

Figure 4: Example of samples and ground-truth panoptic segmentation annotation from the MS COCO 2017 dataset. Source: https://cocodataset.org/#panoptic-2020.
Figure 5: Example of semantic segmentation produced by ICNet for a video sample in the Cityscapes dataset. Source: https://gitplanet.com/project/fast-semantic-segmentation.

Figure 3: Samples, proposals¹ and ground-truth segmentation annotation from the Pascal VOC 2012 dataset.

¹ J. Long, E. Shelhamer, and T. Darrell. Fully Convolutional Networks for Semantic Segmentation. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 3431-3440. 2015.
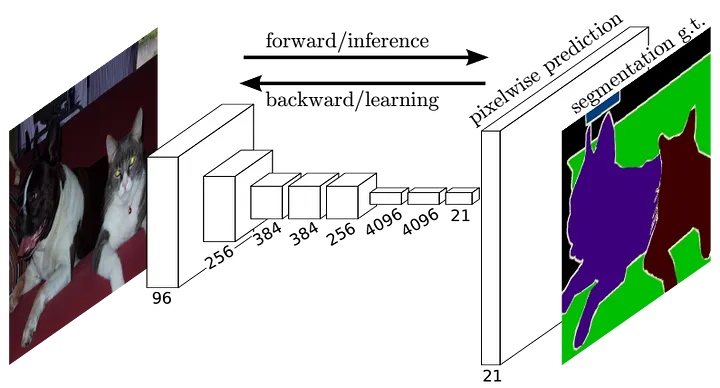
Figure 9: Fully Convolutional Network (FCN) architecture¹, mapping image samples to their respective semantic segmentation maps.
This information needs the be known and available at training time.
\text{CE}(p_i, y_i) = -\sum_{c=1}^M y_{ic}\log(p_{ic})
Equation 1: The (naive) categorical cross-entropy loss function.
Semantic Segmentation Representation Learning
Weakly Supervised (WSSS) Semantic Segmentation
¹ O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein and A.C. Berg. Imagenet Large Scale Visual Recognition Challenge.
In International Journal of Computer Vision, 115, pp.211-252, 2015.
Figure 10: Samples in the ImageNet 2012 dataset¹. Source: cs.stanford.edu/people/karpathy/cnnembed.

Weakly Supervised (WSSS) Semantic Segmentation
¹ B. Zhou, A. Khosla, A. Lapedriza, A. Oliva, and A. Torralba. Learning Deep Features for Discriminative Localization. In Conference on Computer Vision and Pattern Recognition (CVPR), pp. 2921-2929. 2016.
Equation 4: Feed-Forward for a for Convolutional Networks containing GAP layers and the formulation for CAM¹.
\implies L^c_\text{CAM}(f, x) = \sum_k w_k^c A^k
f(x) = \frac{1}{hw}\sum_{ij} \sum_k w_k^c A^k_{ij} = \text{GAP} (w^c \cdot A)
f(x) = \sum_k w_k^c \text{GAP}(A^k) = \sum_k w_k^c \frac{1}{hw}\sum_{ij} A^k_{ij}
Weakly Supervised (WSSS) Semantic Segmentation
¹ B. Zhou, A. Khosla, A. Lapedriza, A. Oliva, and A. Torralba. Learning Deep Features for Discriminative Localization. In Conference on Computer Vision and Pattern Recognition (CVPR), pp. 2921-2929. 2016.

Figure 11: Examples of CAMs and approximate bounding boxes found for different birds in the CUB200 dataset. Source: Zhou et al.¹
Weakly Supervised (WSSS) Semantic Segmentation
Mutual Promotion WSSS
Self-Supervised Learning Semi-Supervised
¹Liu, S., Zhi, S., Johns, E., and Davison, A. J. (2022b). Bootstrapping semantic segmentation with regional contrast. In International Conference on Learning Representations (ICLR).
²Hu, H., Wei, F., Hu, H., Ye, Q., Cui, J., and Wang, L. (2021). Semi-supervised semantic segmentation via adaptive equalization learning. Advances in Neural Information Processing Systems, 34:22106–22118.
³Wang, Y., et al. (2022). Semi-supervised semantic segmentation using unreliable pseudo-labels. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 4248–4257.
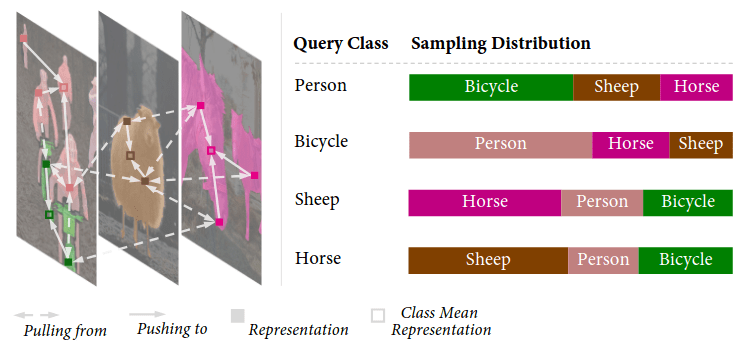
Figure 12: Illustration of Regional Contrast (ReCo). Representations are extracted for pixel queries and trained in a contrastive learning fashion. Source: Liu et al.¹
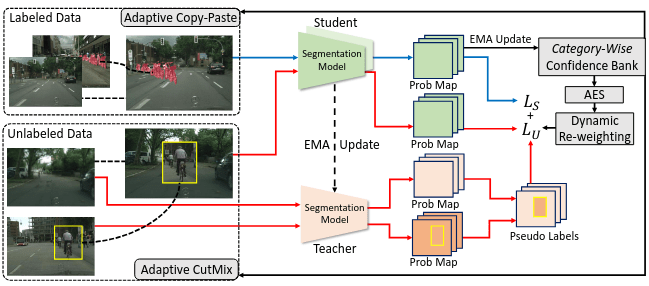
Figure 13: Illustration of Adaptative Equalization Learning (AEL). Unlabeled data is fed to both teacher and student models, and the response of the former is used to regularized the latter's. Source: Hu et al.²
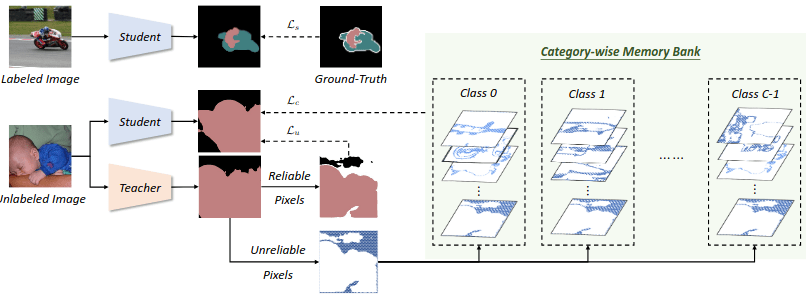
Figure 14: Diagram of U²PL. Employs ideas from both ReCo and AEL for more efficient Semi-Supervised Semantic Segmentation training. Source: Hu et al.³
Summary
- Introduction & Related Works
- Methodology
- Results
- Conclusion
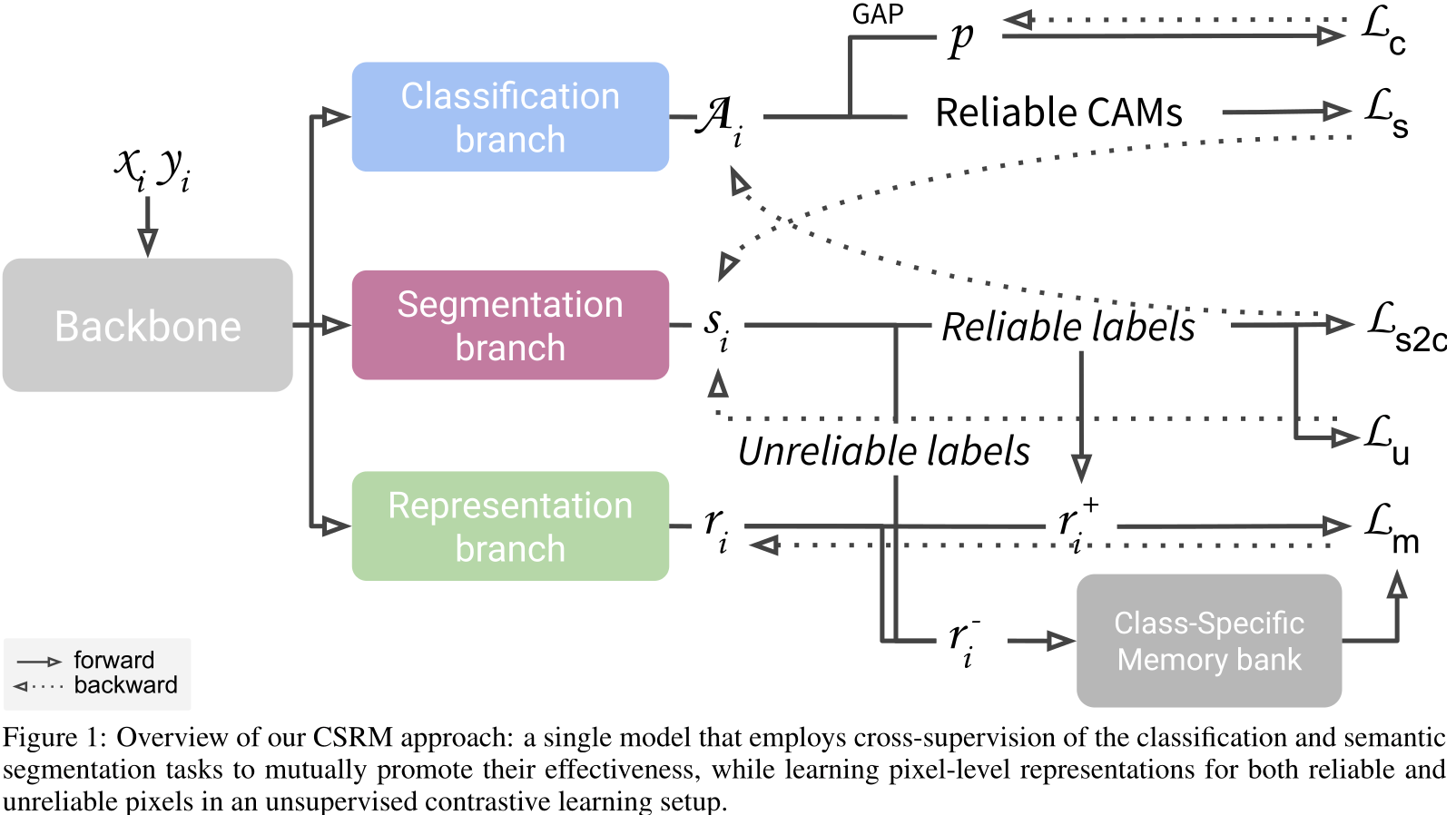
CSRM
Our approach is inspired in previous research on Mutual Promotion and
Self-Supervised Learning.
Key differences:
- Warm starts from pretrained week segmentation model (often a image-level classification model);
- Utilizes only image-level annotation during training:
- Class-specific prototypes are extracted from high-confidence regions based on weak annotation;
- Prototype and negative representations are selected by leveraging the image-level information;
Architecture CSRM
Objective Functions CSRM
\mathcal{L} = \mathcal{L}_c + \mathcal{L}_s
+\lambda_\text{s2c}\mathcal{L}_\text{s2c}
+\lambda_u\mathcal{L}_u
+\lambda_m\mathcal{L}_m
0 \mid t = 0
1 \mid t \neq 0
\{
0 \mid t = 0
\text{interp}(0.1, 1) \mid t \neq 0
\{
(warm-up)
Classification loss Objective Functions
+ (1-y_{ic})\log({e^{-p_{ic}^s}}/{(1 + e^{-p_{ic}^s})})
\mathcal{L}_\text{c}(\mathbb{p}_i^s, \mathbb{y}_i) = - \frac{1}{C} \sum_c y_{ic}\log((1 + e^{-p_{ic}^s})^{-1})
Segmentation loss Objective Functions
\mathcal{L}_\mathbf{s}(\mathbf{s}_i^s, \mathbf{l}_i^t)
= - \frac{1}{|\mathbf{M}^p(\mathbf{l}_i^t)|} \sum_{hw}^{HW} \mathbf{M}_{hw}^p(\mathbf{l}_i^t) \sum_c^C \mathbf{l}_{ihwc}^t
\log\mathbf{s}_{ihwc}^s
\mathbf{M}^p(\mathbb{l}_i^t) = {1}\left[\max_{c\in C} \mathbb{l}_i^{tc}\not\in (\delta_\text{bg}, \delta_\text{fg}]\right]
\mathbb{l}_i^t = \text{dCRF}(\psi(\mathbb{A}_i^t))
Student
Teacher
Activation Consistency loss Objective Functions
where \( c_i^\star = \arg\max_c\mathbf{s}_{ihwc}^t \)
\mathcal{L}_\text{s2c}(\mathbf{A}_i^s, \mathbf{s}_i^t) = - \frac{1}{|\mathbf{M}^s(\mathbf{s}_i^t)|} \sum_{hw}^{HW} \mathbf{M}_{hw}^s(\mathbf{s}_i^t) \log\mathbf{Q}_{ihwc_i^\star}^s
\mathbf{Q}_i^s = \text{softmax}\left(\mathbf{S}_{i, \text{bg}}^s \mid \text{upscale}(\mathbf{A}_i^s)]\right)
\mathbf{M}^s(\mathbf{s}_i^t) = 1\left[\max_{c\in C} \mathbf{s}_{ic}^t > \sigma_\text{s2c}\right]
Teacher
Student
Segmentation Consistency loss Objective Functions
\mathcal{L}_\text{u}(\mathbf{s}_i^s, \mathbf{s}_i^t) = -\frac{1}{|\mathbf{M}^{\tilde{s}}(\mathbf{\tilde{s}}_i^t)|} \sum_{hw}^{HW} \mathbf{M}^{\tilde{s}}_{hw}(\mathbf{\tilde{s}}_i^t) \log\mathbf{s}_{ihw{c_i^\star}}^s
\mathcal{H}_{hw}(\mathbf{\tilde{s}}_{i}^t) = -\sum_c^{|C|} \tilde{s}_{ihwc}^t \log \tilde{s}_{ihwc}^t
\gamma_t^{\tilde{\mathcal{B}}_i} = \text{quantile}\left(\mathcal{H}\left(\left[ \mathbf{\tilde{s}}_{i}^t \mid \mathbf{\tilde{s}}_{i+1}^t \mid \ldots \mid \mathbf{\tilde{s}}_{i+b-1}^t \right]\right), 1-\alpha_t\right)
\mathbf{M}^{\tilde{s}}(\mathbf{\tilde{s}}_i^t) = 1 \left[ \mathcal{H}(\mathbf{\tilde{s}}_{i}^t) \leq \gamma_t^{\tilde{\mathcal{B}}_i} \right]
Student
Teacher
Pixel Contrastive Loss Objective Functions
\mathcal{L}_m = -\frac{1}{|C|\times P}\sum_c^{|C|} \sum_p^{P} \log \left[\frac{e^{\langle\mathbf{r}_{pc}, \mathbf{r}_{pc}^{+}\rangle} / \tau}{e^{\langle\mathbf{r}_{pc}, \mathbf{r}_{pc}^{+}\rangle} / \tau + \sum_j^{N} e^{\langle\mathbf{r}_{pjc}, \mathbf{r}_{pjc}^{-}\rangle} / \tau}\right]
Student
Teacher
Pixel Representation Selection Pixel Contrastive Loss
- \( \mathbf{r}_{pc}^+ \): averaged representation amongst pixels confidently predicted as class c (classification branch) or low segmentation entropy (segmentation branch);
- \( \mathbf{r}_{pc}^- \):
- [Pixels segmented in class c with high probability (low rank class) and confidently classified as other classes (classification branch)]
or - [Pixels segmented in class c with high probability (low rank class) and not in image-level label]
or - [Pixels segmented in class c with medium probability (mid rank class. I.e., hard queries that probably do not belong to c)]
- [Pixels segmented in class c with high probability (low rank class) and confidently classified as other classes (classification branch)]
Summary
- Introduction & Related Works
- Methodology
- Results
- Conclusion
Ablation Results
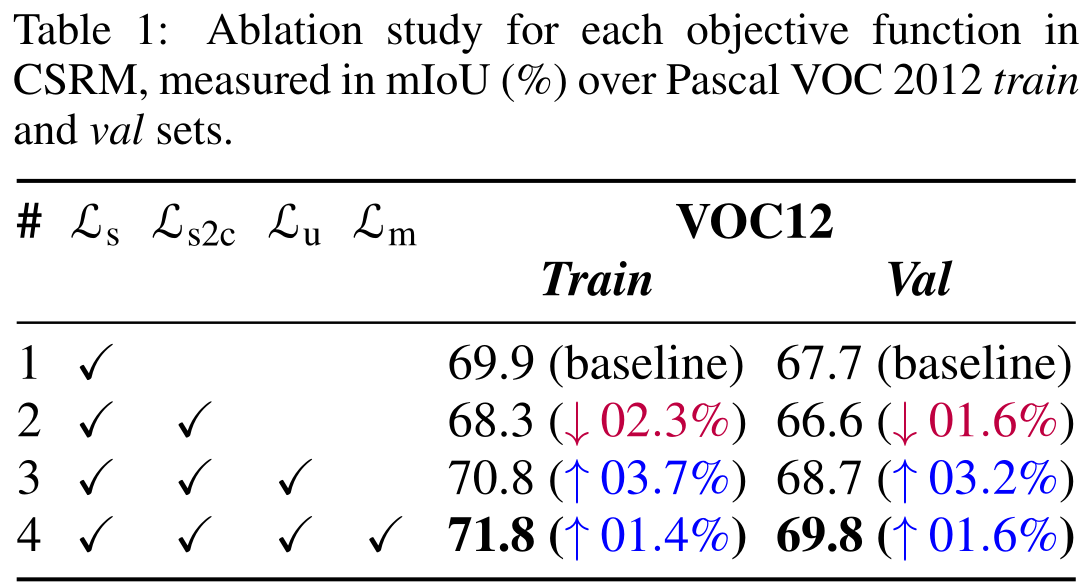
\( \mathcal{L}_\text{s2c} \) alone results in overfit
+ \( \mathcal{L}_\text{u} \) greatly improves results
+ \( \mathcal{L}_\text{m} \) produces the best outcome
Ablation Results
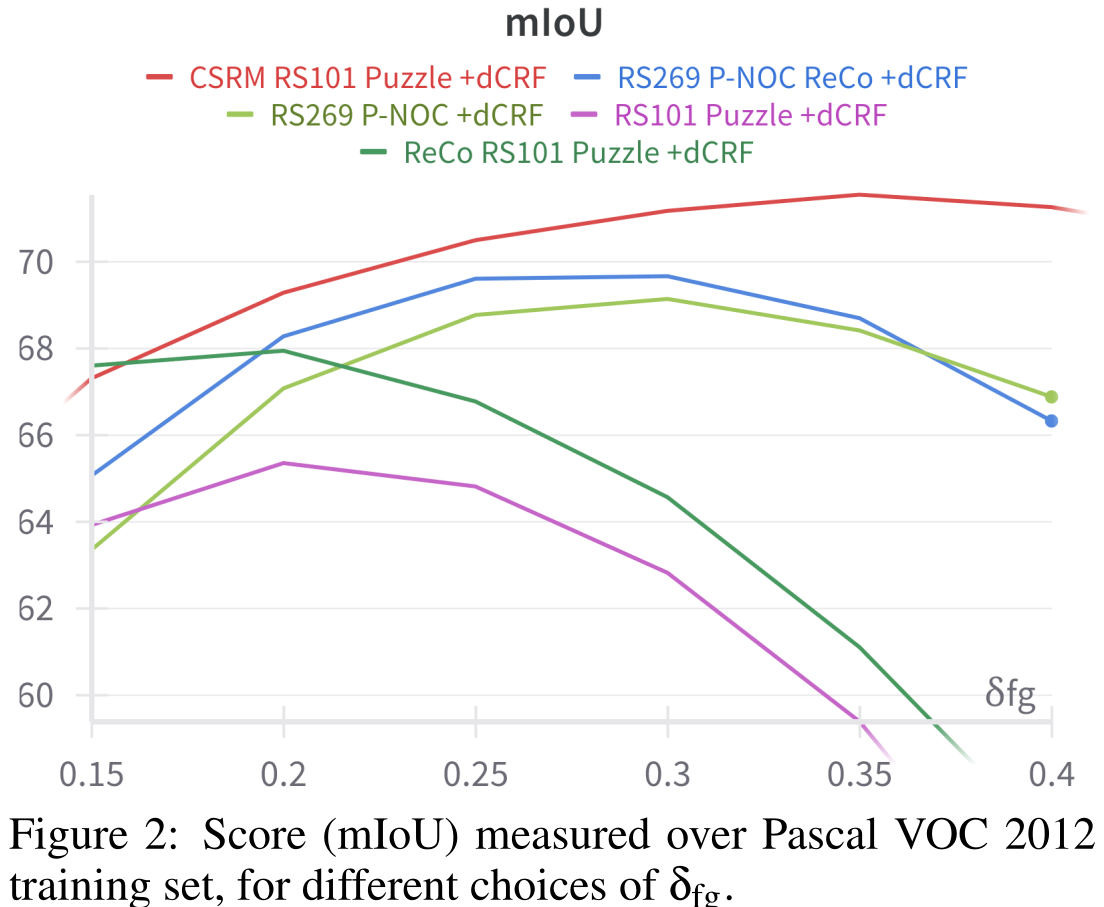
Ablation Results
Robust segmentation scores obtained by CSRM: higher and less varying scores for almost all choices of the threshold δ.
Refinement Results
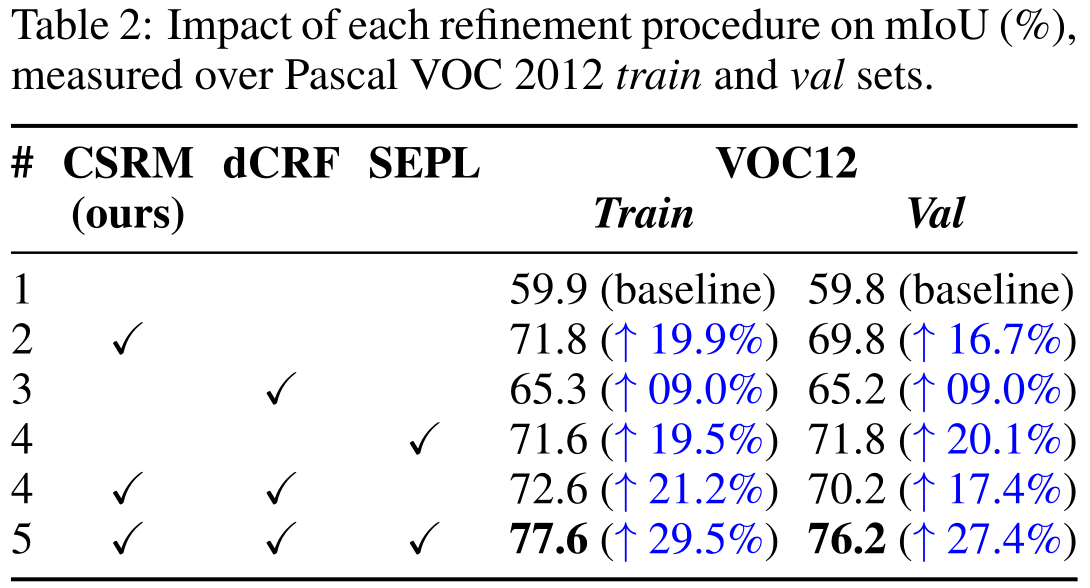
CSRM results in the highest (individual) relative improvement
CSRM can be further improved with refinement methods
Puzzle-CAM
Refinement Results

Figure 15: Qualitative results of pseudo labels generated by CSRM and refined with dCRF and SEPL.
Verification Results
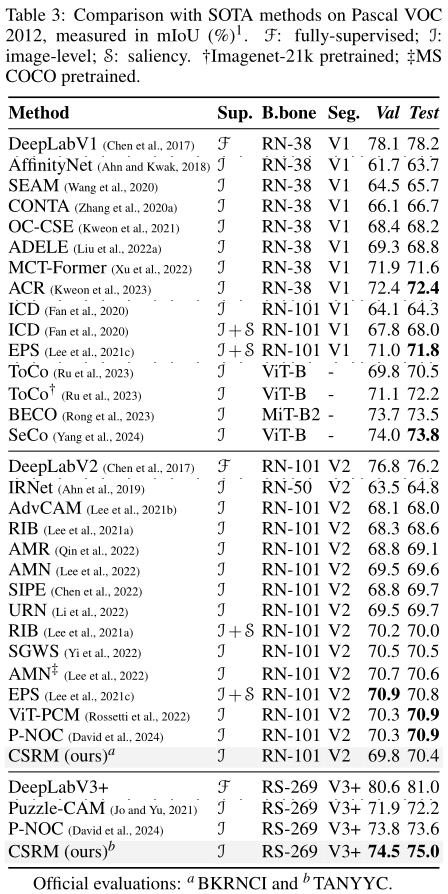
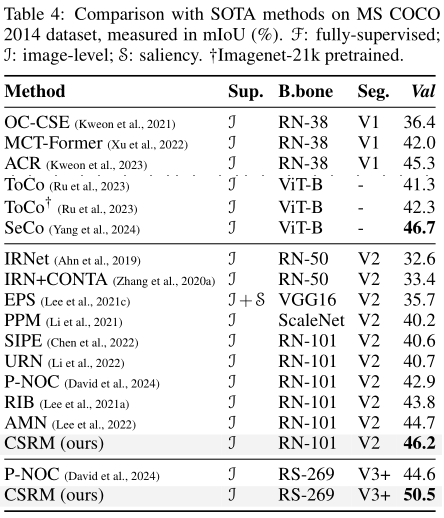
Verification Results

Figure 16: Qualitative results of prediction proposals made by segmentation models trained over pseudo labels devised by CSRM.
Summary
- Introduction & Related Works
- Methodology
- Results
- Conclusion
Conclusion
- We proposed CSRM: an approach to determine and utilize (the otherwise wasted) “unreliable” pixels based only on pseudo information, where no pixel-level annotations are available and human intervention is limited;
- Empirical results suggest our approach can provide substantial improvement in segmentation effectiveness of weakly supervised models, while requiring fewer resources compared to other techniques:
- CSRM requires a single training stage and no external data (e.g., pretrained saliency detectors);
- Training over Pascal VOC 2012 took 15.7 minutes/epoch and 3.9 hours in total, achieving 99% of the best mIoU score observed in the first 1.6 hours;
- Training over MS COCO 2014 took 4.4 hours/epoch, achieving 99% of the best mIoU score
observed after only one epoch.
Future Work
- To investigate the effect of our approach in functional segmentation and biological-related tasks, in which visual patterns are convoluted or unclear;
- Devise ways to compress data representation and further reduce computational footprint.
Learning Weakly Supervised Semantic Segmentation Through Cross-Supervision and Contrasting of Pixel-Level Pseudo-Labels
By Lucas David



