Project: Deliverable 2
Repo for activities: https://github.ugrad.cs.ubc.ca/CPSC310-2018W-T2/d2_tutorial
Refactoring
Is the process of restructuring existing code without changing its behavior -- Wikipedia
Rename: Renames a variable, method, class, etc.
Extract method: Moves some block of code to a well contained method
Repo for activities: https://github.ugrad.cs.ubc.ca/CPSC310-2018W-T2/d2_tutorial
Activity #1
1. Clone the repo: https://github.ugrad.cs.ubc.ca/CPSC310-2018W-T2/d2_tutorial
2. Make sure you can run the tests (yarn install, yarn build, yarn test)
3. Try using extract method on the switch statement, the factorial loop, or both. Do the tests still pass?
~5-10 min
D2: Goals and specs
1. Add and remove a dataset containing information about UBC classrooms
return new Promise(function (fulfill, reject) {
try {
const myZip = new Zip();
if (kind === InsightDatasetKind.Courses) {
// Extract the content
zip = myZip.extract();
for (file in files inside zip) {
try{
contents = file.getContent();
for (section in results) {
// do something
}
} catch (err) {
// do something
}
});
// more code here
} else if (kind === InsightDatasetKind.Rooms) {
// We are just going to copy and paste the code above and generate ourselves a problem
} else {
// keep doing the same strategy until our code is doomed
}
// more code here
// even more code
// ...
} catch (err) {
// do something
}
});Do we have a problem?
return new Promise(function (fulfill, reject) {
try {
const myZip = new Zip();
if (kind === InsightDatasetKind.Courses) {
// Extract the content
zip = myZip.extract();
for (file in files inside zip) {
try{
contents = file.getContent();
for (section in results) {
// do something
}
} catch (err) {
// do something
}
});
// more code here
} else if (kind === InsightDatasetKind.Rooms) {
// Extract the content
zip = myZip.extract();
for (file in files inside zip) {
try{
contents = file.getContent();
for (section in results) {
// do something
}
} catch (err) {
// do something
}
});
} else {
// keep doing the same strategy until our code is doomed
}
// more code here
// even more code
// ...
} catch (err) {
// do something
}
});Do we have a problem?
1. Code Readability
2. Code Maintainability
3. Code Testability
return new Promise(function (fulfill, reject) {
try {
const myZip = new Zip();
if (kind === InsightDatasetKind.Courses) {
// Extract the content
zip = myZip.extract();
for (file in files inside zip) {
try{
contents = file.getContent();
for (section in results) {
// do something
}
} catch (err) {
// do something
}
});
// more code here
} else if (kind === InsightDatasetKind.Rooms) {
// Extract the content
zip = myZip.extract();
for (file in files inside zip) {
try{
contents = file.getContent();
for (section in results) {
// do something
}
} catch (err) {
// do something
}
});
else if (kind === InsightDatasetKind.X) {
// Extract the content
zip = myZip.extract();
for (file in files inside zip) {
try{
contents = file.getContent();
for (section in results) {
// do something
}
} catch (err) {
// do something
}
});
// more code here
} else if (kind === InsightDatasetKind.Y) {
// Extract the content
zip = myZip.extract();
for (file in files inside zip) {
try{
contents = file.getContent();
for (section in results) {
// do something
}
} catch (err) {
// do something
}
});
} else if (kind === InsightDatasetKind.Z) {
// Extract the content
zip = myZip.extract();
for (file in files inside zip) {
try{
contents = file.getContent();
for (section in results) {
// do something
}
} catch (err) {
// do something
}
});
} else {
// keep doing the same strategy until our code is doomed
}
// more code here
// even more code
// ...
} catch (err) {
// do something
}
});Do we have a problem?
1. Code Readability
2. Code Maintainability
3. Code Testability
Goals and specs
1. Add and remove a dataset containing information about UBC classrooms
rooms.zip
addDataset(...)
Parse it
Keep data structure in a variable
Save it to disk
Caching
same workflow as courses.zip BUT with different file types
InsightDatasetKind.Rooms
(kind)
addDataset(...)
new code
kind?
existing code
parse courses
parse rooms
Keep data structure in a variable
Save it to disk
Activity #2. How to solve this problem?
Activity #2
Take a few minutes to talk with a partner (ideally your project partner), about where refactoring might be useful to integrate this new addDataset functionality.
You can think about:
- What steps will be identical, regardless of data type?
- What steps have similar inputs and outputs, but different implementations? Could these be abstracted?
- How might you structure your code to take advantage of these properties?
~5 min
Goals and specs
2. Answer advanced queries about UBC courses and rooms
Goals and specs
Examples:
"what's the average of CPSC 340?"
2. Answer advanced queries about UBC courses and rooms
Goals and specs
2. Answer advanced queries about UBC courses (current solution)
{
"WHERE":{
"AND": [
{ "IS":{ "courses_id": "340" } },
{ "IS":{ "courses_dept": "cpsc" }}
]
},
"OPTIONS":{
"COLUMNS":[
"courses_id", "courses_avg"
],
"ORDER":"courses_avg"
}
}Goals and specs
{"result": [
{ "courses_id": "340",
"courses_avg": 68.4 },
{ "courses_id": "340",
"courses_avg": 68.4 },
{ "courses_id": "340",
"courses_avg": 72.65 },
{ "courses_id": "340",
"courses_avg": 72.65 },
{ "courses_id": "340",
"courses_avg": 72.94 },
{ "courses_id": "340",
"courses_avg": 72.94 },
...
]}{
"WHERE":{
"AND": [
{ "IS":{ "courses_id": "340" } },
{ "IS":{ "courses_dept": "cpsc" }}
]
},
"OPTIONS":{
"COLUMNS":[
"courses_id", "courses_avg"
],
"ORDER":"courses_avg"
}
}not what we
were looking for
2. Answer advanced queries about UBC courses (current solution)
Goals and specs
2. Answer advanced queries about UBC courses (new solution)
{
"result": [
{
"courses_id": "340",
"overallAvg": 75.69
}
]
}{
"WHERE":{
"AND": [
{ "IS":{ "courses_id": "340" } },
{ "IS":{ "courses_dept": "cpsc" }}
]
},
"OPTIONS":{
"COLUMNS":[
"courses_id", "overallAvg"
]
},
"TRANSFORMATIONS":{
"GROUP":[ "courses_id"],
"APPLY": [
{
"overallAvg": {
"AVG": "courses_avg"
}
}
]
}
}this is the right result!
Goals and specs
2. New EBNF:
QUERY ::='{'BODY ', ' OPTIONS (', ' TRANSFORMATIONS)? '}'
BODY ::= 'WHERE:{' (FILTER)? '}'
OPTIONS ::= 'OPTIONS:{' COLUMNS ', ' (SORT)?'}'
TRANSFORMATIONS ::= 'TRANSFORMATIONS: {' GROUP ', ' APPLY '}'
// ... Old content ...
COLUMNS ::= 'COLUMNS:[' ((key | applykey) ',')* (key | applykey) ']'
SORT ::= 'ORDER: ' ('{ dir:' DIRECTION ', keys: [ ' ORDERKEY (',' ORDERKEY)* ']}') | ORDERKEY
DIRECTION ::= 'UP' | 'DOWN'
ORDERKEY ::= key | applykey
GROUP ::= 'GROUP: [' (key ',')* key ']'
APPLY ::= 'APPLY: [' (APPLYRULE (', ' APPLYRULE )* )? ']'
APPLYRULE ::= '{' applykey ': {' APPLYTOKEN ':' key '}}'
APPLYTOKEN ::= 'MAX' | 'MIN' | 'AVG' | 'COUNT' | 'SUM'
key ::= mkey | skey
mkey ::= idstring '_' mfield
skey ::= idstring '_' sfield
mfield ::= 'avg' | 'pass' | 'fail' | 'audit' | 'year' | 'lat' | 'lon' | 'seats'
sfield ::= 'dept' | 'id' | 'instructor' | 'title' | 'uuid' |
'fullname' | 'shortname' | 'number' | 'name' | 'address' | 'type' | 'furniture' | 'href'
idstring ::= [^_]+ // One or more of any character, except asterisk.
inputstring ::= [^*]* // zero or more of any character except asterisk.
applykey ::= [^_]+ // one or more of any character except underscore.D2 - Further clarifications
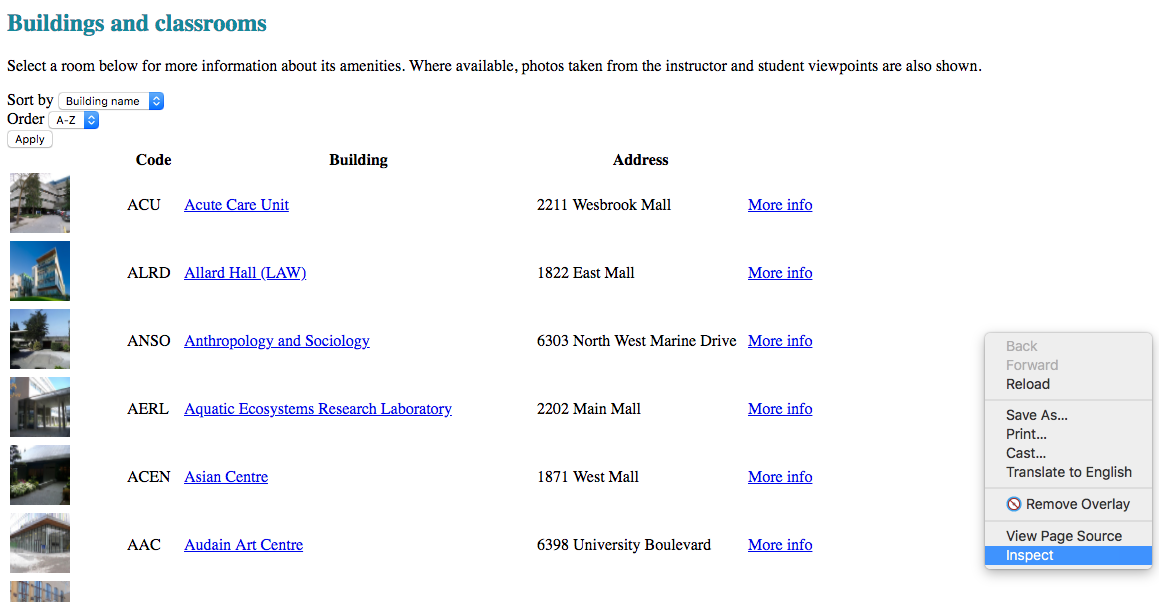
The rooms dataset
rooms/
rooms/index.htm
rooms/campus/
rooms/campus/discover/
rooms/campus/discover/buildings-and-classrooms/
rooms/campus/discover/buildings-and-classrooms/AAC
rooms/campus/discover/buildings-and-classrooms/ACEN
rooms/campus/discover/buildings-and-classrooms/ACU
rooms/campus/discover/buildings-and-classrooms/AERL
rooms/campus/discover/buildings-and-classrooms/ALRD
...
- Files in HTML format, parsable using the parse5 package
- Each file other than index.htm represents a building and its rooms
- All buildings linked from the index should be considered valid buildings
zip.files
?
?
single file
e.g. AAC
your datastructure
parse5 datastructure
HTML in one slide
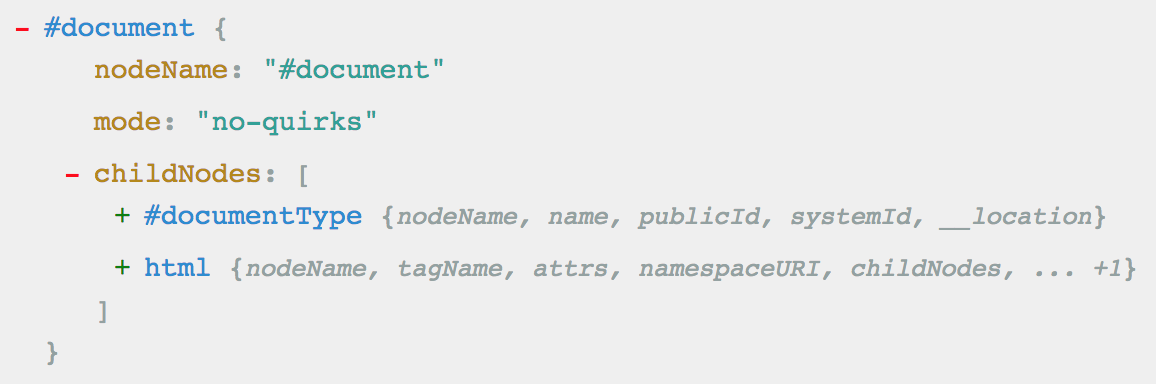
- HTML has a tree structure. The "document" element is the root. Elements have at most one parent, and zero to many children
- Important properties of HTML elements (for D2)
- Tag: What type of element is this (e.g. p, div, h1, a)
- Id: A string label. Each id should be associated with exactly one element (e.g. "clone-repo-button")
- Class: A string label. Many elements can share the same label (e.g. "filesystem-row")
- Elements often have a text value associated with them
<p id="blame-europe" class="popup">By using our site, you agree...</p>
Inspect the html files in the dataset, take a look at them and try to find useful information
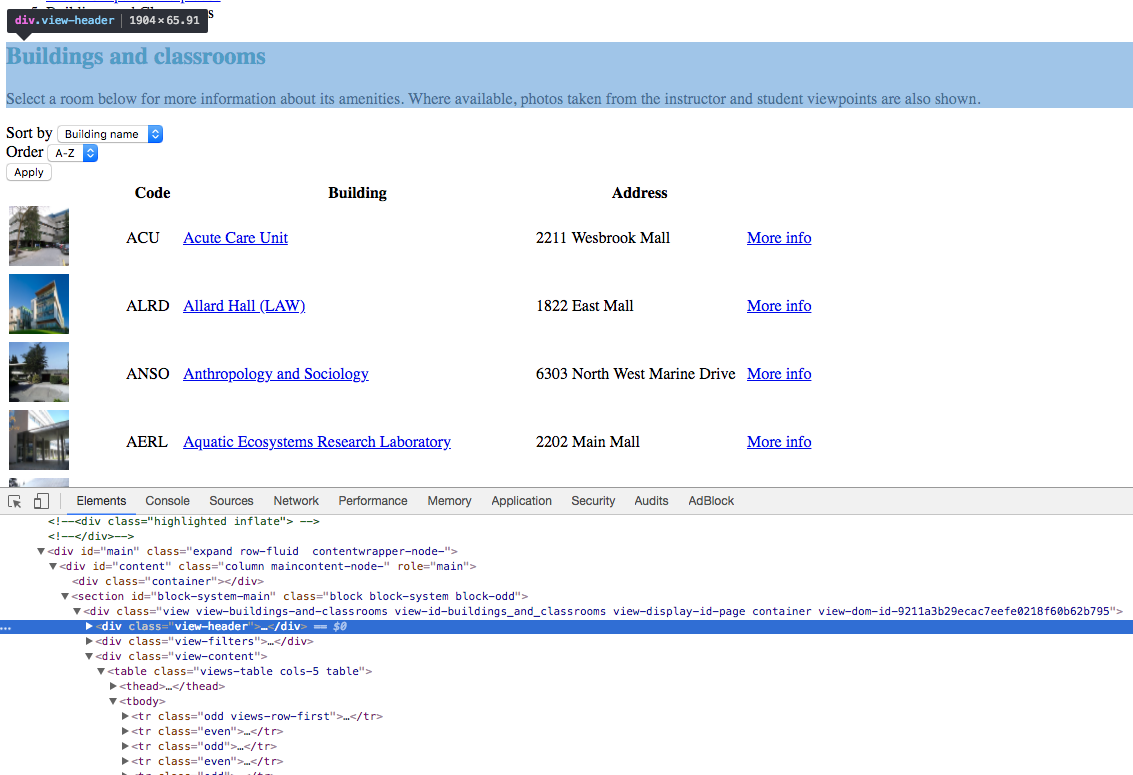
tree node for that element
current html element that I'm inspecting
parse5
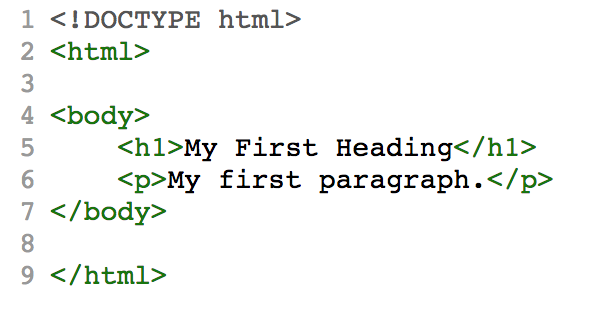
<html><body><h1><p>My first headingMy first paragraph.Activity #3 - AST exploring
At the top of a file on GitHub, there is a small printout of the file size. With a partner, think about how you might approach finding this using parse5. You may want to:
- Look at the element using inspect element in your browser tools
- Paste the page source into the AST explorer and find the element there
- Look at the parse5 output and think about how you would actually access that specific value
~10 min

A note on hardcoding
Since the tree is structured as nodes containing arrays of child nodes, any element could be accessed like:
root.childNodes[1].childNodes[5].childNodes[3]...
Not only is this mindnumbingly annoying to write, it is also incredibly prone to breaking. Any new element added to the page could completely break it.
A better approach is to develop a method to search through this tree for your target data
(Also because we may test for it)
HTTP

GET http://skaha.cs.ubc.ca:11316/api/v1/team666/6245%20Agronomy%20Road%20V6T%201Z46245 Agronomy Road V6T 1Z46245%20Agronomy%20Road%20V6T%201Z4address
URL-encoded address
status: 200,
body: {"lat":49.26125,"lon":-123.24807}request
response
* Take a look at https://en.wikipedia.org/wiki/Hypertext_Transfer_Protocol for a more comprehensive explanation of HTTP
client
server
const request = require('request');
request({
method: 'GET',
uri: 'http://cs310.ugrad.cs.ubc.ca:11316/api/v1/
project_<CSID1>_<CSID2>/6245%20Agronomy%20Road%20V6T%201Z4',
gzip: true
}).on('response', function(response) {
console.log("status: " + response.statusCode);
}).on('data', function(data) {
// decompressed data as it is received
console.log('decoded chunk: ' + data)
});status: 200
decoded chunk: {
"lat":49.26125,
"lon":-123.24807
}* https://github.com/request/request
* This code will not work in your project ! You are supposed to use the http package instead of request.
HTTP
Activity #4
Implement the method do_math in the MathWrapper class. You CAN change the method header and the tests in the process of making it work
- We'll make requests to the math.js API. It can take math expressions as strings and respond with the result
- You'll use the request package for this activity. Note that this is NOT the package you'll use in the project
- There are some links to references in the code comments
~10-15 min
Q&A
Copy of Deliverable 2 tutorial
By lucaszamprogno

