















Luciano Mammino PRO
Cloud developer, entrepreneur, fighter, butterfly maker! #nodejs #javascript - Author of https://www.nodejsdesignpatterns.com , Founder of https://fullstackbulletin.com
Luciano Mammino (@loige)
2022-06-09
Get these slides!
👋 I'm Luciano (🇮🇹🍕🍝🤌)
👨💻 Senior Architect @ fourTheorem (Dublin 🇮🇪)
📔 Co-Author of Node.js Design Patterns 👉
Accelerated Serverless | AI as a Service | Platform Modernisation
We host a weekly podcast about AWS
Based on a talk presented at the AWS Summit London 2022 (MA-03 with Matheus Guimaraes & Colum Thorne) - fth.link/jn5
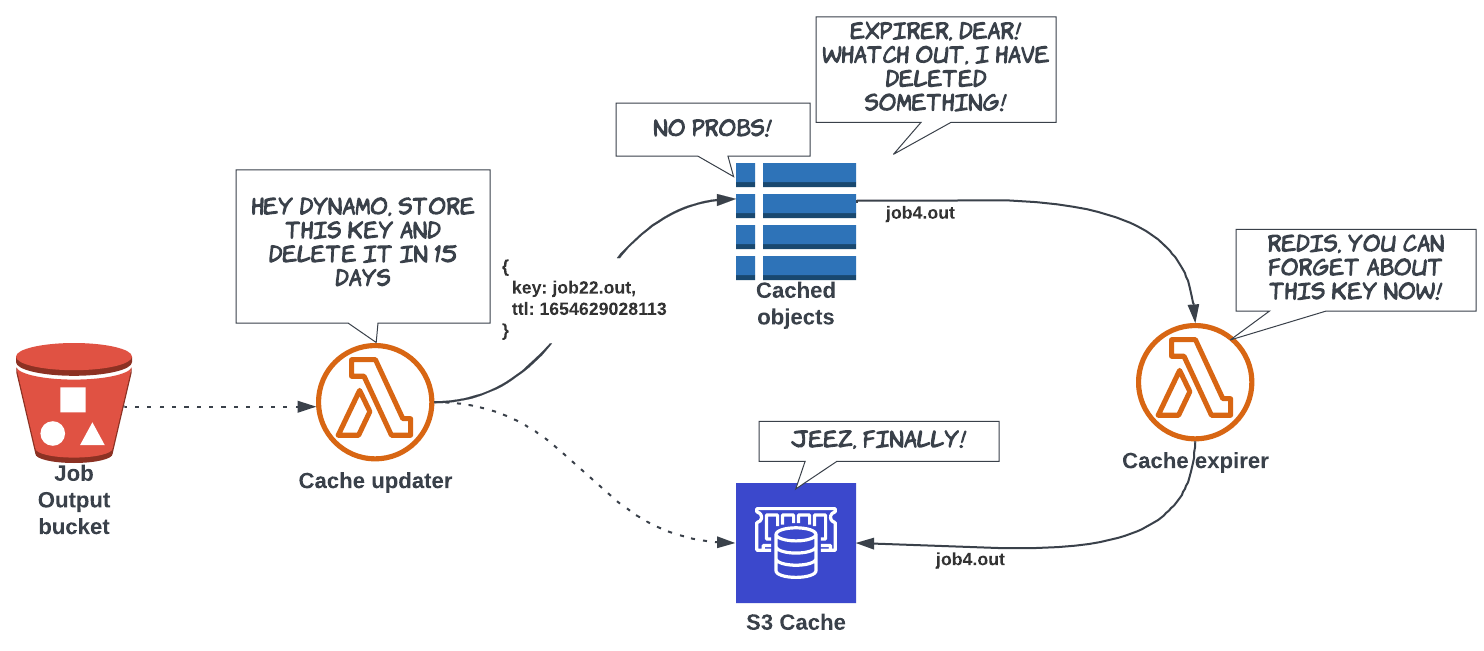
S3 Quotas
/parts/123abc/... /parts/456efg/... /parts/ef12ab/... /parts/...
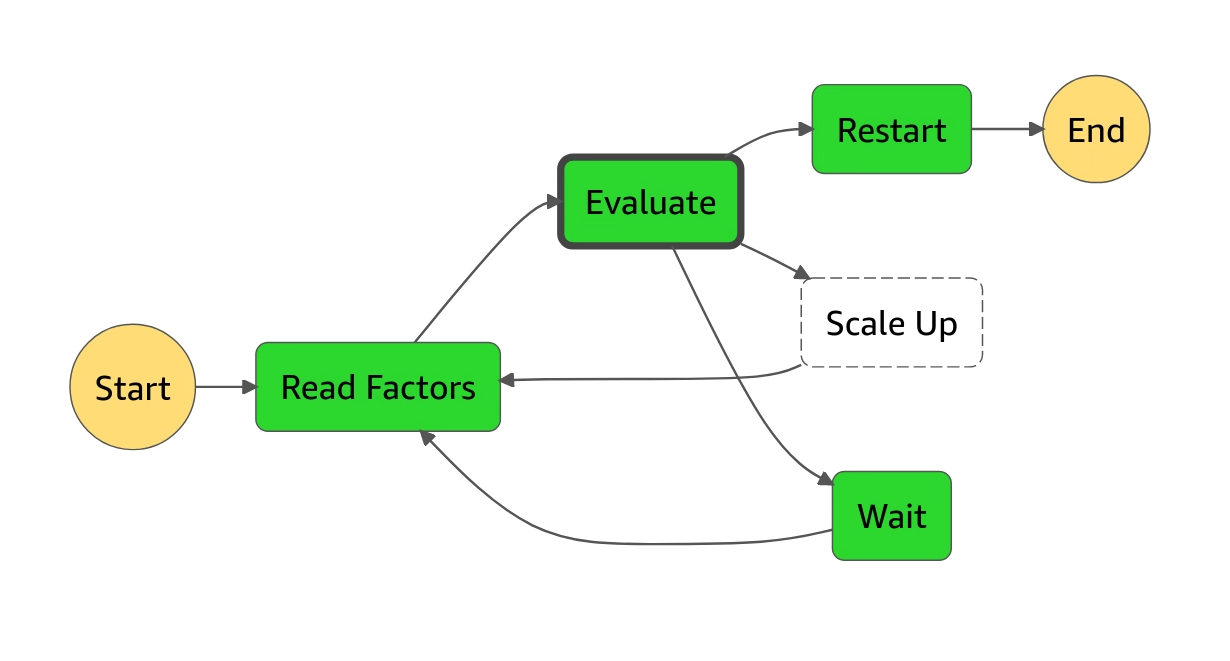
We have a continuously running step function to scale up the number of containers as needed
Decides whether to restart the step function, start new tasks or simply wait
Checks all the running jobs and how many containers they need
Uses the runTask API to start as many containers as needed
If this step function has done 500 iterations, start a new one and end
How do we stop containers?
They stop automatically after 15 minutes if they can't get jobs from the queue.
while True:
result = sqs_client.receive_message(/* ... */)
if 'Messages' not in result and
time.time() - time_since_last_message > 15 * 60:
break
else
process_job(result['Messages'])Cover photo by Murat Onder on Unsplash
Thanks to @eoins, @pelger, @cmthorne10 & @guimathed
THANKS! 🙌
* just a happy cloud
By Luciano Mammino
Serverless is great for web applications and APIs, but this does not mean it cannot be used successfully for other use cases. In this talk, we will discuss a successful application of serverless in the field of High Performance Computing. Specifically we will discuss how Lambda, Fargate, Kinesis and other serverless technologies are being used to run sophisticated financial models at one of the major reinsurance companies in the World. We we learn about the architecture, the tradeoffs, some challenges and some unresolved pain points. Most importantly, we'll find out if serverless can be a great fit for HPC and if we can finally stop managing those boring EC2 instances!




