機器學習小社-8
講師 000

-
你可以叫我 000 / Lucas
-
建國中學資訊社37th學術長
-
建國中學電子計算機研習社44th學術
-
校際交流群創群者
-
不會音遊不會競程不會數學的笨
-
資訊技能樹亂點但都一樣爛
-
專案爛尾大師
-
IZCC x SCINT x Ruby Taiwan 聯課負責人
講師 章魚
-
建國中學電子計算機研習社44th學術+總務
-
是的,我是總務。在座的你各位下次記得交社費
束脩給我 -
技能樹貧乏
-
想拿機器學習做專題結果只學會使用API
-
上屆社展烙跑到資訊社的叛徒
-
科班墊神
-
無模型的價值迭代
-
Q-Learning
-
DQN
目錄
無模型的價值迭代
基於模型
Model-based
基於價值
Value-based
基於策略
Policy-based
基於價值
Value-based
基於策略
Policy-based
策略梯度
Actor-Critic
Q-Leaning
DQN
策略迭代
價值迭代
無模型
Model-free
強化學習
Reinforcement Learning
現在沒有人告訴我們轉移方式跟機率了
怎麼辦
蒙特卡羅方法
Monte Carlo method
重複採樣取得所求機率分布的近似值
蒙特卡羅方法
Monte Carlo method
紀錄每次個點的\(s,a對應的reward跟下個狀態\)
取得動作價值的近似值
Q^\pi(s,a)=R(s,a)+\gamma \sum P(s'|s,a)\sum \pi(a'|s')Q'(s',a')
蒙特卡羅方法
Monte Carlo method
1 episode
\(S_t\)
\(a\)
\(S_{t+1}\)
\(a\)
\(S_{t+2}\)
\(a\)
terminate
\(R_t\)
\(R_{t+1}\)
\(R_{t+2}\)
Q^\pi(s,a)=R(s,a)+\gamma \sum P(s'|s,a)\sum \pi(a'|s')Q'(s',a')
這東西靠蒙地卡羅取得
蒙特卡羅方法
Monte Carlo method
1 episode
\(S_t\)
\(a\)
\(S_{t+1}\)
\(a\)
\(S_{t+2}\)
\(a\)
terminate
\(R_t\)
\(R_{t+1}\)
\(R_{t+2}\)
Q^\pi(s,a)=R(s,a)+\gamma\sum \pi(a'|s')Q'(s',a')
也就是說我們指依照我們走過的足跡更新
只要夠多次就可以得到\(P(s'|s,a)\)的近似值
蒙特卡羅方法
Monte Carlo method
1 episode
\(S_t\)
\(a\)
\(S_{t+1}\)
\(a\)
\(S_{t+2}\)
\(a\)
terminate
\(R_t\)
\(R_{t+1}\)
\(R_{t+2}\)
Q^\pi(s,a)=R(s,a)+\gamma\sum \pi(a'|s')Q'(s',a')
這個會用到\(\epsilon -greedy\)
等等會講
不過在更新Q時,我們只在乎我們的足跡
所以這一步他不影響
蒙特卡羅方法
Monte Carlo method
1 episode
\(S_t\)
\(a\)
\(S_{t+1}\)
\(a\)
\(S_{t+2}\)
\(a\)
terminate
\(R_t\)
\(R_{t+1}\)
\(R_{t+2}\)
Q^\pi(s,a)=R(s,a)+\gamma Q'(s',a')
Q(S_t=s,a)=R_t+\gamma R_{t+1}+\gamma^2 R_{t+2}
蒙特卡羅方法
Monte Carlo method
1 episode
\(S_{t+1}\)
\(a\)
\(S_{t+2}\)
\(a\)
terminate
\(R_{t+1}\)
\(R_{t+2}\)
Q(S_{t+1}=s',a')=R_{t+1}+\gamma R_{t+2}
蒙特卡羅方法
Monte Carlo method
1 episode
\(S_{t+2}\)
\(a\)
terminate
\(R_{t+2}\)
Q(S_{t+2}=s'',a'')=R_{t+2}
時序差分學習
Temporal Difference learning
狀態+動作\(\longrightarrow\)獎勵
時序差分學習
Temporal Difference learning
1 episode
\(S_t\)
\(a\)
\(S_{t+1}\)
\(a\)
\(S_{t+2}\)
\(a\)
terminate
\(R_t\)
\(R_{t+1}\)
\(R_{t+2}\)
Q^\pi(s,a)=R(s,a)+\gamma Q'(s',a')
時序差分學習
Temporal Difference learning
1 episode
\(S_t\)
\(a\)
\(S_{t+1}\)
\(R_t\)
Q(S_t=s,a)=R_t+\gamma Q(S_{t+1}=s',a')
時序差分學習
Temporal Difference learning
1 episode
\(S_{t+1}\)
\(a\)
\(S_{t+2}\)
\(R_{t+1}\)
Q(S_{t+1}=s',a')=R_{t+1}+\gamma Q(S_{t+2}=s'',a'')
時序差分學習
Temporal Difference learning
1 episode
\(S_{t+2}\)
\(a\)
terminate
\(R_{t+2}\)
Q(S_{t+2}=s'',a'')=R_{t+2}
時序差分學習
Temporal Difference learning
好處
更新較快,不必每次都玩到終點在更新
時序差分學習
Temporal Difference learning
更新方法
\(TD\_error=reward+\gamma Q(s',a')-Q(s,a)\)
\(Q(s,a)\space+=\space\alpha TD\_error\)
\(Q(s,a)\space+=\space\alpha(reward+\gamma Q(s',a')-Q(s,a))\)
learning rate
\(\varepsilon -greedy\)
探索-利用策略
exploration-exploitation strategy
探索
利用
隨機選擇下一個動作
選擇目前看起來最好的動作
\(\varepsilon -greedy\)
隨機選擇下一個動作
選擇目前看起來最好的動作
花太多時間亂走,難以收斂
可能有其他先苦後甘的選擇
探索-利用策略
exploration-exploitation strategy
\(\varepsilon -greedy\)
\(\varepsilon -greedy\)
有時探索,有時利用
\(\varepsilon\)代表探索比例
\(0\le \varepsilon \le 1\)
探索-利用策略
exploration-exploitation strategy
\(decayed\space\varepsilon -greedy\)
動態的策略
當迭代次數越多
預測的動作價值就會越接近真實值
花在探索上的時間就可以減少
\(decayed\space\varepsilon -greedy\)
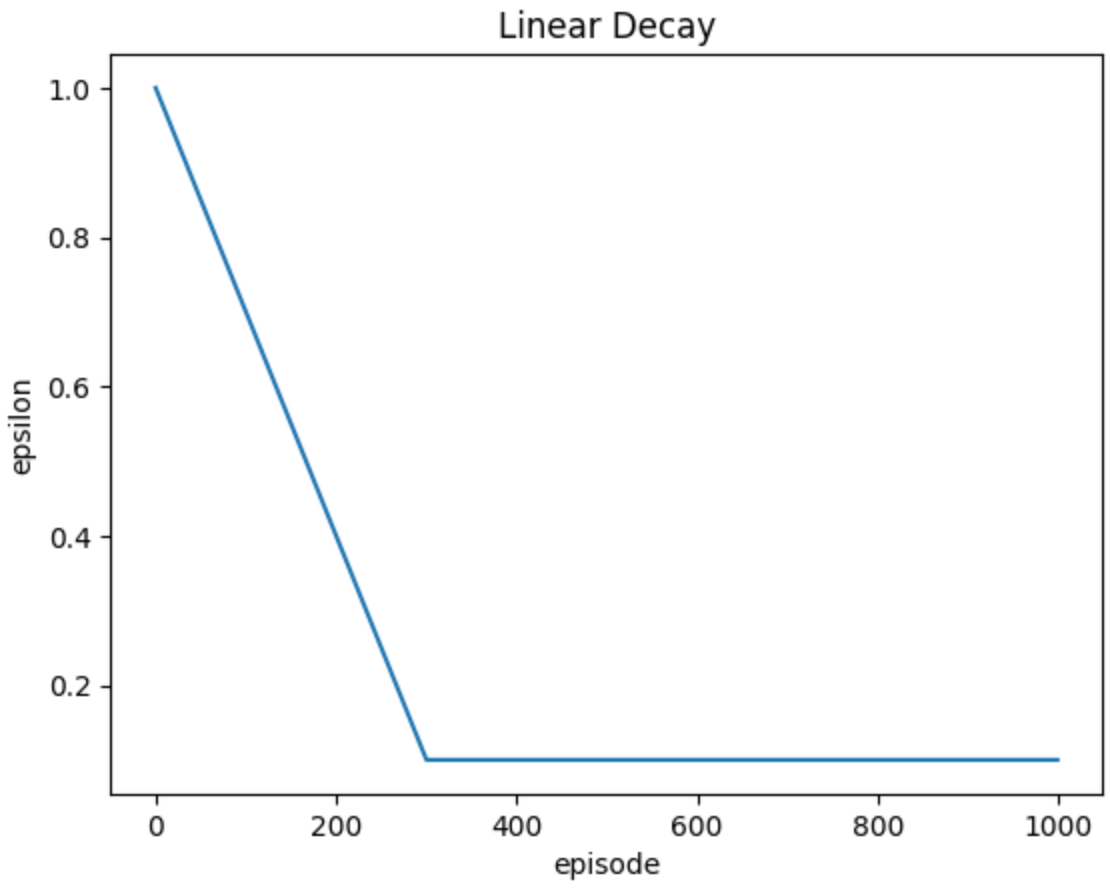
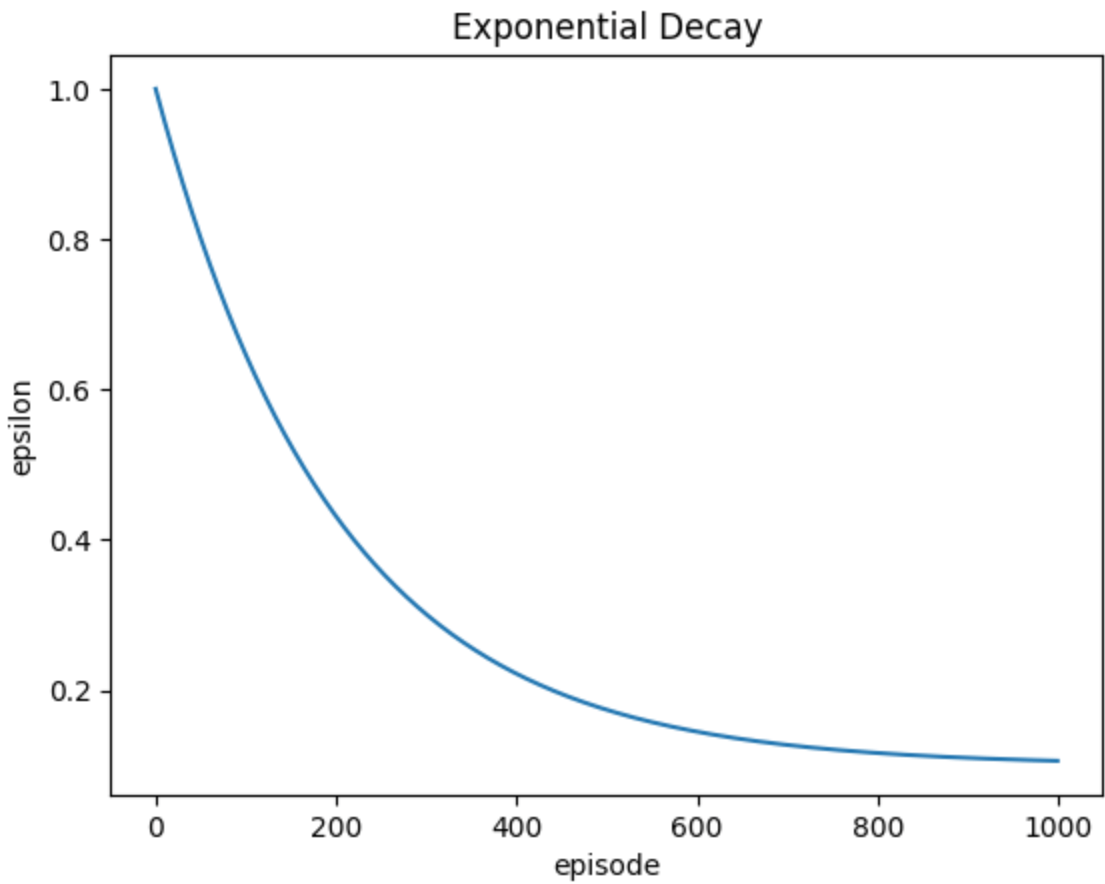
線性衰減
指數衰減
\(\varepsilon_{min}\)
\(decayed\space\varepsilon -greedy\)
\(y=max(1-\frac{1-\varepsilon_{min}}{\varepsilon_{end}}x,\varepsilon_{min})\)
\(y=(1-\varepsilon_{min})e^{\frac{-5x}{n\_episode}}+\varepsilon_{min}\)
Q-Learning
\(On-Policy\)
\(Off-Policy\)
SARSA
Q-Learning
\(On-Policy\)
\(Off-Policy\)
以下一步實際使用的動作之動作價值更新
以下一步最高的
動作價值更新
\(On-Policy\)
\(Off-Policy\)
Q(s,a)=R+\gamma Q'(s',a')
Q(s,a)=R+\gamma max_a Q^*(s',a^*)
其實就是剛剛的作法啦
\(On-Policy\)
人為標註的資料
\(Off-Policy\)
比較謹慎
比較樂觀
收斂較慢
收斂較快
適合真實環境
適合模擬環境
DQN
Deep Q-Network
Q-Table
Neural-Network
\(state\)
\(action\)
NN
\(Q(s,a)\)
\(s_1\)
\(s_2\)
\(s_3\)
\(a_3\)
\(a_2\)
\(a_1\)
\(Q(s_1,a_1)\)
\(Q(s_1,a_2)\)
\(Q(s_1,a_3)\)
\(Q(s_2,a_1)\)
\(Q(s_3,a_1)\)
\(Q(s_2,a_2)\)
\(Q(s_2,a_3)\)
\(Q(s_3,a_2)\)
\(Q(s_3,a_3)\)
\(state\)
NN
\(Q(s,a_1)\)
\(Q(s,a_2)\)
\(\dots\)
\(Q(s,a_n)\)
僅限離散動作
Q-Table
人為標註的資料
DQN
狀態多時很佔記憶體
只需儲存有限參數
只能處理離散狀態
可以處理連續狀態
沒有泛化能力
有泛化能力
ex.圍棋有361個點,每個點有三種狀態
\(3^{361}\)
\(\approx 1.74\times 10^{172}\)
Loss Function
\(TD\_error=reward+\gamma Q(s',a')-Q(s,a)\)
\(L=(reward+\gamma Q(s',a')-Q(s,a))^2\)
DQN的創新
Replay Buffer
每步更新可能會受到資料順序影響
且每筆資料只用一次
太浪費了!
- 把每一步的s,a,r,s'存起來
- 存到一定數量再開始訓練
- 訓練時打亂資料
- 新的資料進來時把舊資料擠出去
Replay Buffer
- 把每一步的s,a,r,s'存起來
- 存到一定數量再開始訓練
- 訓練時打亂資料
- 新的資料進來時把舊資料擠出去
\(s_1,a,r,s_2\)
\(s_2,a,r,s_3\)
\(s_3,a,r,s_4\)
\(s_4,a,r,s_5\)
Replay Buffer
- 把每一步的s,a,r,s'存起來
- 存到一定數量再開始訓練
- 訓練時打亂資料
- 新的資料進來時把舊資料擠出去
\(s_1,a,r,s_2\)
\(s_2,a,r,s_3\)
\(s_3,a,r,s_4\)
\(s_4,a,r,s_5\)
Replay Buffer
- 把每一步的s,a,r,s'存起來
- 存到一定數量再開始訓練
- 訓練時打亂資料
- 新的資料進來時把舊資料擠出去
\(s_2,a,r,s_3\)
\(s_3,a,r,s_4\)
\(s_4,a,r,s_5\)
sample
train
Fixed Q-Target
\(L=(reward+\gamma Q(s',a')-maxQ(s,a))^2\)
同一個神經網路,難收斂
Fixed Q-Target
神經網路
\(s_2,a,r,s_3\)
\(s_3,a,r,s_4\)
\(s_4,a,r,s_5\)
與環境互動取得資料
採樣訓練
Fixed Q-Target
預測網路
目標網路
\(s_2,a,r,s_3\)
\(s_3,a,r,s_4\)
\(s_4,a,r,s_5\)
與環境互動取得資料
採樣訓練
過段時間後再把參數複製給他
Double DQN
\(L=(reward+\gamma maxQ(s',a')-Q(s,a))^2\)
同一個神經網路,難收斂
Bootstrapping
\(L=(reward+\gamma maxQ(s',a')-Q(s,a))^2\)
同一個神經網路,會放大誤差
某處出現高估
較容易用他更新(Q-learning)
傳遞這個高估
過度樂觀
Fixed Q-Target
預測網路
目標網路
\(s_2,a,r,s_3\)
\(s_3,a,r,s_4\)
\(s_4,a,r,s_5\)
與環境互動取得資料
採樣訓練
過段時間後再把參數複製給他
Fixed Q-Target
目標網路
採樣訓練
\(L=(reward+\gamma maxQ(s',a')-Q(s,a))^2\)
還是同一個神經網路
Double DQN
目標網路
採樣訓練
\(L=(reward+\gamma Q(s',a^*)-Q(s,a))^2\)
預測網路
沒有解決,但能緩解
\(a^*=argmax_a\space Q(s',a)\)
Dueling DQN
同樣的問題
不同的解法
\(state\)
\(DQN\)
\(Q(s,a)\)
同樣的問題
不同的解法
\(state\)
\(DQN\)
\(v(s)\)
\(A(s,a)\)
\(Q(s,a)=v(s)+A(s,a)\)
\(v(s)\)
\(A(s,a)\)
狀態價值
優勢函數(相對動作價值)
\(\sum_a A(s,a)=0\)
\(Q(s,a)\)平均值
變得更靈活
要避免Agent只靠\(A(s,a)\)做決策
\(A(s,a)=Q(s,a)-v(s)\)
\(A^*(s,a)=Q^*(s,a)-v^*(s)\)
\(A^*(s,a)=Q^*(s,a)-v^*(s)\)
\(v^*(s)=Q^*(s,a)\)
\(A^*(s,a)=0\)
也就是說讓最大的\(A\)是0
其他的是負的
\(A^*(s,a)=0\)
\(Q(s,a)=v(s)+[A(s,a)-max_a A(s,a)]\)
經過神奇的嘗試發現
\(Q(s,a)=v(s)+[A(s,a)-mean_a A(s,a)]\)
這樣比較好
Copy of 機器學習社課 第八堂
By oct0920




