Let's build our own message streaming platform
Piotr Gankiewicz
# whoami
Hello


+10 YOE
# intro
The origins





# intro
How it started




# iggy
How it's going


iggy.apache.org
Apache Iggy (Incubating)
# iggy
-
Blazingly fast message streaming in Rust
-
TCP, QUIC, HTTP transport protocols
-
Very high throughput and stable P99+
-
+5 GB/s writes & reads on a single node
-
Vibrant community, multiple SDK supported
-
Benchmarking as the first-class citizen
-
Built-in CLI, Web UI and other tooling
Iggy CLI
# iggy
cargo install iggy-cli
Iggy Web UI
# iggy
Iggy Bench CLI
# iggy
Iggy Benchmarks Platform
# iggy
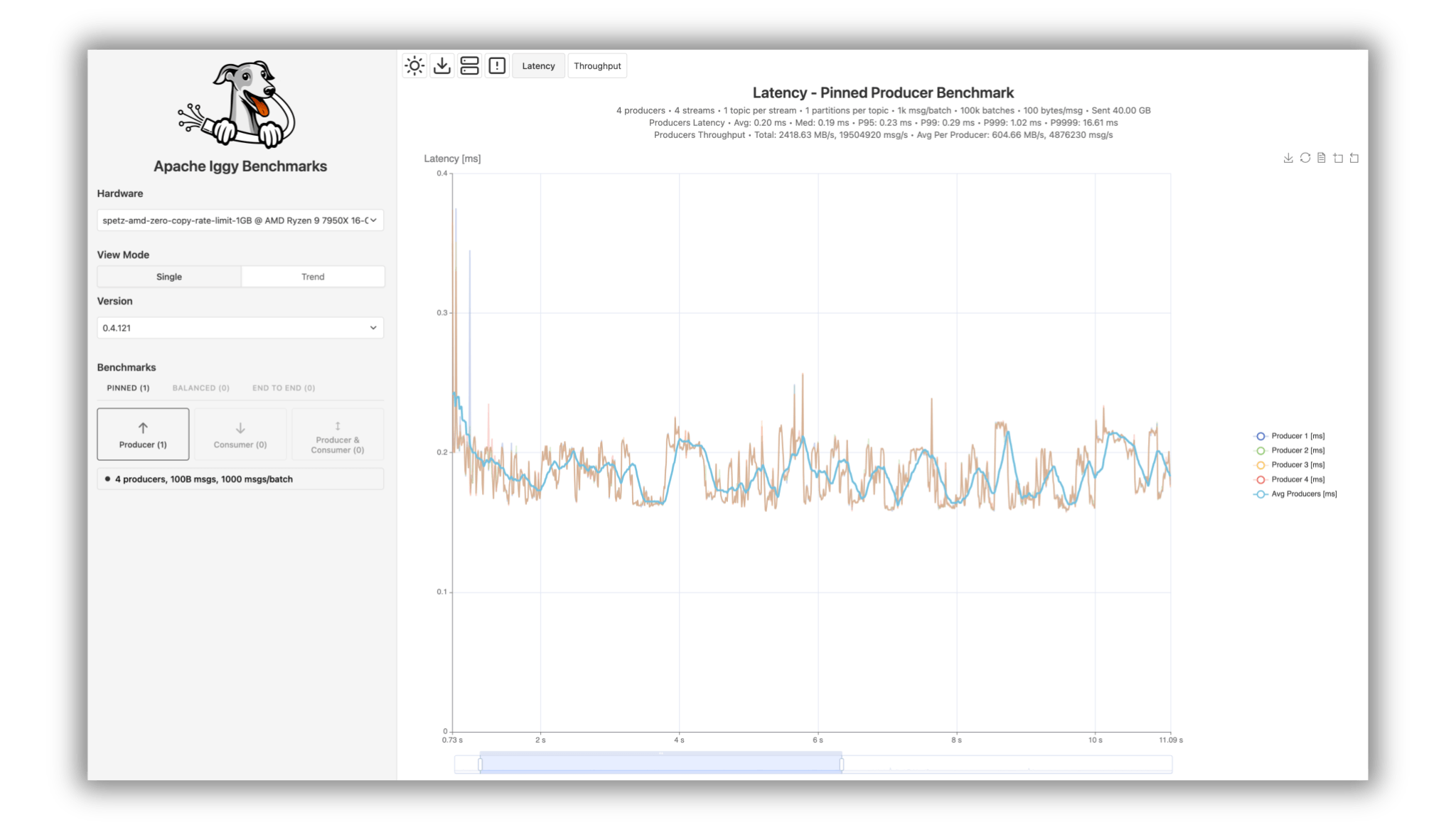
benchmarks.iggy.rs
The Stream
# stream
Stream
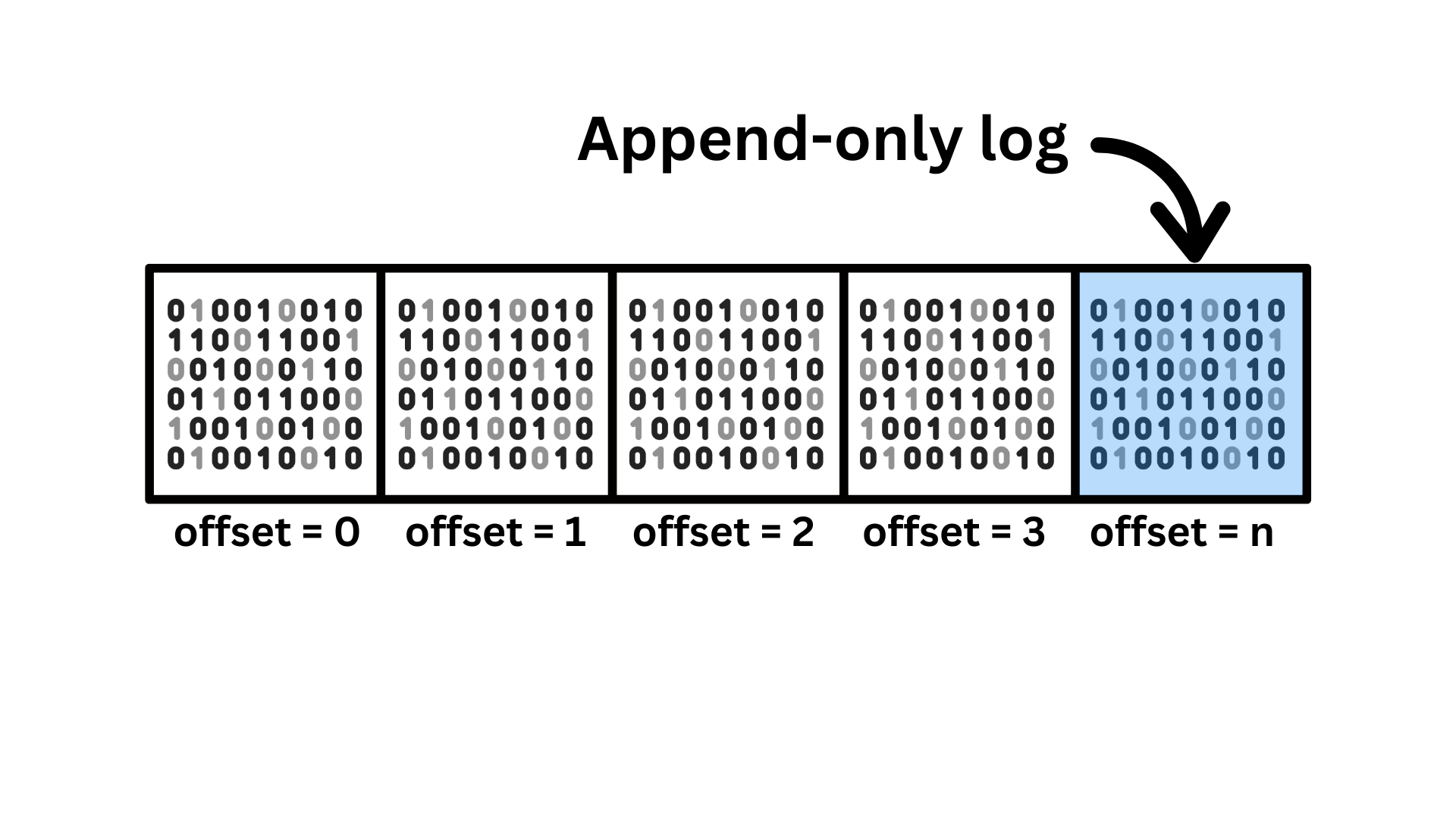
# stream
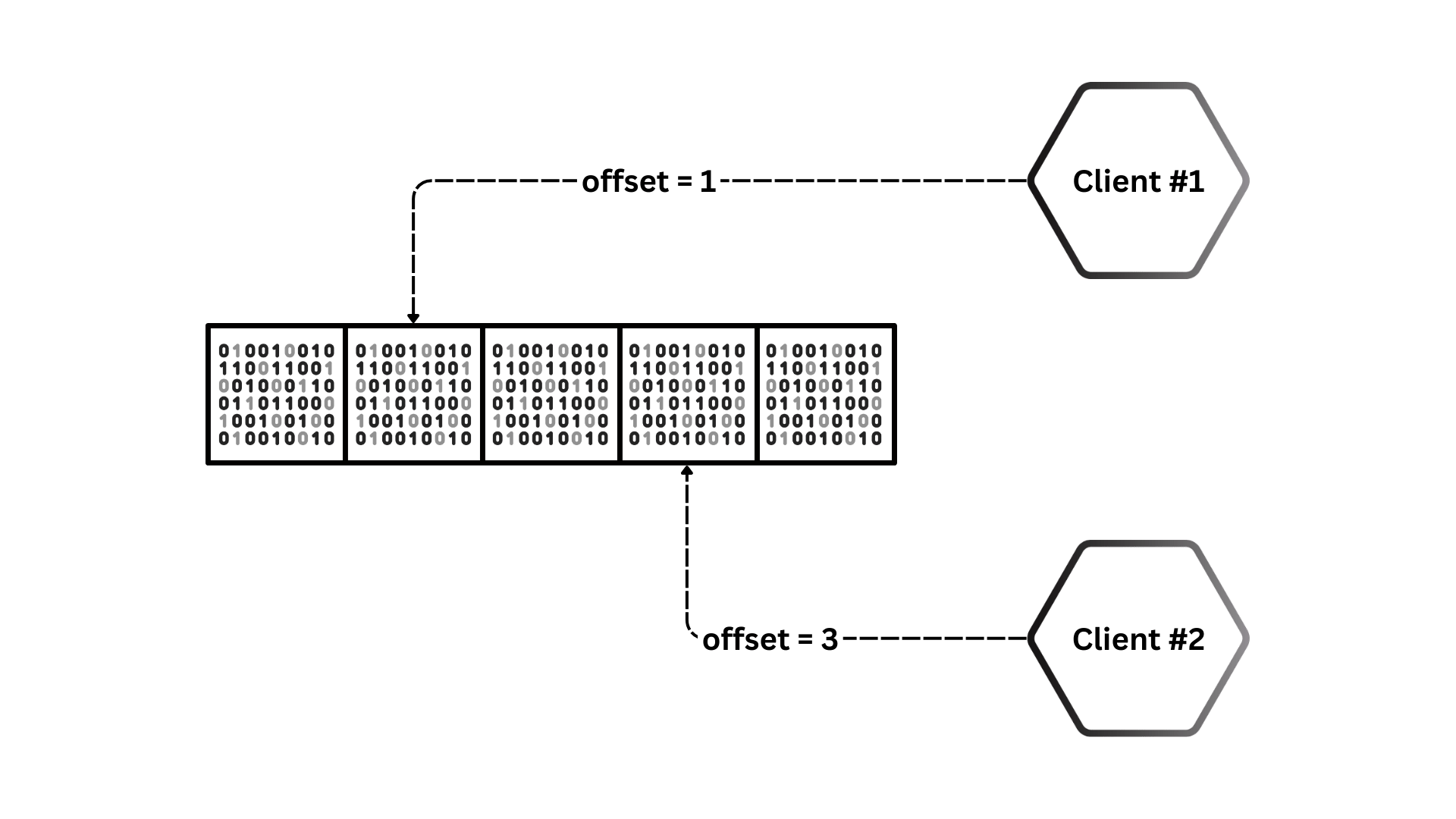
Parallel reads
# build
Talk is cheap, show me the code

# build
Hello world
struct Stream {
id: u32,
offset: u64,
path: String
}
struct Message {
offset: u64,
payload: Vec<u8>
}# build
Reads & writes
impl Stream {
fn append(&mut self, message: Message) {
// TODO: Persist the append-only data
}
fn poll(&self, offset: u64, count: u64) -> Vec<Message> {
// TODO: Load the persisted data by offset
}
}# build
Serialization
impl Message {
fn as_bytes(&self) -> Vec<u8> {
let mut bytes = vec![];
bytes.put_u64(self.offset);
bytes.put_u32(self.payload.len());
bytes.put(&self.payload);
bytes
}
}# build
Deserialization
impl Message {
fn from_bytes(bytes: &[u8]) -> Message {
let offset = bytes[0..8].into();
let length = bytes[8..12].into();
let payload = bytes[12..12 + length].to_vec();
Message {
offset,
payload
}
}
}# build
hexdump
|................|
|....hello.......|
|.............wor|
|ld|
00 00 00 00 00 00 00 00 01 00 00 00 00 00 00 00
05 00 00 00 68 65 6c 6c 6f 01 00 00 00 00 00 00
00 02 00 00 00 00 00 00 00 05 00 00 00 77 6f 72
6c 64 # build
File storage
impl Stream {
async fn append(&mut self, message: Message) {
self.offset += 1;
message.offset = self.offset;
let bytes = message.as_bytes();
let mut file = file::open(&self.path).await;
file.write_all(&bytes).await;
}
}# build
Durable file storage
impl Stream {
async fn append(&mut self, message: Message) {
self.offset += 1;
message.offset = self.offset;
let bytes = message.as_bytes();
let mut file = file::open(&self.path).await;
file.write_all(&bytes).await;
file.sync_all().await;
}
}# build
fsync
"This frequency of application-level fsyncs has a large impact on both latency and throughput. Setting a large flush interval will improve throughput as the operating system can buffer the many small writes into a single large write."
# build
Messages batching
async fn append(&mut self, messages: Vec<Message>) {
for message in message {
self.unsaved_messages.push(message);
}
if self.unsaved_messages.len() < 1000 {
return;
}
let mut bytes = vec![];
for message in self.unsaved_messages {
bytes.put(message.as_bytes());
}
file.write_all(&bytes).await;
file.sync_all().await; // fsync() here?
self.unsaved_messages.clear();
}# build
Background saver
spawn(async move {
let mut interval = interval(Duration::from_secs(5));
loop {
interval.tick().await;
stream.persist_unsaved_messages().await; // fsync()
}
}# build
Clustering
-
Replicate the data across multiple nodes
-
Provide high-availability & reliability
-
Results in additional complexity
-
Might have an impact on the latency
-
Raft, Viewstamped Replication etc.
-
Probably not within the scope of this talk :)
# build
Reading the data at any offset
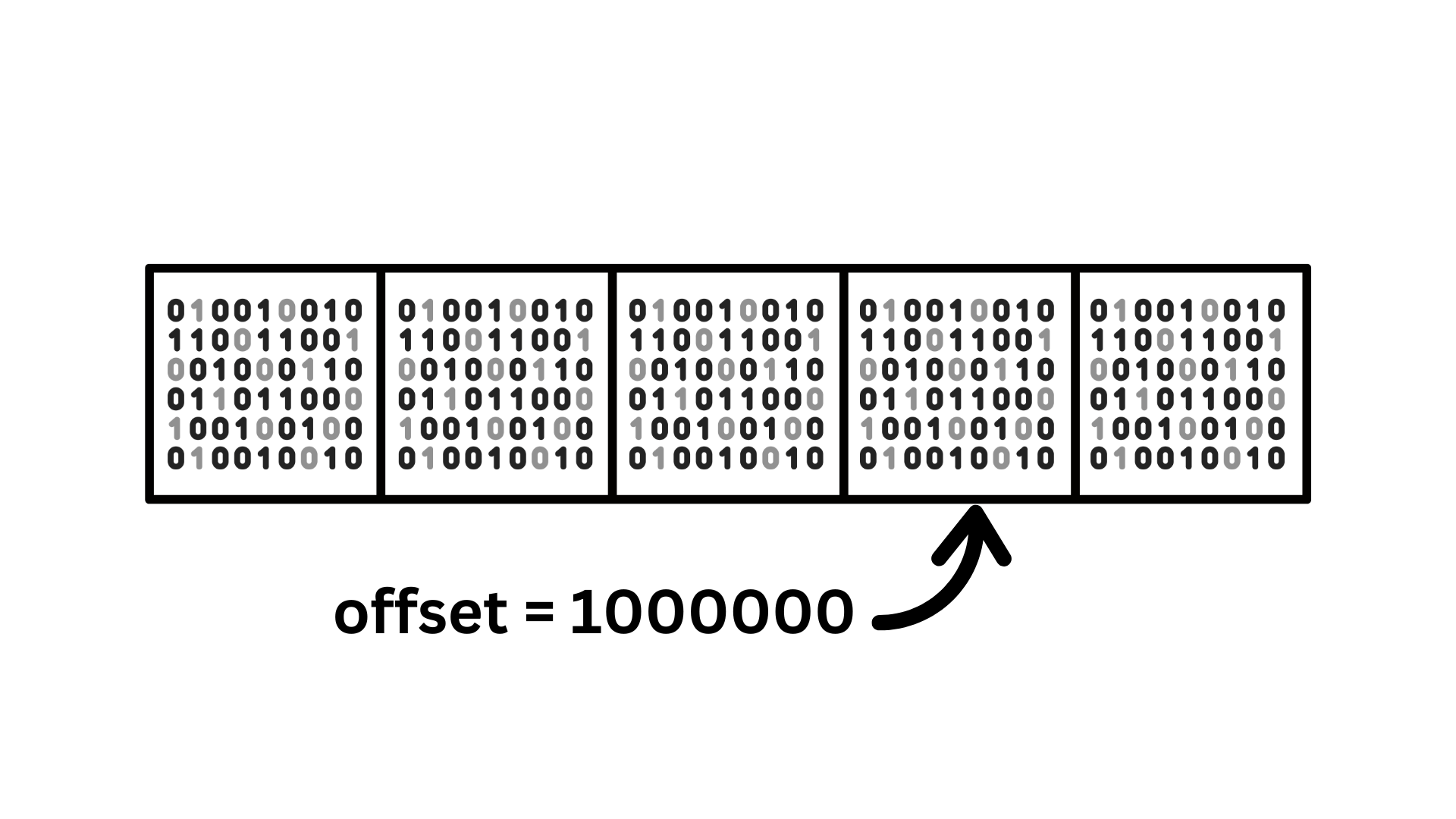
# build
Index - the offset position

# build
Storing the index
async fn append(&mut self, message: Message) {
// ... previous stuff
self.position += bytes.len(); // Message as bytes
let mut file = file::open(&self.index_path).await;
file.write_u32(self.position).await;
}# build
Reading the index
async fn poll(&self, offset: u64, count: u64) -> Vec<Message> {
let file = file::open(&self.index_path).await;
file.seek(SeekFrom::Start(4 * offset)).await;
let position = file.read_u32().await;
let file = file::open(&self.stream_path).await;
file.seek(SeekFrom::Start(position)).await;
// Load N messages based on the count
}Networking
# network
Let there be network
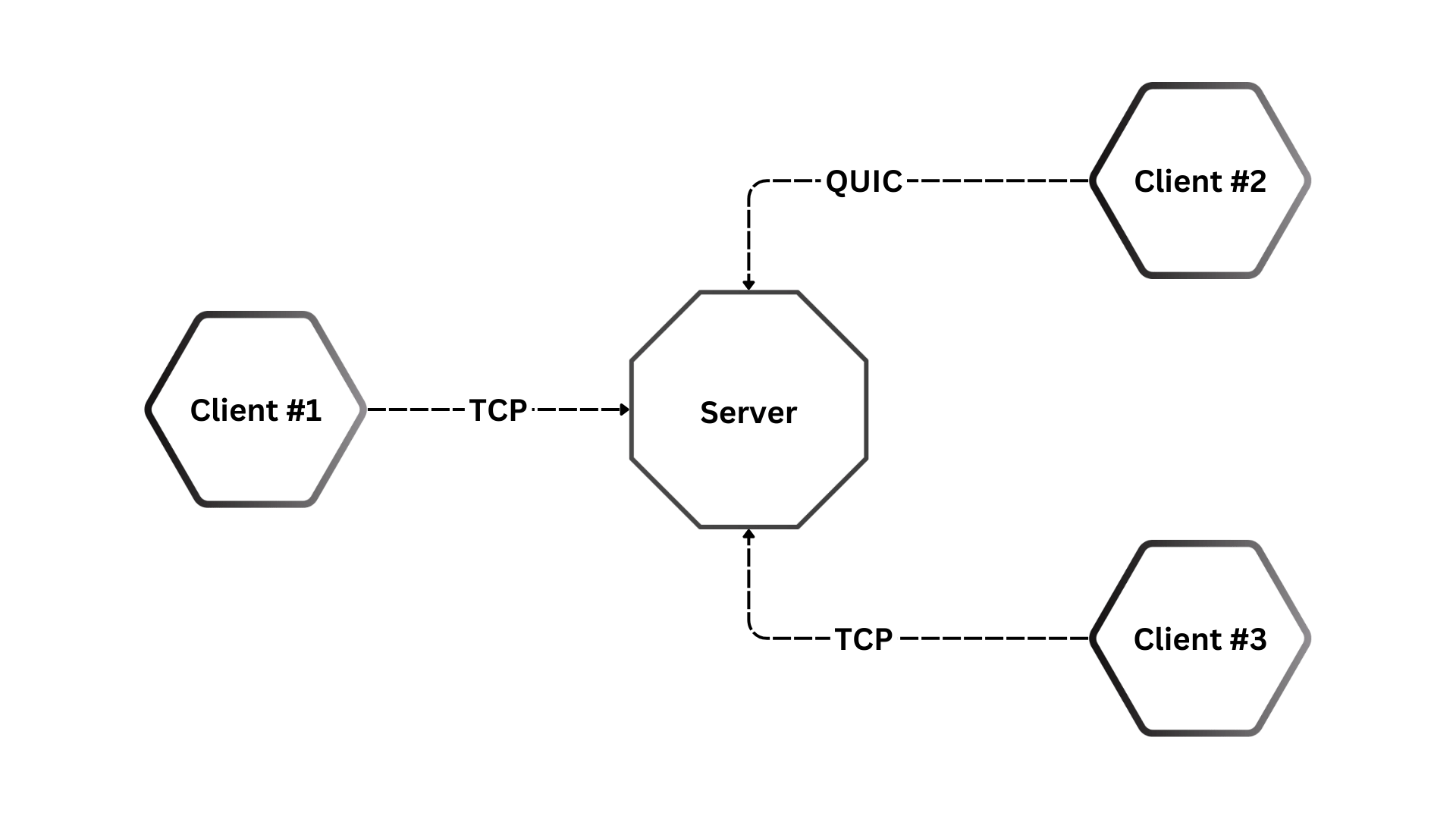
# network
Multiple streams support
struct Server {
streams: HashMap<u32, Stream>,
clients: HashMap<u32, Client>,
}
impl Server {
async fn append(&self, stream_id: u32, message: Message) {
let stream = self.get_stream(stream_id);
stream.append(message).await
}
async fn poll(&self, stream_id: u32, offset: u64, count: u64) -> Vec<Message> {
let stream = self.get_stream(stream_id);
stream.poll(offset, count).await
}
}# network
Parallel writes & reads
struct Server {
streams: HashMap<u32, Arc<RwLock<Stream>>>,
clients: HashMap<u32, Client>,
}
impl Server {
async fn append(&self, stream_id: u32, message: Message) {
let stream = self.get_stream(stream_id);
let stream = stream.write().await; // Acquire write lock
stream.append(message).await
}
async fn poll(&self, stream_id: u32, offset: u64, count: u64) -> Vec<Message> {
let stream = self.get_stream(stream_id);
let stream = stream.read().await; // Acquire read lock
stream.poll(offset, count).await
}
}# network
Partitioning
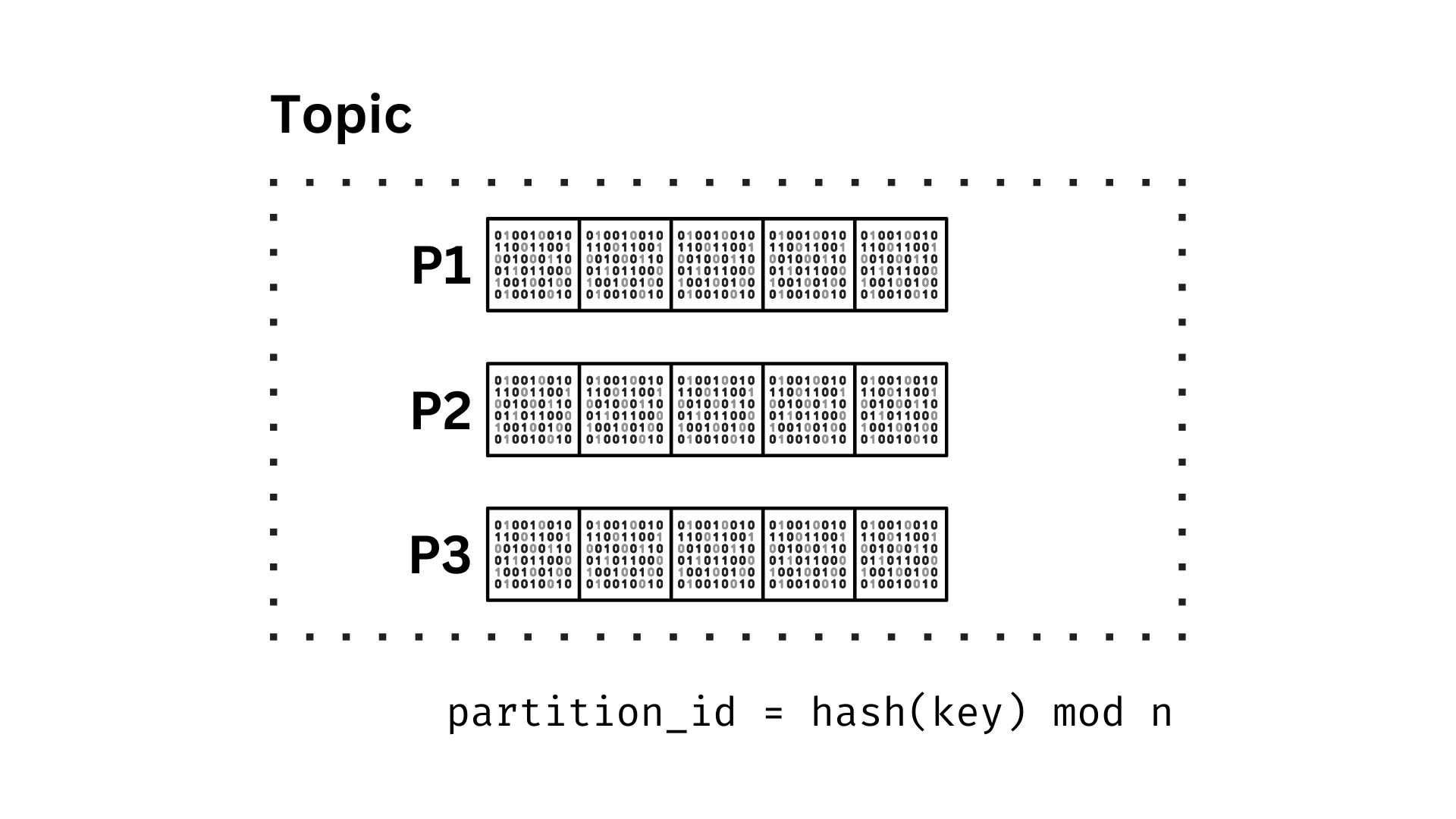
# network
Partitioning
struct Topic {
id: u32,
path: String,
partitions: HashMap<u32, Partition>
}
struct Partition {
id: u64,
offset: u64,
path: String
}# network
Partitioning
struct Server {
topics: HashMap<u32, Arc<RwLock<Topic>>>,
clients: HashMap<u32, Client>
}
struct Topic {
id: u32,
path: String,
partitions: HashMap<u32, Partition>
}# network
Partitioning
struct Server {
topics: HashMap<u32, Topic>,
clients: HashMap<u32, Client>
}
struct Topic {
id: u32,
path: String,
partitions: HashMap<u32, Arc<RwLock<Partition>>>
}Performance
Zero-copy (de)serialization
-
Regular (de)serialization consists of 2 stages
-
Break down a model into serializable types
-
Serialization of the types using given format
-
-
Read + Parse + Reconstruct
-
Zero-copy directly references these bytes
-
Deserialization is just casting the pointer
-
&[u8] -> &T (without an additional cost)
# performance
How to zero-copy?
-
Just use (github.com/rkyv/rkyv)
-
Mom, we have zero-copy at home

# performance
let mut pos = 0;
while position < slice.len() {
let offset = u64::from_le_bytes(slice[pos..pos+8].try_into()?);
pos += 8;
let payload_length = u64::from_le_bytes(slice[pos..pos+8].try_into()?);
pos += 8;
let payload = &slice[pos..pos + payload_length as usize];
position += payload_length as usize;
let message: MessageView<'_> = MessageView::new(offset, payload);
}How to zero-copy?
# performance
fn write_value_at<const N: usize>(slice: &mut [u8],
value: [u8; N], position: usize) {
let slice = &mut slice[position..position + N];
let ptr = slice.as_mut_ptr();
unsafe {
std::ptr::copy_nonoverlapping(value.as_ptr(), ptr, N);
}
}# performance
User vs Kernel space
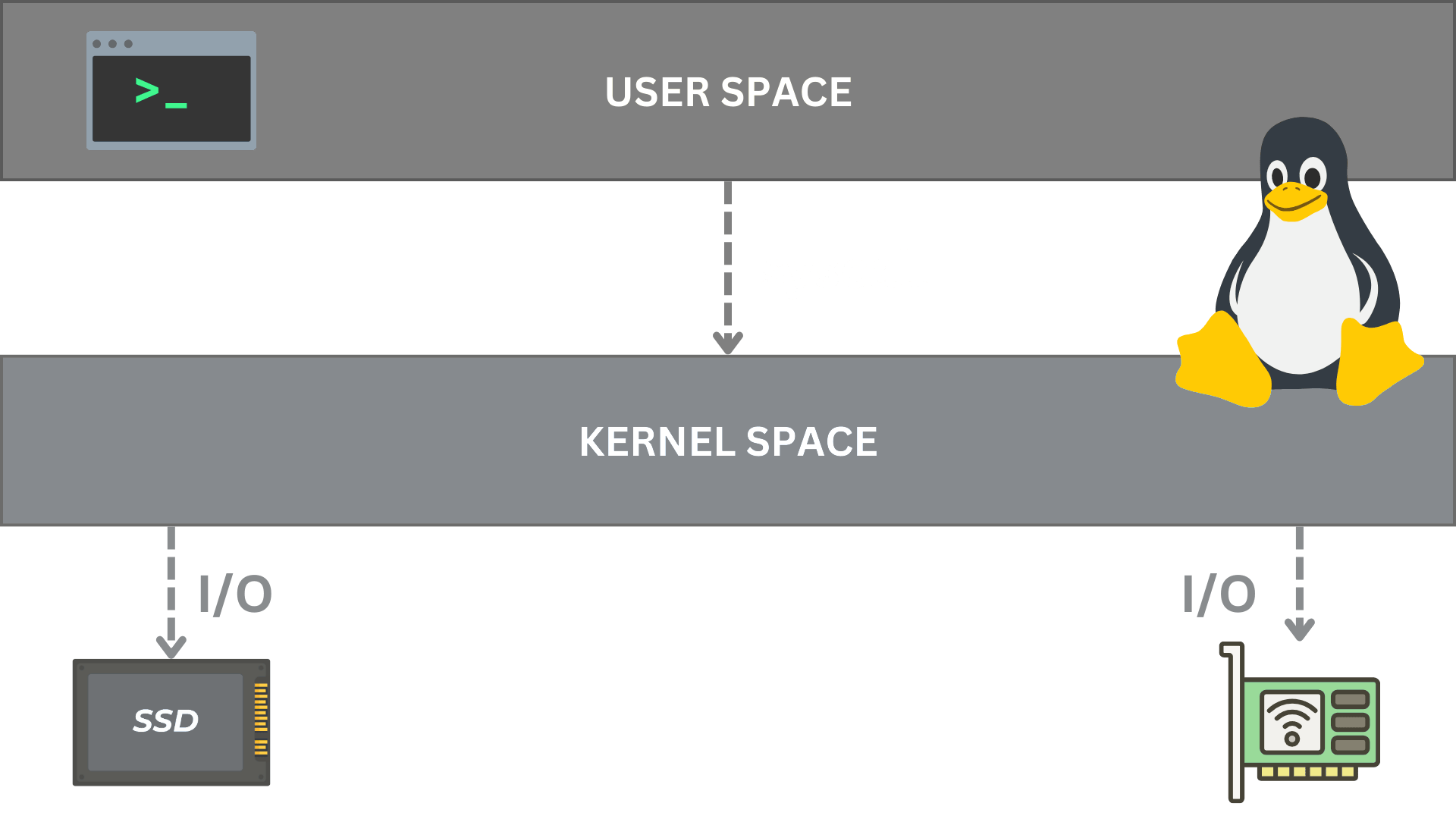
Syscalls
impl Stream {
async fn append(&mut self, message: Message) {
self.offset += 1;
message.offset = self.offset;
let bytes = message.as_bytes();
// 1. Open file
let mut file = file::open(&self.path).await;
// 2. Write to file
file.write_all(&bytes).await;
} // 3. Close file
}# performance
ulimit
"Kafka uses a very large number of files and a large number of sockets to communicate with the clients.
All of this requires a relatively high number of available file descriptors."
"You should increase your file descriptor count to at least 100,000, and possibly much more."
# performance
io_uring
-
New, asynchronous I/O for Linux
-
An alternative for epoll, kqueue, aio
-
Unified interface for network & storage
-
Reduces syscalls and context switches
-
Allows batching multiple calls as a single one
-
Readiness-based vs Completion-based I/O
-
Battle-tested solution (TigerBeetle and others)
# performance
io_uring
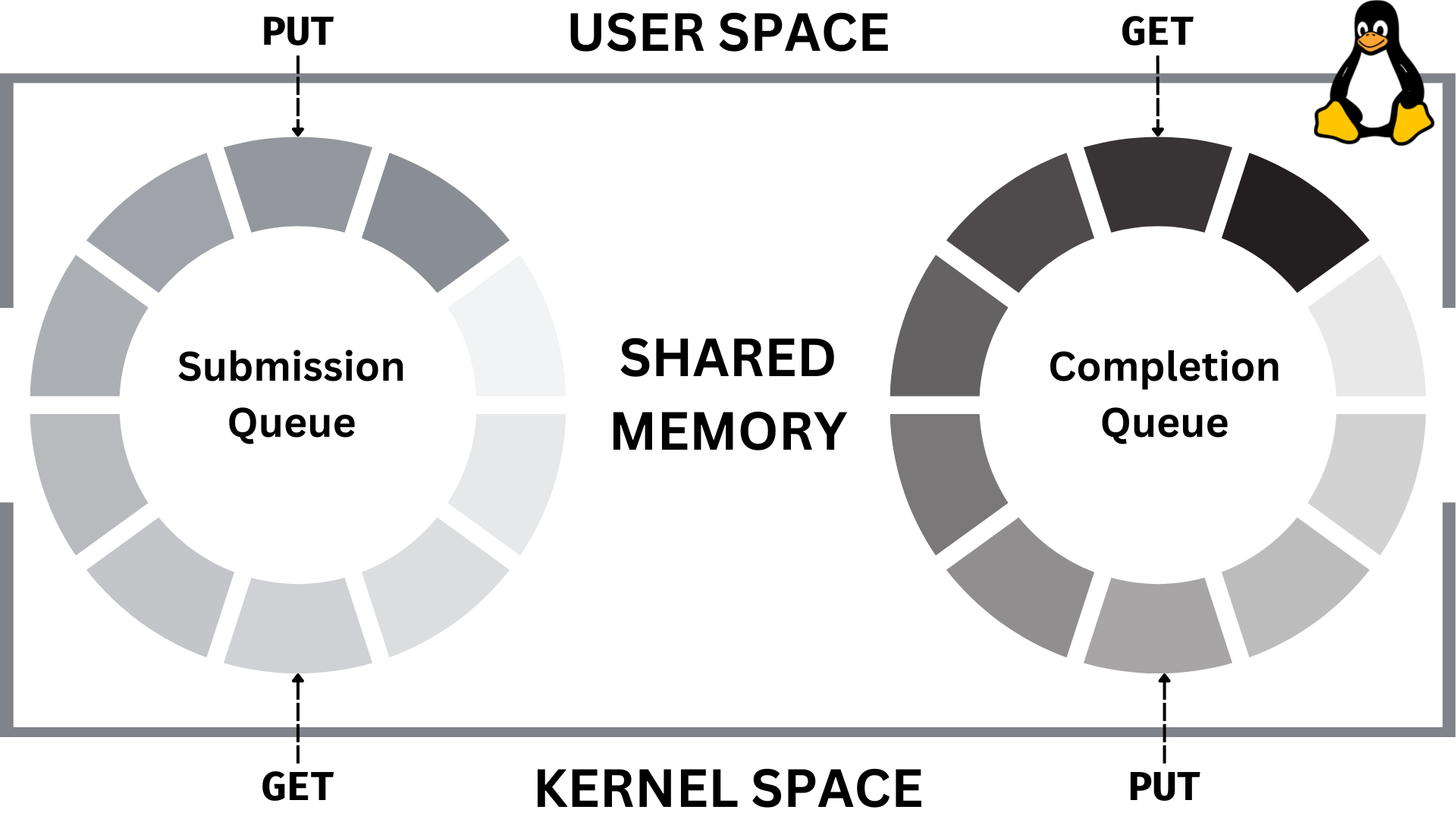
# performance
monoio
let file = file::open(&self.path).await?;
let mut position = 0;
let buffer = Vec::with_capacity(4);
let (result, buffer) = file.read_exact_at(buffer, position).await;
if result.is_err() {
return Err(Error::InvalidOffset);
}
let offset = u32::from_le_bytes(buffer.try_into()?);
position += 4;# performance
DirectIO
-
Bypass kernel page cache via DMA
-
Reduce unnecessary memory copies
-
Lower and more predictable (tail) latencies
-
Better CPU & RAM utilization
-
Fsyncgate - errors on fsync are unrecovarable
-
Doesn't play too well with Tokio...
# performance
DirectIO
const O_DIRECT = 0x4000;
const O_DSYNC = 0x4096;
const ALIGNED_SIZE = 512;
let file = std::fs::File::options()
.read(true)
.write(true)
.custom_flags(O_DIRECT | O_DSYNC)
.open(self.file_path);# performance
Context switch

# performance
Context switch
impl Stream {
async fn append(
&self,
partition_id: u32,
message: Message
) {
let partition = self.get_partition(partition_id);
// Maybe a context switch if lock is contended
let partition = partition.write().await;
// Context switch due to async
partition.append(message).await
}
}# performance
Work stealing
# performance
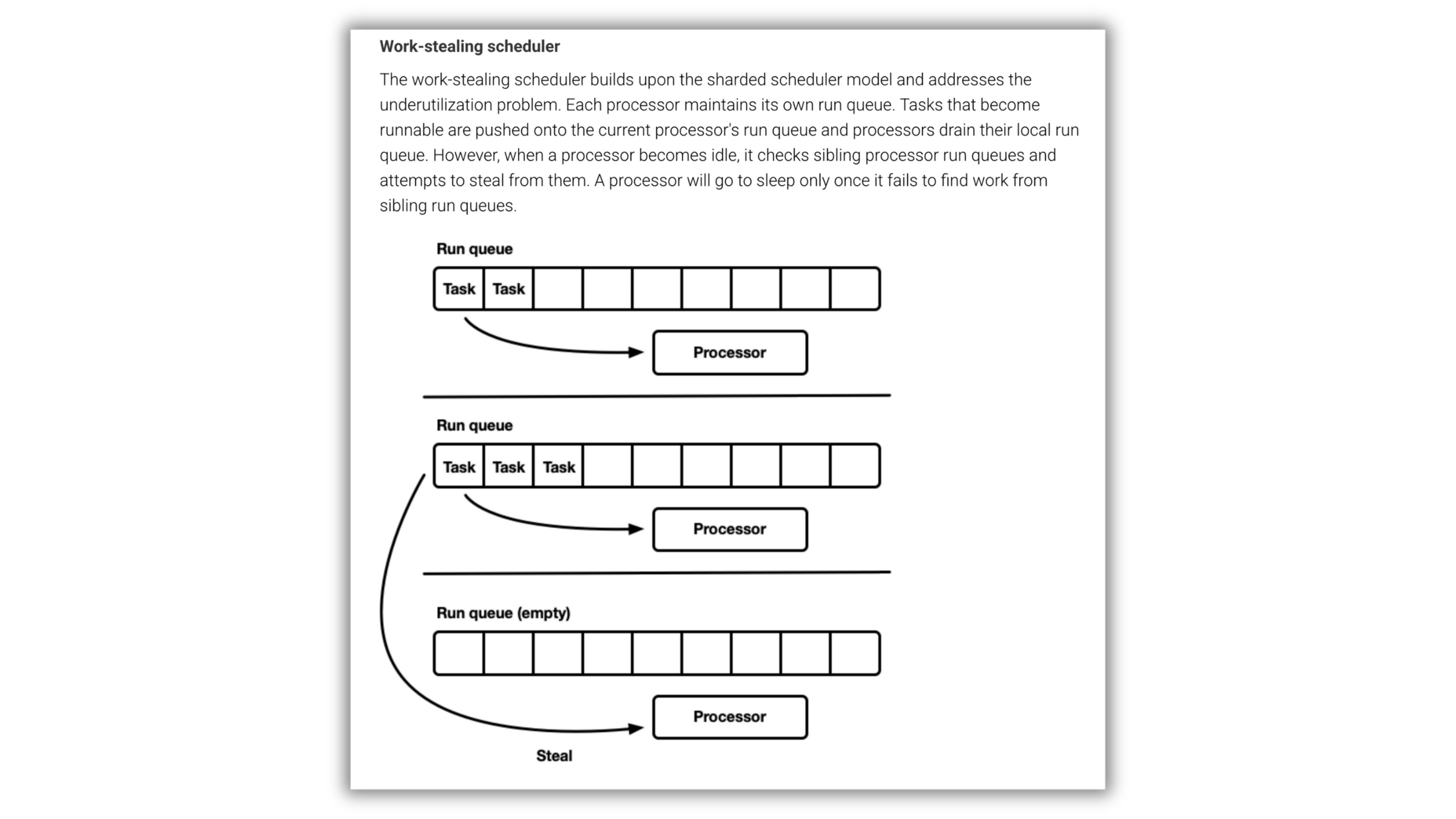
https://tokio.rs/blog/2019-10-scheduler
Thread affinity & Thread-per-core
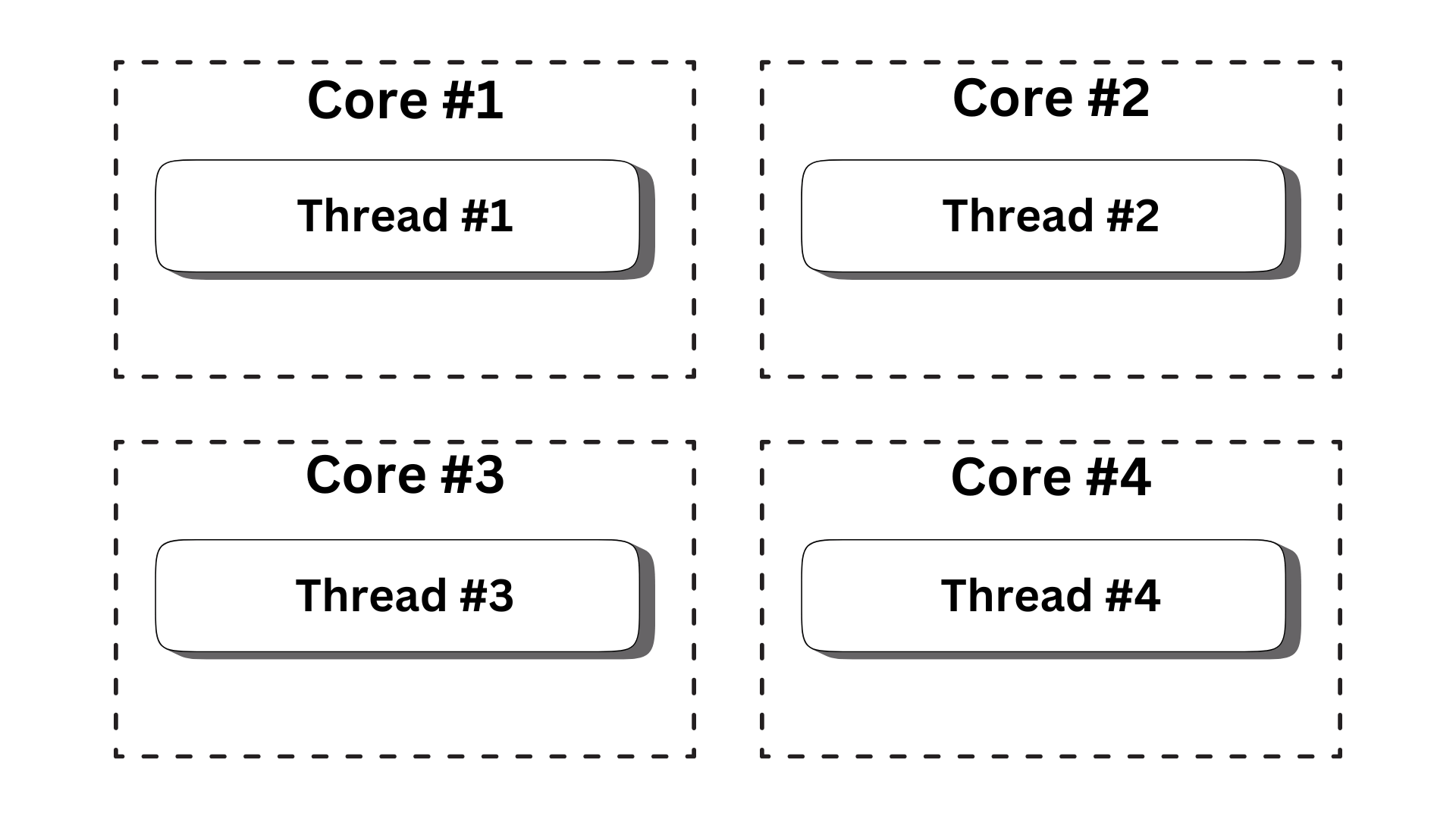
# performance
Shared Nothing
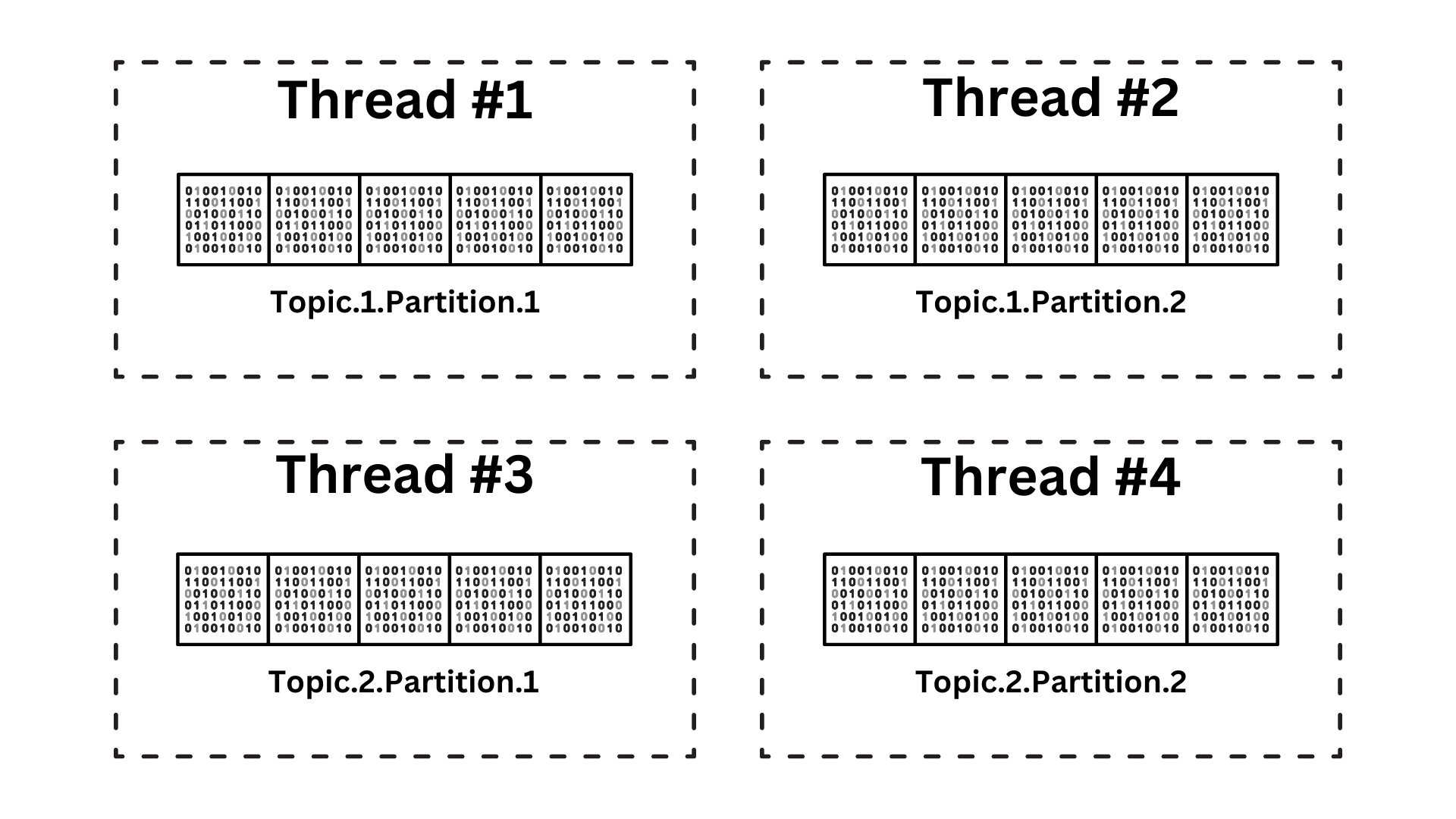
# performance
monoio
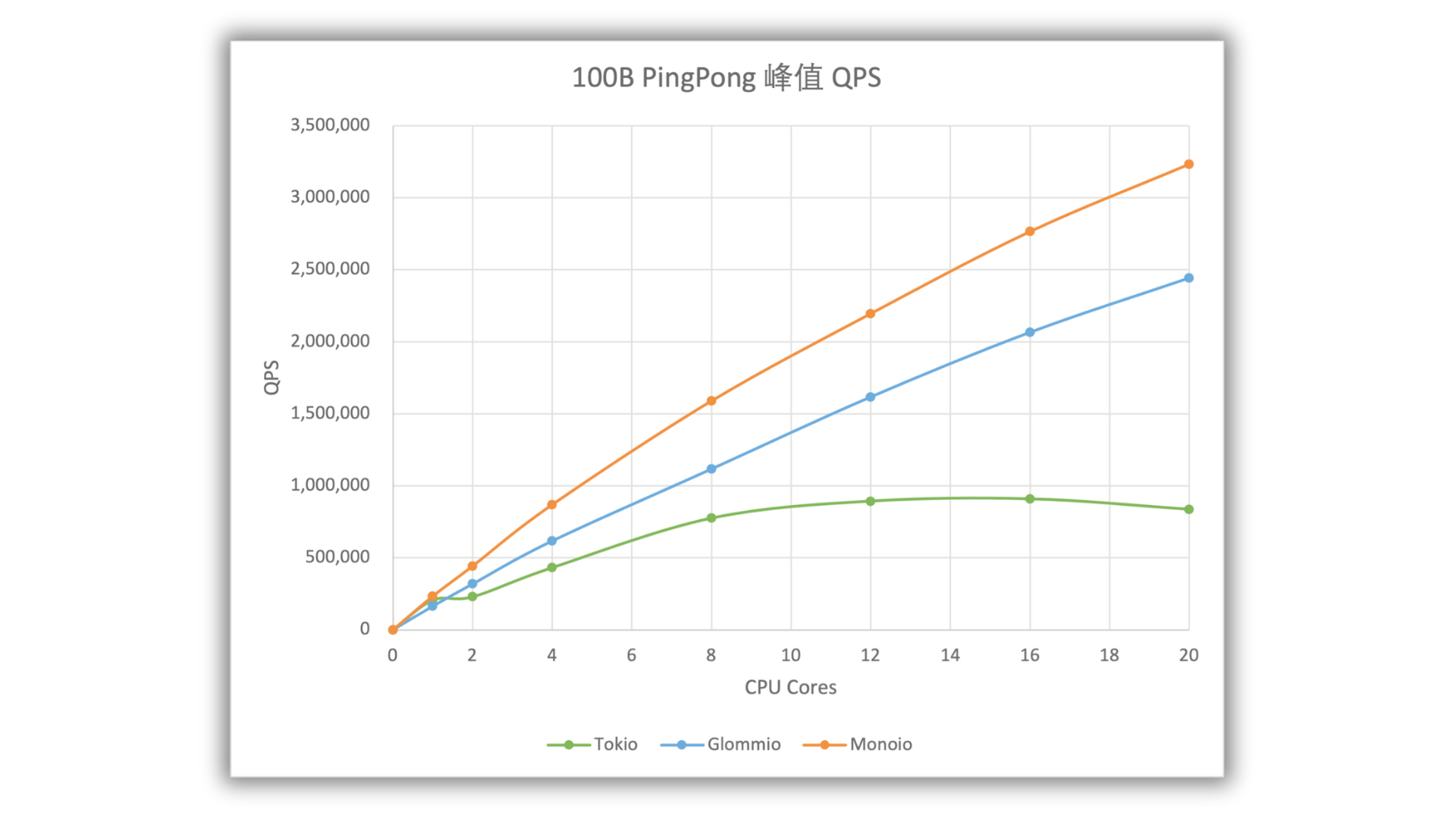
# performance
Optimization rabbit hole
-
Kernel bypass
-
DPDK
-
eBPF
-
Just to name a few :)
# performance
# thanks


https://spetz.github.io/posts/rustikon-2025/
Rustikon 2025
By Piotr Gankiewicz

