

















Renato Cordeiro Ferreira
Scientific Programmer @ JADS | PhD Candidate @ USP | Co-founder & Coordinator @CodeLab
Making a Pipeline Production-Ready
https://renatocf.xyz/sadis25-slides
2025
Renato Cordeiro Ferreira
Institute of Mathematics and Statistics (IME)
University of São Paulo (USP) – Brazil
Jheronimus Academy of Data Science (JADS)
Technical University of Eindhoven (TUe) / Tilburg University (TiU) – The Netherlands
Paper
Slides
Challenges and Lessons Learned in the Healthcare Domain
Former Principal ML Engineer at Elo7 (BR)
4 years of industry experience designing, building, and operating ML products with multidisciplinary teams
B.Sc. and M.Sc. at University of São Paulo (BR)
Theoretical and practical experience with Machine Learning and Software Engineering
Scientific Programmer at JADS (NL)
Currently participating in the MARIT-D European project, using ML techniques for more secure seas
Ph.D. candidate at USP + JADS (BR + NL)
Research about SE4AI, in particular about MLOps and the software architecture of ML-Enabled Systems
Renato Cordeiro Ferreira
https://renatocf.xyz/contacts
Renato Cordeiro Ferreira
Lucas Quaresma Lam
Daniel Lawand
renatocf@ime.usp.br
lucasqml08@alumni.usp.br
daniel.lawand@alumni.usp.br
Alfredo Goldman
gold@ime.usp.br
Marcelo Finger
mfinger@ime.usp.br
Roberto Oliveira Bolgheroni
robertobolgheroni@alumni.usp.br
Our paper describes
challenges and lessons learned
on evolving the training pipeline of SPIRA:
from a BIG BALL OF MUD (v1)
to a MODULAR MONOLITH (v2)
to a set of MICROSERVICES (v3).
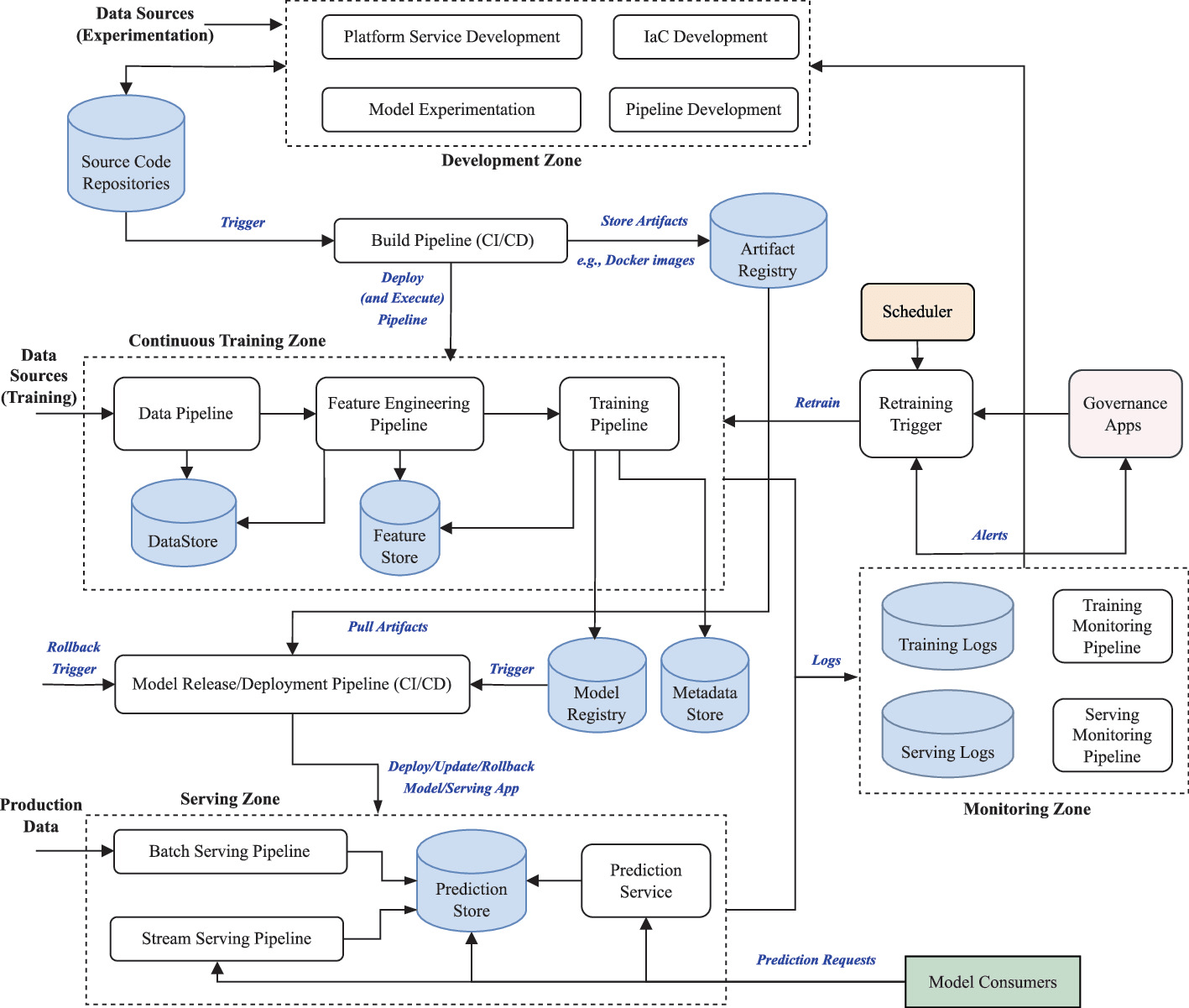
System
Architecture
Research Track - ECSA 2025
MLOps in Practice: Requirements and a Reference Architecture from Industry
Doctoral Symposium - CAIN 2025
A Metrics-Oriented Architectural Model
to Characterize Complexity on
Machine Learning-Enabled Systems
Doctoral Symposium - CAIN 2025
A Metrics-Oriented Architectural Model
to Characterize Complexity on
Machine Learning-Enabled Systems
Data Collection App
Scientific Initiation 2021
Francisco Wernke
Streaming
Prediction Server
+ Client API / App
Capstone Project 2022
Vitor Tamae
Highly Availability
with Kubernetes
Capstone Project 2023
Vitor Guidi
Redesign Continuous Training Subsystem
Capstone Project 2023
Daniel Lawand
CI/CD/CD4ML on
Training Pipeline
Capstone Project 2024
Lucas Quaresma
+ Roberto Bolgheroni
Pipeline
Reimplementation
random.seed(c.train_config["seed"])
torch.manual_seed(c.train_config["seed"])
torch.cuda.manual_seed(c.train_config["seed"])
np.random.seed(c.train_config["seed"])
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
self.c = c
self.ap = ap
self.train = train
self.test = test
self.test_insert_noise = test_insert_noise
self.num_test_additive_noise = num_test_additive_noise
self.num_test_specaug = num_test_specaug
self.dataset_csv = \
c.dataset["train_csv"] if train else c.dataset["eval_csv"]
assert os.path.isfile(self.dataset_csv), \
"Test or Train CSV file don't exists! Fix it in config.json")
accepted_tc = [ 'overlapping', 'padding', 'one_window' ]
assert self.c.dataset['temporal_control'] in accepted_tc), \
"You cannot use the padding_with_max_length option with the \
split_wav_using_overlapping option, disable one of them !!")
self.control_class = c.dataset['control_class']
self.patient_class = c.dataset['patient_class']
self.dataset_list = \
pd.read_csv(self.dataset_csv, sep=',') \
.replace({'?': -1}) \
.replace({'negative': self.control_class}, regex=True) \
.replace({'positive': self.patient_class}, regex=True) \
.values
Misplaced
Responsabilities
Lines 1-7 handle random number generation
Lines 8-16 assign values to
attributes
Lines 18-19 and 22-24
handle assertions
Line 30 handles data loading
# Setup
config_path = ValidPath.from_str("/app/spira/spira.json")
config = load_config(config_path)
operation_mode = OperationMode.TRAIN
randomizer = initialize_random(config, operation_mode)
# Data Loading
patients_paths = read_valid_paths_from_csv(config.patients_csv)
controls_paths = read_valid_paths_from_csv(config.controls_csv)
noises_paths = read_valid_paths_from_csv(config.noises_csv)
patients_inputs = Audios.load(
patients_paths, config.audio, config.dataset
)
controls_inputs = Audios.load(
controls_paths, config.audio, config.dataset
)
noises = Audios.load(noises_paths, config)
noises_path, config.audio, config.dataset
)
# Feature Engineering
audio_processor = create_audio_processor(config.audio)
patient_feature_transformer = create_audio_feature_transformer(
randomizer, audio_processor, config, noises,
)
control_feature_transformer = create_audio_feature_transformer(
randomizer, audio_processor, config, noises,
)
Design-Pattern
Modularization
Lines 15-23 handles data loading by using the
Audio ADAPTER
Line 27 builds an audio_processor via a CHAIN OF RESPONSIBILITY
Lines 29-34 build two
feature_transformer's
via a STRATEGY
By bringing ML Engineers to
work with Data Scientists and
employing automated testing
since the beginning,
projects may reach production sooner
Making a Pipeline Production-Ready
https://renatocf.xyz/sadis25-slides
2025
Renato Cordeiro Ferreira
Institute of Mathematics and Statistics (IME)
University of São Paulo (USP) – Brazil
Jheronimus Academy of Data Science (JADS)
Technical University of Eindhoven (TUe) / Tilburg University (TiU) – The Netherlands
Paper
Slides
Challenges and Lessons Learned in the Healthcare Domain
By Renato Cordeiro Ferreira
Deploying a Machine Learning (ML) training pipeline into production requires good software engineering practices. Unfortunately, the typical data science workflow often leads to code that lacks critical software quality attributes. This experience report investigates this problem in SPIRA, a project whose goal is to create an ML-Enabled System (MLES) to pre-diagnose insufficiency respiratory via speech analysis. This paper presents an overview of the architecture of the MLES, then compares three versions of its Continuous Training subsystem: from a proof of concept Big Ball of Mud (v1), to a design pattern-based Modular Monolith (v2), to a test-driven set of Microservices (v3). Each version improved its overall extensibility, maintainability, robustness, and resiliency. The paper shares challenges and lessons learned in this process, offering insights for researchers and practitioners seeking to productionize their pipelines.




