


Sarah Dean PRO
asst prof in CS at Cornell
Fall 2025, Prof Sarah Dean
Please open a large, searchable text document on your laptop or phone
described in "A Mathematical Theory of Communication" (Shannon, 1948)
and in The Hedgehog Review article Language Machinery
exercise inspired by Jordan Ellenberg
"What we do"
(for now, assume \(\mathcal S\) is never empty)
"What we do"
"Why we do it"
$$\min_{\Theta\in \mathbb R^{|\mathcal X|\times |\mathcal X|}} \sum_{k=1}^{K_i-1} \sum_{i=1}^n \|\Theta^\top e_{x_{k,i}} - e_{x_{k+1,i}}\|_2^2$$
$$\min_{\Theta\in \mathbb R^{|\mathcal X|\times |\mathcal X|}} \sum_{k=1}^{K_i-1} \sum_{i=1}^n \|\Theta^\top e_{x_{k,i}} - e_{x_{k+1,i}}\|_2^2$$
Fact 1: Predicting \(\hat x_{t+1}=\max_x (\hat \Theta^\top e_{x_t})_x\) is equivalent to bigram prediction, i.e. choosing the mode of \(\mathcal S = \{x_{k+1,i} | x_{k,i} = x_{t}\}\)
Fact 2: Sampling \(\hat x_{t+1}\sim \hat \Theta^\top e_{ x_t}\) is equivalent to bigram generation, i.e. choosing uniformly at random from \(\mathcal S=\{x_{k+1,i} | x_{k,i} = x_{t}\}\)
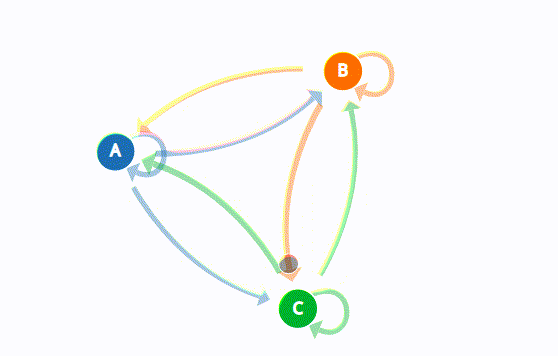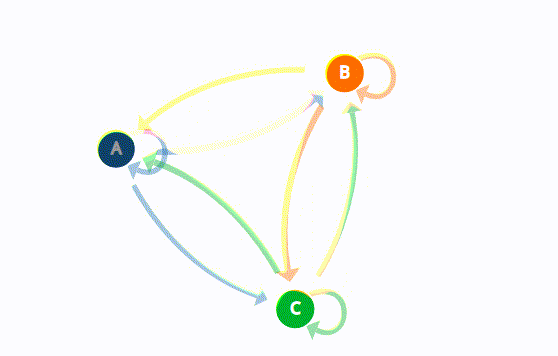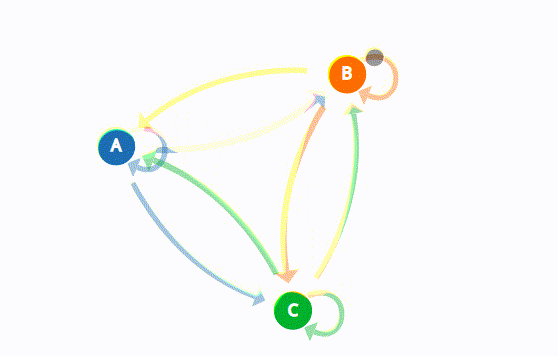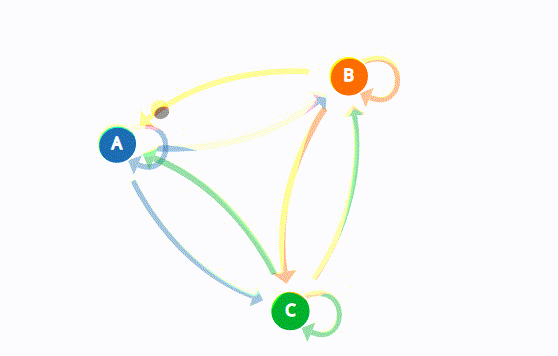
Fact 3: Sampling \( x_{t+1}\sim \Theta^\top e_{ x_t}\) \(\iff\) finite state Markov
chain with transition matrix \(\Theta\)
\(1\)
\(2\)
\(P = \begin{bmatrix} p_{1} & 1-p_1 \\ 1-p_2 & p_2 \end{bmatrix}\)
Next time: continuous state models
By Sarah Dean




