

Sarah Dean PRO
asst prof in CS at Cornell
Fall 2025, Prof Sarah Dean
policy
\(\pi_t:\mathcal X\to\mathcal A\)
observation
action
\(x_t\)
accumulate
\(\{(x_t, a_t, r_t)\}\)
\(a_{t}\)
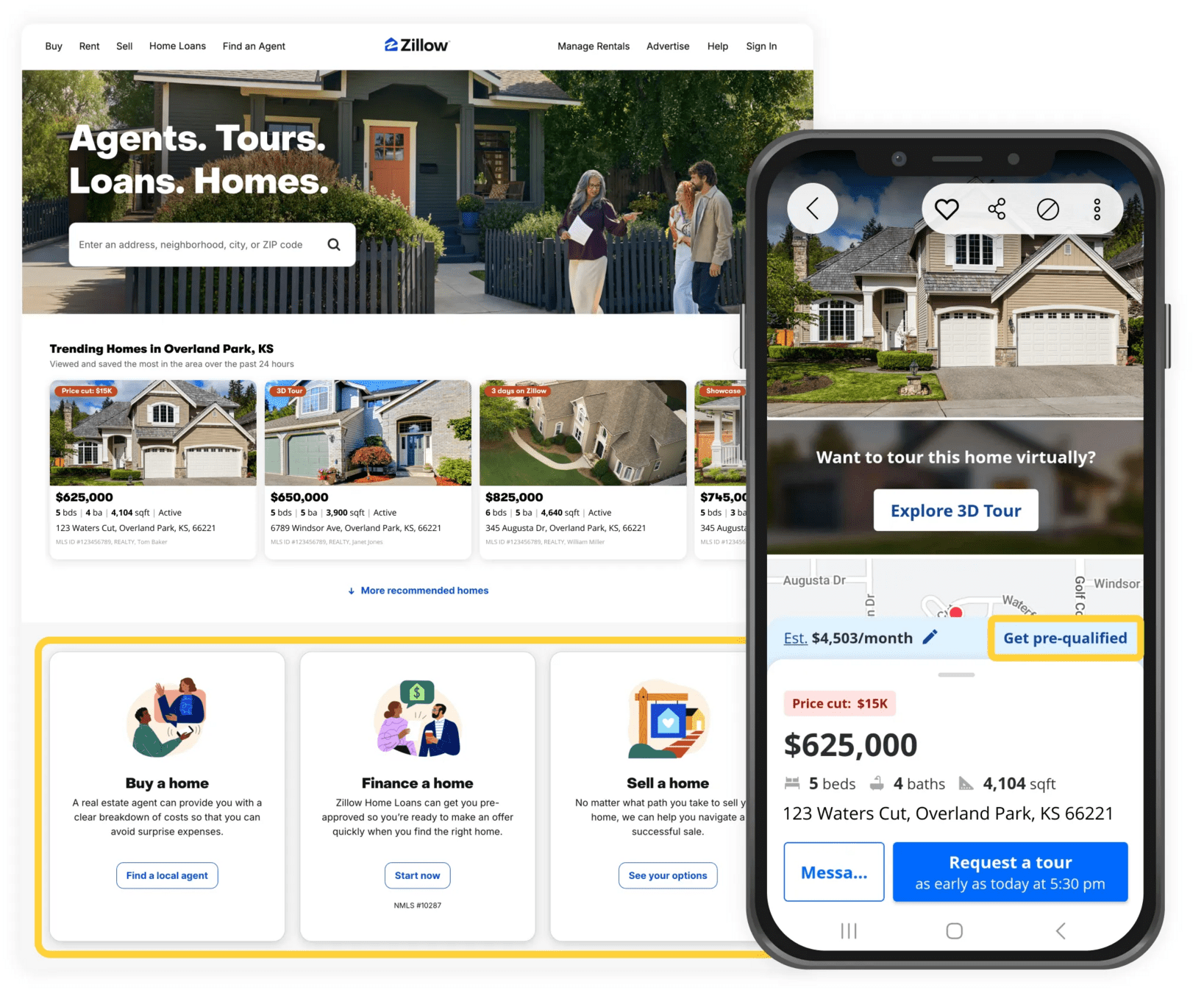
"What we do"
Notation: \(\|x\|^2_M = x^\top Mx\)
"Why we do it"
e.g. personalization
Taking action \(a_t\in\mathcal A\) in context \(x_t\) yields reward $$r_t = \langle\theta_\star, \varphi(x_t, a_t)\rangle + \varepsilon_t,\qquad \mathbb E[\varepsilon_t]=0,~~\mathbb E[\varepsilon_t^2] = \sigma^2$$
e.g. betting
Taking action \(a_t\in\mathcal A\) in context \(x_t\) yields reward $$r_t = \langle\theta_\star, \varphi(x_t, a_t)\rangle + \varepsilon_t,\qquad \mathbb E[\varepsilon_t]=0,~~\mathbb E[\varepsilon_t^2] = \sigma^2$$
Taking action \(a_t\in\mathcal A\) in context \(x_t\) yields reward $$r_t = \langle\theta_\star, \varphi(x_t, a_t)\rangle + \varepsilon_t$$
Taking action \(a_t\in\mathcal A\) in context \(x_t\) yields reward $$r_t = \langle\theta_\star, \varphi(x_t, a_t)\rangle + \varepsilon_t$$
Taking action \(a_t\in\mathcal A\) in context \(x_t\) yields reward $$r_t = \langle\theta_\star, \varphi(x_t, a_t)\rangle + \varepsilon_t$$
Let \(\varphi_t = \varphi(x_t,a_t)\), then using data \(\{(\varphi_k, r_k)\}_{k=1}^t\)
$$\hat\theta_t = \arg\min_\theta \sum_{k=1}^t (\theta^\top \varphi_k - r_k)^2$$
assuming \(\varphi_k\) are full rank, $$\hat\theta_t ={\underbrace{ \left(\sum_{k=1}^t \varphi_k\varphi_k^\top\right)}_{V_t}}^{-1}\sum_{k=1}^t \varphi_k r_k $$
Last lecture we discussed \(1-\delta\) confidence interval on prediction \(\theta_\star^\top\varphi\) is $$\Big[\hat\theta_t^\top \varphi \pm \sqrt{\beta} \|\varphi\|_{V_t^{-1}}\Big]$$
Define the confidence ellipsoid $$\mathcal C_t = \{\theta\in\mathbb R^d \mid \|\theta-\hat\theta_t\|_{V_t}^2\leq \beta_t\} $$
Fact: For the right choice of \(\beta_t\), with high probability, \(\theta_\star\in\mathcal C_t\)
Reference: Ch 19-20 in Bandit Algorithms by Lattimore & Szepesvari
Exercise: For a fixed action \(\varphi\), show that $$\max_{\theta\in\mathcal C_t} \theta^\top \varphi \leq \hat\theta^\top \varphi +\sqrt{\beta_t}\|\varphi\|_{V_t^{-1}}$$
$$\min_{\theta\in\mathcal C_t}\theta^\top \varphi \geq \hat\theta^\top\varphi -\sqrt{\beta_t}\|\varphi\|_{V_t^{-1}}$$
Last lecture we discussed \(1-\delta\) confidence interval on prediction \(\theta_\star^\top\varphi\) is $$\Big[\hat\theta_t^\top \varphi \pm \sqrt{\beta} \|\varphi\|_{V_t^{-1}}\Big]$$
example: \(K=2\) and we've pulled the arms 2 and 1 times respectively
\(V_t = \begin{bmatrix} 2& \\& 1\end{bmatrix}\)
\(\hat\theta = (\hat \mu_1,\hat\mu_2)\)
$$ \left\{\begin{bmatrix} 1\\ 0\end{bmatrix}, \begin{bmatrix} 1\\ 0\end{bmatrix}, \begin{bmatrix} 0\\ 1\end{bmatrix}\right \} $$
\(2(\mu_1-\hat\mu_1)^2 + (\mu_2-\hat\mu_2)^2 \leq \beta_t\)
example: \(d=2\) linear bandits
\(\hat \theta\)
$$ \left\{\begin{bmatrix} 1\\ 1\end{bmatrix}, \begin{bmatrix} -1\\ 1\end{bmatrix}, \begin{bmatrix} -1\\ -1\end{bmatrix}\right \} $$
\(V_t = \begin{bmatrix} 3&1 \\1& 3\end{bmatrix}\)
\(V_t^{-1} = \frac{1}{8} \begin{bmatrix} 3&-1 \\-1& 3\end{bmatrix}\)
Trying action \(a=[0,1]\):
Now we have
Confidence ellipsoid takes the same form $$\mathcal C_t = \{\theta\in\mathbb R^d \mid \|\theta-\hat\theta_t\|_{V_t}^2\leq \beta_t\} $$
$$\hat\theta_t =V_t^{-1}\sum_{k=1}^t \varphi_k r_k,\quad V_t=\lambda I+\sum_{k=1}^t\varphi_k\varphi_k^\top $$
$$\hat\theta_t = \arg\min_\theta \sum_{k=1}^t (\theta^\top \varphi_k - r_k)^2 + \lambda\|\theta\|_2^2$$
To handle cases where \(\{\varphi_k\}\) are not full rank, we consider regularized LS
Reference: Ch 19-20 in Bandit Algorithms by Lattimore & Szepesvari
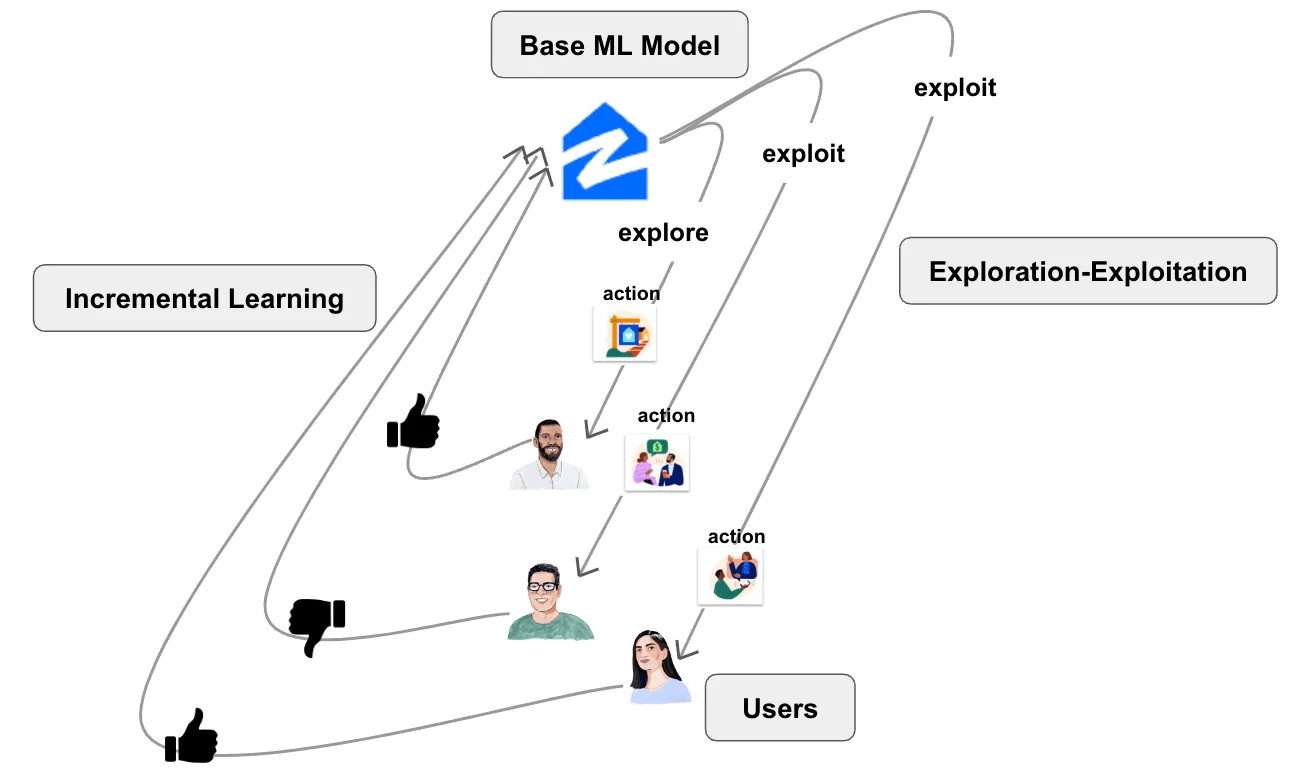
How to trade-off exploration and exploitation?
The regret of an algorithm choosing \(\{a_t\}\) is defined as $$R(T) = \sum_{t=1}^T\max_{a\in\mathcal A} r(x_t, a) - r(x_t, a_t) $$
Notice that $$ \frac{1}{T}\sum_{t=1}^T r(x_t,a_t) \geq \frac{1}{T}\sum_{t=1}^T \max_{a\in\mathcal A} r(x_t, a) - \frac{R(T)}{{T}}$$
ETC
The regret has two components
$$R(T) = \underbrace{\sum_{t=1}^{N} \max_{\varphi\in\mathcal A_t}\theta_\star^\top \varphi - \theta_\star^\top \varphi_t }_{R_1} + \underbrace{\sum_{t=N+1}^{T} \max_{\varphi\in\mathcal A_t}\theta_\star^\top \varphi - \theta_\star^\top \varphi_t }_{R_2}$$
The regret has two components
$$R(T) = \underbrace{\sum_{t=1}^{N} \max_{\varphi\in\mathcal A_t}\theta_\star^\top \varphi - \theta_\star^\top \varphi_t }_{R_1} + \underbrace{\sum_{t=N+1}^{T} \max_{\varphi\in\mathcal A_t}\theta_\star^\top \varphi - \theta_\star^\top \varphi_t }_{R_2}$$
Suppose that \(B\) bounds the norm of \(\varphi\) and \(\|\theta_\star\|\leq 1\).
Then we have \(R_1\leq 2BN\)
The regret has two components
$$R(T) = \underbrace{\sum_{t=1}^{N} \max_{\varphi\in\mathcal A_t}\theta_\star^\top \varphi - \theta_\star^\top \varphi_t }_{R_1} + \underbrace{\sum_{t=N+1}^{T} \max_{\varphi\in\mathcal A_t}\theta_\star^\top \varphi - \theta_\star^\top \varphi_t }_{R_2}$$
The suboptimality is \(\theta_\star^\top \varphi_t^\star - \theta_\star^\top \hat\varphi_t\)
The regret has two components
$$R(T) = \underbrace{\sum_{t=1}^{N} \max_{\varphi\in\mathcal A_t}\theta_\star^\top \varphi - \theta_\star^\top \varphi_t }_{R_1} + \underbrace{\sum_{t=N+1}^{T} \max_{\varphi\in\mathcal A_t}\theta_\star^\top \varphi - \theta_\star^\top \varphi_t }_{R_2}$$
Using sub-optimality result, with high probability \(R_2 \lesssim (T-N)2B\sqrt{\beta \frac{d}{N} }\)
Suppose that \(\max_t\beta_t\leq \beta\).
The regret is bounded with high probability by
$$R(T) \lesssim 2BN + 2BT\sqrt{\beta \frac{d}{N} }$$
Choosing \(N=T^{2/3}\) leads to sublinear regret
Adaptive perspective: optimism in the face of uncertainty
UCB
The suboptimality is \(\theta_\star^\top \varphi_t^\star - \theta_\star^\top \hat\varphi_t\)
Proof Sketch: \(R(T) = \sum_{t=1}^T \theta_\star^\top \varphi_t^\star - \theta_\star^\top \hat\varphi_t\)
The regret is bounded with high probability by
$$R(T) \lesssim \sqrt{T}$$
Reference: Ch 19-20 in Bandit Algorithms by Lattimore & Szepesvari
Next time: optimal action sequences
By Sarah Dean




