Sarah Dean PRO
asst prof in CS at Cornell
(down arrow to see handout slides)
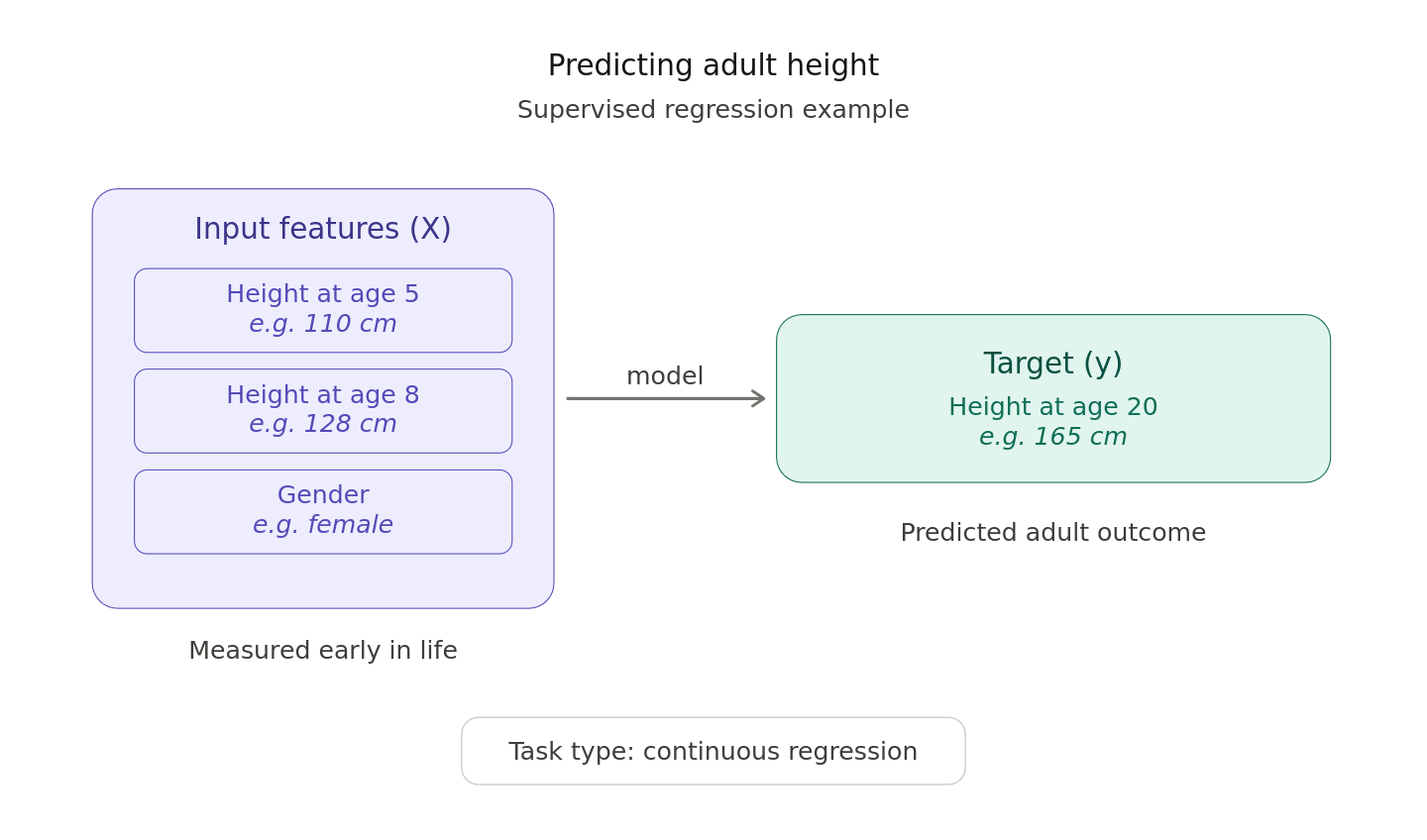
$$\textbf{Goal: }E_{\mathbf{x}, y, D} \left[ \left( h_{D}(\mathbf{x}) - y \right)^{2} \right] = \underbrace{E_{\mathbf{x}, D} \left[ \left(h_{D}(\mathbf{x}) - \bar{h}(\mathbf{x}) \right)^{2} \right]}_{\text{Variance}} + E_{\mathbf{x}, y}\left[ \left( \bar{h}(\mathbf{x}) - y \right)^{2} \right]$$
Fill in below steps: Add and subtract, then expand, then simplify cross term
$$E_{\mathbf{x},y,D}\left[(h_D(\mathbf{x}) - y)^2\right] = E_{\mathbf{x},y,D}\left[\left[(h_D(\mathbf{x}) - \qquad) + ( \qquad - y)\right]^2\right] $$
$$ = E_{\mathbf{x},D}\left[(h_D(\mathbf{x}) - \qquad)^2\right] + 2 E_{\mathbf{x},y,D}\left[(h_D(\mathbf{x}) - \qquad)( \qquad - y)\right] + E_{\mathbf{x},y}\left[( \qquad - y)^2\right] $$
$$\begin{aligned} E_{\mathbf{x}, y, D} \left[\left(h_{D}(\mathbf{x}) - \qquad\right) \left(\qquad - y\right)\right] &= E_{\underline{\qquad}} \left[E_{\underline{\qquad}} \left[ h_{D}(\mathbf{x}) - \qquad\right] \left(\qquad - y\right) \right] \\ &= E_{\underline{\qquad}} \left[ \left( E_{\underline{\qquad}} \left[ h_{D}(\mathbf{x}) \right] - \qquad \right) \left(\qquad - y \right)\right] \\ &= E_{\underline{\qquad}} \left[ \left(\qquad - \qquad\right) \left(\qquad - y \right)\right]\ \\ &= 0 \end{aligned}$$
$$\textbf{Goal: } E_{\mathbf{x}, y} \left[ \left(\bar{h}(\mathbf{x}) - y \right)^{2}\right] = \underbrace{E_{\mathbf{x}, y} \left[\left(\bar{y}(\mathbf{x}) - y\right)^{2}\right]}_{\text{Noise}} + \underbrace{E_{\mathbf{x}} \left[\left(\bar{h}(\mathbf{x}) - \bar{y}(\mathbf{x})\right)^{2}\right]}_{\text{Bias}^2} $$
Fill in below steps: Add and subtract, then expand, then simplify cross term
$$\begin{aligned} &E_{\mathbf{x}, y} \left[ \left(\bar{h}(\mathbf{x}) - y \right)^{2}\right] = E_{\mathbf{x}, y} \left[ \left(\bar{h}(\mathbf{x}) - \qquad )+(\qquad - y \right)^{2}\right] \\ &=E_{\mathbf{x}, y} \left[\left(\qquad - y\right)^{2}\right] + E_{\mathbf{x}} \left[\left(\bar{h}(\mathbf{x}) - \qquad\right)^{2}\right] + 2 E_{\mathbf{x}, y} \left[ \left(\bar{h}(\mathbf{x}) - \qquad\right)\left(\qquad - y\right)\right] \end{aligned}$$
$$\begin{aligned}E_{\mathbf{x}, y} \left[ \left(\bar{h}(\mathbf{x}) - \qquad\right)\left(\qquad - y\right)\right] &= \\ &= \\ &= 0 \end{aligned}$$
$$\underbrace{E_{\mathbf{x}, y, D} \left[\left(h_{D}(\mathbf{x}) - y\right)^{2}\right]}_{\text{Expected Test Error}} = \underbrace{E_{\mathbf{x}, D}\left[\left(h_{D}(\mathbf{x}) - \bar{h}(\mathbf{x})\right)^{2}\right]}_{\text{Variance}} + \underbrace{E_{\mathbf{x}, y}\left[\left(\bar{y}(\mathbf{x}) - y\right)^{2}\right]}_{\text{Noise}} + \underbrace{E_{\mathbf{x}}\left[\left(\bar{h}(\mathbf{x}) - \bar{y}(\mathbf{x})\right)^{2}\right]}_{\text{Bias}^2}$$
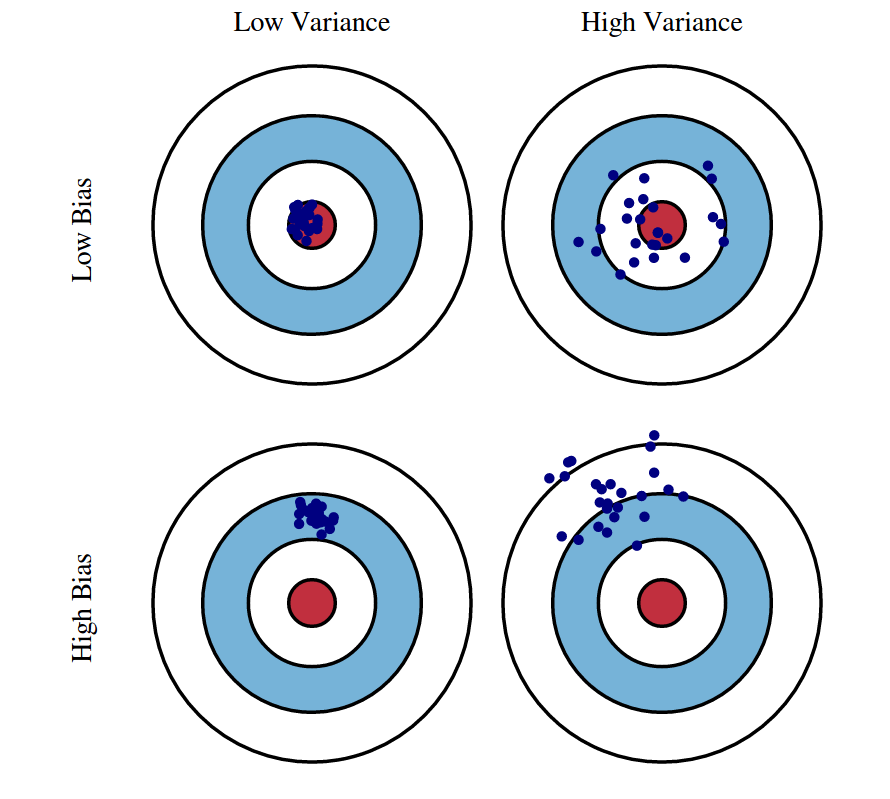
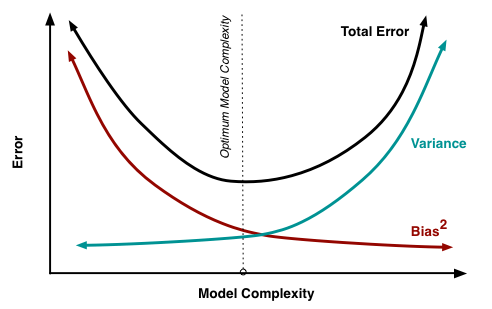
Insight: tune the model complexity to trade off Variance and Bias
Diagnosis: where does poor performance come from?
Bias-Variance Decomposition: $$ \text{Expected Test Error} = \text{Bias}^2 + \text{Variance} + \text{Noise} $$
By Sarah Dean




