
Sarah Dean PRO
asst prof in CS at Cornell
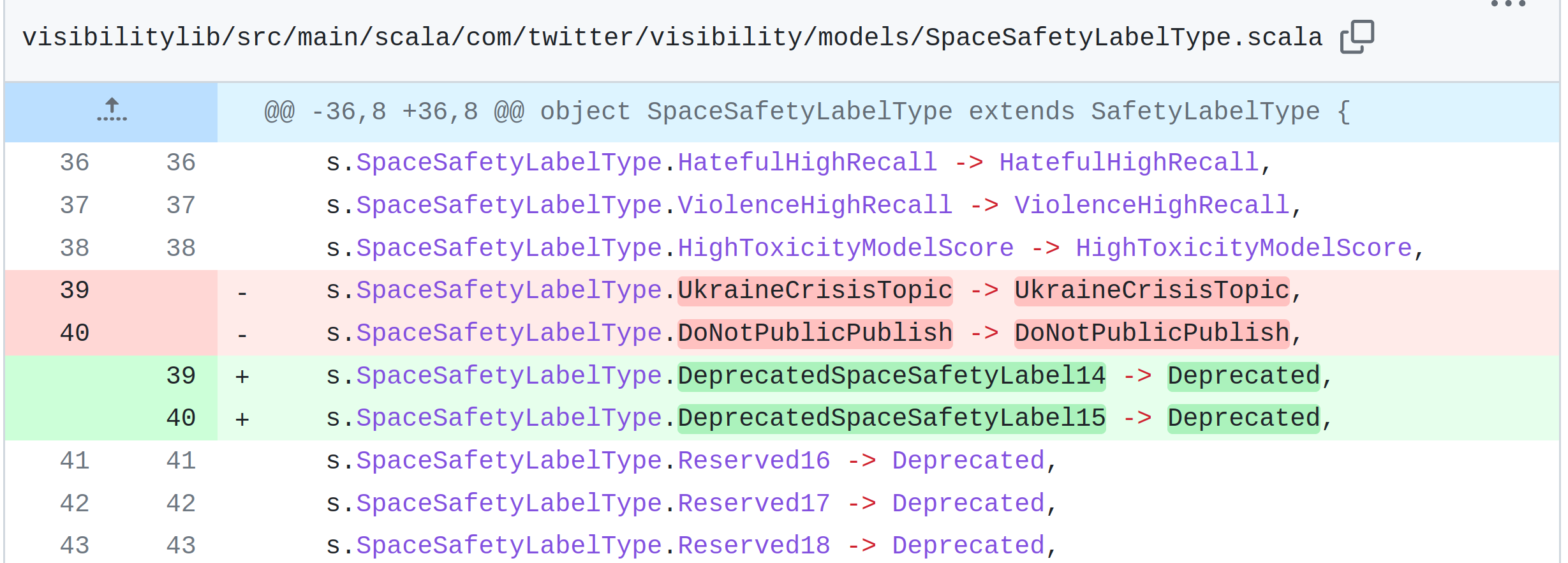
Please note we have force-pushed a new initial commit in order to remove some publicly-available Twitter user information. Note that this process may be required in the future.
How is my feed populated?
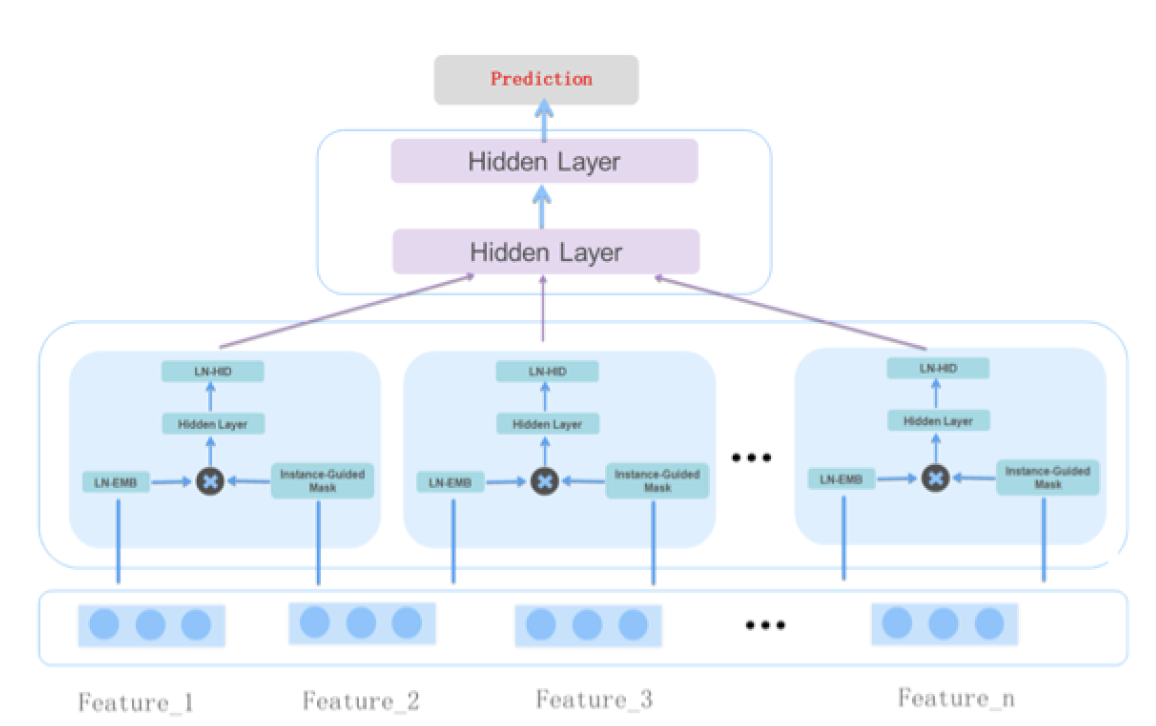
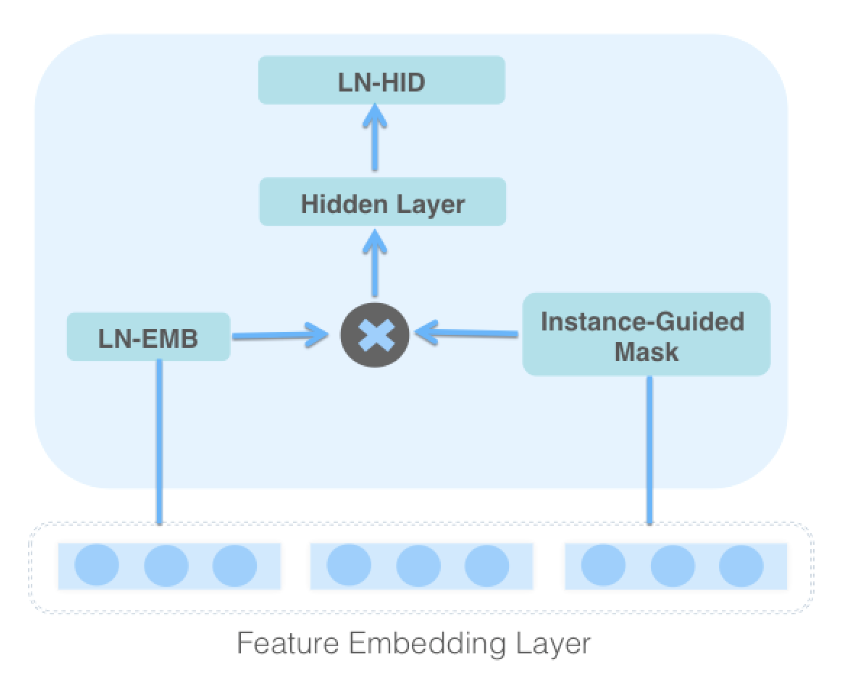
similarity of tweet to user's recent engaged tweets "sim_clusters"
other misc features about time, request context, author health
Thwin embeddings: directional follow embeddings, engagement embedding, each 200 dimensional
categorical input fields are embedded and numerical ones are compressed to \(k\) dimensions
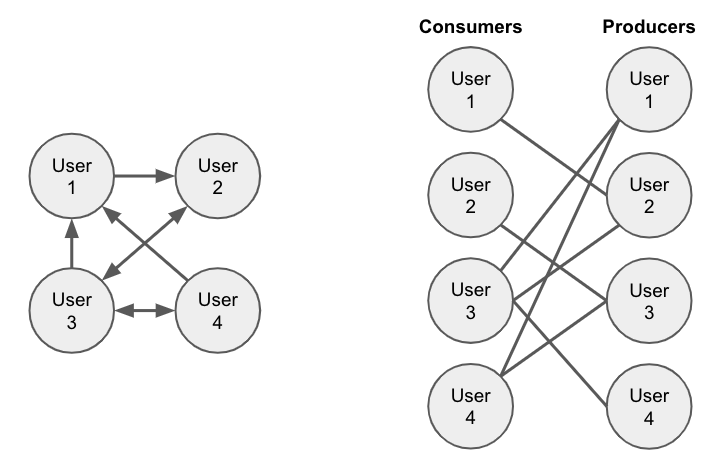
Facebook, Twitter, TikTok, YouTube and other dominant social media platforms treat the list of people we follow as suggestions, not commands. When you identify a list of people you want to hear from, the platform uses that as training data for suggestions that only incidentally contain the messages that the people you subscribed to.
By Sarah Dean



