


Sarah Dean PRO
asst prof in CS at Cornell
(down arrow to see handout slides)
?
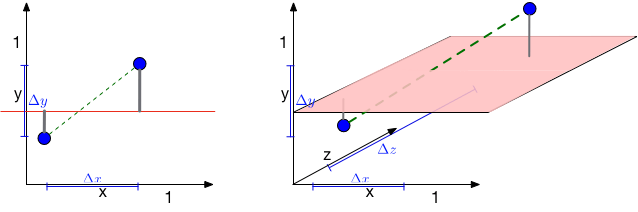
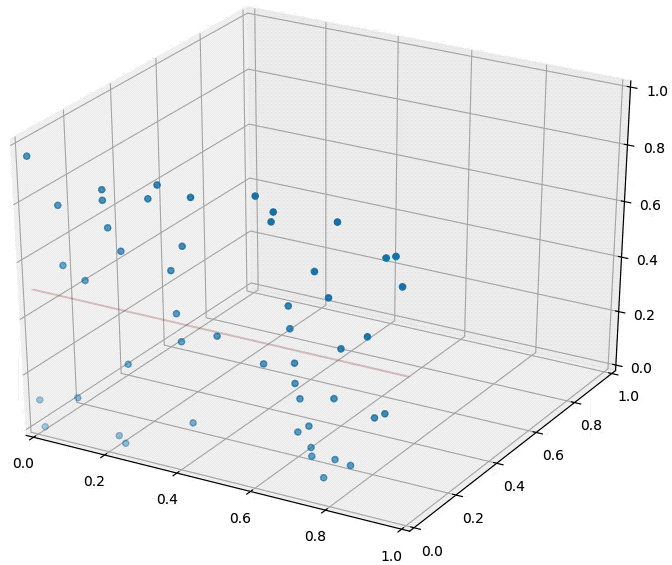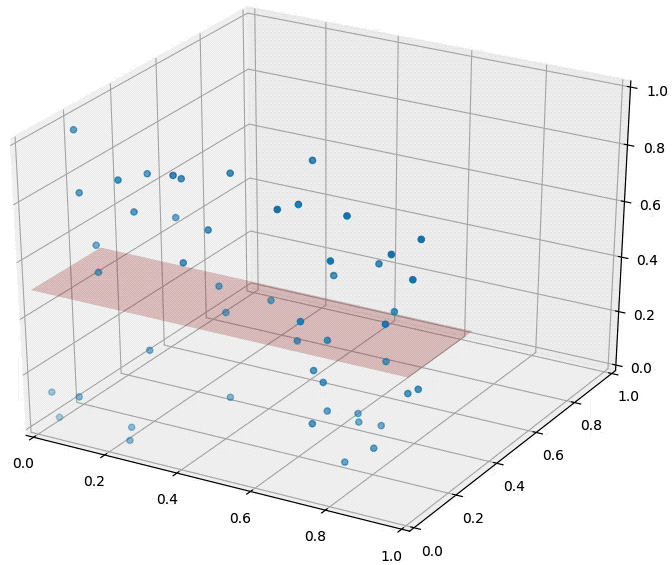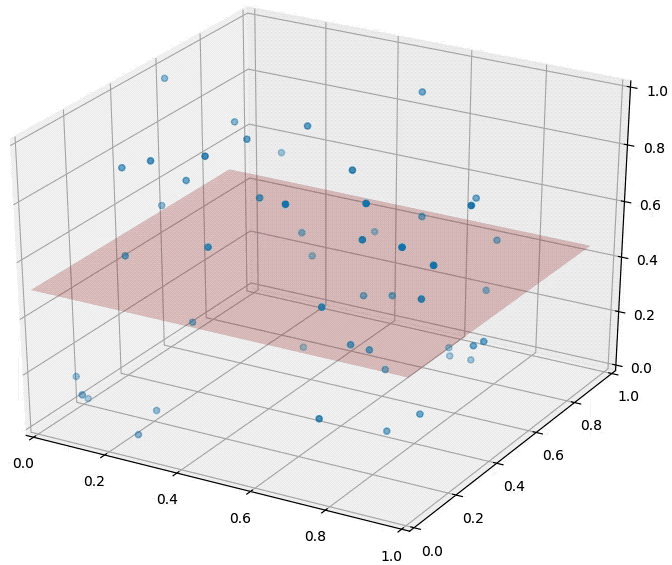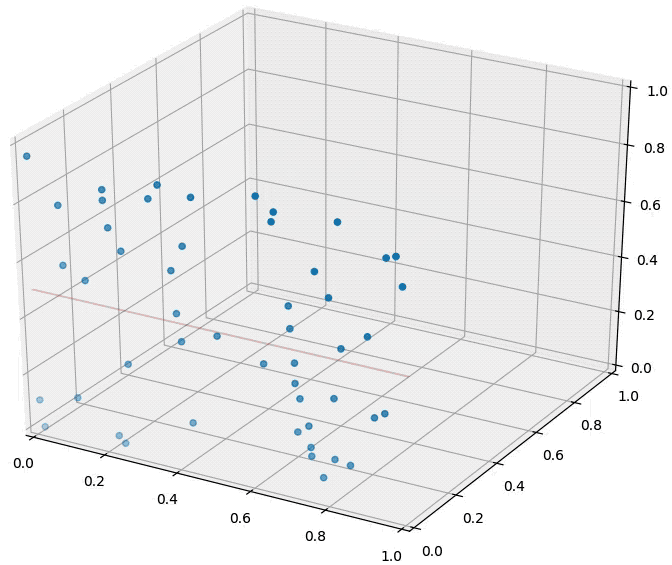
Common assumption: the relationship between \(\mathbf x\) and \(y\) is locally smooth
?
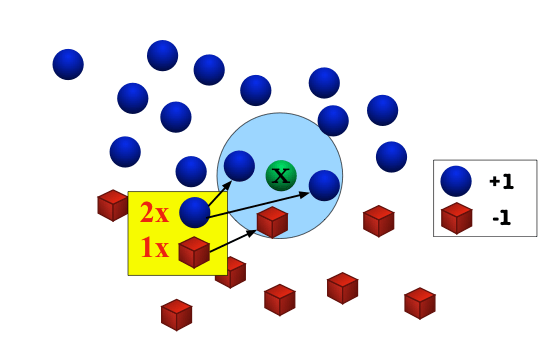
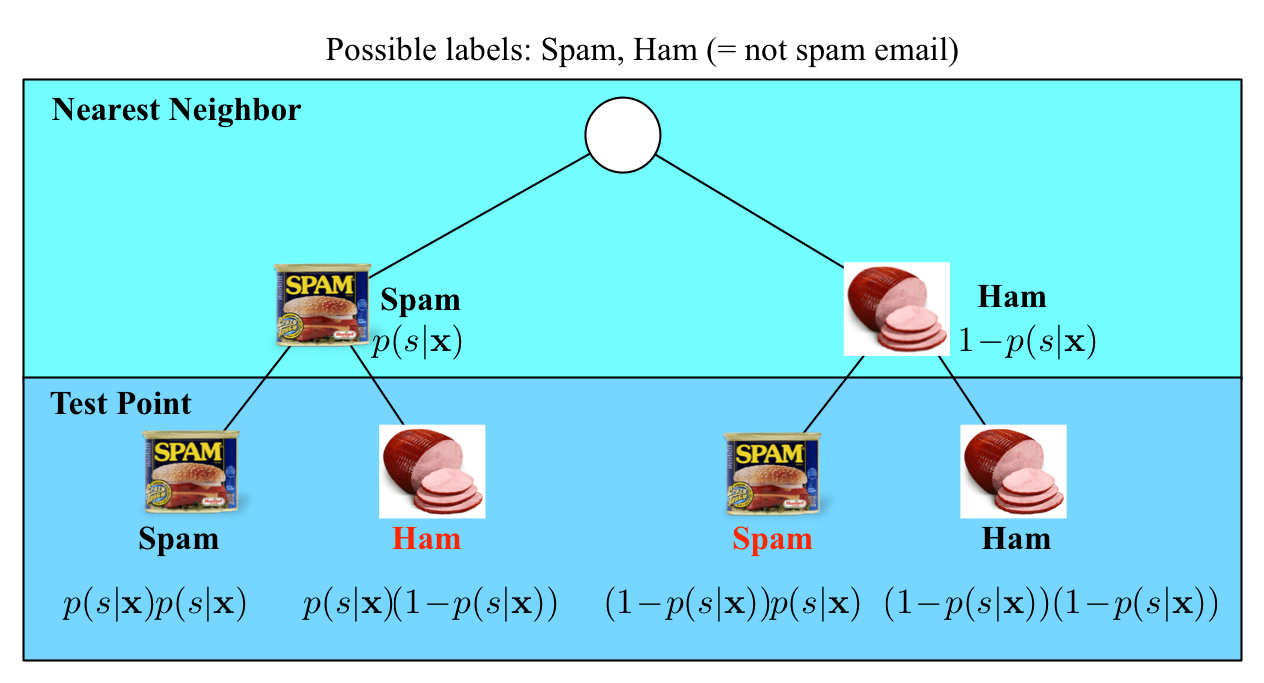
example: \(k=3\)
for test sample \(\mathbf x\), prediction is \(+1\)
The classifier fundamentally relies on a distance metric; the better it reflects label similarity, the better the classifier.
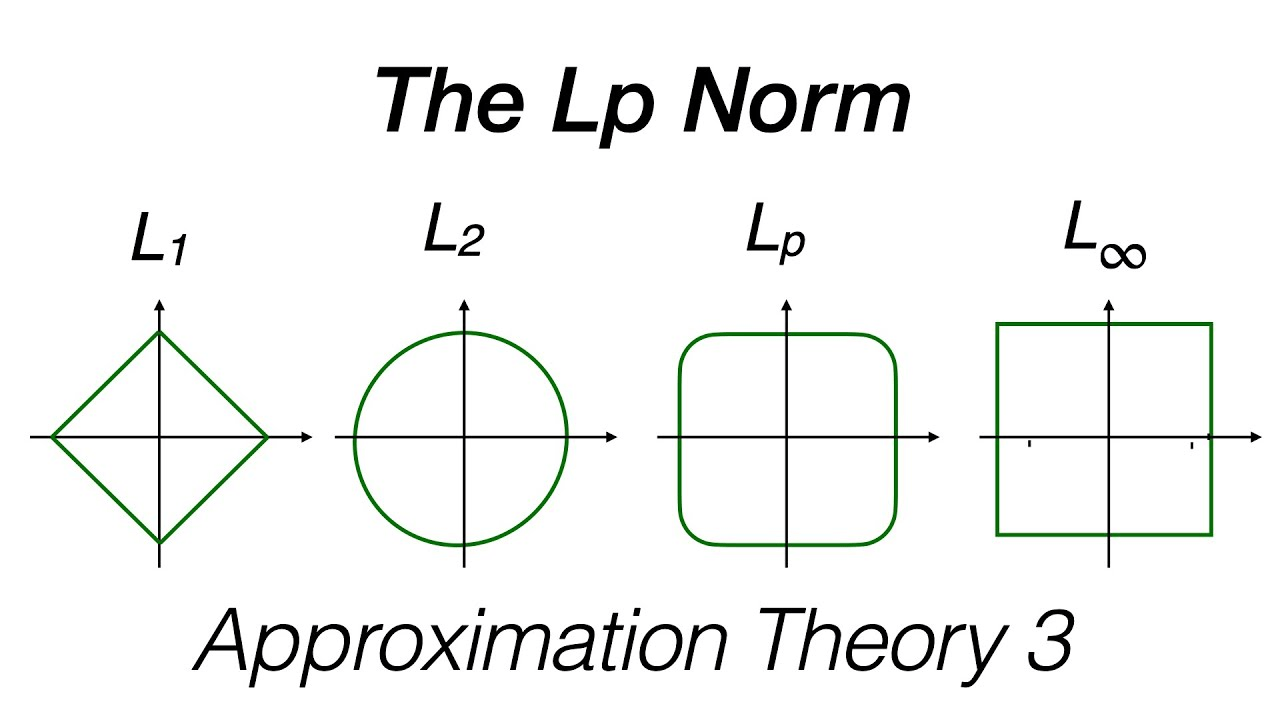
$$\text{dist}(\mathbf{x},\mathbf{x}') = \left(\sum_{r=1}^d |x_r - x'_r|^p\right)^{1/p}$$
\(\mathbf x\)
\(y=+1\)
\(y=-1\)
\(y^*=+1\)
\(y^*=-1\)
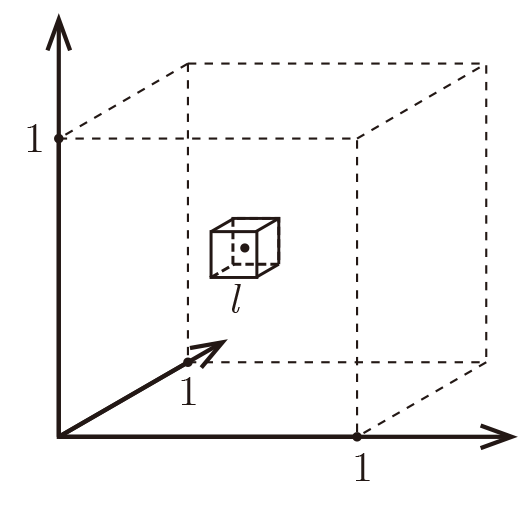
| Dimension (\(d\)) | Edge Length (\(\ell\)) |
|---|---|
| 2 | 0.1 |
| 10 | 0.63 |
| 100 | 0.955 |
| 1000 | 0.9954 |
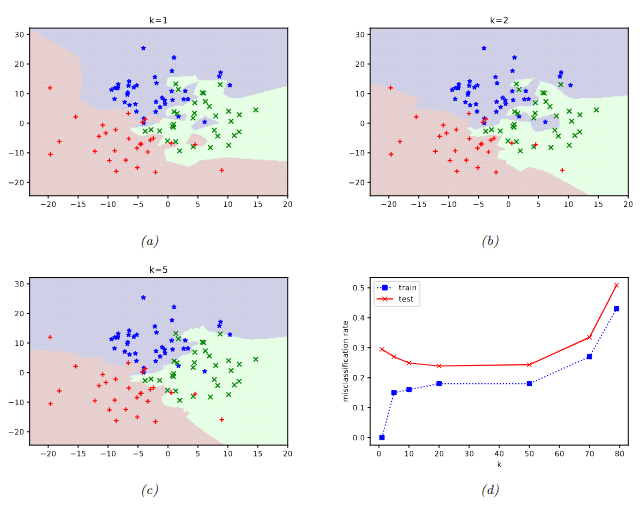
For \(k=10, n=1000\)
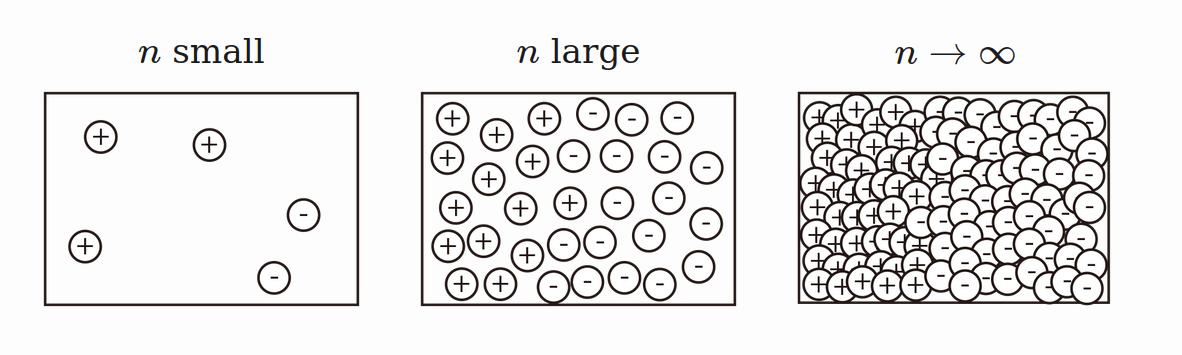
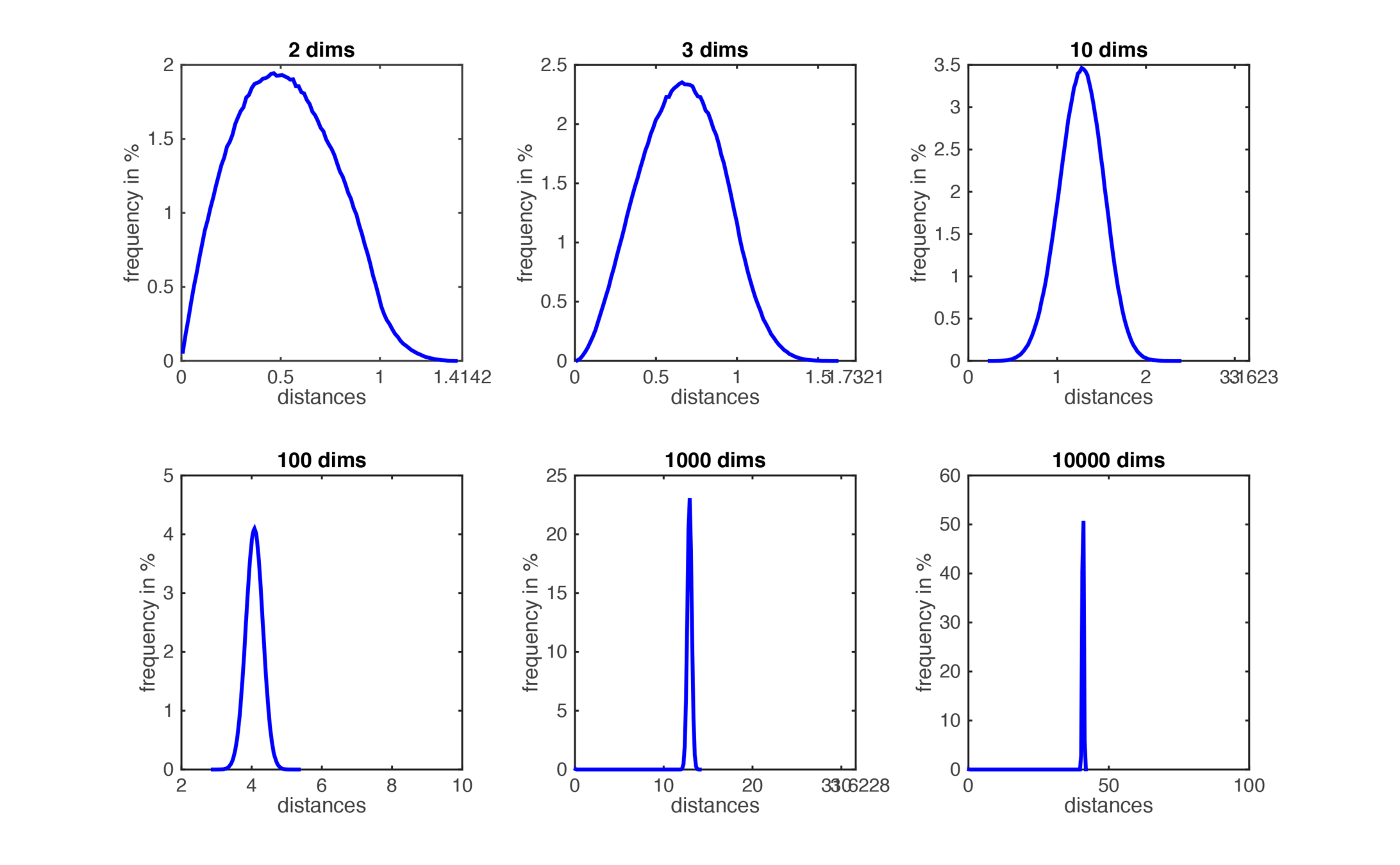
The distributions of all pairwise distances between randomly distributed points within \(d\)-dimensional unit squares.
By Sarah Dean




