- General upper bound in terms of Vapnik-Chervonenkis (VC) Dimension of a hypothesis class \(d_{VC}(H)\) $$ \max_{|D|=n} |H[D]|\leq (ne/d_{VC}(H))^{d_{VC}(H)} $$
- VC Dimension is well known for many \(H\)
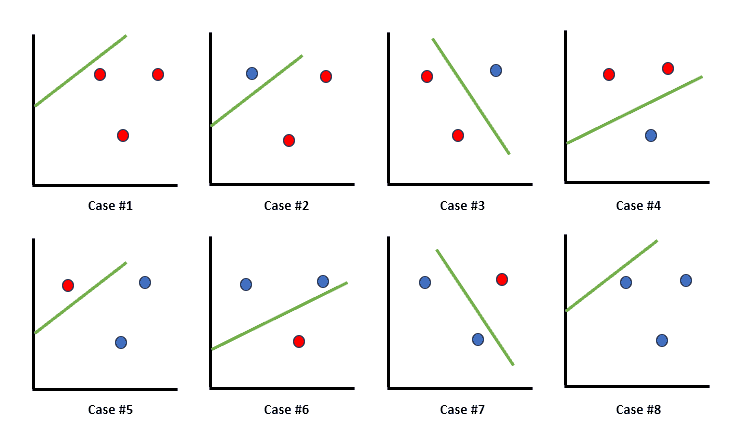
- Linear classifiers on \(d\) features: \(d_{VC} = d\)
- Linear classifiers with bias: \(d_{VC} = d+1\)
- Linear classifiers with margin \(\gamma\) on data with \(\|x_i\|\leq R\): \(d_{VC} = R^2/\gamma^2\)
- Can derive a PAC ("probably approximately correct") bound
- For \(H\) with VC dimension \(d_{VC}\), given \(n\) training data points \(D\), with probability at least \(1-\delta\):
$$\begin{align*}\text{err}_{P}(h_D)& \leq \underbrace{\text{err}_{D}(h_D)}_{(a)} + \underbrace{\sqrt{\frac{d_{VC}\log(2n/d_{VC}) + 1 +\log(1/\delta)}{4n}}}_{(b)} \end{align*}$$