











Sarah Dean PRO
asst prof in CS at Cornell
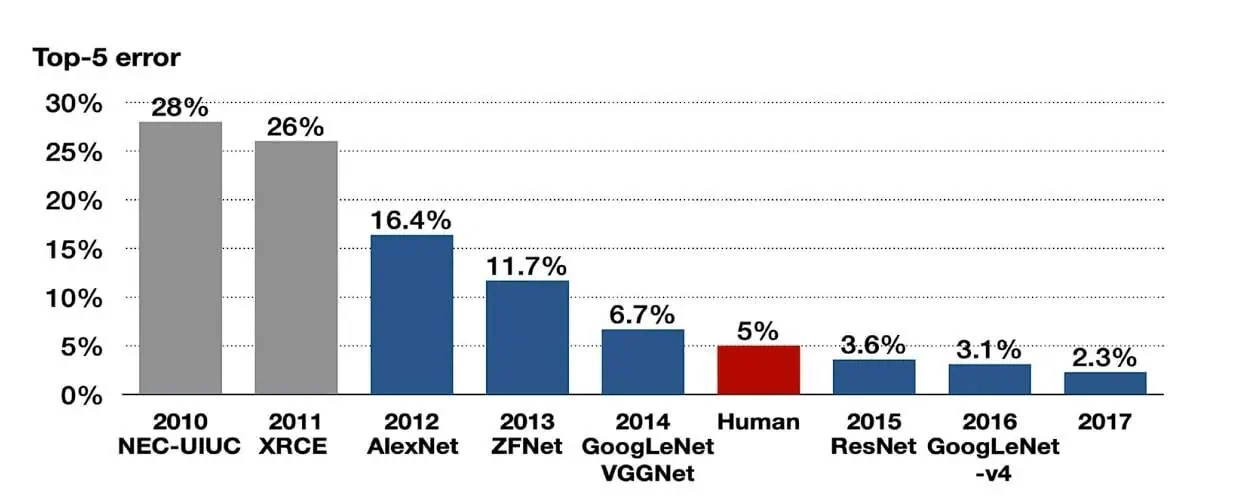
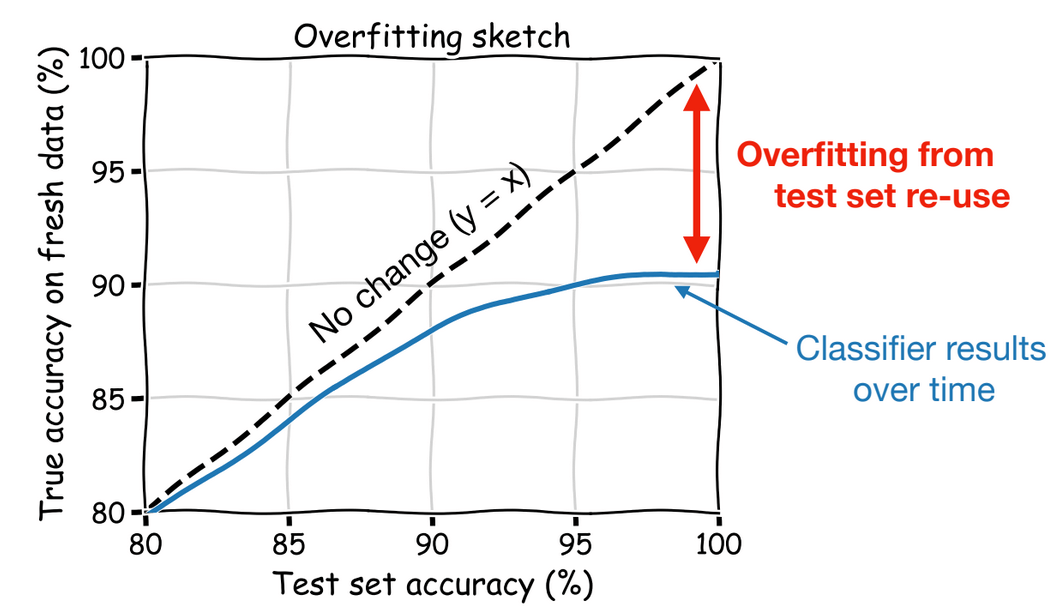
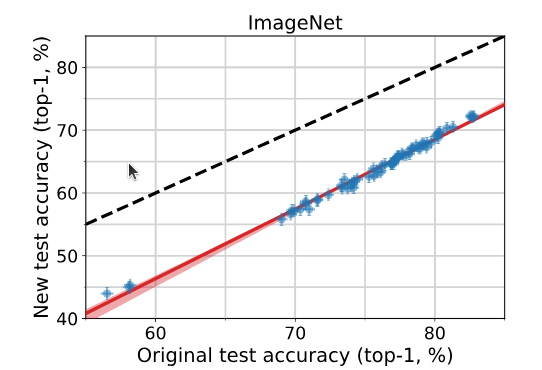
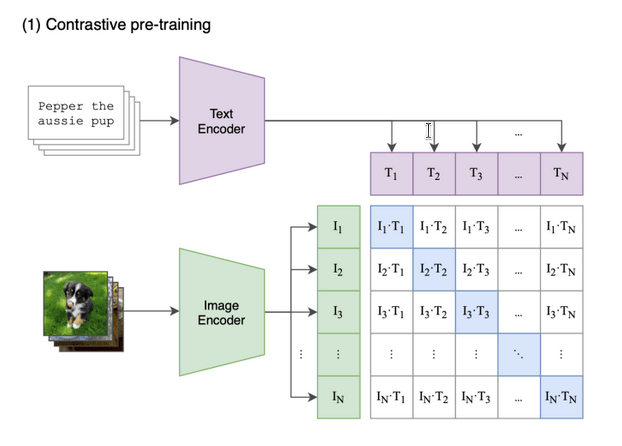
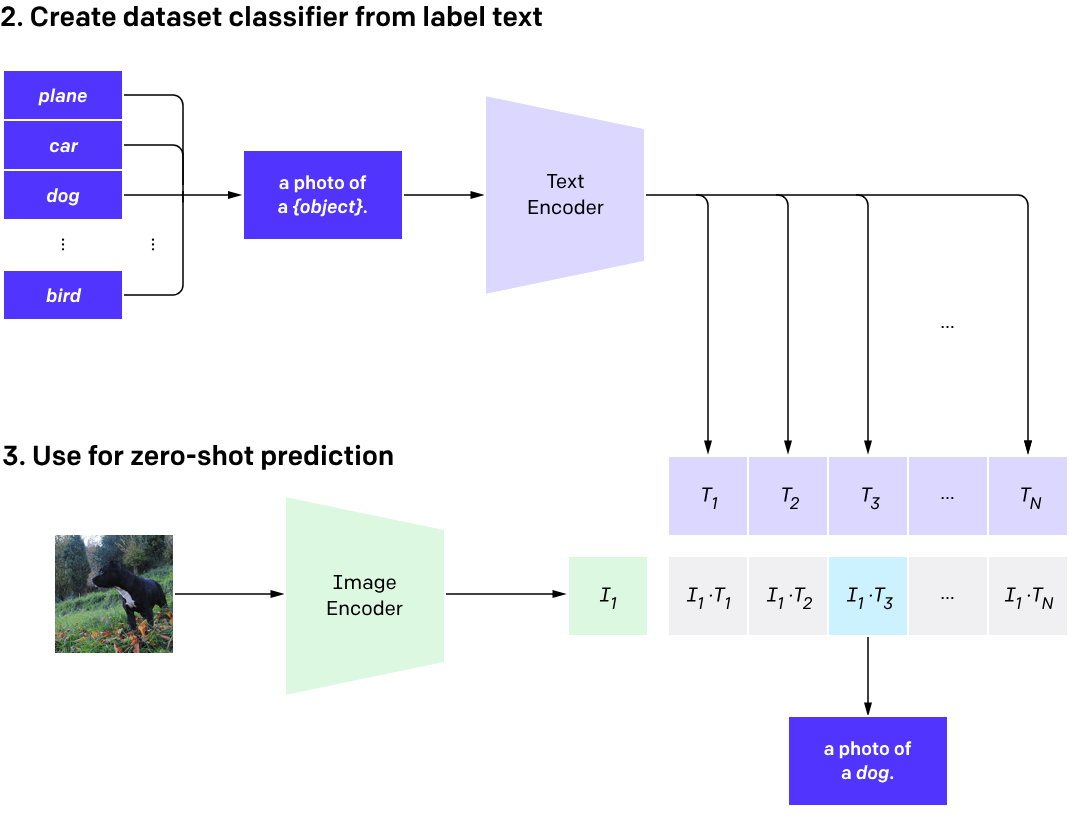
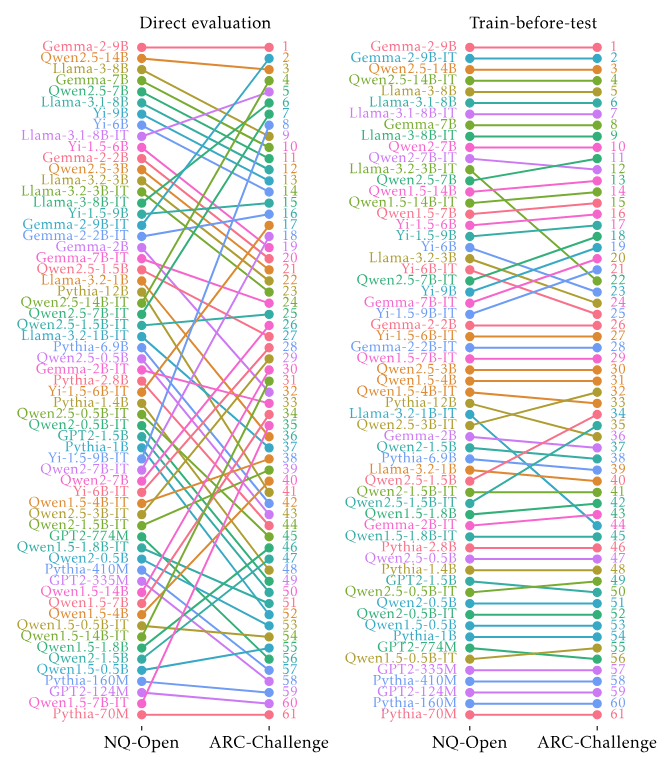
Datasets are central to machine learning. In particular, the competitive testing paradigm is the engine of progress in ML and AI.
Bill Highleyman and Louis Kamenstky, 1959 at Bell Labs
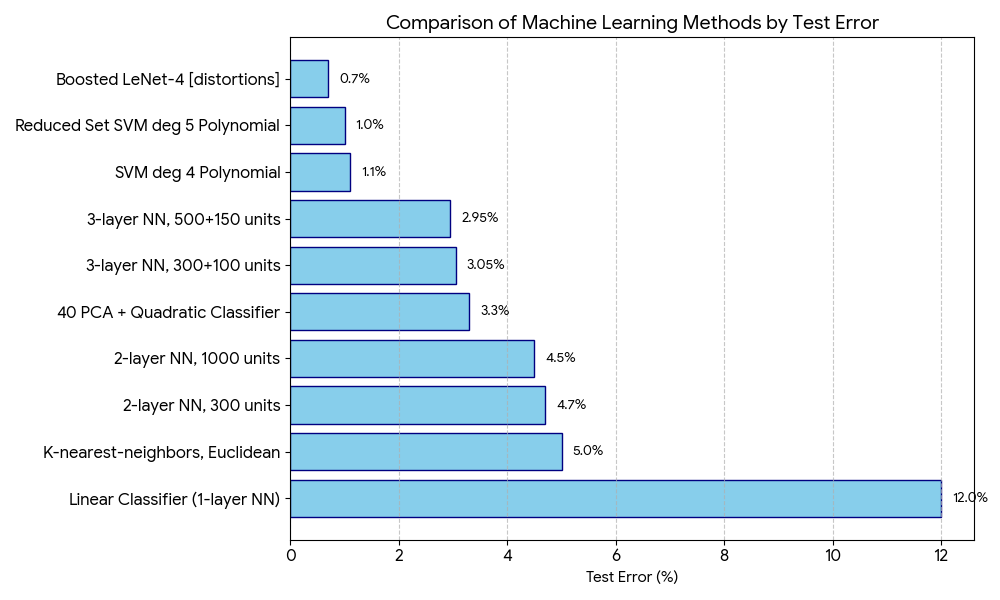
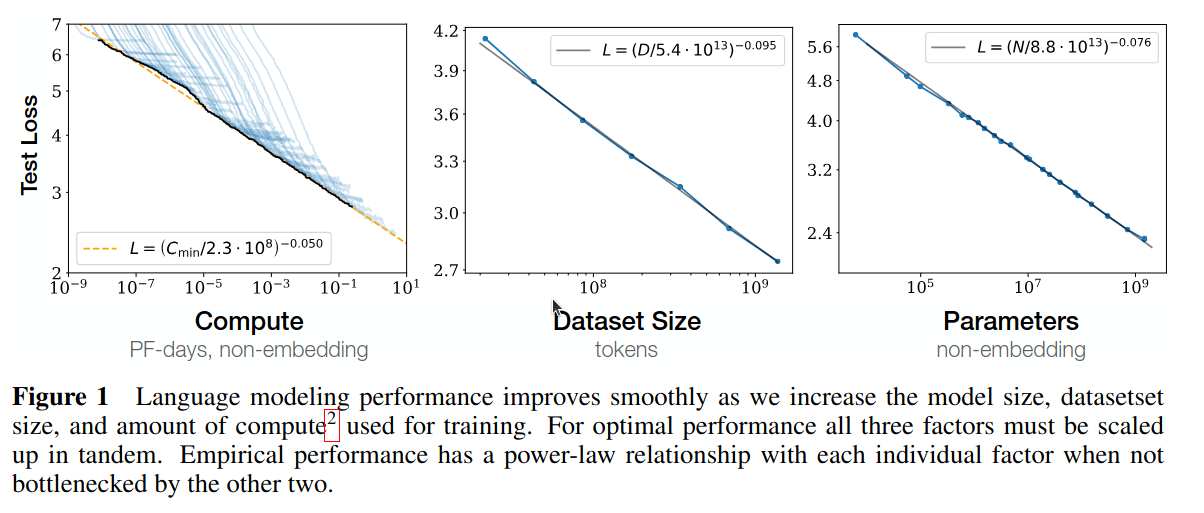
Larger and higher-quality datasets are needed for work aimed at achieving useful results ... contain hundreds, or even thousands, of samples in each class.
| Research Group | Organization | Error Rate |
| Woody Bledsoe | Sandia Labs | ~60% |
| Chao Kong Chow | Burroughs Corporation | 41.7% |
| Munson, Duda, and Hart | Stanford Research Institute (SRI) | 31.7% (Linear Model) |
| Munson, Duda, and Hart | Stanford Research Institute (SRI) | 12% (Digits Only) |
| Human Subjects | (Informal Experiment) | 15.7% |
$$ \mathrm{PPL}= \exp \left(-\frac{1}{D}\sum_{i=1}^D \log p(t_i \mid t_1t_2\cdots t_{i-1})\right) $$
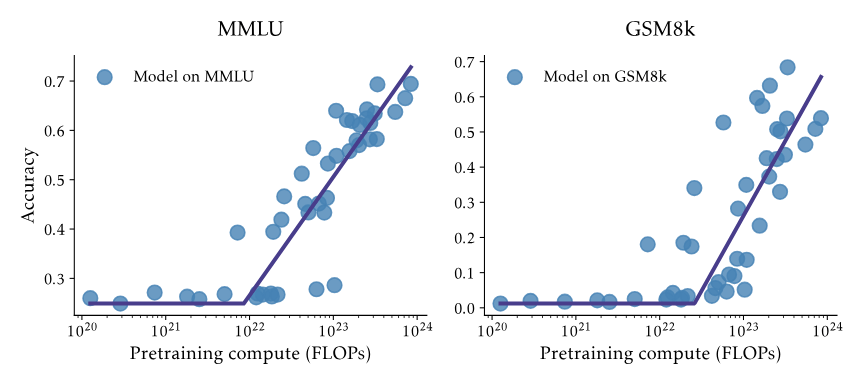
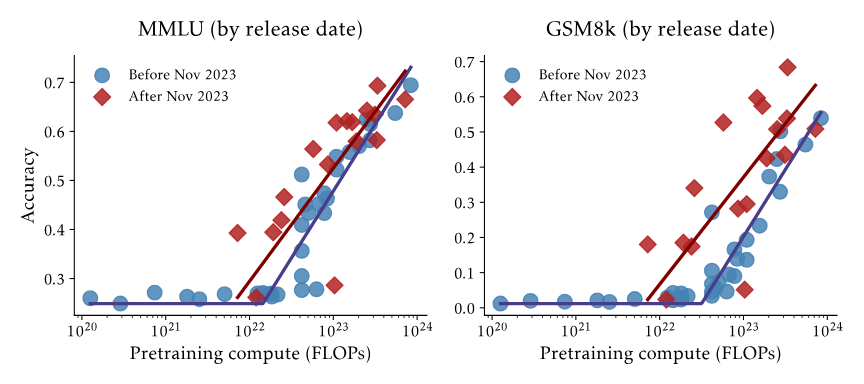
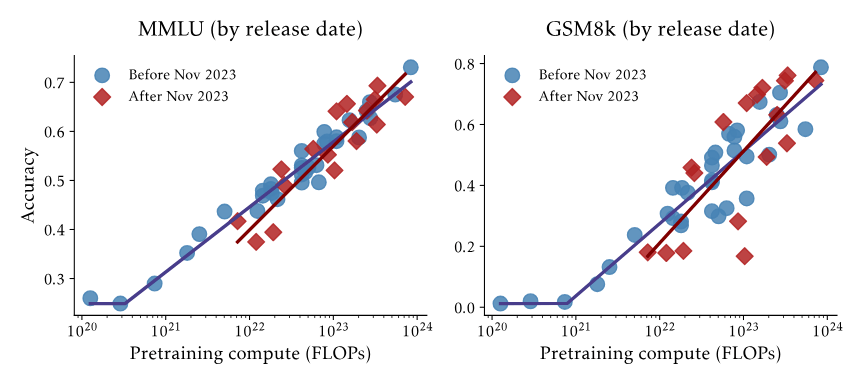
multiple-choice, 1000s questions, college level
measures language comprehension and knowledge
GSM8K (Grade School Math 8K), 2021
8.5k math word problems with natural language solutions
evaluated by numerical accuracy of final answer
measures comprehension and reasoning
HumanEval, 2021
164 hand-crafted programming problems: function signature, a descriptive docstring, reference implementation, and unit tests
evaluated on passing tests
measures ability to generate correct code
Patterns, Predictions, and Actions: A story about machine learning (mlstory.org), Moritz Hardt and Benjamin Recht
The Emerging Science of Machine Learning Benchmarks (mlbenchmarks.org), Moritz Hardt
CS525: Training Data for AI at Stanford, Winter 2026 (https://ludwigschmidt.github.io/cs525-winter2026-website/), Ludwig Schmidt
By Sarah Dean




