






























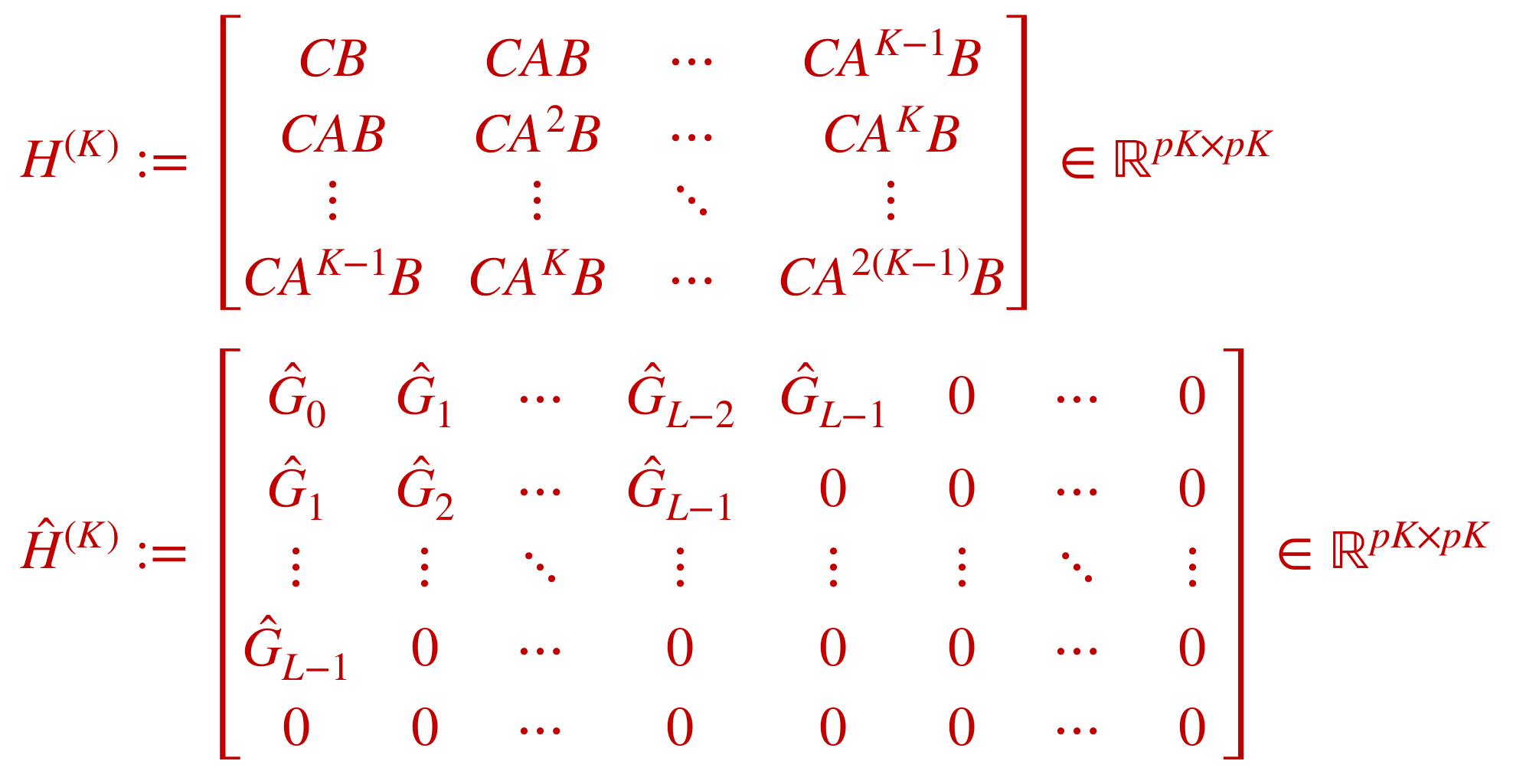
Sarah Dean PRO
asst prof in CS at Cornell
Simons Workshop, April 2025
learning & decision-making algorithm
learning & decision-making algorithm
1. Motivation and Background
2. Learning Dynamics
inputs
outputs
time
3. Optimal Control
1. Motivation and Background
Work with Horia Mania, Nikolai Matni, Ben Recht, and Stephen Tu in 2017
Sample Complexity: How much data is necessary to control a system?
Motivation: foundation for understanding RL & ML-enabled control
Classic RL setting: discrete problems and inspired by games
RL techniques applied to continuous systems interacting with the physical world
Simplest problem: linear dynamics, quadratic cost, zero mean noise
minimize \(\mathbb{E}\left[ \sum_{t=0}^{T-1} x_t^\top Q x_t + u_t^\top R u_t\right]\)
s.t. \(x_{t+1} = Ax_t+Bu_t+w_t\)
\(u_t = K_t^\star x_t\)
Linear policy is optimal and can be computed in closed-form:
Simplest problem: linear dynamics, quadratic cost, zero mean noise
\(u_t = K_t^\star \hat x_t,\quad \hat x_t = \mathbb E[x_t|u_0,...,u_t,y_0,...,y_t]\)
Linear policy is optimal and can be computed in closed-form:
minimize \(\mathbb{E}\left[ \sum_{t=0}^{T-1} x_t^\top Q x_t + u_t^\top R u_t\right]\)
s.t. \(x_{t+1} = Ax_t+Bu_t+w_t\)
\(y_{t} = Cx_t+v_t\)
?
(separation principle)
?
?
?
?
1. Collect \(N\) observations and estimate \(\widehat A,\widehat B, \widehat C\)
2. Design policy as if estimate is true ("certainty equivalent")
\((A_\star, B_\star,C_\star)\)
\(\widehat \pi\)
\((A_\star, B_\star,C_\star)\)
Control Result (Informal):
sub-opt. of \(\widehat \pi\lesssim(\)param. err.\()^2 \lesssim \frac{1}{N}\)
Learning Result (Informal):
parameter error \( \lesssim \frac{1}{\sqrt{N}}\)
least squares regression
Naive exploration is essentially optimal!
white noise inputs
What lessons did we learn about RL & ML-enabled control?
\(\implies\) Problem does not capture all issues of interest!
*Exceptions: low data regime, safety/actuation limits
Observer effect: coupling between actuation
and observation
\(u_t\)
\(y_t\)
Classically studied as an online decision problem (e.g. multi-armed bandits)
unknown preference
expressed preferences
recommended content
recommender policy
\(u_t\)
unknown preference parameters \(\theta\)
expressed preferences
recommended content
recommender policy
\(\mathbb E[y_t] = \theta^\top u_t \)
approach: identify \(\theta\) sufficiently well to make good recommendations
Classically studied as an online decision problem (e.g. multi-armed bandits)
\(u_t\)
However, interests may be impacted by recommended content
preference state \(x_t\)
expressed preferences
recommended content
recommender policy
\(\mathbb E[y_t] = x_t^\top C u_t \)
updates to \(x_{t+1}\)
Implications for personalization [DM22]
It is not necessary to estimate preferences to make "good" recommendations
Instead of polarization, preferences "collapse" towards whatever users are often recommended
Randomization can prevent such outcomes
Even if harmful content is never recommended, can cause harm through preference shifts [CKEWDI24]
initial preference
resulting preference
recommendation
1. Motivation and Background
2. Learning Dynamics
inputs
outputs
time
3. Optimal Control
2. Learning Dynamics from Bilinear Observations
inputs
outputs
time
e.g. playlist attributes
e.g. listen time
inputs \(u_t\)
\( \)
outputs \(y_t\)
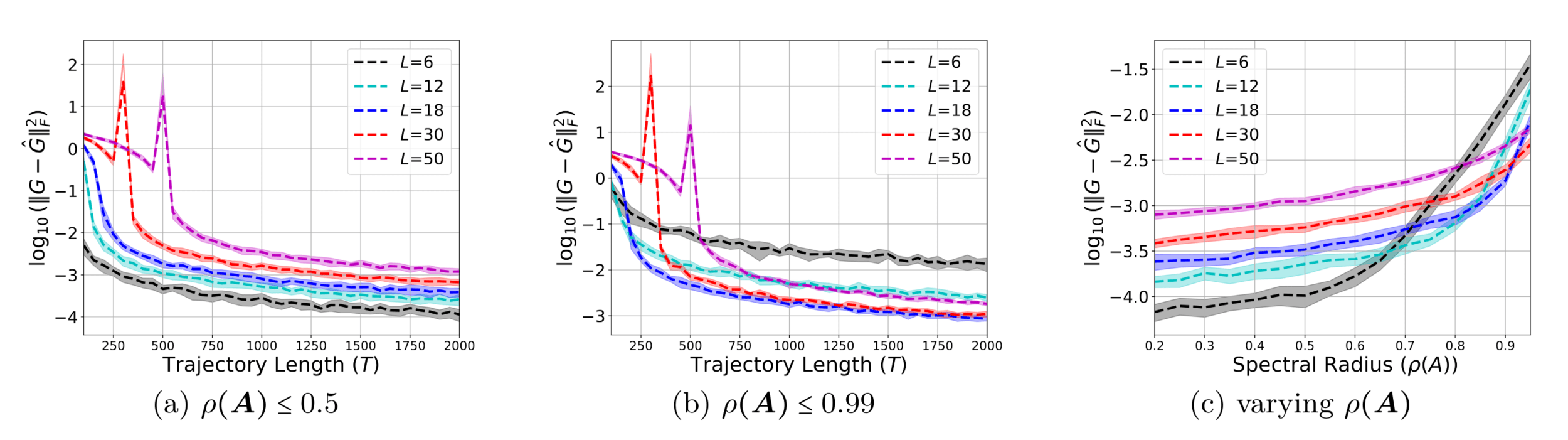
Input: data \((u_0,y_0,...,u_T,y_T)\), history length \(L\), state dim \(n\)
Step 1: Regression
$$\hat G = \arg\min_{G\in\mathbb R^{p\times pL}} \sum_{t=L}^T \big( y_t - u_t^\top \textstyle \sum_{k=1}^L G[k] u_{t-k} \big)^2 $$
Step 2: Decomposition \(\hat A,\hat B,\hat C = \mathrm{HoKalman}(\hat G, n)\)
(Omyak & Ozay, 2019)
\(t\)
\(L\)
\(\underbrace{\qquad\qquad}\)
inputs
outputs
time
Yahya Sattar
\(~\)
Yassir Jedra
$$\hat G = \arg\min_{G\in\mathbb R^{p\times pL}} \sum_{t=L}^T \big( y_t - u_t^\top \textstyle \sum_{k=1}^L G[k] u_{t-k} \big)^2 $$
\(t\)
\(L\)
\(\underbrace{\qquad\qquad}\)
\(\bar u_{t-1}^\top \otimes u_t^\top \mathrm{vec}(G) \)
inputs
outputs
time
Assumptions:
With probability at least \(1-\delta\), $$\|G-\hat G\|_{Z^\top Z} \lesssim \sqrt{ \frac{p^2 L}{\delta} \cdot c_{\mathrm{stability,noise}} }+ \rho(A)^L\sqrt{T} c_{\mathrm{stability}}$$
\(\hat G\)
Assumptions:
Choosing \(L=\log(T)/\log(\rho(A)^{-1})\)
With high probabilty, for bounded random design inputs \(u_{0:T}\), $$\mathrm{est.~errors} \lesssim \sqrt{ \frac{\mathsf{poly}(\mathrm{dimension})}{\sigma_{\min}(Z^\top Z)}}$$
$$ \lesssim \sqrt{ \frac{\mathsf{poly}(\mathrm{dim.})}{T}}$$
$$\hat G = \arg\min_{G\in\mathbb R^{p\times pL}} \sum_{t=L}^T \big( y_t - \bar u_{t-1}^\top \otimes u_t^\top \mathrm{vec}(G) \big)^2 $$
\(*\)
\(=\)
$$ = \begin{bmatrix}\bar u_{L-1}^\top \otimes u_L^\top \\ \vdots \\ \bar u_{T-1}^\top \otimes u_T^\top\end{bmatrix} =Z$$
2. Learning Dynamics from Bilinear Observations
Algorithm: nonlinear features
Analysis: blocking technique
Exploration: similar to linear setting
inputs
outputs
time
3. Optimal Control with Bilinear Observations
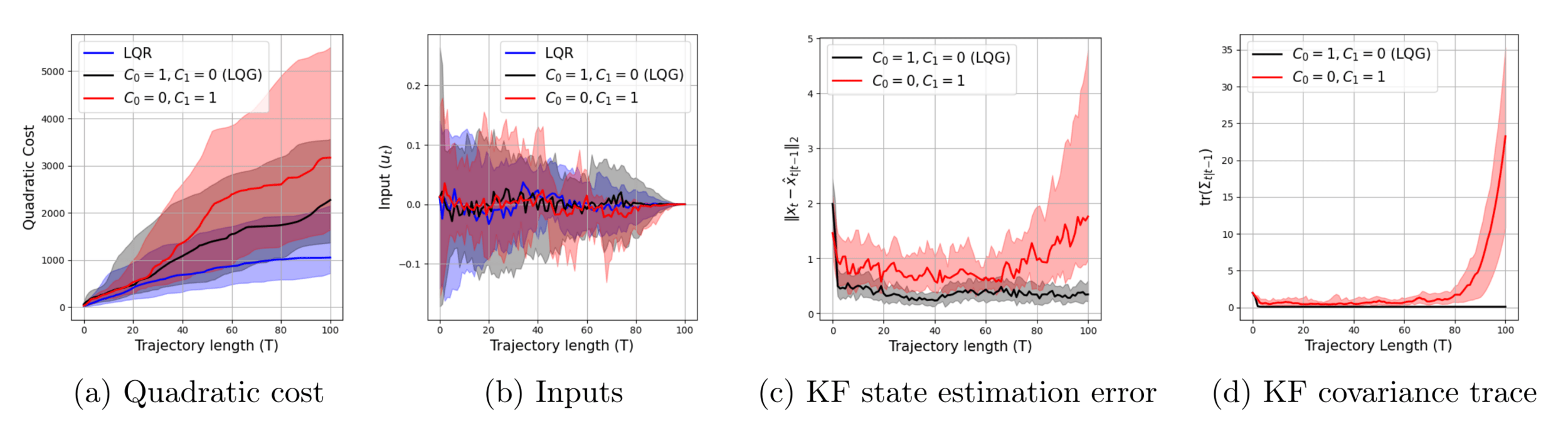
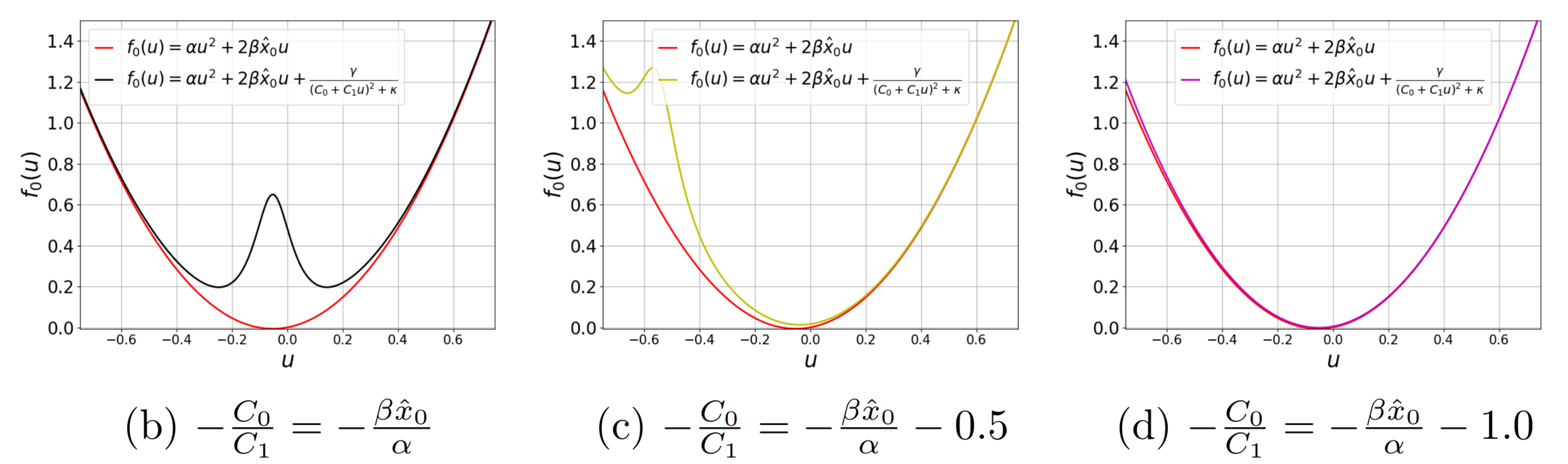
$$\min_{u_t=\pi_t(\mathcal I_t)} \mathbb E\left[x_T^\top Q x_T+ \sum_{t=1}^{T-1} x_t^\top Q x_t + u_t^\top R u_t \right]\\ \text{s.t.} \quad x_{t+1} = Ax_t + Bu_t + w_t \\\qquad\qquad\qquad y_t =\Big(C_0 + \sum_{i=1}^p u_t[i] C_i \Big)x_t + v_t$$
Small departure from classic LQG control
$$ x_{t+1} = \begin{bmatrix} 1 & 0.3 \\ 0 & 1\end{bmatrix} x_t + \begin{bmatrix}0.3 \\ 0 \end{bmatrix} u_t + w_t $$
$$ y_t = (C_0+C_1 u_t)\begin{bmatrix} 1 & 0\end{bmatrix} x_t + v_t$$
with \(Q=I\) and \(R=1000\)
1. Motivation and Background
2. Learning Dynamics
inputs
outputs
time
3. Optimal Control
(Oymak & Ozay, 2019)
By Sarah Dean



