Module 110 - Analyser et représenter des données avec des outils
Bonnes pratiques et fiabilité
partie 2
De quoi avons-nous parlé la semaine dernière ?
Temps à disposition : 5 minutes
Connectez-vous à : https://app.wooclap.com/EBFBDA

De quoi avons-nous parlé la semaine dernière ?
Objectifs du cours
- Expliquer les termes SRE, SLI, SLO, SLA
- Citez les bonnes pratiques du principe du moindre privilège

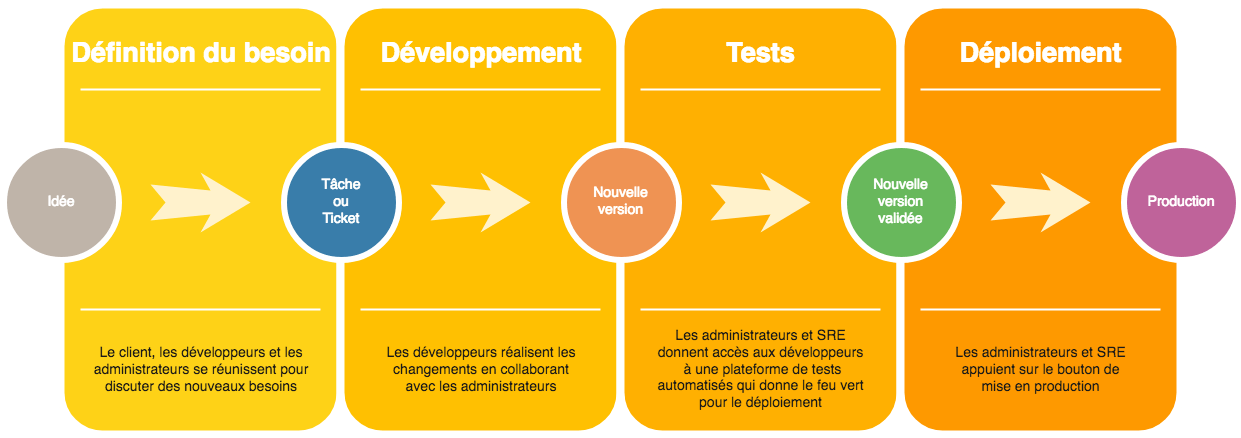
Concepts d’ingénierie de la fiabilité des sites (SRE)
L'ingénierie de la fiabilité des sites, ou SRE (Site Reliability Engineering), est une approche d'ingénierie logicielle pour l'exploitation informatique. Les équipes de SRE utilisent des logiciels, comme les logiciel de monitoring pour gérer des systèmes, résoudre des problèmes et automatiser des tâches liées à l'exploitation
Concepts d’ingénierie de la fiabilité des sites (SRE)
Le Site Reliability Engineering (SRE) vise à garantir la fiabilité des systèmes en mesurant leur performance à travers des indicateurs (SLI), en fixant des objectifs internes de qualité de service (SLO), et en s’assurant du respect des engagements contractuels envers les clients (SLA). Rôle de l’ingénieur SRE :
- Travailler au croisement du développement logiciel et des opérations système.
- Écrire du code pour automatiser l’infrastructure (IaC, pipelines CI/CD).
- Mettre en place des systèmes d’alerte, de logs et de métriques.
- Participer à la gestion d’incidents, à l’analyse post-mortem, et à l’amélioration continue.
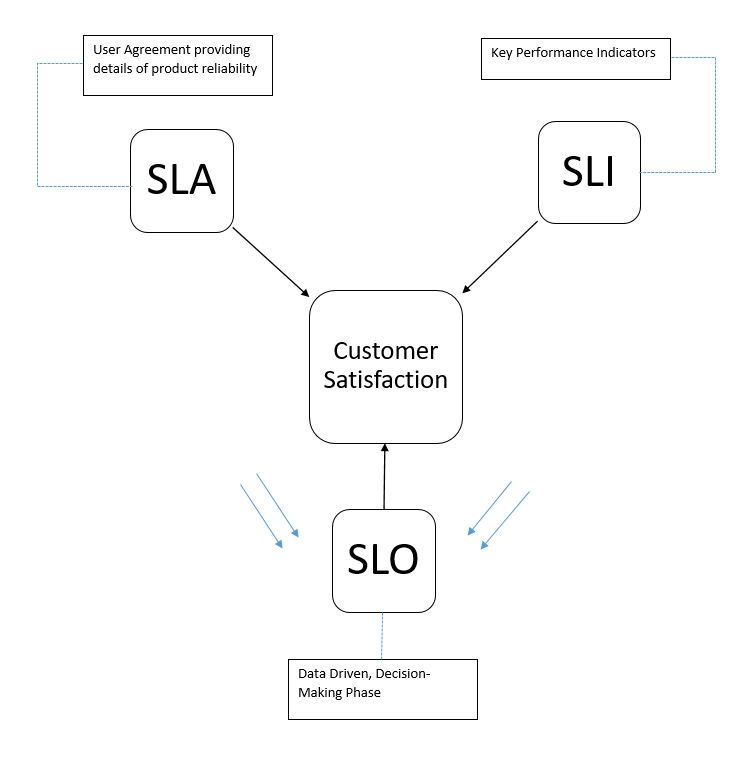
Concepts SLI
Un SLI (Service Level Indicator) est une mesure quantitative précise du comportement d’un système. Il est conçu pour refléter l’expérience réelle des utilisateurs.
| SLI | Description |
|---|---|
| Taux d’erreur | % des requêtes retournant un code ≠ 200 |
| Latence | Temps de réponse pour 95e percentile |
| Disponibilité | % du temps où le service répond correctement |
| Frais de saturation | Nombre de requêtes refusées ou limitées |
Concepts SLA
Le SLA (Service Level Agreement) est un contrat formel (souvent légal) entre un fournisseur de service et un client, fondé sur un ou plusieurs SLOs.
Exemple : Le service sera disponible à 99.9% sur un mois, sinon le client recevra un crédit de 20%.

Concepts SLO
Le SLO (Service Level Objective) fixe la cible de performance ou fiabilité attendue pour un SLI.
C’est une base de contrat interne qui permet aux équipes de mesurer objectivement la santé d’un service. Exemple :
Autres exemples :
- 99.95% de disponibilité sur 30 jours
- Moins de 0.1% d’erreurs 500
- 99% de requêtes réussies dans les 300ms
Budget d'erreur
Le budget d’erreur est une approche pragmatique pour équilibrer fiabilité et innovation.
SLO = 99.9% → Erreur tolérée = 0.1%
Sur un mois (30 jours = 43 200 minutes) → 43 minutes d’indisponibilité permises.
SRE intégré aux monitoring
| Intégration | En pratique |
|---|---|
| Choix des SLI pertinents | Utiliser des métriques comme le taux d’erreur HTTP, la latence 95e percentile, ou le succès des transactions. |
| Définition des SLO | Fixer des objectifs clairs, mesurables et réalistes. |
| Alerting intelligent | Déclencher une alerte seulement si le SLO est menacé (ex : taux d’erreurs > 0.1% pendant 10 minutes). |
| Dashboards centrés sur les utilisateurs | Visualiser la santé du service à travers les SLO. |
Respect du principe du moindre privilège (Least Information Principle)
Les outils de monitoring collectent, stockent et visualisent des données sensibles :
- Logs d'accès utilisateurs
- Données d'applications (requêtes, erreurs, payloads)
- Traces réseau, etc.
Si mal configurés, ces outils peuvent devenir une source majeure de fuite de données.

Respect du principe du moindre privilège (Least Information Principle)
Bonnes pratiques :
- Donner aux utilisateurs (analystes, développeurs, SRE) accès uniquement aux dashboards ou données nécessaires.
- Filtrer les données sensibles avant de les exposer dans les logs ou dashboards (ex : masquer les emails, tokens, numéros de carte).
- Utiliser des outils de monitoring qui supportent le contrôle d'accès granulaire (RBAC)
Exemple : Un développeur front n’a pas besoin de voir les logs de requêtes contenant des données personnelles, il devrait voir uniquement les erreurs applicatives.
Maintien de la conformité
Bonnes pratiques:
- Mettre en place une classification automatique des données dans les logs.
- Appliquer des politiques de rétention (ex : purger les logs contenant des identifiants utilisateurs au bout de 30 jours).
- Chiffrer les données de monitoring, au repos et en transit (surtout si elles passent par des systèmes tiers : Datadog, Sentry...).
- S’assurer que les logs d’audit sont immuables et bien conservés pour les obligations réglementaires.

Evaluation continue des processus
Les pipelines de monitoring évoluent : ajout de métriques, nouveaux microservices, migration cloud, les données collectées changent, il faut s’assurer qu’elles ne violent pas les principes de sécurité ou de conformité.
Evaluation continue des processus
Bonnes pratiques:
- Mettre en place une revue périodique des données collectées: collecte-t-on des données inutiles, trop sensibles, non masquées ?
- Faire des audits réguliers des accès aux outils de monitoring
- Utiliser des alertes de sécurité sur les anomalies dans les systèmes de logs (ex : afflux de logs contenant des tokens, ou détection de données personnelles non conformes)
- Valider que les données monitorées sont utiles et exploitables (éviter les métriques mortes ou obsolètes)
Exemple concret : L’équipe remarque qu’un volume inhabituel de logs contenant des données géographiques précises (coordonnées GPS) est collecté et stocké sans anonymisation.
Cas pratique

Effectuez le Cas pratique 7 - Rapport des visites
Temps: 45 minutes

Wooflash
Répondez aux différentes questions liées à la matière enseignée
Connectez-vous à : https://app.wooflash.com/join/1G69UJX7
110-6 Bonnes pratiques et fiabilité - partie 2
By Myriam Fallet



