A first look at bridging choice modeling and agent-based microsimulation in MATSim
Sebastian Hörl (presenting)
Milos Balac
Kay W. Axhausen
ABTMRANS Workshop 2018
Best paper award
Porto, 11 May 2018
Initial Idea
- Much work and effort put into choice modeling at IVT
- Discrete choice models are readily available
- Microcensus on Transport and Mobility
- Autonomous vehicles
- How to make use of them in MATSim?
Example: Multinomial logit model
P(k) = \frac{\exp(u_k)}{\sum_i \exp(u_i)}
u_{walking} = ?
u_{cycling} = ?
u_{car} = ?
u_{pt} = ?
Making discrete choices
- Score (utility) for each available
choice with deterministic and
random component
- Choice model
- Choice sampling
U_i=V_i+\epsilon_i
k = \text{argmax}_i \{ U_i,...,U_N \}
P(k) = \frac{\exp(U_k)}{\sum_i \exp(U_i)}
Making discrete choices

Making discrete choices
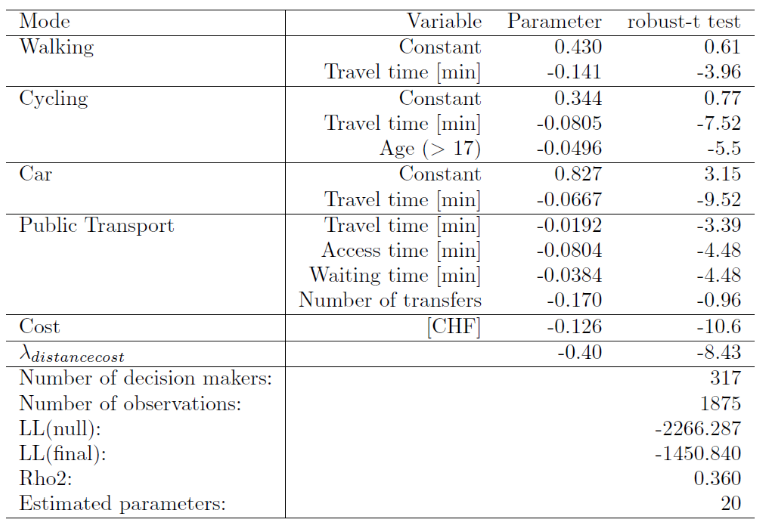
- Walking
- Travel Time:
- Travel Time:
- Cycling
- Travel Time:
- Travel Time:
- Car
- Travel Time:
- Cost:
- Public Transport
- Travel Time:
- Access Time:
- Waiting Time:
- Number of transfers:
- Cost:
V_{walking} = ?
V_{cycling} = ?
V_{car} = ?
V_{pt} = ?
Making discrete choices
V_{walking} = ?
V_{cycling} = ?
V_{car} = ?
V_{pt} = ?
P(walking) = ?
P(cycling) = ?
P(car) = ?
P(pt) = ?
Making discrete choices
- Probabilistic choice interpretation
- More complex models available
- Nested Logit
- Mixed Logit
- ...
Mode choice in MATSim
Almost purely random proposition of new plan
Score-based selection of plan from memory
Simulation
Scoring
Clean-up of worst plans until N are left
Initial execution is
necessary before
selection makes sense
First idea of integration
- Selection between chains
- Two components:
- Choice set generation
- A priori mode choice based on estimated travel characteristics
Choice set generation
- Obtain the set of all possible chains of modes for a given chain of trips with origin and destination
- Constrained by agent-level attributes (e.g. car availability)
- Constrained by continuity constraints (e.g. vehicle location)
- Maximum set:
- Feasible set:
|\mathcal{C}| = M^N
|\mathcal{C}_f \subset \mathcal{C}| = M^N - q
Choice set generation
\mathcal{C} = \left\{ (\text{walk}, \text{walk}, \text{walk}, \text{walk}, \text{walk}), ... \right\}
Start
Choice set generation
\mathcal{C} = \left\{ (\text{walk}, \text{walk}, \text{walk}, \text{walk}, \text{walk}), \right.
\left. (\text{car}, \text{car}, \text{car}, \text{car}, \text{car}), ... \right\}
Start
Choice set generation
\mathcal{C} = \left\{ (\text{walk}, \text{walk}, \text{walk}, \text{walk}, \text{walk}), \right.
\left. (\text{car}, \text{car}, \text{car}, \text{car}, \text{car}), \right.
\left. (\text{car}, \text{walk}, \text{public transit}, \text{car}, \text{car}), ... \right\}
Start
Selection procedure
- Problem: How to use a trip-based mode choice model for a whole chain?
- Three (imperfect) approaches
\tilde u_k = \sum_i u_{k,i}(\theta_{k,i})
k = \text{argmax}_k \left \{ \tilde u_1, ..., \tilde u_K \right \}
\tilde z_k = \sum_i u_{k,i} + \epsilon_{k,i}
Best response selection
k = \text{argmax}_k \left \{ \tilde z_1, ..., \tilde z_K \right \}
Total chain utility sampling
k \sim \text{Cat}(\tilde \pi_1, ..., \tilde \pi_K)
Naive chain sampling
with
\epsilon_{k,i} \sim \text{Gumbel}
and
\tilde \pi_k = \tilde w_k / \left( \sum_{k'} \tilde w_{k'} \right)
\tilde w_k = \prod_i \tilde \pi_{k,i}
\tilde \pi_{k,i} = \mathbb{P}(\hat \theta_{k,i})
First simulation results
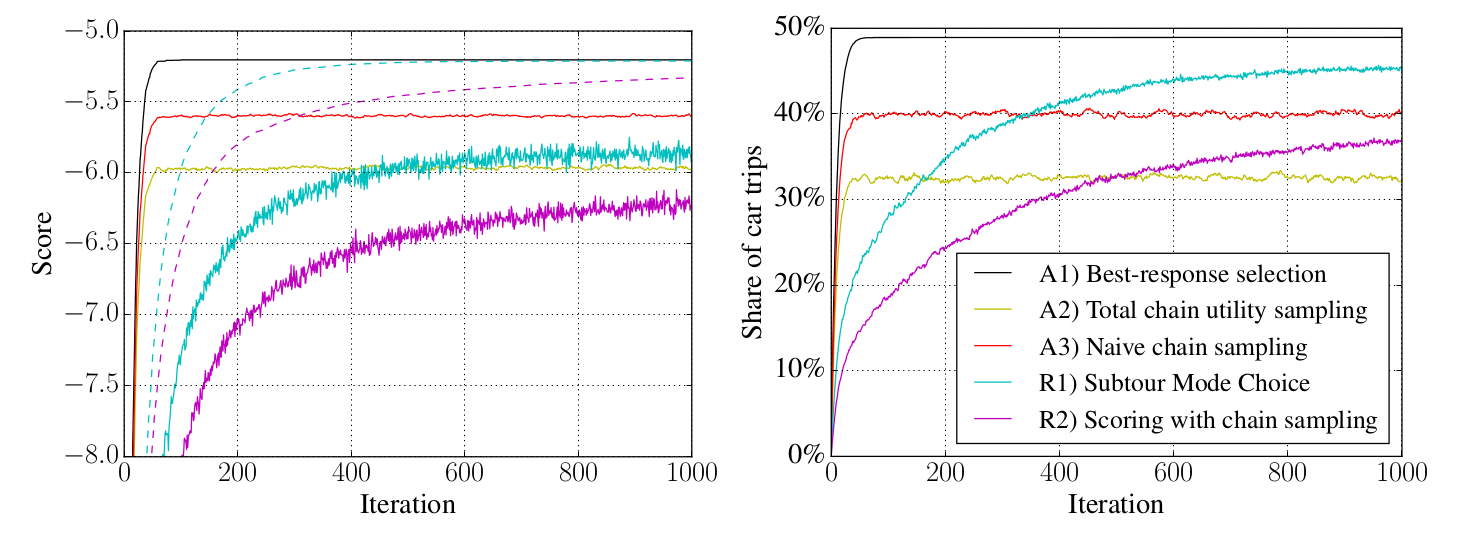
- Teleportation-based simulation
- Best-response is upper bound
- Fast convergence for tested approaches vs SMC
First simulation results
- Network-based simulation
- Best-response is not upper bound
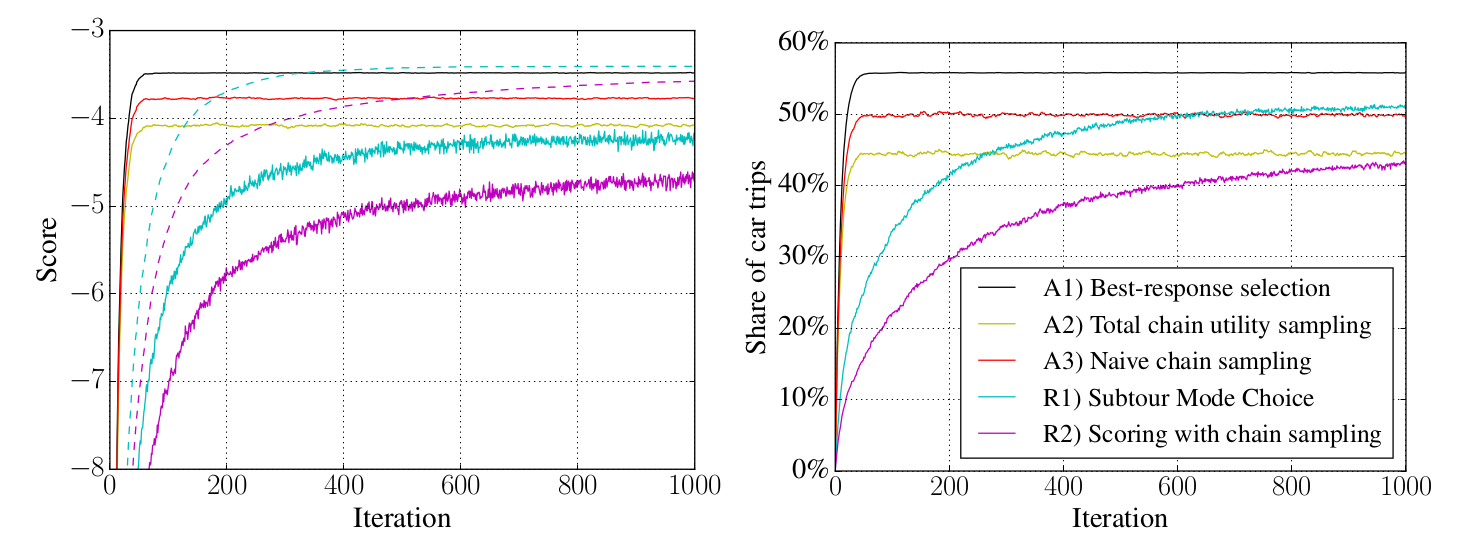
Conclusions from our experiment
- Questionable to draw conclusions from trip-based model in chain-based environment (MATSim)
- Choice model makes life easier - we can argue to skip some calibration work, faster convergence
- Choice model makes life harder - we need to come up with good estimates for the trip characteristics
- Which one is right?
Mode choice in MATSim
If memory size exceeds limit Then
- Remove plan with worst score in memory
If the removed plan was selected Then
- Select random plan from the remaining ones
End If
End If
- Choose a strategy by probability (given whether innovation is already turned off)
If chosen strategy is a selection strategy:
- Select new plan from existing ones according to strategy
Else (it is an innovation strategy)
- Copy a random plan from the existing ones and set as selected plan
- Apply mutation strategy to the newly selected plan
End If
Some thoughts on choice making in MATSim
- Imagine a MATSim run without innovation
- Choice set per agent is changed continuously
- Worst plan removal strategy has biggest influence on the procession of the choice set
- Choice set collapses for high number of iterations
- Finally, M plans with momentarily best score for the agent = (Stochastic) User Equilibrium
- Choice set per agent is changed continuously
Some thoughts on choice making in MATSim
- Except, there is innovation
- Random new plan in X% of iterations (e.g. every 20th)
-
Early stopping after N iterations to maintain variability
- So ...
- MATSim is a global search algorithm for the UE
- MATSim stops optimizing early to maintain a notion of a discrete plan choice
Short detour: One-agent toy examples
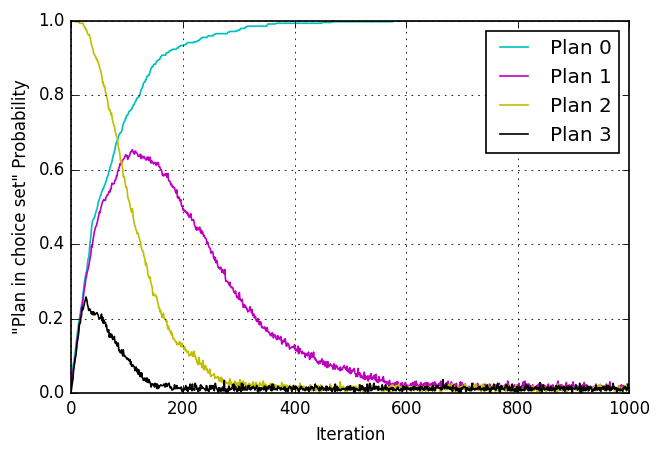
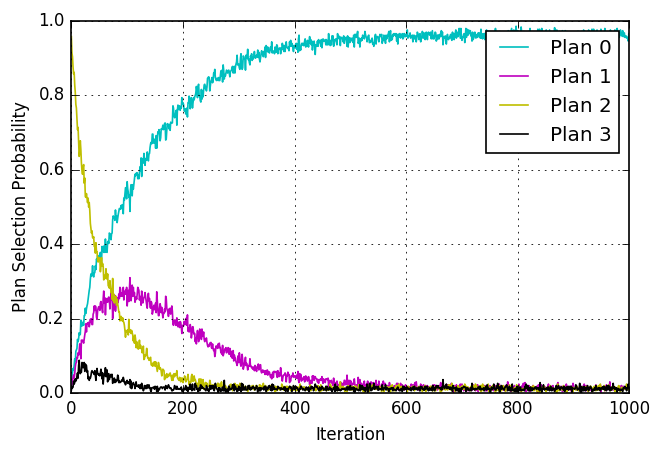
- Numerical experiment: One agent, four plans with predefined utilities
- Run MATSim selection / innovation procedure
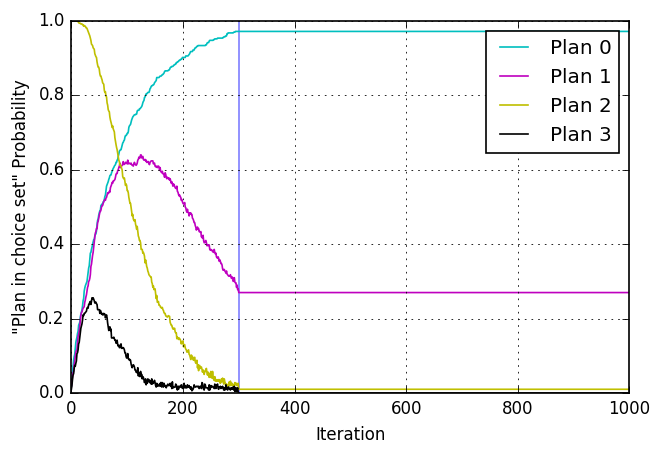
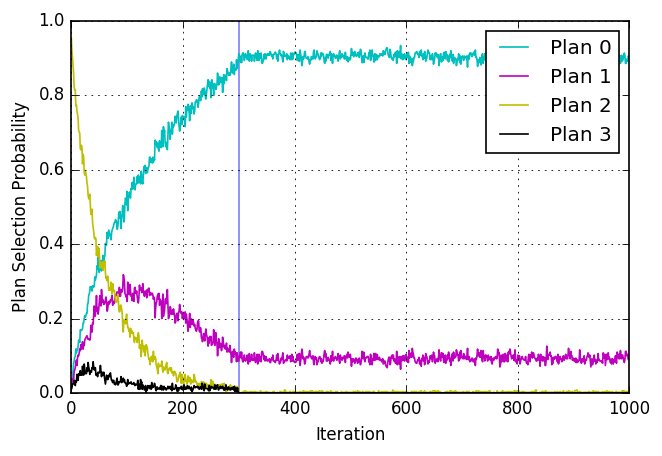
Short detour: One-agent toy examples
- Now without innovation after 300 iterations
The best of both worlds?
Model-based proposition of plans
MATSim scoring and selection
Estimates (model input)
Sampling of relevant alternatives
-
Improves convergence
-
Avoids "innovation turn-off"
- May introduce bias through estimates
-
Maintains stability
- Compensates for estimation bias
The best of both worlds?
Model-based proposition of plans
MATSim scoring and selection
Estimates (model input)
Sampling of relevant alternatives
- Condition: Any feasible can be sampled with non-zero probability
- The code is there (for mode choice)
- Chain sampler is available, scoring framework is available
- MATSim choice procedure is available
Can we do better?
- Why evolutionary algorithm? Notouriously hard to treat theoretically.
- We have:
- Prior score (during plan sampling)
- Posterior score (after simulation)
- Apply any rejection sampling approach (simulated annealing, Metropolis Hastings) on one plan per agent
- Natural convergence measure: Prior score vs. posterior score
Propose plan
Simulate plan
Score plan
Accept / Reject plan
a(s,s')=\max(1, \exp((s' - s)/\sigma))
Thanks!
Questions?
ABMTRANS 2018
By Sebastian Hörl
ABMTRANS 2018
11 May April 2018, Porto



