競技プログラミング練習会
2019 Normal
第4回 ソート、二分探索、データ構造
担当:kidman7
自己紹介
自己紹介
KMC-ID:kidman7
- 理学部2回生
- Python, C++を書いてます。
- After effectsとblenderとcinema4d勉強中
- 電子ピアノ(中古)を買いました。
- 昼夜逆転生活はじめました
- 家にこもってるので、一日一食で事足りる...
今日の内容
今日の内容
- ソート
- 二分探索
- 基本的なデータ構造の紹介
ソート
ソートって?
- ソートとは、配列などのデータを小さい順または大きい順に並べ替えること。
- 小さい順のことを昇順という。
- 大きい順のことを降順という。
- 以下では昇順ソートについてやっていく。
様々なソート
- ソートには色んなアルゴリズムがある。
- バブルソート
- マージソート
- クイックソート
- etc...
- 今日は上の3つのアルゴリズムについて紹介していく。
- 実際にソートするときは以下のSTLを使おう
- 昇順:sort(vec.begin(),vec.end());
- 降順:sort(vec.begin(),vec.end(),greater<>());
ソートの計算量
- 各ソートの計算量は(後で詳しくやる)
- バブルソート:
- マージソート:
- クイックソート:
- ソートアルゴリズムの計算量は 未満にならないことが証明されている。
O(n^2)
O(n\log{n})
O(n\log{n})
O(n\log{n})
安定ソート
- 安定ソート:同じ値があったとき、ソート後にその値が入れ替わらないソートのこと
(4Aと4Bを並べ替えたとき、逆になったりする)
- 今日やるソートでは、バブルソートとマージソートが安定ソート。クイックソートは安定ではない...
-
stable_sort(vec.begin(),vec.end());
- O(nlogn)で安定ソートができるSTL
バブルソート
バブルソート
- 実装は簡単
- 計算量が他のソートに比べて大きい
O(n^2)
バブルソート(アルゴリズム)
配列長nとする。
- 隣接した配列の要素を比較して昇順になっていなかったら入れ替えて昇順にする。
- これを前から順番にやっていく。
- これをn-1回行えばソート終了
バブルソート
- 隣接した配列の要素を比較する。
- これを前から順番にやっていく。
| index | 0 | 1 | 2 | 3 | 4 |
| 値 | 8 | 2 | 7 | 3 | 4 |
バブルソート
- 隣接した配列の要素を比較する。
- これを前から順番にやっていく。
| index | 0 | 1 | 2 | 3 | 4 |
| 値 | 8 | 2 | 7 | 3 | 4 |
バブルソート
- 隣接した配列の要素を比較する。
- これを前から順番にやっていく。
| index | 0 | 1 | 2 | 3 | 4 |
| 値 | 8 | 2 | 7 | 3 | 4 |
0番目>1番目なので入れ替え
バブルソート
- 隣接した配列の要素を比較する。
- これを前から順番にやっていく。
| index | 0 | 1 | 2 | 3 | 4 |
| 値 | 2 | 8 | 7 | 3 | 4 |
バブルソート
- 隣接した配列の要素を比較する。
- これを前から順番にやっていく。
| index | 0 | 1 | 2 | 3 | 4 |
| 値 | 2 | 8 | 7 | 3 | 4 |
バブルソート
- 隣接した配列の要素を比較する。
- これを前から順番にやっていく。
| index | 0 | 1 | 2 | 3 | 4 |
| 値 | 2 | 7 | 8 | 3 | 4 |
バブルソート
- 隣接した配列の要素を比較する。
- これを前から順番にやっていく。
| index | 0 | 1 | 2 | 3 | 4 |
| 値 | 2 | 7 | 8 | 3 | 4 |
バブルソート
- 隣接した配列の要素を比較する。
- これを前から順番にやっていく。
| index | 0 | 1 | 2 | 3 | 4 |
| 値 | 2 | 7 | 3 | 8 | 4 |
バブルソート
- 隣接した配列の要素を比較する。
- これを前から順番にやっていく。
| index | 0 | 1 | 2 | 3 | 4 |
| 値 | 2 | 7 | 3 | 8 | 4 |
バブルソート
- 隣接した配列の要素を比較する。
- これを前から順番にやっていく。
| index | 0 | 1 | 2 | 3 | 4 |
| 値 | 2 | 7 | 3 | 4 | 8 |
バブルソート
3. これを最大n-1回繰り返す
| index | 0 | 1 | 2 | 3 | 4 |
| 値 | 2 | 7 | 3 | 4 | 8 |
バブルソート
3. これを最大n-1回繰り返す
| index | 0 | 1 | 2 | 3 | 4 |
| 値 | 2 | 7 | 3 | 4 | 8 |
バブルソート
3. これを最大n-1回繰り返す
| index | 0 | 1 | 2 | 3 | 4 |
| 値 | 2 | 7 | 3 | 4 | 8 |
バブルソート
3. これを最大n-1回繰り返す
| index | 0 | 1 | 2 | 3 | 4 |
| 値 | 2 | 3 | 7 | 4 | 8 |
バブルソート
3. これを最大n-1回繰り返す
| index | 0 | 1 | 2 | 3 | 4 |
| 値 | 2 | 3 | 4 | 7 | 8 |
バブルソート
3. これを最大n-1回繰り返す
| index | 0 | 1 | 2 | 3 | 4 |
| 値 | 2 | 3 | 4 | 7 | 8 |
バブルソート
3. これを最大n-1回繰り返す
| index | 0 | 1 | 2 | 3 | 4 |
| 値 | 2 | 3 | 4 | 7 | 8 |
今回は3回目でソート済みとなった。
バブルソート
- なぜ最大n-1回で終了すると言えるのか
- 1回の試行で最大の数字が右端に行く。
- このとき右端を除いた配列について同じことをすると、その中で最大の数字が右端に行く。
- これを繰り返して配列のサイズが1になるまで繰り返すとn-1回。
バブルソート(計算量)
\sum\limits_{i=1}^{n-1}(n-i) = \dfrac{1}{2}(n-1)n=O(n^2)
- 配列サイズが1になるまで、隣接要素の比較を繰り返す。
バブルソート(コード例)
swap(a,b); :aとbの中身を入れ替えるSTL
//バブルソート
void bubble_sort(vector<int> &vec){
//n-1周全てを左から比較する。
for(int i=0;i<(int)vec.size()-1;++i){
//右端にできたソート済部分を除いて左から順に見る
for(int j=0;j<(int)vec.size()-i-1;++j){
//左>右なら
if(vec.at(j)>vec.at(j+1)) {
//右<左となるように入れ替える。
swap(vec.at(j),vec.at(j+1));
}
}
}
}&vecは参照渡しと言って、同じものを渡している
マージソート
マージソートとは
- マージ:複数の集合や配列を結合すること。
- ソート前の配列を真ん中で2つにする
- その2つの配列をそれぞれマージソートする
- 2つの配列をいい感じにマージする。
- 配列の要素を全て分解し、いい感じにマージを繰り返すことでソートする。
マージソートのイメージ
- 元の配列を真ん中で2つに分ける。
| index | 0 | 1 | 2 | 3 | 4 | 5 |
| 値 | 6 | 2 | 9 | 5 | 1 | 4 |
マージソートのイメージ
- 元の配列を真ん中で2つに分ける。
| index | 0 | 1 | 2 |
| 値 | 6 | 2 | 9 |
| index | 0 | 1 | 2 |
| 値 | 5 | 1 | 4 |
| index | 0 | 1 | 2 | 3 | 4 | 5 |
| 値 | 6 | 2 | 9 | 5 | 1 | 4 |
マージソートのイメージ
- 分けた配列をそれぞれマージソートしておく。
| index | 0 | 1 | 2 |
| 値 | 6 | 2 | 9 |
| index | 0 | 1 | 2 |
| 値 | 5 | 1 | 4 |
| index | 0 | 1 | 2 | 3 | 4 | 5 |
| 値 | 6 | 2 | 9 | 5 | 1 | 4 |
マージソートのイメージ
- 分けた配列をそれぞれマージソートしておく。
| index | 0 | 1 | 2 |
| 値 | 2 | 6 | 9 |
| index | 0 | 1 | 2 |
| 値 | 1 | 4 | 5 |
| index | 0 | 1 | 2 | 3 | 4 | 5 |
| 値 | 6 | 2 | 9 | 5 | 1 | 4 |
マージソートのイメージ
- 最後に無限を追加すると比較がうまく行くので、各配列の最後に大きい値を入れておく。
| index | 0 | 1 | 2 |
| 値 | 2 | 6 | 9 |
| index | 0 | 1 | 2 |
| 値 | 1 | 4 | 5 |
マージソートのイメージ
| index | 0 | 1 | 2 | 3 |
| 値 | 2 | 6 | 9 |
| index | 0 | 1 | 2 | 3 |
| 値 | 1 | 4 | 5 |
\infty
\infty
- 最後に無限を追加すると比較がうまく行くので、各配列の最後に大きい値を追加する。
マージソートのイメージ
- ソート済み配列同士を小さい方からマージしたものは同じくソート済みである。
| index | 0 | 1 | 2 | 3 |
| 値 | 2 | 6 | 9 |
| index | 0 | 1 | 2 | 3 |
| 値 | 1 | 4 | 5 |
\infty
\infty
| index | 0 | 1 | 2 | 3 | 4 | 5 |
| 値 |
マージ後の配列
マージソートのイメージ
- ソート済み配列同士を小さい方からマージしたものは同じくソート済みである。
| index | 0 | 1 | 2 | 3 |
| 値 | 2 | 6 | 9 |
| index | 0 | 1 | 2 | 3 |
| 値 | 1 | 4 | 5 |
\infty
\infty
| index | 0 | 1 | 2 | 3 | 4 | 5 |
| 値 |
マージ後の配列
1の方が小さいので1を入れる。
マージソートのイメージ
- ソート済み配列同士を小さい方からマージしたものは同じくソート済みである。
| index | 0 | 1 | 2 | 3 |
| 値 | 2 | 6 | 9 |
| index | 0 | 1 | 2 | 3 |
| 値 | 1 | 4 | 5 |
\infty
\infty
| index | 0 | 1 | 2 | 3 | 4 | 5 |
| 値 | 1 |
マージ後の配列
1の方が小さいので1を入れる。
マージソートのイメージ
- ソート済み配列同士を小さい方からマージしたものは同じくソート済みである。
| index | 0 | 1 | 2 | 3 |
| 値 | 2 | 6 | 9 |
| index | 0 | 1 | 2 | 3 |
| 値 | 1 | 4 | 5 |
\infty
\infty
| index | 0 | 1 | 2 | 3 | 4 | 5 |
| 値 | 1 |
マージ後の配列
マージソートのイメージ
- ソート済み配列同士を小さい方からマージしたものは同じくソート済みである。
| index | 0 | 1 | 2 | 3 |
| 値 | 2 | 6 | 9 |
| index | 0 | 1 | 2 | 3 |
| 値 | 1 | 4 | 5 |
\infty
\infty
| index | 0 | 1 | 2 | 3 | 4 | 5 |
| 値 | 1 | 2 |
マージ後の配列
マージソートのイメージ
- ソート済み配列同士を小さい方からマージしたものは同じくソート済みである。
| index | 0 | 1 | 2 | 3 |
| 値 | 2 | 6 | 9 |
| index | 0 | 1 | 2 | 3 |
| 値 | 1 | 4 | 5 |
\infty
\infty
| index | 0 | 1 | 2 | 3 | 4 | 5 |
| 値 | 1 | 2 | 4 |
マージ後の配列
マージソートのイメージ
- ソート済み配列同士を小さい方からマージしたものは同じくソート済みである。
| index | 0 | 1 | 2 | 3 |
| 値 | 2 | 6 | 9 |
| index | 0 | 1 | 2 | 3 |
| 値 | 1 | 4 | 5 |
\infty
\infty
| index | 0 | 1 | 2 | 3 | 4 | 5 |
| 値 | 1 | 2 | 4 | 5 |
マージ後の配列
マージソートのイメージ
- ソート済み配列同士を小さい方からマージしたものは同じくソート済みである。
| index | 0 | 1 | 2 | 3 |
| 値 | 2 | 6 | 9 |
| index | 0 | 1 | 2 | 3 |
| 値 | 1 | 4 | 5 |
\infty
\infty
| index | 0 | 1 | 2 | 3 | 4 | 5 |
| 値 | 1 | 2 | 4 | 5 | 6 |
マージ後の配列
マージソートのイメージ
- ソート済み配列同士を小さい方からマージしたものは同じくソート済みである。
| index | 0 | 1 | 2 | 3 |
| 値 | 2 | 6 | 9 |
| index | 0 | 1 | 2 | 3 |
| 値 | 1 | 4 | 5 |
\infty
\infty
| index | 0 | 1 | 2 | 3 | 4 | 5 |
| 値 | 1 | 2 | 4 | 5 | 6 | 9 |
マージ後の配列
マージソートのアルゴリズム
- このようにソート済みの配列同士を正しい手順でマージすることでソートできる。
- 配列の中身を全てバラバラにして、マージしまくれば、全ての要素をソートできる。
| index | 0 | 1 | 2 | 3 | 4 | 5 |
| 値 | 1 | 2 | 4 | 5 | 6 | 9 |
マージ後の配列
マージソートのアルゴリズム
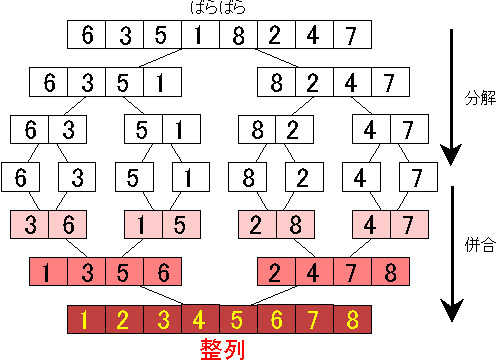
マージソートの計算量
- さっきの図の、全部バラバラの状態から、1つ下の状態に移るのに\(O(N)\)かかる。
- 2つの配列をマージするのに、その配列のサイズの和だけ計算量がかかるため。
- 図でバラバラの状態からソート済みになるまでの高さは\(\log N\)程度(正確には\(\log 2\))。
- よって、全体で\(O(N\log N)\)かかる。
クイックソート
クイックソートの概要
- ソート前の配列から基準値(pivot)より大きいか小さいかでグループ分けする。
- 基準値はなんでも良い。
- 中央値がベストだが、それを計算するのに時間をかけても意味がない。
- 基準値はなんでも良い。
- その2つのグループで、さらに基準値を決めてグループ分けする。
- これをサイズが1になるまで繰り返す。
- そのグループをそのまま合併する。
クイックソートの例
- 基準値を決める。
- 今回は最初の値を基準値にする。
| index | 0 | 1 | 2 | 3 | 4 |
| 値 | 3 | 5 | 2 | 4 | 1 |
クイックソートの例
- 基準値より大きいものとそうでないものでグループ分けする。
| index | 0 | 1 | 2 | 3 | 4 |
| 値 | 3 | 5 | 2 | 4 | 1 |
3より小さい配列
3より大きい配列
クイックソートの例
- 基準値より大きいものとそうでないものでグループ分けする。
| index | 0 | 1 | 2 | 3 | 4 |
| 値 | 3 | 5 | 2 | 4 | 1 |
| 2 | 1 |
| 5 | 4 |
3より小さい配列
3より大きい配列
クイックソートの例
| index | 0 | 1 | 2 | 3 | 4 |
| 値 | 3 | 5 | 2 | 4 | 1 |
| 2 | 1 |
| 5 | 4 |
3より小さい配列
3より大きい配列
- グループ分けした配列を同じようにクイックソートしておく。
クイックソートの例
| index | 0 | 1 | 2 | 3 | 4 |
| 値 | 3 | 5 | 2 | 4 | 1 |
| 1 | 2 |
| 4 | 5 |
3より小さい配列
3より大きい配列
- グループ分けした配列を同じようにクイックソートしておく。
クイックソートの例
| 3 |
| 1 | 2 |
| 4 | 5 |
3より小さい配列
3より大きい配列
- この小さい配列と基準値と大きい配列をそのままマージする。
基準値
| index | 0 | 1 | 2 | 3 | 4 |
| 値 |
クイックソートの例
| 3 |
| 1 | 2 |
| 4 | 5 |
3より小さい配列
3より大きい配列
- この小さい配列と基準値と大きい配列をそのままマージする。
基準値
| index | 0 | 1 | 2 | 3 | 4 |
| 値 | 1 | 2 | 3 | 4 | 5 |
クイックソートの例
- これでソート終了!!
| index | 0 | 1 | 2 | 3 | 4 |
| 値 | 1 | 2 | 3 | 4 | 5 |
再帰の終了地点
- マージソートと同じようにサイズが1か0になるまで分解すると再帰が終了する。
実際の動き
| 3 | 5 | 2 | 4 | 1 |
| 2 | 1 |
| 5 | 4 |
| 3 |
| 2 |
| 1 |
| 4 |
| 5 |
| 1 | 2 | 3 | 4 | 5 |
| 1 | 2 |
| 4 | 5 |
クイックソートの特徴
- 長さNの配列なら、平均的に
- ただし最悪の場合
- また、同じ値が複数あるとき入れ替わるかもしれない。(安定でない)
- 最悪のケースでマージソートに劣るが、一般にはクイックソートの方が速いことがほとんど。
- 乱択アルゴリズムで最悪の場合が起こらないように工夫したりすることも
O(N\log{N})
O(N^2)
ここまでの話ですが…
- バブルソート以外は実装が面倒で自分で書くのはあまりに面倒。
- ソートアルゴリズムを知っていることは重要だが、STLを使うべき。
- なのでsortのSTL を使おう。
二分探索
二分探索とは
- ソート済みの領域から1つの要素を探す時、真ん中の要素と比較すると効率が良い。
- これを繰り返すと探索時の計算量を飛躍的に落とせる。
どういうこと?
| index | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
| 値 | 2 | 3 | 4 | 7 | 8 | 10 | 11 |
配列から2のあるindexを見つける。
どういうこと?
| index | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
| 値 | 2 | 3 | 4 | 7 | 8 | 10 | 11 |
配列から2のあるindexを見つける。
真ん中の値と比較する
2<7
どういうこと?
| index | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
| 値 | 2 | 3 | 4 | 7 | 8 | 10 | 11 |
配列から2のあるindexを見つける。
真ん中の値と比較する
2<7
この区間には2はない
探索範囲
どういうこと?
| index | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
| 値 | 2 | 3 | 4 | 7 | 8 | 10 | 11 |
配列から2のあるindexを見つける。
探索範囲の真ん中の値と比較する
2<3
探索範囲
この区間には2はない
どういうこと?
| index | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
| 値 | 2 | 3 | 4 | 7 | 8 | 10 | 11 |
配列から2のあるindexを見つける。
探索範囲の真ん中の値と比較する
2<3
探索範囲
この区間には2はない
どういうこと?
| index | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
| 値 | 2 | 3 | 4 | 7 | 8 | 10 | 11 |
配列から2のあるindexを見つける。
探索範囲の真ん中の値と比較する
2=2
発見!!
この区間には2はない
二分探索の特徴
- 通常通り探索すると、最大7回調べる必要がある。
- 二分探索すると、最大でも3回で済む。
- 一回あたりで探索範囲を半分にできるので、配列長Nに対し
O(\log{N})
二分探索 コード例
// v 中に t を見つけたら そのindex 、なければ -1を返す
int binsearch(vector<int> v, int t) {
int l = 0, r = v.size(); // 最初は全範囲 (半開区間)
while (l+1 < r) { // 範囲の長さが 0 でない限り繰り返す
int m = l + (r - l) / 2; // 中間の点...オーバーフロー対策の式
// 中間点で一致した = 見つかった
if (v[m] == t) return m;
// 見つからなかったら、値の大小に応じて範囲を狭める
if (v[m] < t) l = m;
else r = m;
}
// ここまできたら見つからなかった → v中にない
return -1;
}例題:探索
- 長さ\(N\)の配列\(v\)と\(Q\)回のクエリが与えられる。
- 各クエリで聞かれた値が\(v\)に存在するなら"Yes",ないなら"No"を出力せよ。
- 制約:
N\leqq 10^5,\ Q\leqq 10^5
考察:探索
- そのまま\(Q\)回探索すると、1度の探索に かかるので、全体で
- これだと最悪 かかるので無理そう。
O(N)
O(NQ)
10^{10}
考察2:探索
- さっきやった二分探索を使ってみたい。
- そのために配列vをソートする。
- その後Q回二分探索すれば良い。
- 全体で
- これで全体で大体 くらい
- これなら間に合いそう。
O((N+Q)\log{N})
O(N\log{N})
10^{6}
O(Q\log{N})
二分探索STL
- 二分探索も自分で実装する必要はない。
-
binary_search(v.begin(),v.end(),x);
- 配列vからxがあれば1、なければ0を返す。
- lower_bound(v.begin(),v.end(),x);
- 配列vからx以上の最初の値のイテレータを返す。(なければv.end())
-
upper_bound(v.begin(),v.end(),x);
- 配列vからxを超える最初の値のイテレータを返す。(なければv.end())
- (lowerとupperで要素の数も数えられる)
イテレータって何?
- indexに近い存在。
- v.begin()やv.end()もイテレータ。
- i番目の要素のイテレータはv.begin()+iで表せる。
- v.end()はv.begin()+nと一致する。
- 故にv.end()が示す値は存在しない。
- null文字みたいなもの(最後の要素はv.end()-1)
- 以下itrをvのイテレータとする。
- distance(v.begin(),itr)でindexを取得できる。
- *itrでその要素が示す値を見れる。
例題のコード例
#include<bits/stdc++.h>
using namespace std;
int main(){
int n; cin >> n; //配列長nの宣言・入力
vector<int> v(n); //配列vの宣言
for(int i=0;i<n;++i){
cin >> v.at(i); //vの入力
}
sort(v.begin(),v.end()); //vの昇順ソート
int q; cin >> q; //クエリ数qの宣言・入力
for(int i=0;i<q;++i){
int x; cin >> x;//探索クエリxの宣言・入力
if(binary_search(v.begin(),v.end(),x)==1){
//二分探索して見つかったとき、"Yes"を出力。
cout << "Yes" << endl;
} else cout << "No" << endl; //なかったとき"No"を出力
}
}データ構造
データ構造とは(ざっくり)
- データを持っておく方法を決めておくことで、様々な計算量を減らすことができる代物。
- これを知っているだけで稀に問題が解けることもあるので学んで帰ろう!
- とはいえ、途轍もない情報量なので名前と概要を覚えることを目標にしよう(後から調べられる)
今日やるデータ構造たち
- pair
- vector(復習)
- set
- map
- stack
- queue
- priority_queue
全部STLにある!!!!
pair
pairとは
- その名の通り2つの異なる値を保持できる。
- 比較するときは第一変数を優先し、それが同じ値なら第二変数を比べる。
- 比較が優秀で、元のindexを保持したままsortしたいときに便利。
pairの宣言と参照
-
pair<型1,型2> 変数名;
- これで第一変数と第二変数の型を指定して宣言する。
- 以下、変数名をprとすると、
-
pr.first, pr.second
- 第一変数,第二変数の値を参照できる。
pair関連のSTL
-
make_pair(x,y);
- 変数x,yでpairを作る。
- 主にpairに代入するときやpairと比較するときに使う。
-
比較について
- まずfirstの順番で比較
- firstが同じ値の場合、secondで比較
pairコード例
#include<bits/stdc++.h>
using namespace std;
int main(){
pair<int,int> pr; //pairを両方intで宣言
pr.first = 5; //1つ目に5を代入
pr.second = 3; //2つ目に3を代入
/*
pair<int,int> pr = {5,3};
これはC++11からなら大丈夫(なはず)
*/
if(pr < make_pair(5,4)){ //(5,4)より小さいとき
//今回は実行される
//2番目の値を出力
cout << pr.second << endl; //3が出力される。
}
}可変長配列 vector
vectorとは
- 後からサイズを変更できる配列で、末尾に値を付け足したり、削除するのが得意。
- ランダムアクセス(index指定で参照)できる。
-
以下vをvectorとする。
-
v.push_back(x);
- xを末尾に付け足す。O(1)
-
v.emplace_back(x);
- xを直接コンストラクトして末尾に付け足す(おすすめ)
-
v.pop_back();
- 末尾の値を削除。O(1)
-
v.at(i),v[i]
- i番目の値を参照する。O(1)
-
v.push_back(x);
vector<pair<int,int>> vec;
vec.emplace_back(3,5);
vec.push_back(make_pair(3,5));emplace_backとpush_back
コードが上のほうが奇麗で
かつ、上のほうが内部の処理回数が少ないので
上を使いましょう
ただし、push_backと違ってエラーを吐いてくれないので注意
vectorの要素の型
- vectorの要素の型は何でもOK。
- int, vectorはもちろん、pairや他のデータ構造もだいたい入れられます。
- vector<pair<int,int>> vecp; など
- int, vectorはもちろん、pairや他のデータ構造もだいたい入れられます。
- 次以降にやるデータ構造も、それぞれの条件を満たしていれば、要素の型は何でもOK。
vectorの苦手なこと
-
途中の値を削除したり、途中に値を挿入すると、それ以降の値を全てずらす必要があるのでO(N)かかる。
-
v.insert(v.begin()+i,x);
- vのi番目に値xを挿入する。O(N)
-
v.erase(v.begin()+i);
- i番目の値を削除する。O(N)
-
v.erase(v.begin()+i,v.begin()+j);
- 区間[i,j)の値を削除する。O(N)
-
v.insert(v.begin()+i,x);
vectorの苦手なこと2
- ソートされていない領域の探索
- O(N)かかる。
- もちろんソートされていれば二分探索でO(logN)ですむ。
集合
set / multiset
setの概要
- 要は集合のこと。
- 集合内に値が存在するか否かを管理。
- 探索とデータの追加、削除がO(logN)でできる。
- また、unordered_setというのもあり、これは上記のことが平均O(1)でできる。
- ランダムアクセスはできない。
- 重複は認められない。(追加されない。)
- 重複を許す、multiset / unordered_multiset もある。
- 今日やるデータ構造で1番使う気がする(主観)
setの中身
- set, multisetは内部でソートされた状態で持っている。
- だから探索が二分探索同じくO(logN)でできる、みたいな解釈をすると良いと思う。
- unordered付きは名前の通り昇順じゃないので注意。その分速い。
setの宣言
- set<型> 変数名;
- これで型を内部にもつsetを宣言できる。
- multisetやらunordered_setも大体同じ。
- ただし、型となるものは比較できる必要がある。
- pairは大丈夫。
- vectorとかは流石に無理。
setの関数
- stをsetとする。(重複はない)
-
st.insert(x);
- 値xをstに追加する。O(logN)
-
st.erase(x);
- 値xをstから削除する。O(logN)
-
st.find(x);
- 値xのイテレータを返す。なければst.end()を返す。O(logN)
-
st.count(x);
- 値xがあれば1、なければ0を返す。O(logN)
setのイテレータ操作で全列挙
- setは内部でソートされた状態でデータを持っているので、イテレータを最初から辿ることで昇順にデータを取得できる。
set<int> st = {5,1,3,2,4,6};
//beginから順番にイテレータを辿る。
//これによって、昇順ソートされたものと同等に出力できる。
//autoで初期化すれば、自動で型を決めてくれる。
for(auto itr = st.begin();itr!=st.end();++itr){
cout << *itr << endl; //*をつけて要素にアクセス。
//1,2,3,4,5,6が改行で区切られて出力される。
}
//以下でも同じ挙動をする(拡張for文)
for(auto e: st){
cout << e << endl;
}multisetの関数
- mstをmultisetとする。重複OK。
-
mst.insert(x);
- 値xをmstに追加する。O(logN)
-
mst.erase(x);
- 値xをmstから全て削除する。O(logN)
-
mst.find(x);
- 値xの含まれる最初のイテレータを返す。なければmst.end()を返す。O(logN)
-
mst.count(x);
- 値xの数を返す。O(logN+xの数)
unordered_set, unordered_multisetについて
- set, multisetでO(logN)だったことが平均O(1)で済むのでとても強い。(でも最悪O(N))
- 実際はそんなに速くないことが多いので注意(元のsetの半分ほどの計算時間がかかる)
- また、ハッシュ関数がその型に定義されている必要があるので、int,stringなどの基本型なら大丈夫だが、pairなどは使えない。
- unorderedの名の通り、ソートされた状態では並んでない。
連想配列
map
mapの概要
- 配列と似ているが、indexが整数でなくても良い。(mapでのindexをキーと呼ぶ)
- friend["John"] = "Mike"; みたいなことができる。
- アクセスにO(logN)かかるが、探索もO(logN)ですむ。
- setと同じように常にソートした状態で持っているため。
- 数学における写像に近いイメージ。
- setと同じようにunordered_mapもある。
mapの宣言
-
map<キーの型,要素の型> 変数名;
- キーの型と要素の型を指定して宣言する。
-
キーの型は比較できる必要がある。
- 要素の型は特に条件なし。
mapの関数
- 以下mpをmapとする。
-
mp[key] = x;
- keyの先の値がなければ追加してxにする。
- あればxに書き換える。
- O(logN)
-
mp[key]
- keyの先の値を参照する。
- なければ値の型のデフォルト値になる(int型なら0)
- O(logN)
mapの関数2
- 以下mpをmapとする。
-
mp.find(key);
- あればkeyと値のpairのイテレータを返す。
- なければmp.end()を返す。
- O(logN)
-
mp.erase(key);
- keyの先の値を削除する。
- O(logN)
unordered_map
- mapでO(log N)でできたことが平均O(1),最悪O(N)でできる。
- 注意事項はunordered_setと同じなので割愛。
スタック
stack
stackの概要
- Last In, First Out(LIFO)で、最後に入れたものを最初に処理するデータ構造
- あんまり使わないかも…(vectorの下位互換みたいなところもあるし)
- 次回やる深さ優先探索で使えるが、再帰で書くことが多い。
(自分はよくスタックで書くけど...)

stackの宣言
-
stack<型> 変数名;
- これで要素の型を指定して宣言する。
stackの関数
- 以下stをstackとする。
- 全てO(1)
-
st.push(x);
- stの末尾にxを追加。
-
st.pop();
- stの末尾の要素を削除。
-
st.top()
- stの末尾の要素を取得
-
st.empty()
- stが空ならtrue(1),そうでないならfalse(0)を返す。
キュー
queue
queueの概要
- First In, First Out(FIFO)で最初に入れたものを最初に処理するデータ構造
- 次回やる、幅優先探索で使います。

queueの宣言
-
queue<型> 変数名;
- 要素の型を指定して宣言する。
queueの関数
- 以下qをqueueとする。
- 全てO(1)
-
q.push(x);
- qの末尾にxを追加する。
-
q.pop();
- qの先頭の要素を削除する。
-
q.front()
- qの先頭の要素を取得する。
-
q.empty()
- qが空ならtrue(1),そうでないならfalse(0)を返す。
優先度付きキュー
priority_queue
priority_queueの概要
- 最も大きいものや小さいものを最初に取り出すデータ構造。
- 正確には、優先度を定義して、最も優先度の高いものを取り出す。
- 重要度は高く、第8回のdijkstra法などで出てくる。
priority_queueの宣言
-
priority_queue<型> 変数名;
- 要素の型を指定して宣言。
- デフォルトでは最大のものから取得する。
-
priority_queue<型,vector<型>,greater<>> 変数名;
- こうすると最小のものから取得できる。
- すごい複雑で覚えにくい
- 後ろのgreater<>は比較関数を自作しても大丈夫
priority_queueの関数
- qをpriority_queueとする。
-
q.push(x);
- qにxを追加する。
- O(logN)
-
q.pop();
- qの優先度最高のものを削除する。
- O(logN)
-
q.top();
- qの優先度最高のものを取得する。
- queueなのにtop…注意!
- O(1)
その他のデータ構造
両端キュー deque
- dqをdequeとする
- 先頭/末尾に値をつけたり消したりがO(1)。
- さらにランダムアクセスまでO(1)。
- dq.push_front(x); / dq.push_back(x);
- 先頭/末尾に値を付け足す。
- dq.push_front(); / dq.push_back();
- 先頭/末尾の値を削除する。
- dq[i]
- i番目の値を参照。
- 基本的にstack,queue,vectorで事足りるのでそんなに使わない。(pythonならdequeは活躍するけど)
双方向連結リスト list
- (場所さえ分かっていれば。)任意の場所に値を挿入したり、削除したりをO(1)でできる。
- listのイテレータは双方向イテレータなので、任意箇所を参照するのに、O(N)かかる。
- lstをlistとする。itrをlistのイテレータとする。
- lst.insert(itr,x);
- lsのitrの場所にxを挿入する。O(1)
- 返し値に挿入後のイテレータを返す。
- lst.erase(itr);
- lsのitrの場所の値を削除。O(1)
- 返し値に削除後のイテレータを返す。
まとめ:データ構造
- 各構造の概要と名前だけでも覚えて帰ってくれれば後はGoogleせんせえが教えてくれる。
┏━━━━━━━━━━━┳━━┓
┃ c++ set ┃検索┃
┗━━━━━━━━━━━┻━━┛
-
- このサイトは僕も結構見ます。
参考文献
- プログラミングコンテストチャレンジブック第二版
- 通称 蟻本。
- アルゴリズムのあれこれが載ってます。
- 競プロerのほとんどが持っている。
- 競プロやるなら、買って損はないと思います。
- 去年のスライド
次回予告
- 次回は 全探索 BFS DFS
かなーーーーー
コンテスト
- コンテスト中にスライドを見たり、ググったりしてくれて全然良いです。
- 分からないことがあればどんどん質問してください!
Copy of 第3回:ソート,二分探索,データ構造
By Seiji M
Copy of 第3回:ソート,二分探索,データ構造
発表日時 2019年4月26日(金)


