
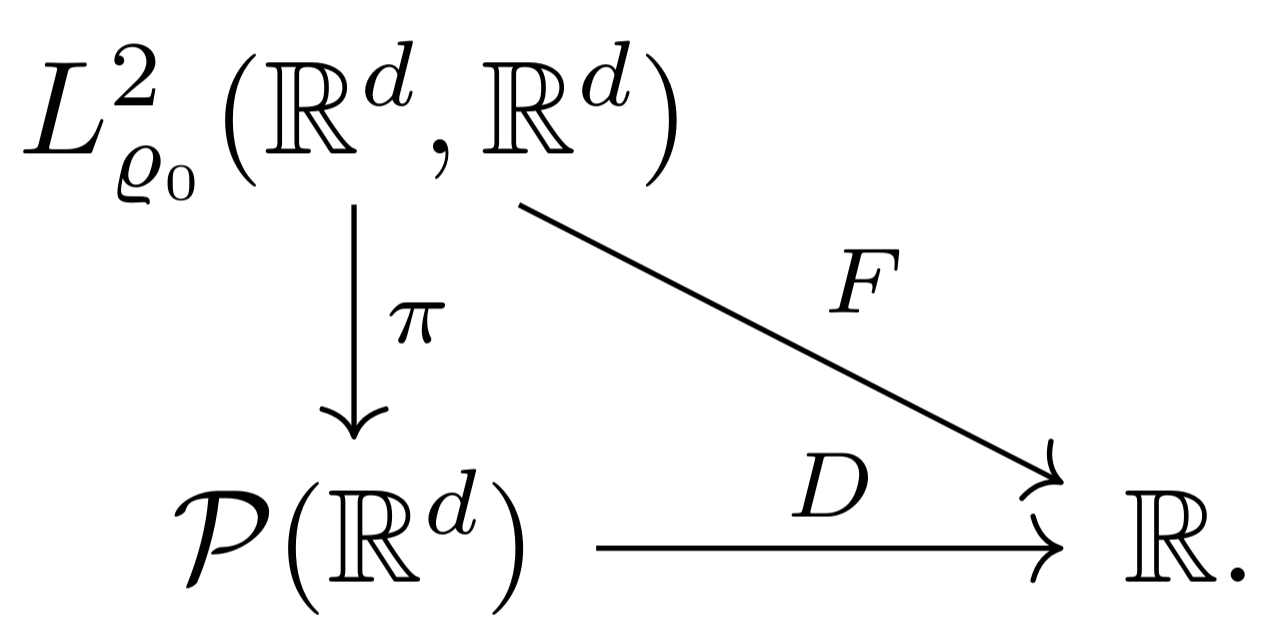
Théo Dumont
PhD student in optimal transport & geometry @ Université Gustave Eiffel
Learning Monge maps by lifting and constraining the relative entropy gradient flow
Théo Dumont
Univ. Gustave Eiffel
theo.dumont@univ-eiffel.fr
T.D., Théo Lacombe, François-Xavier Vialard. Learning Monge maps by lifting and constraining Wasserstein gradient flows
(on arXiv on Monday!).
Flow map
Brenier's theorem
Let \(\rho_0\in\mathcal P(\mathbb R^d)\) s.t. \(\rho_0\ll \mathrm dx\). Then for any \(\gamma\in\mathcal P(\mathbb R^d)\) there exists a unique solution to OT, and it is the gradient of a convex function \(\phi:\mathbb R^d\to\mathbb R\), that is, \[T^{\varrho_0}_{\gamma}=\nabla \phi.\]
Wasserstein gradient flow
(Fokker-Planck)
Convergence of the entropy flow
Suppose that \(\gamma\) is log-concave. Then the Wasserstein gradient flow of the relative entropy converges to \(\gamma\).
Sub-optimality of the flow map
The limit \(S_\infty\) of the flow map \(S_t\) of the relative entropy is not the optimal transport map between \(\varrho_0\) and \(\gamma\).
Proposition.
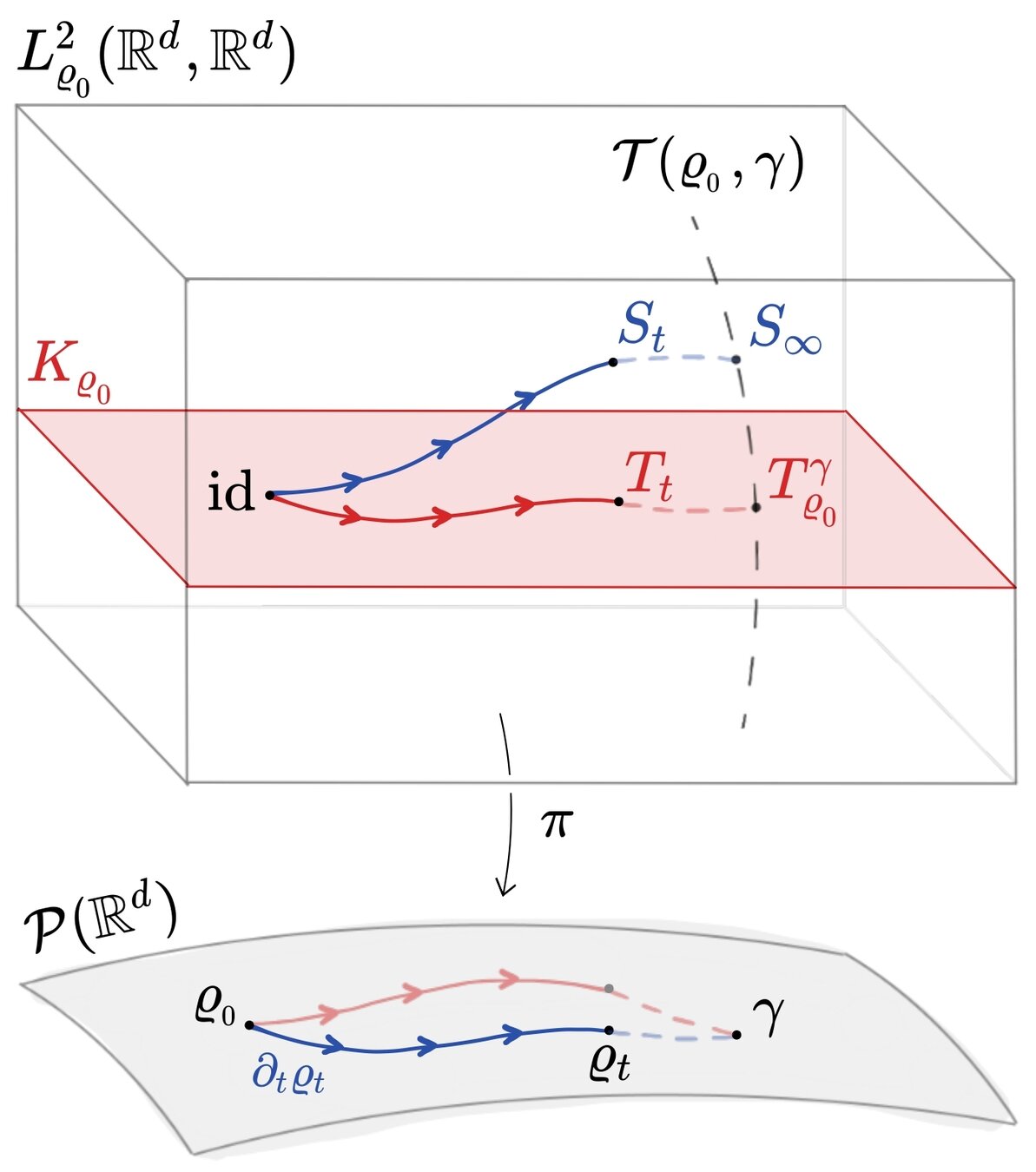
\(K\) is convex and closed in \(L^2_{ \varrho_0}(\mathbb R^d,\mathbb R^d)\).
The idea: lift the functional \(D\) in the simple (Hilbert) space \(L^2_{\varrho_0}(\mathbb R^d,\mathbb R^d)\), and constrain the flow to stay in the closed convex set \(K\) of optimal transport maps.
Theorem 1. Existence of solutions
Let \(D:\mathcal P(\mathbb R^d)\to\mathbb R\) be l.s.c., differentiable, and
\(\lambda\)-convex along generalized geodesics with anchor point \(\varrho_0\).
Then, for every \(t_{\text{max}}>0\), there exists a solution \((T_t)_t\in H^1([0,t_{\text{max}}],K)\) to (Cons.GF).
Theorem 2. Convergence
Under the same assumptions, suppose also \(\lambda>0\). Then \[\forall t\geq0,\quad D(T_t{}_*\varrho_0)-D(\gamma)\leq e^{-2\lambda t}\big(D(\varrho_0)-D(\gamma)\big)\] and \[\forall t\geq0,\quad \|T_t-T_{\varrho_0}^{\gamma}\|^2_{L^2_{\varrho_0}}\leq\frac{4}{\lambda} e^{-2\lambda t}\big(D(\varrho_0)-D(\gamma)\big)\]
Corollary. For the relative entropy
Let \(D(\varrho)\coloneqq \operatorname{KL}(\varrho\,|\,\gamma)\), where \(\gamma\) is some \(\lambda\)-log-concave measure with \(\lambda>0\).
Then (Cons.GF) admits a solution and it converges to the OT map \(T_{\varrho_0}^\gamma\) in \(O(e^{-2\lambda t})\).
Lifting functionals
Can we build a flow that remains an OT map?
?
The constrained gradient flow
The constrained gradient flow: theory
Implementation
Let \(D:\mathcal P(\mathbb R^d)\to\mathbb R\).
The lifted functional \(F\) is defined as \(F=D\circ\pi\),
where \(\pi:T\mapsto T_*\varrho_0\).
Theorem.
This is a Wasserstein natural gradient descent in \(\Theta\).
Some properties:
Natural gradient descent/flow
Optimal transport maps
Optimal transport problem (Monge)
Let \(K\) be the set of optimal transport maps:
\(\mathcal P(\mathbb R^d)\): probability measures of finite second-order moment
Flow map of the relative entropy
For the relative entropy / Kullback-Leibler divergence
and the gradient flow is
quadratic optimization problem
For instance: \(\nabla\) ICNN, \(\nabla\) LSE
Parameterize \(K\):
Choices for \(D\):
(Cons.GF)
Let \(D:\mathcal P(\mathbb R^d)\to\mathbb R\) be some functional on \(\mathcal P(\mathbb R^d)\), minimal at \(\gamma\).
Constrained gradient flow
(Cons.GF)
the vector field is
Flow map
[AGS, 2008], [LS, 2022]
By Théo Dumont
[Poster] On the existence of Monge maps for the Gromov-Wasserstein problem (https://arxiv.org/abs/2210.11945https://arxiv.org/abs/2210.11945


