CS110 Lecture 15: More on http requests
Principles of Computer Systems
Winter 2021
Stanford University
Computer Science Department
Instructors: Chris Gregg and
Nick Troccoli


Today's Learning Goals
- Dig deeper into GET
- Learn about HEAD and POST
- Discuss proxy servers (assignment 6)
- Let's look at the GET HTTP request in a bit more detail.
- This is the most common web request, and it is sent by a web browser to a page when you first request the page. For example, if we go to http://web.stanford.edu/class/cs110, we can see the request on Chrome in the View->Developer->Developer Tools->Networking panel:
CS110 Lecture 15: More on http requests
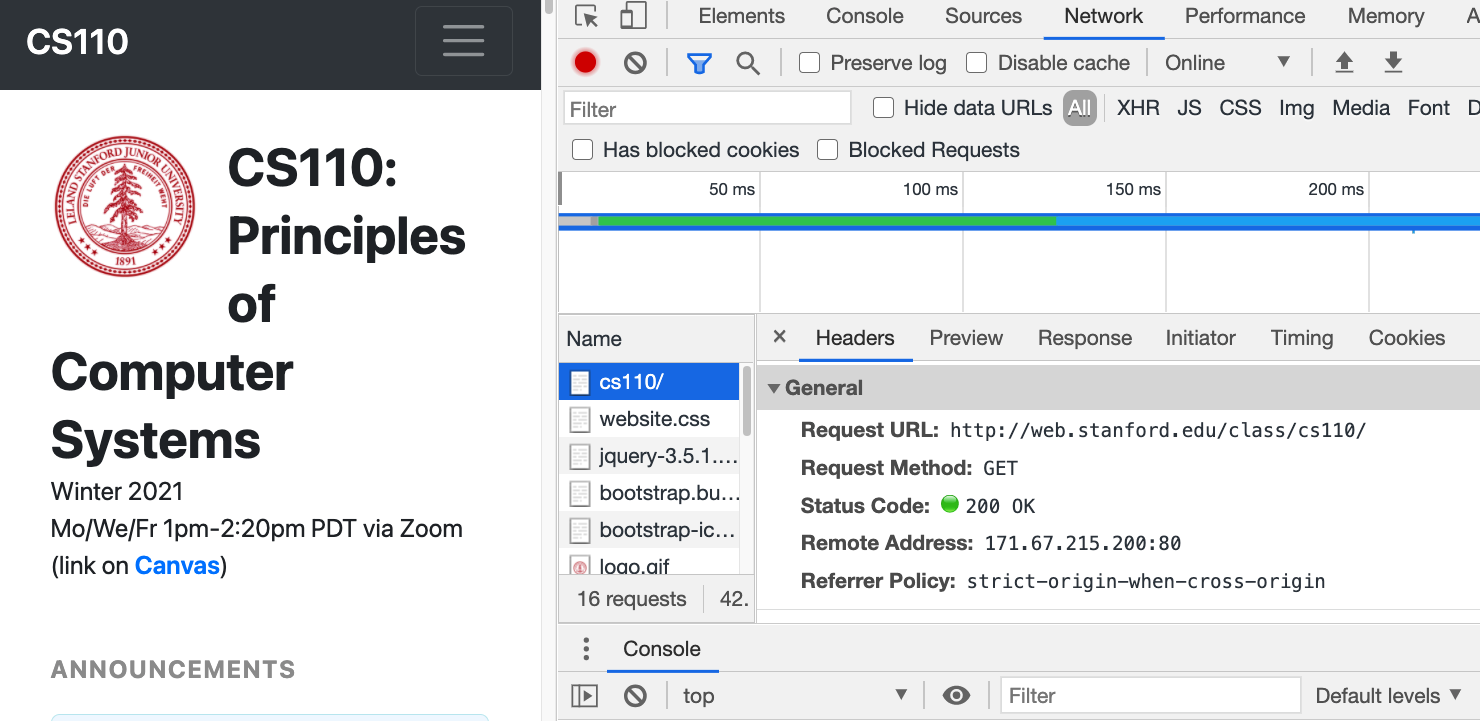
- We see that the request was a GET request, and that the status code that was returned was "200 OK"
- What other status codes are possible?
- You can find a list of status codes here: https://en.wikipedia.org/wiki/List_of_HTTP_status_codes
- The general form of the code is as follows:
- Code 100: Informational
- e.g., not frequently used, but can be as simple as "I'm working on it" (code 102 Processing)
- Code 200: Success
- 200-level codes indicate that a request was received and accepted. The most common code is 200 OK, meaning that the request was fine and the response contains the answer to the request
- Code 300: Redirection
- This means that the client must take more steps to complete the request. The most common is 301 Moved Permanently, which will also provide the address to make a proper request to. Browsers usually make the follow-on requests without alerting the user.
- Code 400: Client Error
- These messages say that the client made an error. Typical messages are 401 Unauthorized (incorrect authorization) or 403 Forbidden (a bit more general than an authorization issue)
- Code 500: Server Error
- These errors are caused by the server having some trouble -- often it is because the web page developer didn't set permissions properly, or has a bug in their backend code. The most common is 500 Internal Server Error.
- Code 100: Informational
CS110 Lecture 15: More on http requests
- As always, programmers love humor, and there are some humorous responses
- 418 I'm a Teapot was an April Fools joke that may have referred to one of the first web pages and web cams in existence (in 1991), which was a page dedicated to showing an image of how full a coffee pot was in a particular office.
- 451 Unavailable for Legal Reasons (get it?) is a response that means that the server cannot return the request because of a legal issue, such as government-censored content.
- You can also think of the general codes as follows...
CS110 Lecture 15: More on http requests

- Back to the original request -- if we look at the request itself in Chrome, we can see the details and headers:
CS110 Lecture 15: More on http requests
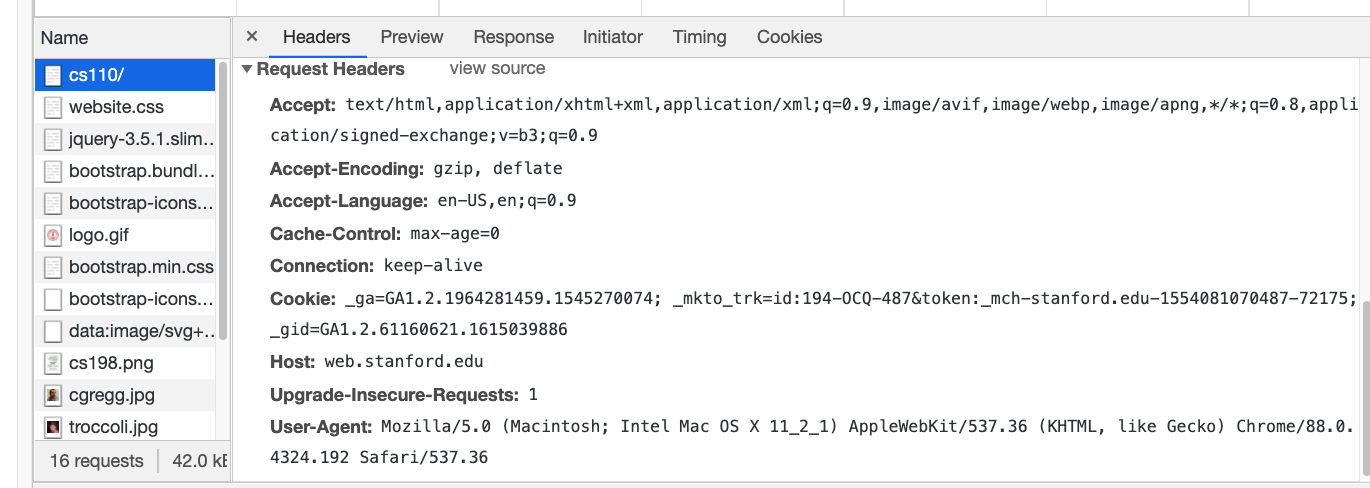
- As you can see, the browser accepts lots of different types (including "*/*" which basically means it will try to figure out any response).
- It also accepts compressed (gzip, deflate) pages, which can speed up the response
- If a site we request previously set a "cookie", that cookie can be sent during the request
- The "User-Agent" line tells the server the browser type, which can be useful if different browsers need different content.
- If we wanted our website to return a compressed page, we could do so (we also check if the request allows gzip). The following is modified from the scrabble-word-finder-server (full program here):
CS110 Lecture 15: More on http requests
static void returnWebpage(iosockstream &ss) {
bool foundGzip = checkHeadersForGzip(ss);
string fullText, line, filename;
if (foundGzip) {
filename = "words.gz";
} else {
filename = "/usr/share/dict/words";
}
ifstream fileToRead(filename);
while (getline(fileToRead, line)) fullText += line + "\n";
fileToRead.close();
ss << "HTTP/1.1 200 OK\r\n";
ss << "Content-Type: text/plain; charset=UTF-8\r\n";
if (foundGzip) {
ss << "Content-Encoding: gzip\r\n";
}
ss << "Content-Length: " << fullText.size() << "\r\n\r\n";
ss << fullText << endl << flush;
}static bool checkHeadersForGzip(iosockstream& ss) {
string line;
bool foundGzip = false;
do {
getline(ss, line);
if ((line.find("Accept-Encoding:") != string::npos) && (line.find("gzip") != string::npos)) {
foundGzip = true;
}
} while (!line.empty() && line != "\r");
return foundGzip;
}We pre-compressed our file:
gzip -c /usr/share/words/dict > words.gz
- Let's turn our attention to another HTTP request, the HEAD request.
- HEAD is basically an exact duplicate of GET, except that only the headers are returned. It is an error to return a body from a HEAD request.
- The reason for sending a HEAD request is to get the headers before making the actual request.
- Perhaps a browser wants to determine the length of the body of the response, and determine if it wants to make the request or not
- Example:
CS110 Lecture 15: More on http requests
$ telnet web.stanford.edu 80
Trying 171.67.215.200...
Connected to web.Stanford.EDU.
Escape character is '^]'.
HEAD /class/cs110/ HTTP/1.1
Host: web.stanford.edu
HTTP/1.1 200 OK
Date: Sun, 07 Mar 2021 20:10:11 GMT
Server: Apache
Accept-Ranges: bytes
Content-Length: 41776
Content-Type: text/html
Connection closed by foreign host.- Another important HTTP request is the POST request.
- POST is used to send data to a web server.
- It could be a web form, or a file, or some other data for the web server to act upon.
- Unlike a GET request, a POST request can change something on the server, such as updating a database, or storing a file.
- Here is an example web page that sends a simple form when the user clicks the "Submit" button:
CS110 Lecture 15: More on http requests
<!DOCTYPE html>
<html>
<body>
<h1>The form method="post" attribute</h1>
<form action="/action_page.cgi" method="post" target="_blank">
<label for="fname">First name:</label>
<input type="text" id="fname" name="fname"><br><br>
<label for="lname">Last name:</label>
<input type="text" id="lname" name="lname"><br><br>
<input type="submit" value="Submit">
</form>
<p>Click on the submit button, and the form
will be submittied using the POST method.</p>
</body>
</html>
- More on POST
- Often the POST payload is in simple "application/x-www-form-urlencoded" form, which means it looks like a URL, with a key/value list (e.g.,
fname=Chris&lname=Gregg) - The html on the previous page sends the following response (see this code for an example of reading the response and parroting it back to the page that requested it)
- Often the POST payload is in simple "application/x-www-form-urlencoded" form, which means it looks like a URL, with a key/value list (e.g.,
CS110 Lecture 15: More on http requests
Host: myth57.stanford.edu:13133
Connection: keep-alive
Content-Length: 23
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 11_2_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.192 Safari/537.36
Origin: http://myth57.stanford.edu:13133
Content-Type: application/x-www-form-urlencoded
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Referer: http://myth57.stanford.edu:13133/
Accept-Encoding: gzip, deflate
Accept-Language: en-US,en;q=0.9
Cookie: _ga=GA1.2.1964281459.1545270074; _mkto_trk=id:194-OCQ-487&token:_mch-stanford.edu-1554081070487-72175; _gid=GA1.2.61160621.1615039886
fname=Chris&lname=Gregg- More on POST
- POST requests can also hold data in binary form, or multiple pieces of data. When you see a form like the following, it will upload the text and both files in one POST:
CS110 Lecture 15: More on http requests
<form action="http://localhost:8000" method="post" enctype="multipart/form-data">
<p><input type="text" name="text" value="text default">
<p><input type="file" name="file1">
<p><input type="file" name="file2">
<p><button type="submit">Submit</button>
</form>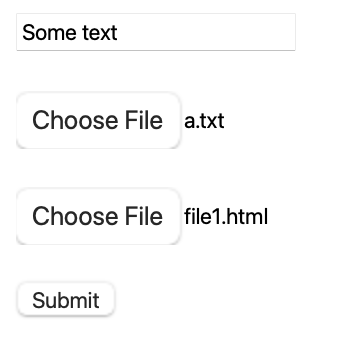
CS110 Lecture 15: More on http requests
- You can see the result of the request on the previous page by running
nc -l localhost 8000
- Note the
Content-Type: multipart/form-data; boundary=----WebKitFormBoundaryIVpTQH4nQEVWt9pR
POST / HTTP/1.1
Host: localhost:8000
Content-Type: multipart/form-data; boundary=----WebKitFormBoundaryIVpTQH4nQEVWt9pR
Origin: null
Connection: keep-alive
Upgrade-Insecure-Requests: 1
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0.3 Safari/605.1.15
Content-Length: 493
Accept-Language: en-us
Accept-Encoding: gzip, deflate
------WebKitFormBoundaryIVpTQH4nQEVWt9pR
Content-Disposition: form-data; name="text"
Some text
------WebKitFormBoundaryIVpTQH4nQEVWt9pR
Content-Disposition: form-data; name="file1"; filename="a.txt"
Content-Type: text/plain
This is the a.txt file.
------WebKitFormBoundaryIVpTQH4nQEVWt9pR
Content-Disposition: form-data; name="file2"; filename="file1.html"
Content-Type: text/html
<!DOCTYPE html><title>Content of a.html.</title>
------WebKitFormBoundaryIVpTQH4nQEVWt9pR--- A web proxy server is a server that acts as a go-between from your browser to sites on the Internet. Proxies can serve many purposes:
- Block access to certain websites
- Block access to certain documents (big documents, .zip files, etc.)
- Act as an anonymizer to strip data from headers about what the real IP address of the client is, or by stripping out cookies or other identifying information. The Tor network, using onion routing performs this role (among other roles, such as protecting data with strong encryption)
- Intercept image requests, serving only upside-down versions of images.
- Intercept all traffic and redirect to kittenwar.com.
- Cache requests for static data (e.g., images) so it can later serve local copies rather than re-request from the web.
- Redirect to a paywall (e.g., what happens at airports)
Lecture 15: HTTP Web Proxy
- We have built a very basic proxy for you, and you need to set up Firefox (or another browser, but we suggest Firefox) to forward all web requests to the proxy:
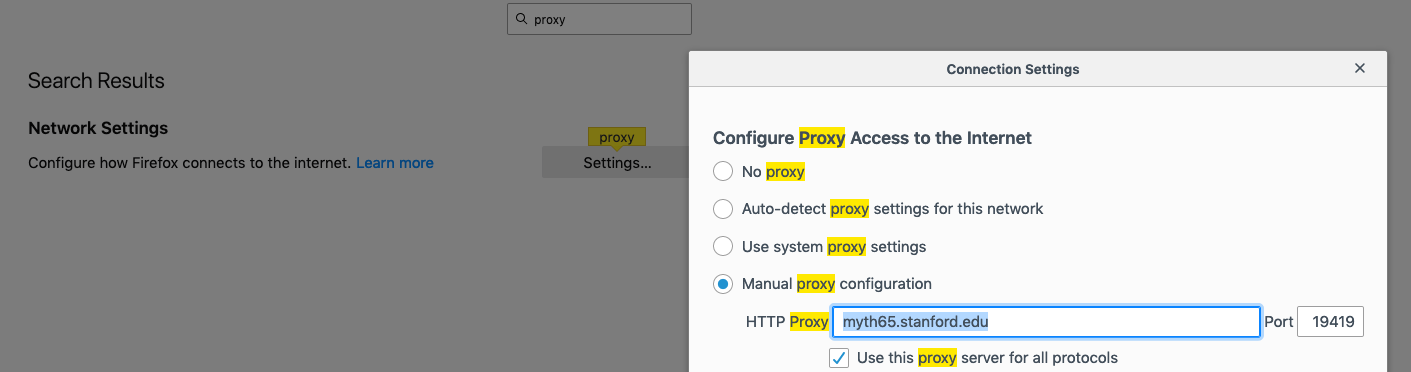
- To set up Firefox, go to Firefox->Preferences, then type "proxy" in the search box, then click on settings. You should have a window as above. Then, click on "Manual proxy configuration," and type in the myth machine and port number you get after starting your proxy:
$ ./proxy
Listening for all incoming traffic on port 19419.- Make sure you also select the checkbox for "Use this proxy server for all protocols."
Lecture 15: HTTP Web Proxy
- Once you have started the proxy (starter code), you should be able to go to any web site, and see the following:
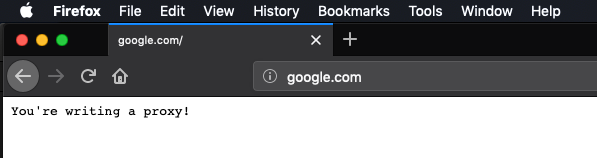
- Not much going on!
- After you have set up the proxy, you can leave it (if you browse with another browser), as long as you always ssh into the same myth machine each time you work on the assignment. If you change myth machines, you will need to update the proxy settings (always check this first if you run into issues)
- You should also frequently clear the browser's cache, as it can locally cache elements, too, which means that you might load a page without ever going to your proxy.
Lecture 15: HTTP Web Proxy
- If you want to avoid the browser, you can use
telnet, instead:
- After the "Host: api.ipify.org" line, you need to hit enter, twice.
- If you are off-campus, you will need to log into the Stanford VPN in order to access the proxy.
myth51:$ telnet myth65.stanford.edu 19419
Trying 171.64.15.30...
Connected to myth65.stanford.edu.
Escape character is '^]'.
GET http://api.ipify.org/?format=json HTTP/1.1
Host: api.ipify.org
HTTP/1.0 200 OK
content-length: 23
You're writing a proxy!Connection closed by foreign host.
myth51:$Lecture 15: HTTP Web Proxy
- If you want to see how the solution behaves, run samples/proxy_soln and then test:
myth51:$ telnet myth65.stanford.edu 19419
Trying 171.64.15.30...
Connected to myth65.stanford.edu.
Escape character is '^]'.
GET http://api.ipify.org/?format=json HTTP/1.1
Host: api.ipify.org
HTTP/1.1 200 OK
connection: keep-alive
content-length: 21
content-type: application/json
date: Wed, 22 May 2019 16:56:33 GMT
server: Cowboy
vary: Origin
via: 1.1 vegur
{"ip":"172.27.64.82"}Connection closed by foreign host.
myth51:$Lecture 15: HTTP Web Proxy
- Version 1: Sequential Proxy
- You will eventually add a
ThreadPoolto your program, but first, write a sequential version. - You will be changing the starter code to be a true proxy, that intercepts the requests and passes them on to the intended server. There are three HTTP methods you need to support:
- GET: request a web page from the server
- HEAD: exactly like GET, but only requests the headers
- POST: send data to the website
- The request line will look like this:
- You will eventually add a
GET http://www.cornell.edu/research/ HTTP/1.1
-
- For this example, your program forwards the request to www.cornell.edu, with the first line of the request as follows:
GET /research/ HTTP/1.1
-
- You already have a fully implemented
HTTPRequestclass, although you will have to update theoperator<<function at a later stage.
- You already have a fully implemented
Lecture 15: HTTP Web Proxy
- There are a couple of extra request headers that you will need to add when you forward the page:
- You should add a new request header entity named
x-forwarded-protoand set its value to behttp. Ifx-forwarded-protois already included in the request header, then simply add it again. - You should add a new request header entity called
x-forwarded-forand set its value to be the IP address of the requesting client. Ifx-forwarded-foris already present, then you should extend its value into a comma-separated chain of IP addresses the request has passed through before arriving at your proxy. (The IP address of the machine you’re directly hearing from would be appended to the end). - You need to be familiar with the
header.h/ccfiles to utilize the functions, e.g.,
- You should add a new request header entity named
string xForwardedForStr = requestHeader.getValueAsString("x-forwarded-for");
-
- You need to manually add the extra x-forwarded-for value, by the way.
- Most of the code for the sequential version will be in
request-handler.h/cc, and some inrequest.h/cc. - After you've written this version, test all the
HTTP://sites you can find!
Lecture 15: HTTP Web Proxy
- Version 2: Adding blocklisting and caching
-
Blocklisting means to block access to certain websites
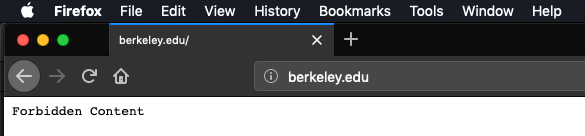
- You have a
blocked-domains.txtfile that lists domains that should not be let through your proxy. When the server in the blacklist is requested, you should return to the client a status code of403, and a payload of "Forbidden Content":
- You have a
-
Blocklisting means to block access to certain websites
- You should understand the functionality of the (short)
strikeset.ccfile, e.g.,
if (!strikeset.serverIsAllowed(request.getServer()) { ...
- If you respond with your own page, use
"HTTP/1.0"as the protocol.
Lecture 15: HTTP Web Proxy
- Version 2: Adding strikesets and caching
-
Caching means to keep a local copy of a page, so that you do not have to re-request the page from the Internet.
- You should update your
HTTPRequestHandlerto check to see if you've already stored a copy of a request -- if you have, just return it instead of forwarding on! You can use theHTTPCacheclass to do this check (and to add sites, as well). - If it isn't in the cache, forward on as usual, but if the response indicates that it is cacheable (e.g.,
cache.shouldCache(request, response)), then you cache it for later.
- You should update your
-
Caching means to keep a local copy of a page, so that you do not have to re-request the page from the Internet.
- Make sure you clear your own browser's cache often when testing this functionality, and also clear the program's cache often, as well:
myth51:$ ./proxy --clear-cache
Clearing the cache... wait for it.... done!
Listening for all incoming traffic on port 19419.
- I put together a tiny web page that simply returns the server time, but it actually allows a cache (not a good thing, but useful for testing): http://ecosimulation.com/cgi-bin/currentTime.php
Lecture 15: HTTP Web Proxy
- Version 3: Concurrent proxy with blocklisting and caching
- Now is the time to leverage your
ThreadPoolclass (we give you a working version in case yours still has bugs) - You will be updating the scheduler.h/cc files, which will be scheduled on a limited amount (64) threads.
- Now is the time to leverage your
- You will be building a scheduler to handle the requests, and you will be writing the
HTTPProxySchedulerclass.- Keep this simple and straightforward! It should have a single
HTTPRequestHandler, which already has a singleHTTPStrikeSetand a singleHTTPCache. You will need to go back and add synchronization directives (e.g.,mutexes) to your prior code to ensure that you don't have race conditions.- You can safely leave the blacklist functions alone, as they never change, but the cache certainly needs to be locked when accessed.
- Keep this simple and straightforward! It should have a single
- You can only have one request open for a given request. If two threads are trying to access the same document, one must wait.
Lecture 15: HTTP Web Proxy
- Version 3: Concurrent proxy with blocklisting and caching
- Don't lock the entire cache with a single mutex -- this is slow!
- Instead, you are going to have an array of 997
mutexes.- What?
- Yes -- every time you request a site, you will tie the request to a particular mutex. How, you say? Well, you will hash the request (it is easy:
size_t requestHash = hashRequest(request);) - The hash you get will always be the same for a particular request, so this is how you will ensure that two threads aren't trying to download the same site concurrently. Yes, you will have some collisions with other sites, but it will be rare.
- You should update the cache.h/cc files to make it easy to get the hash and the associated mutex, and then return the mutex to the calling function.
- It is fine to have different requests adding their cached information to the cache or checking the cache, because it is thread-safe in that respect. You should never have the same site trying to update the cache at the same time.
- Instead, you are going to have an array of 997
- The
client-socket.h/ccfiles have been updated to include thread-safe versions of their functions, so no need to worry about that.
- Don't lock the entire cache with a single mutex -- this is slow!
Lecture 15: HTTP Web Proxy
- Version 4: Concurrent proxy with strikesets, caching, and proxy chaining
-
Proxy chaining is where your proxy will itself use another proxy.
- Is this a real thing? Yes! Some proxies rely on other proxies to do the heavy lifting, while they add more functionality (better caching, more blocklisting, etc.). Some proxies do this to further anonymize the client.
- Example:
- On myth63, we can start a proxy as normal, on a particular port:
-
Proxy chaining is where your proxy will itself use another proxy.
myth63:$ samples/proxy_soln --port 12345
Listening for all incoming traffic on port 12345.- On myth65, we can start another proxy that will forward all requests to the myth63 proxy:
myth65:$ samples/proxy_soln --proxy-server myth63.stanford.edu --proxy-port 12345
Listening for all incoming traffic on port 19419.
Requests will be directed toward another proxy at myth63.stanford.edu:12345.- Now, all requests will go through both proxies (unless cached!):
Lecture 15: HTTP Web Proxy
- You will have to update a number of method signatures to include the possibility of a secondary proxy.
- If you are going to forward to another proxy:
- Check to see if you've got a cached request -- if so, return it
- If you notice a cycle of proxies, respond with a status code of 504.
- How do you know you have a chain? That's why you have the
"x-forwarded-for"header! You analyze that list to see if you are about to create a chain.
- How do you know you have a chain? That's why you have the
- If not, forward the request exactly, with the addition of your
"x-forwarded-proto"and"x-forwarded-for"headers.
- We provide you with a
run-proxy-farm.pyprogram that can manage a chain of proxies (but it doesn't check for cycles -- you would need to modify the python code to do that).
Lecture 15: HTTP Web Proxy
- Whew! That is a lot of moving parts.
- As always, one step at a time.
- Finally: to support
https://sites, you have the option to implement the CONNECT HTTP method, which is actually not that much more work to add. The assignment gives you information about how to support CONNECT. - Test often, and remember to check your proxy settings, myth number, and to clear both your browser cache and your own proxy server cache often.
- The files you will likely have to modify are as follows (with major/minor/very minor changes listed below):
| file | changes |
|---|---|
| cache.cc | (very minor) |
| cache.h | (very minor) |
| proxy.cc | (very minor) |
| request.cc | (minor) |
| request.h | (minor) |
| request-handler.cc | (major) |
| request-handler.h | (major) |
| scheduler.cc | (minor) |
| scheduler.h | (very minor) |
Lecture 15: HTTP Web Proxy
Lecture 15: HEAD, GET, POST, Proxy overview (w21)
By Chris Gregg
Lecture 15: HEAD, GET, POST, Proxy overview (w21)
Winter 2020




