Merkle Trees
and Cryptographic Hash Functions
Tsvetan Dimitrov


Agenda
-
Merkle Trees
-
Definition
-
Benefits
-
Use Cases
-
-
Sparse Merkle Trees
-
Cryptographic Hash Functions
-
SHA-256
-
Summary

Merkle Trees
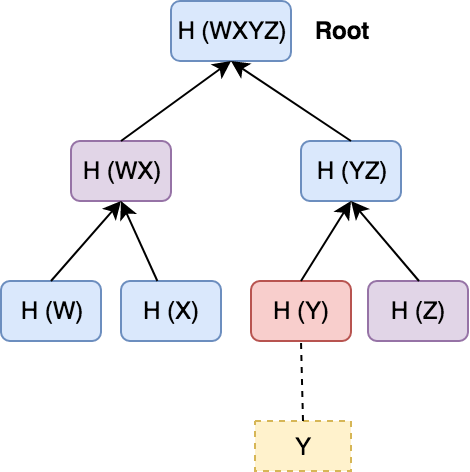
Definition / 1
-
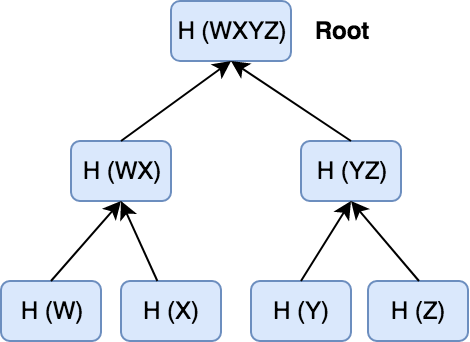
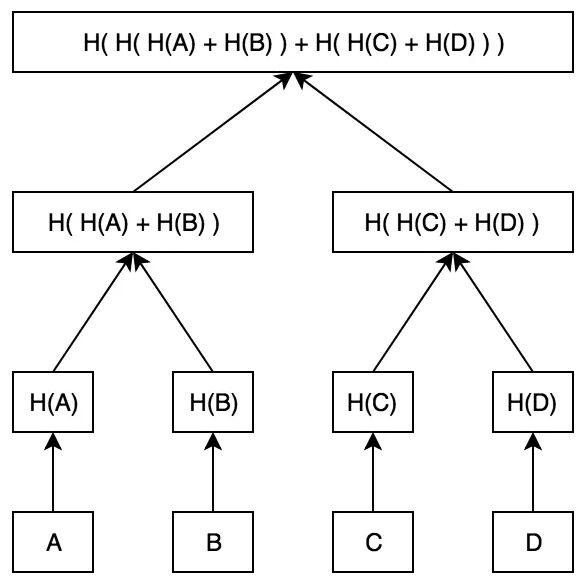
Also called Binary Hash Tree.
-
Leaves represent individual pieces of data, such as transactions in a blockchain.
Definition / 2
-
Each internal node in the tree represents the hash of the concatenation of its two child nodes.
-
This continues until a single root node is reached, which represents the root hash of the entire tree, called Merkle Root.
Definition / 3
-
Data can be audited using the Merkle Root in O(log n) time to the number of leaves. This is called the Merkle Proof.
-
The Merkle Path corresponds to recreating the branch containing the piece of data from the root to the piece of data being audited.
Benefits
-
Validate data integrity.
-
Take small amount of disk space.
-
Small amount of information is sent across the network.
-
Efficient data format enabling fast verification.
-
Prove that giving tiny amounts of information across the network is all that is required for a transaction to be valid.

Use Cases in Blockchain
Other Use Cases
-
Git
-
Interplanetary File System, a peer-to-peer distributed protocol (Merkle DAG).
-
It's part of the technique that generates verifiable certificate transparency logs.
-
Amazon DynamoDB and Apache Cassandra use it during the data replication process to control discrepancies.
Sparse Merkle Trees
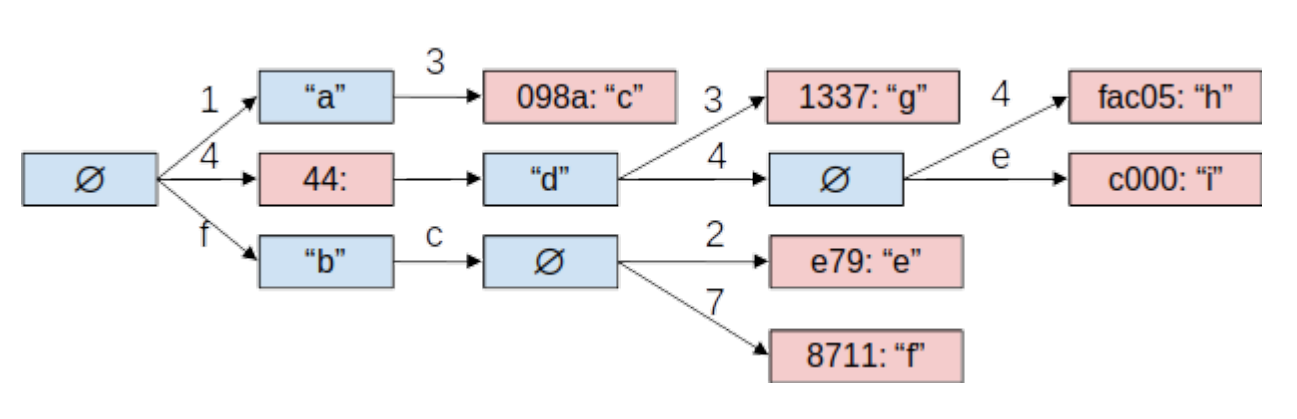
-
A standard Merkle Tree, except the contained data is indexed, and each data point is placed at the leaf that corresponds to that data point’s index.
-
Suitable for proving non-inclusion of a node in the tree.
-
Acts as a key-value store inside of a Merkle Tree.
Definition

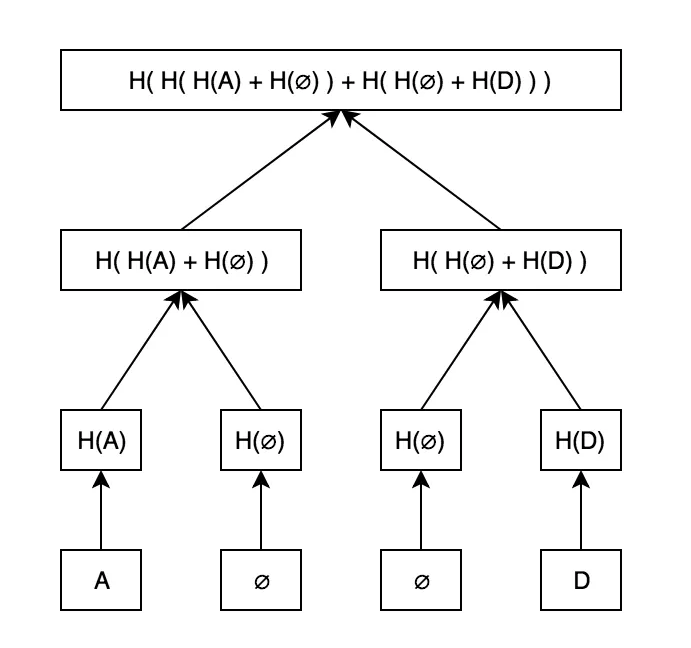
Space Complexity and Caching
-
Efficient proofs of non-inclusion, but at the cost of huge trees (about 2²⁵⁶ hashes)
-
Luckily, caching is possible because H(null) is a constant value and so is H(H(null)).
-
A naive caching strategy could record every hash that is non-empty.
-
The goal is to capture branches down to the leaves by a constant.
Cryptographic Hash Functions
-
Avoid collisions for non malicious input.
-
Aim to detect accidental changes in data (CRCs).
Non Cryptographic Hash Functions / 1
Non Cryptographic Hash Functions / 2
-
Put objects into different buckets in a hash table with as few collisions as possible.

Properties of CHF
-
Deterministic.
-
Pre-Image Resistant.
-
Computationally Efficient.
-
Cannot be Reversed Engineered.
-
Collision Resistant.

CHF Algorithm Families


SHA-256

Definition
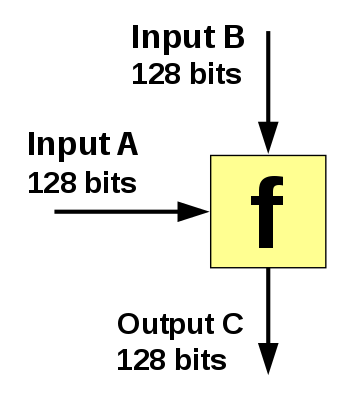
-
Produces a fixed-size, 256-bit hash value.
-
Part of the SHA-2 family of hash functions and designed by the National Security Agency (NSA).
-
Built with a Merkle-Damgård structure derived from a one-way compression function.
-
A brute-force attack would need to make 2²⁵⁶ attempts to generate the initial data.
Step 1: Padding Bits
-
Bits are appended to the original input to make it compatible with the hash function.
-
Total bits must always be 64 bits short of any multiple of 512.
-
The first bit added is 1 and the rest are zeroes.
Original Message
Padding Bits
Step 2: Padding Length
-
The length of the original message is padded to the result from step 1 and it is expressed in the form of 64 bits.
-
The final data to be hashed will now be a multiple of 512 (used mostly to increase the complexity of the function).
Original Message
Padding Bits
Input Length
Step 3: Initialize Chaining Variables
-
The entire message is broken down into blocks of 512 bits each (5 buffers of 32 bits each).
-
They are 5 words named A, B, C, D, and E.
-
The first iteration has fixed hex values.
A = 01 23 45 67
B = 89 ab cd ef
C = fe dc ba 98
D = 76 54 32 10
E = C3 D2 E1 F0
Step 4.1: Process Each Block
-
512 bit block = 16 sub blocks * 32 bits each.
-
4 rounds of operations, utilizing the ABCDE register, the 512 bit block and a constant named K[t].
-
Each round has 20 iterations: 4 * 20 = 80.
-
K[t] is an array of 80 elements.
Step 4.2: Process Each Block
-
On each iteration the following formula is calculated:
ABCDE = E + Process P + S⁵(A) + W(t) + K(t)-
P = Non Linear Logical Process that changes each round.
-
S⁵ = Circular shift by 5 bits.
-
W(t) = A 32 bit string derived from an existing sub block.
-
K(t) = One of the 80 constants which change with every round.
ABCDEABCDEABCDEABCDEProcess PS⁵W(t)
K(t)
Summary
-
Merkle Trees and Sparse Merkle Trees - definitions, use cases, benefits and drawbacks.
-
Differences between CHF and non CHF.
-
SHA-256 definition and algorithm explanation.


Questions?
Merkle Trees and Cryptographic Hash Functions
By Tsvetan Dimitrov
Merkle Trees and Cryptographic Hash Functions
Introduction to software versioning and release management best practices




