Human Centric
Machine Learning Infrastructure
@

Ville Tuulos
QCon SF, November 2018




Meet Alex, a new chief data scientist at Caveman Cupcakes

You are hired!
We need a dynamic pricing model.
Optimal pricing model





Great job!
The model works
perfectly!
Could you
predict churn
too?

Optimal pricing model
Optimal churn model
Alex's model
Good job again!
Promising results!
Can you include a causal attribution model for marketing?
Optimal pricing model
Optimal churn model
Alex's model

Attribution
model
Are you sure
these results
make sense?
Take two
Meet the new data science team at Caveman Cupcakes
You are hired!






Pricing model
Churn model
Attribution
model


the human is the bottleneck
the human is the bottleneck
VS



Build
Data Warehouse
Build
Data Warehouse
Compute Resources
Build
Data Warehouse
Compute Resources
Job Scheduler
Build
Data Warehouse
Compute Resources
Job Scheduler
Versioning
Build
Data Warehouse
Compute Resources
Job Scheduler
Versioning
Collaboration Tools
Build
Data Warehouse
Compute Resources
Job Scheduler
Versioning
Collaboration Tools
Model Deployment
Build
Data Warehouse
Compute Resources
Job Scheduler
Versioning
Collaboration Tools
Model Deployment
Feature Engineering
Build
Data Warehouse
Compute Resources
Job Scheduler
Versioning
Collaboration Tools
Model Deployment
Feature Engineering
ML Libraries
Build
Data Warehouse
Compute Resources
Job Scheduler
Versioning
Collaboration Tools
Model Deployment
Feature Engineering
ML Libraries
How much
data scientist
cares
Build
Data Warehouse
Compute Resources
Job Scheduler
Versioning
Collaboration Tools
Model Deployment
Feature Engineering
ML Libraries
How much
data scientist
cares
How much
infrastructure
is needed
Build

Deploy
Deploy
No plan survives contact with enemy
Deploy
No plan survives contact with enemy
No model survives contact with reality
our ML infra supports
two human activities:
building and deploying
data science workflows.
Screenplay Analysis Using NLP

Fraud Detection
Title Portfolio Optimization
Estimate Word-of-Mouth Effects
Incremental Impact of Marketing
Classify Support Tickets
Predict Quality of Network
Content Valuation
Cluster Tweets
Intelligent Infrastructure
Machine Translation
Optimal CDN Caching

Predict Churn
Content Tagging
Optimize Production Schedules




Notebooks: Nteract
Job Scheduler: Meson
Compute Resources: Titus
Query Engine: Spark
Data Lake: S3



{
data
compute
prototyping
ML Libraries: R, XGBoost, TF etc.
models

Bad Old Days
Data Scientist built an NLP model in Python. Easy and fun!
How to run at scale?
Custom Titus executor.
How to schedule the model to update daily?Learn about the job scheduler.
How to access data at scale?
Slow!
How to expose the model to a custom UI? Custom web backend.
Time to production:
4 months
How to monitor models in production?
How to iterate on a new version without breaking the production version?
How to let another data scientist iterate on her version of the model safely?
How to debug yesterday's failed production run?
How to backfill historical data?
How to make this faster?
Notebooks: Nteract
Job Scheduler: Meson
Compute Resources: Titus
Query Engine: Spark
Data Lake: S3
{
data
compute
prototyping
ML Libraries: R, XGBoost, TF etc.
models

ML Wrapping: Metaflow
Metaflow
Build
def compute(input):
output = my_model(input)
return outputoutput
input
compute
How to get started?
# python myscript.py
from metaflow import FlowSpec, step
class MyFlow(FlowSpec):
@step
def start(self):
self.next(self.a, self.b)
@step
def a(self):
self.next(self.join)
@step
def b(self):
self.next(self.join)
@step
def join(self, inputs):
self.next(self.end)
MyFlow()start
How to structure my code?
B
A
join
end
# python myscript.py run
metaflow("MyFlow") %>%
step(
step = "start",
next_step = c("a", "b")
) %>%
step(
step = "A",
r_function = r_function(a_func),
next_step = "join"
) %>%
step(
step = "B",
r_function = r_function(b_func),
next_step = "join"
) %>%
step(
step = "Join",
r_function = r_function(join,
join_step = TRUE),
start
How to deal with models
written in R?
B
A
join
end
# RScript myscript.R

Metaflow adoption
at Netflix
134 projects on Metaflow
as of November 2018
start
How to prototype and test
my code locally?
B
A
join
end
# python myscript.py resume Bx=0
x+=2
x+=3
max(A.x, B.x)
@step
def start(self):
self.x = 0
self.next(self.a, self.b)
@step
def a(self):
self.x += 2
self.next(self.join)
@step
def b(self):
self.x += 3
self.next(self.join)
@step
def join(self, inputs):
self.out = max(i.x for i in inputs)
self.next(self.end)start
How to get access to more CPUs,
GPUs, or memory?
B
A
join
end
@titus(cpu=16, gpu=1)
@step
def a(self):
tensorflow.train()
self.next(self.join)
@titus(memory=200000)
@step
def b(self):
massive_dataframe_operation()
self.next(self.join)16 cores, 1GPU
200GB RAM
# python myscript.py run
start
How to distribute work over
many parallel jobs?
A
join
end
@step
def start(self):
self.grid = [’x’,’y’,’z’]
self.next(self.a, foreach=’grid’)
@titus(memory=10000)
@step
def a(self):
self.x = ord(self.input)
self.next(self.join)
@step
def join(self, inputs):
self.out = max(i.x for i in inputs)
self.next(self.end)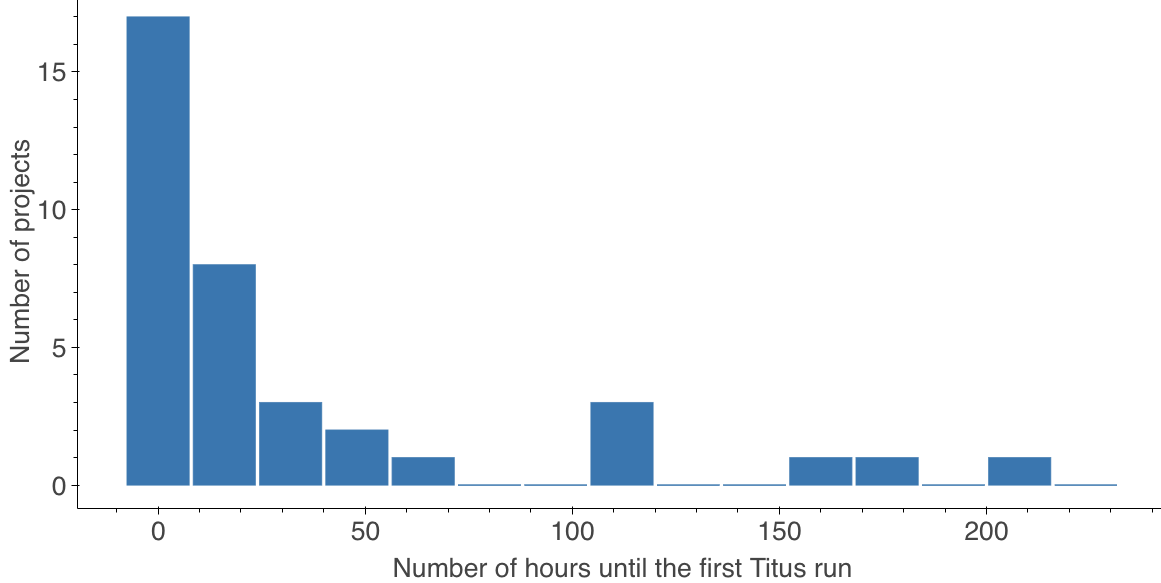
40% of projects run steps outside their dev environment.
How quickly they start using Titus?
from metaflow import Table
@titus(memory=200000, network=20000)
@step
def b(self):
# Load data from S3 to a dataframe
# at 10Gbps
df = Table('vtuulos', 'input_table')
self.next(self.end)start
How to access large amounts of input data?
B
A
join
end
S3
Case Study: Marketing Cost per Incremental Watcher
1. Build a separate model for every new title with marketing spend.
Parallel foreach.
2. Load and prepare input data for each model.
Download Parquet directly from S3.
Total amount of model input data: 890GB.
3. Fit a model.
Train each model on an instance with 400GB of RAM, 16 cores.
The model is written in R.
4. Share updated results.
Collect results of individual models, write to a table.
Results shown on a Tableau dashboard.
Deploy
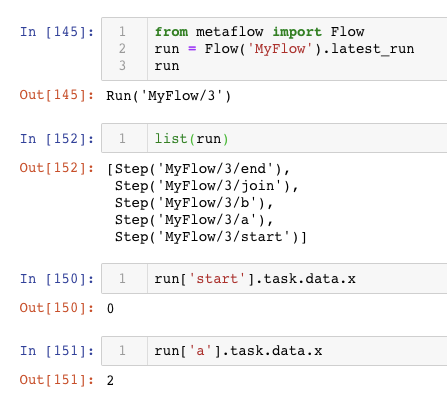
# Access Savin's runs
namespace('user:savin')
run = Flow('MyFlow').latest_run
print(run.id) # = 234
print(run.tags) # = ['unsampled_model']
# Access David's runs
namespace('user:david')
run = Flow('MyFlow').latest_run
print(run.id) # = 184
print(run.tags) # = ['sampled_model']
# Access everyone's runs
namespace(None)
run = Flow('MyFlow').latest_run
print(run.id) # = 184 start
How to version my results and
access results by others?
B
A
join
end
david: sampled_model
savin: unsampled_model
start
How to deploy my workflow to production?
B
A
join
end

#python myscript.py meson create
26% of projects get deployed to the production scheduler.
How quickly the first deployment happens?

start
How to monitor models and
examine results?
B
A
join
end
x=0
x+=2
x+=3
max(A.x, B.x)

start
How to deploy results as
a microservice?
B
A
join
end
x=0
x+=2
x+=3
max(A.x, B.x)
Metaflow
hosting
from metaflow import WebServiceSpec
from metaflow import endpoint
class MyWebService(WebServiceSpec):
@endpoint
def show_data(self, request_dict):
# TODO: real-time predict here
result = self.artifacts.flow.x
return {'result': result}
# curl http://host/show_data
{"result": 3}{
Case Study: Launch Date Schedule Optimization
1. Batch optimize launch date schedules for new titles daily.
Batch optimization deployed on Meson.
2. Serve results through a custom UI.
Results deployed on Metaflow Hosting.
3. Support arbitrary what-if scenarios in the custom UI.
Run optimizer in real-time in a custom web endpoint.
Metaflow
diverse problems
diverse people
help people build
help people deploy
diverse models
happy people, healthy business
thank you!
@vtuulos
vtuulos@netflix.com
Bruno Coldiori
https://www.flickr.com/photos/br1dotcom/8900102170/
https://www.maxpixel.net/Isolated-Animal-Hundeportrait-Dog-Nature-3234285
Photo Credits
Human Centric Machine Learning Infrastructure Qcon 2018
By Ville Tuulos




