




















vivalavika
Откройте мир украшений https://vivalavika.com/ на официальном сайте vivalavika.com. Ваш идеальный магазин украшений в Москве, где доступны эксклюзивные коллекции от Виктории Молдавской. От браслетов желаний до элегантных сережек...
NLP pipelines with
Follow me on
In this presentation you will:
Don't be shy. Ask questions!
pip install -U pip setuptools wheel
pip install -U spacy
python -m spacy download en_core_web_smimport spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("Apple is looking at buying U.K. startup for $1 billion")
for token in doc:
print(token.text, token.pos_, token.dep_) Apple PROPN nsubj
is AUX aux
looking VERB ROOT
at ADP prep
buying VERB pcomp
U.K. PROPN dobj
startup NOUN dobj
for ADP prep
$ SYM quantmod
1 NUM compound
billion NUM pobj
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("Apple is looking at buying U.K. startup for $1 billion")
for token in doc:
print(token.text, token.pos_, token.dep_) Apple PROPN nsubj
is AUX aux
looking VERB ROOT
at ADP prep
buying VERB pcomp
U.K. PROPN dobj
startup NOUN dobj
for ADP prep
$ SYM quantmod
1 NUM compound
billion NUM pobj
Use nlp.pipe method
Preprocesses texts as a stream, yields Doc objects
Much faster than calling nlp on each texst
# BAD
docs = [nlp(text) for text in LOTS_OF_TEXTS]
# GOOD
docs = list(nlp.pipe(LOTS_OF_TEXTS))import os
import spacy
nlp = spacy.load("en_core_news_sm")
texts = ... # a large list of documents
batch_size = 128
docs = []
for doc in nlp.pipe(texts, n_process=os.cpu_count()-1, batch_size=batch_size):
docs.append(doc)
spaCy can also leverage multiprocessing and batching
Disable unused components for the pipeline
import spacy
nlp = spacy.load("en_core_web_sm", disable=["tagger", "parser"])
If you want to tokenize the text only, use the nlp.make_doc
# BAD
doc = nlp("Hello World")
# GOOD
doc = nlp.make_doc("Hello World")from spacy.matcher import Matcher
nlp = spacy.load("en_core_web_sm")
matcher = Matcher(nlp.vocab)
pattern = [
{"TEXT": "Hello"}
]
matcher.add("HelloPattern", [pattern])
doc = nlp("Hello my friend!")
matcher(doc)
>>> [(10496072603676489703, 0, 1)]
match = matcher(doc)
match_id, start, end = match[0]
doc[start:end]
>>> Hello
matcher = Matcher(nlp.vocab)
pattern = [
{"LOWER": "hello"},
{"IS_PUNCT": True},
{"LOWER": "world"}
]
matcher.add("HelloWorldPattern", [pattern])
doc = nlp("Hello, world! This is my first attempt using the Matcher class")
matcher(doc)
>>> [(15578876784678163569, 0, 3)]
match = matcher(doc)
match_id, start, end = match[0]
doc[start:end]
>>> Hello, worldmatcher = Matcher(nlp.vocab)
pattern = [
{"LEMMA": {"IN": ["like", "love"]}},
{"POS": "NOUN"}
]
matcher.add("like_love_pattern", [pattern])
doc = nlp("I really love pasta!")
matcher(doc)
>>> [(2173185394966972186, 2, 4)]
match = matcher(doc)
match_id, start, end = match[0]
doc[start:end]
>>> love pastapattern = [
{"LOWER": {"IN": ["iphones", "ipads", "imacs", "macbooks"]}},
{"LEMMA": "be"},
{"POS": "ADV", "OP": "*"},
{"POS": "ADJ"}
]
matcher.add("apple_products", [pattern])
doc = nlp("""Here's what I think about Apple products: Iphones are expensive,
Ipads are clunky and macbooks are professional.""")
matcher(doc)
>>> [(4184201092351343283, 9, 12),
(4184201092351343283, 14, 17),
(4184201092351343283, 18, 21)]
matches = matcher(doc)
for match_id, start, end in matches:
print(doc[start:end])
>>> Iphones are expensive
Ipads are clunky
macbooks are professionalpattern_length = [{"LENGTH": {">=": 10}}]
pattern_email = [{"LIKE_EMAIL": True}]
pattern_url = [{"LIKE_URL": True}]
pattern_digit = [{"IS_DIGIT": True}]
pattern_ent_type = [{"ENT_TYPE": "ORG"}]
pattern_regex = [{"TEXT": {"REGEX": "deff?in[ia]tely"}}]
pattern_bitcoin = [
{"LEMMA": {"IN": ["buy", "sell"]}},
{"LOWER": {"IN": ["bitcoin", "dogecoin"]}},
]
Extract expressions and noun phrases
Enhance regular expressions with token annotations (tag_, dep_, text, etc.)
A rich syntax
Create complex patterns with operators and properties...
Preannotate data for NER training
Allows to combine statistical with rule-based models for more powerful pipelines
Useful to detect very specific entities not captured by statistical models
New entities are added as patterns in an EntityRuler component
import spacy
nlp = spacy.blanc("en")
doc_before = nlp("John lives in Atlanta")
# No entities are detected
print(doc_before.ents)
# ()
# Create an entity ruler and add it some patterns
entity_ruler = nlp.add_pipe("entity_ruler")
patterns = [
{
"label": "PERSON",
"pattern": "John",
"id": "john",
},
{
"label": "GPE",
"pattern": [{"LOWER": "atlanta"}],
"id": "atlanta",
},
]
entity_ruler.add_patterns(patterns)
doc_after = nlp("Jonh lives in Atlanta.")
for ent in doc.ents:
print(ent.text, ":", ent.label_)
# John : PERSON
# atlanta : GPEimport spacy
import scispacy
# load a spacy model that detects DNA, RNA and PROTEINS from
# biomedical documents
model = spacy.load(
"en_ner_jnlpba_md",
disable=["tok2vec", "tagger", "parser", "attribute_ruler", "lemmatizer"],
)
# build a list of patterns and inject them into the entity ruler.
# these patterns contain entities that are not initially captured
# by the model.
# knowledge bases or ontologies could be used to construct the patterns
patterns = build_patterns_from_knowledge_base()
print(patterns[:3])
# [{'label': 'PROTEIN', 'pattern': 'tetraspanin-5'},
# {'label': 'PROTEIN', 'pattern': 'estradiol 17-beta-dehydrogenase akr1b15'},
# {'label': 'PROTEIN', 'pattern': 'moz, ybf2/sas3, sas2 and tip60 protein 4'}]
# define an entity ruler
entity_ruler = model.add_pipe("entity_ruler", after="ner")
# add the patterns to the entity rulerUsecase: How to improve the detection of biomedical entities with an EntityRuler?
import spacy
from spacy import displacy
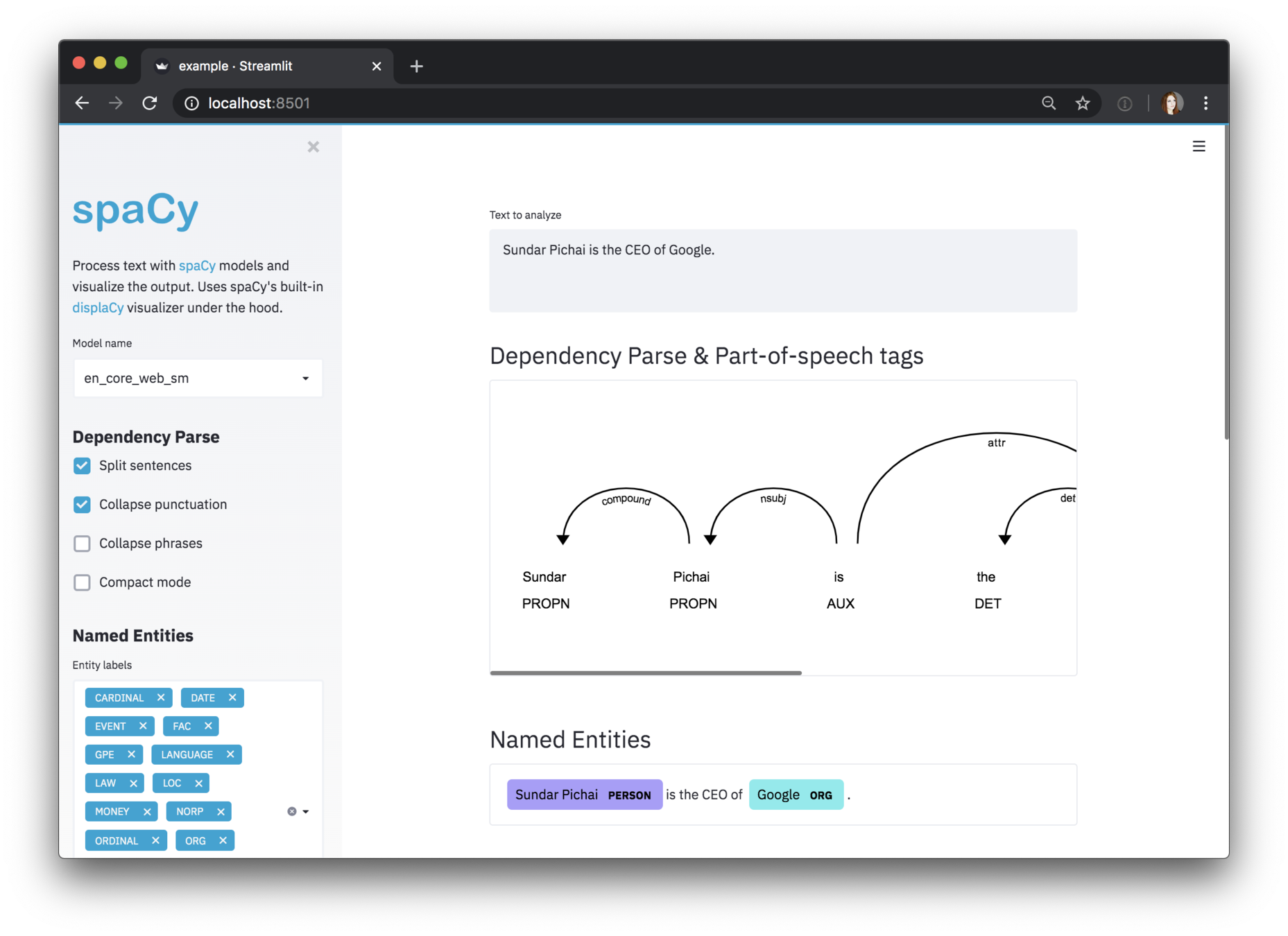
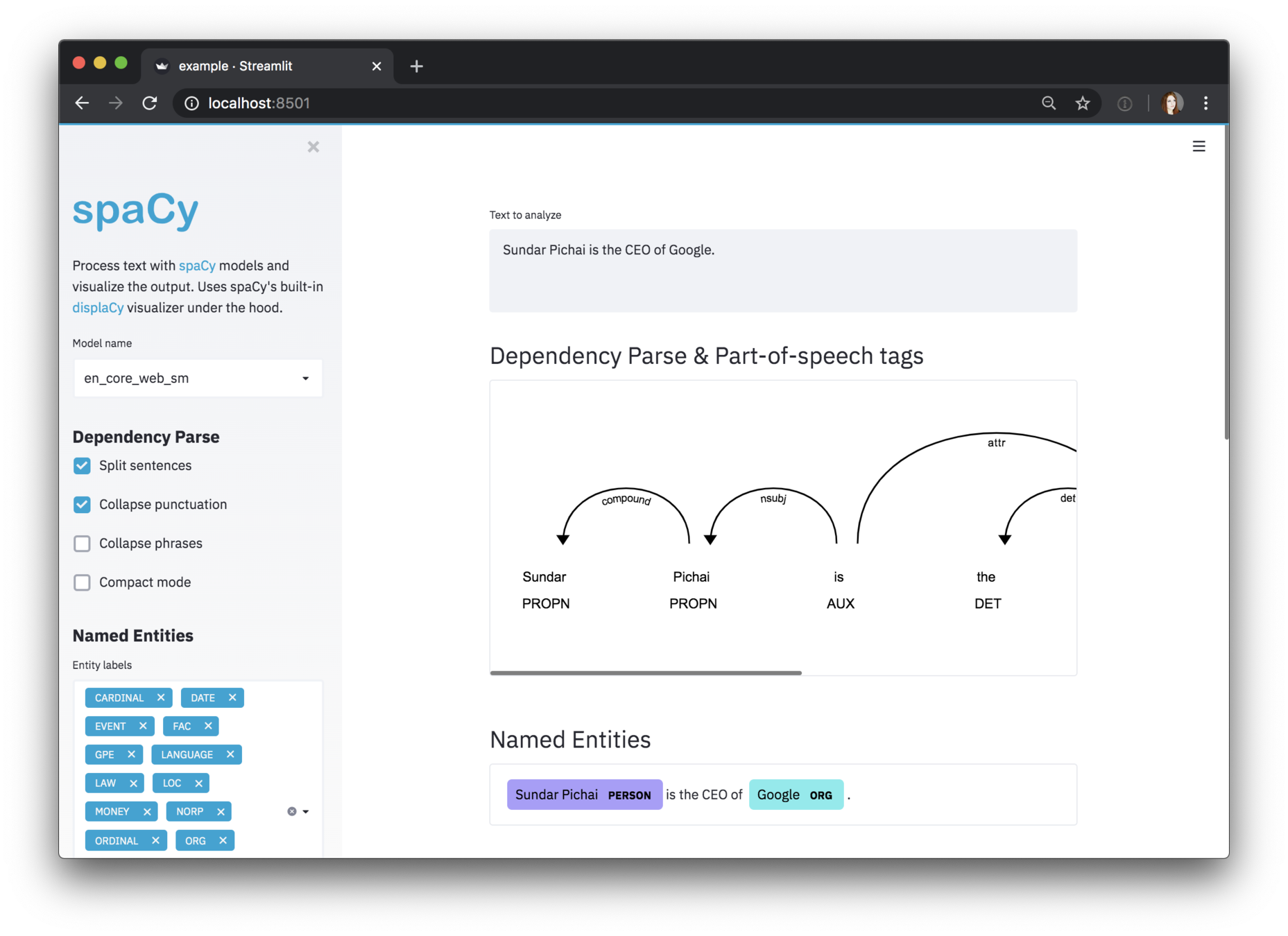
nlp = spacy.load("en_core_web_sm")
doc = nlp("Ahmed is a freelance data scientist and works in Paris")
displacy.serve(doc, style="dep")
https://github.com/explosion/spacy-streamlit
A function that takes a doc, modifies it, and returns it
Registered using the Language.component decorator
Added using the nlp.add_pipe method
@Language.component("custom_component")
def custom_component_function(doc):
# Do something to the doc here
return doc
nlp.add_pipe("custom_component")import spacy
from spacy.language import Language
@Language.component("custom_component")
def custom_component(doc):
print(f"Doc length : {len(doc)}")
return doc
nlp = spacy.load("en_core_web_sm")
nlp.add_pipe("custom_component", first=True)
>>> print("Pipeline:", nlp.pipe_names)
# Pipeline: ['custom_component', 'tok2vec', 'tagger', 'parser',
# 'ner', 'attribute_ruler', 'lemmatizer']
>>> doc = nlp("I love pasta!")
# Doc length: 4import spacy
from spacy.language import Language
from spacy.matcher import PhraseMatcher
from spacy.tokens import Span
nlp = spacy.load("en_core_web_sm")
animals = ["Golden Retriever", "cat", "turtle", "Rattus norvegicus"]
animal_patterns = list(nlp.pipe(animals))
print("animal_patterns:", animal_patterns)
matcher = PhraseMatcher(nlp.vocab)
matcher.add("ANIMAL", animal_patterns)
# Define the custom component
@Language.component("animal_component")
def animal_component_function(doc):
# Apply the matcher to the doc
matches = matcher(doc)
# Create a Span for each match and assign the label "ANIMAL"
spans = [Span(doc, start, end, label="ANIMAL") for match_id, start, end in matches]
# Overwrite the doc.ents with the matched spans
doc.ents = spans
return doc
# Add the component to the pipeline after the "ner" component
nlp.add_pipe("animal_component", after="ner")
print(nlp.pipe_names)
# Process the text and print the text and label for the doc.ents
doc = nlp("I have a cat and a Golden Retriever")
print([(ent.text, ent.label_) for ent in doc.ents])https://spacy.io/
https://ner.pythonhumanities.com/intro.html
https://towardsdatascience.com/7-spacy-features-to-boost-your-nlp-pipelines-and-save-time-9e12d18c3742
https://www.youtube.com/playlist?list=PLBmcuObd5An5DOl2_IkB0JGQTGFHTAP1h
By vivalavika
How to scale and improve your NLP pipelines with spaCy



