



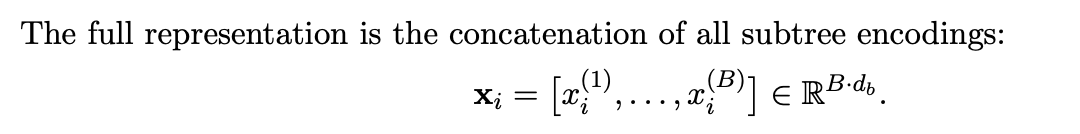
Vidhi Lalchand
Postdoctoral Fellow, Broad and MIT
Vidhi Lalchand, Ph.D.
IMU Biosciences
April 29, 2026
[203 donors]
Depth-weighted pooling approach to modelling immue ratios
How are the subtrees formed?
Each column of the megatable is mapped to a subtree label
"population","ratio_parent","hierarchical_path","subtree"
"Eosinophil_Tv5","Live_cells_Tv5","Total_Tv5/WBC_Tv5/Live_cells_Tv5/Eosinophil_Tv5","Granulocyte"
"Eosinophil/CD5p_Tv5","Eosinophil_Tv5","Total_Tv5/WBC_Tv5/Live_cells_Tv5/Eosinophil_Tv5/Eosinophil/CD5p_Tv5","Granulocyte"
"Eosinophil/HLADRp_Tv5","Eosinophil_Tv5","Total_Tv5/WBC_Tv5/Live_cells_Tv5/Eosinophil_Tv5/Eosinophil/HLADRp_Tv5","Granulocyte"
"Eosinophil/PD1p_Tv5","Eosinophil_Tv5","Total_Tv5/WBC_Tv5/Live_cells_Tv5/Eosinophil_Tv5/Eosinophil/PD1p_Tv5","Granulocyte"
"Neutrophil_Tv5","Live_cells_Tv5","Total_Tv5/WBC_Tv5/Live_cells_Tv5/Neutrophil_Tv5","Granulocyte"
"Neutrophil/BIG_Tv5","Neutrophil_Tv5","Total_Tv5/WBC_Tv5/Live_cells_Tv5/Neutrophil_Tv5/Neutrophil/BIG_Tv5","Granulocyte"
"Neutrophil/CD5p_Tv5","Neutrophil_Tv5","Total_Tv5/WBC_Tv5/Live_cells_Tv5/Neutrophil_Tv5/Neutrophil/CD5p_Tv5","Granulocyte"
"Neutrophil/HLADRp_Tv5","Neutrophil_Tv5","Total_Tv5/WBC_Tv5/Live_cells_Tv5/Neutrophil_Tv5/Neutrophil/HLADRp_Tv5","Granulocyte"
"Neutrophil/PD1p_Tv5","Neutrophil_Tv5","Total_Tv5/WBC_Tv5/Live_cells_Tv5/Neutrophil_Tv5/Neutrophil/PD1p_Tv5","Granulocyte"
"Neutrophil/SMALL_Tv5","Neutrophil_Tv5","Total_Tv5/WBC_Tv5/Live_cells_Tv5/Neutrophil_Tv5/Neutrophil/SMALL_Tv5","Granulocyte"
"Total_B_Tv5","Live_cells_Tv5","Total_Tv5/WBC_Tv5/Live_cells_Tv5/Total_B_Tv5","B_cell"
"Total_B/CD5p_Tv5","Total_B_Tv5","Total_Tv5/WBC_Tv5/Live_cells_Tv5/Total_B_Tv5/Total_B/CD5p_Tv5","B_cell"
"Total_B/CD27p_Tv5","Total_B_Tv5","Total_Tv5/WBC_Tv5/Live_cells_Tv5/Total_B_Tv5/Total_B/CD27p_Tv5","B_cell"
"Total_B/CD39p_Tv5","Total_B_Tv5","Total_Tv5/WBC_Tv5/Live_cells_Tv5/Total_B_Tv5/Total_B/CD39p_Tv5","B_cell"
"Total_B/CD57p_Tv5","Total_B_Tv5","Total_Tv5/WBC_Tv5/Live_cells_Tv5/Total_B_Tv5/Total_B/CD57p_Tv5","B_cell"
"Total_B/CD95p_Tv5","Total_B_Tv5","Total_Tv5/WBC_Tv5/Live_cells_Tv5/Total_B_Tv5/Total_B/CD95p_Tv5","B_cell"
"Total_B/CD103p_Tv5","Total_B_Tv5","Total_Tv5/WBC_Tv5/Live_cells_Tv5/Total_B_Tv5/Total_B/CD103p_Tv5","B_cell"
"Total_B/CXCR5p_Tv5","Total_B_Tv5","Total_Tv5/WBC_Tv5/Live_cells_Tv5/Total_B_Tv5/Total_B/CXCR5p_Tv5","B_cell"
"Total_B/ICOSp_Tv5","Total_B_Tv5","Total_Tv5/WBC_Tv5/Live_cells_Tv5/Total_B_Tv5/Total_B/ICOSp_Tv5","B_cell"
"Total_B/LAG3p_Tv5","Total_B_Tv5","Total_Tv5/WBC_Tv5/Live_cells_Tv5/Total_B_Tv5/Total_B/LAG3p_Tv5","B_cell"
"Total_B/PD1p_Tv5","Total_B_Tv5","Total_Tv5/WBC_Tv5/Live_cells_Tv5/Total_B_Tv5/Total_B/PD1p_Tv5","B_cell"
"Total_B/TIM3p_Tv5","Total_B_Tv5","Total_Tv5/WBC_Tv5/Live_cells_Tv5/Total_B_Tv5/Total_B/TIM3p_Tv5","B_cell"
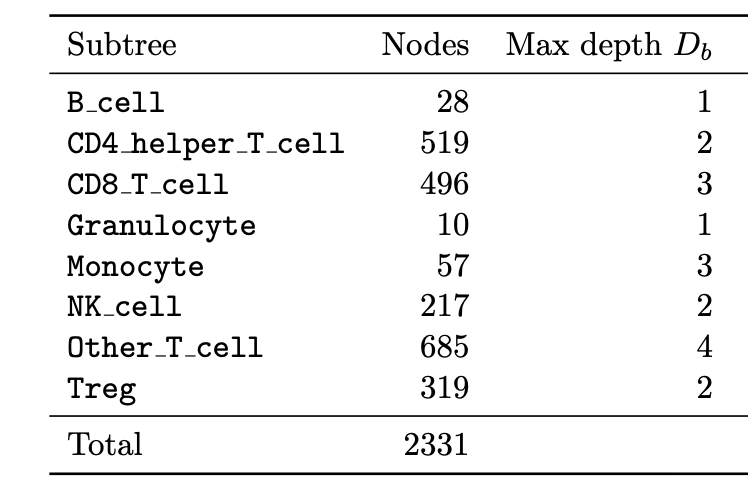
Total rows: 2342
Number of subtrees: B = 8
Columns:
- population : Node name (e.g. Eosinophil_Tv5, VD1/PD1p_Tv5)
- ratio_parent : Direct parent node, defines the tree edges
- hierarchical_path : Full path from root (e.g.
Total_Tv5/WBC_Tv5/.../VD1_Tv5)
- subtree : Which of the B=8 subtrees this node belongs to
Tree encoding: Aggregate ratios at each depth level to collapse noisy information
Below, is just to show how it happens for different types of tree topologies
Once we have access to this final embedding which has encoded all the subtrees, we can treat it as a flat embedding vector training any non-linear model on it to predict the binary response.
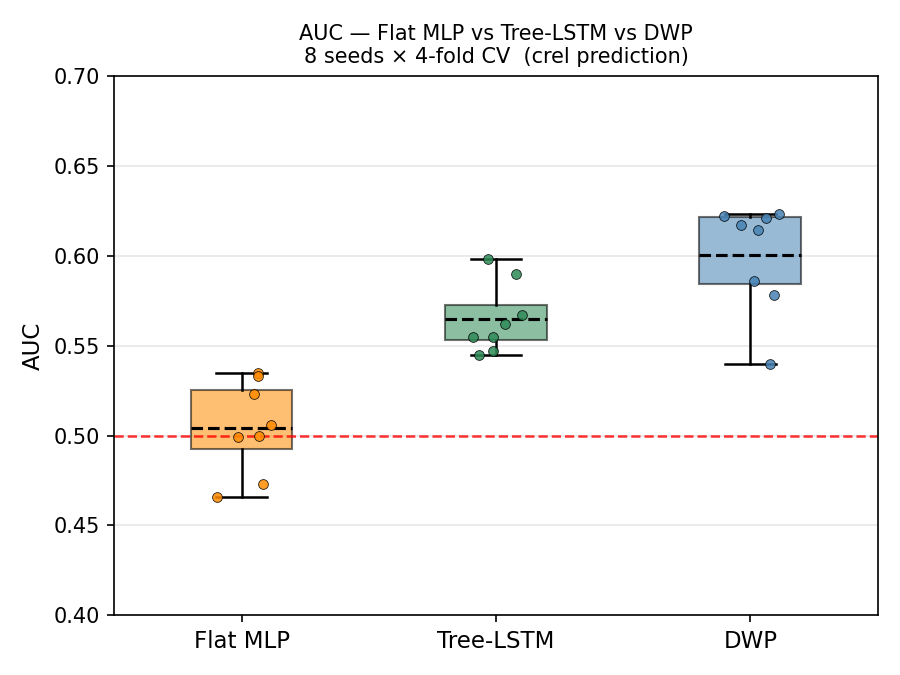
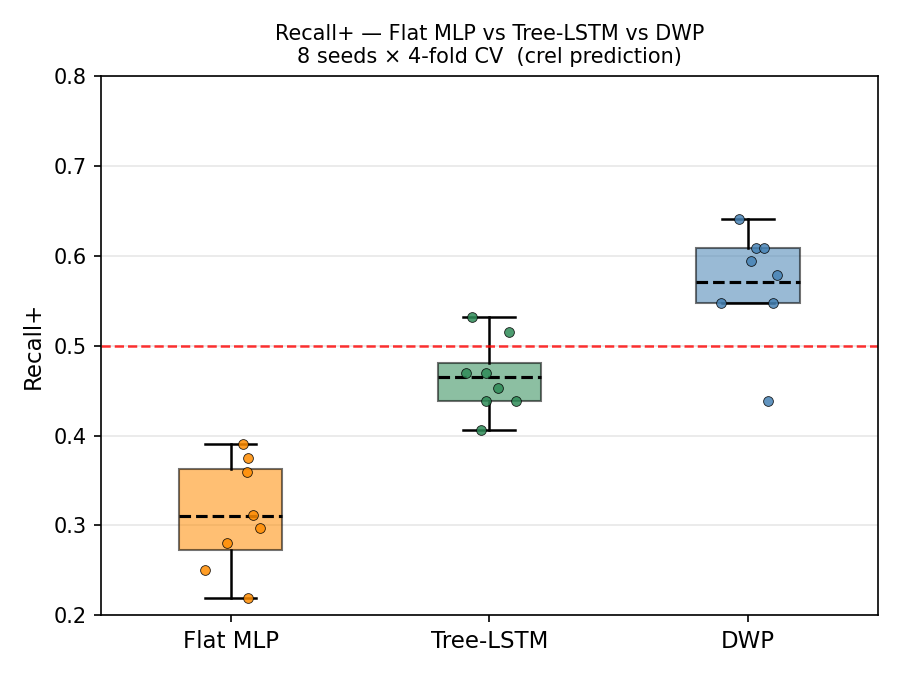
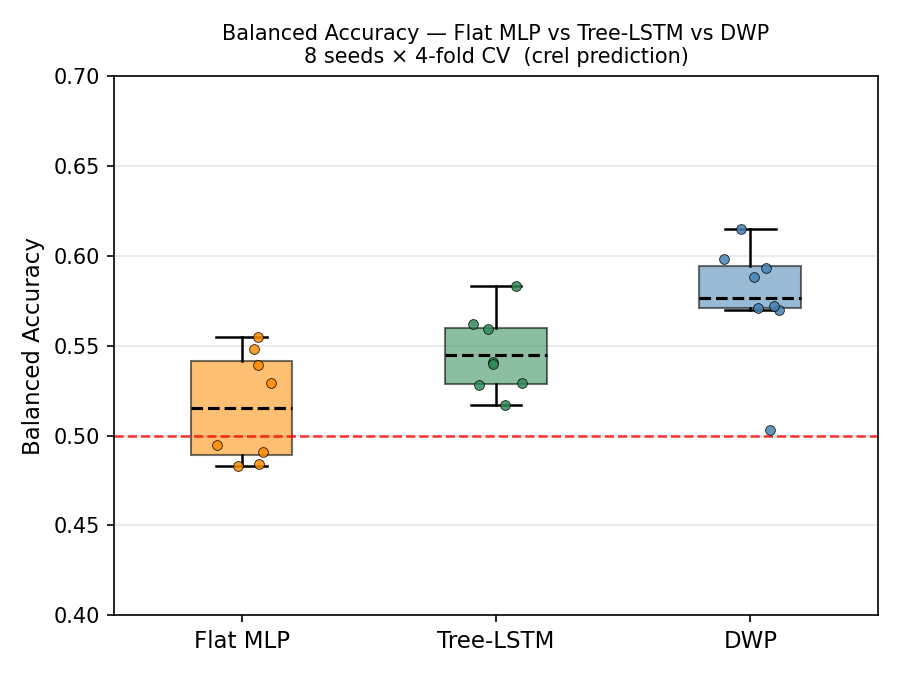
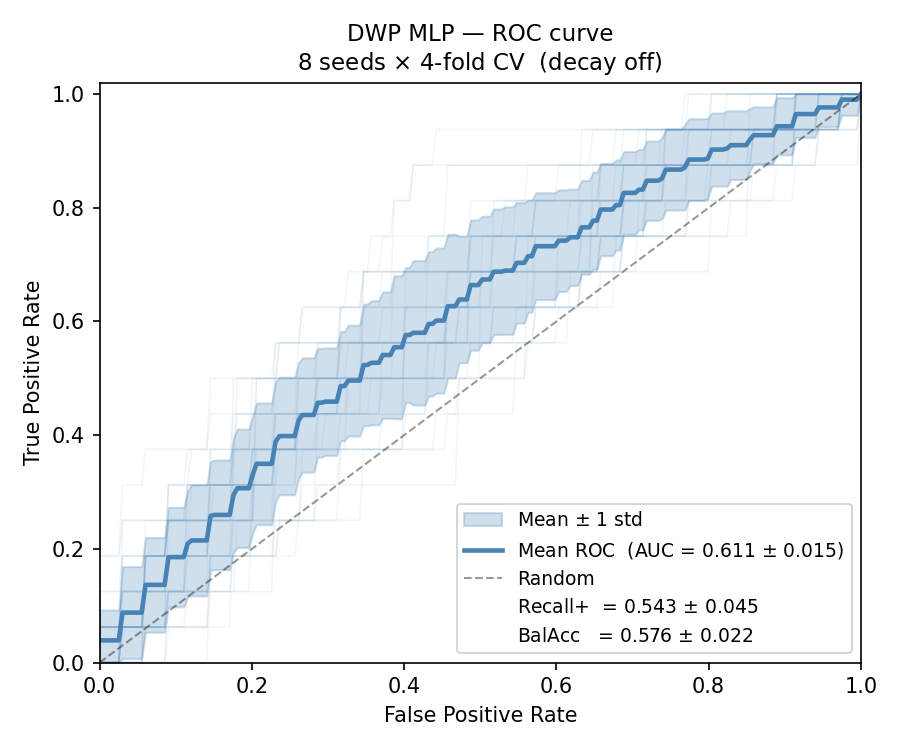
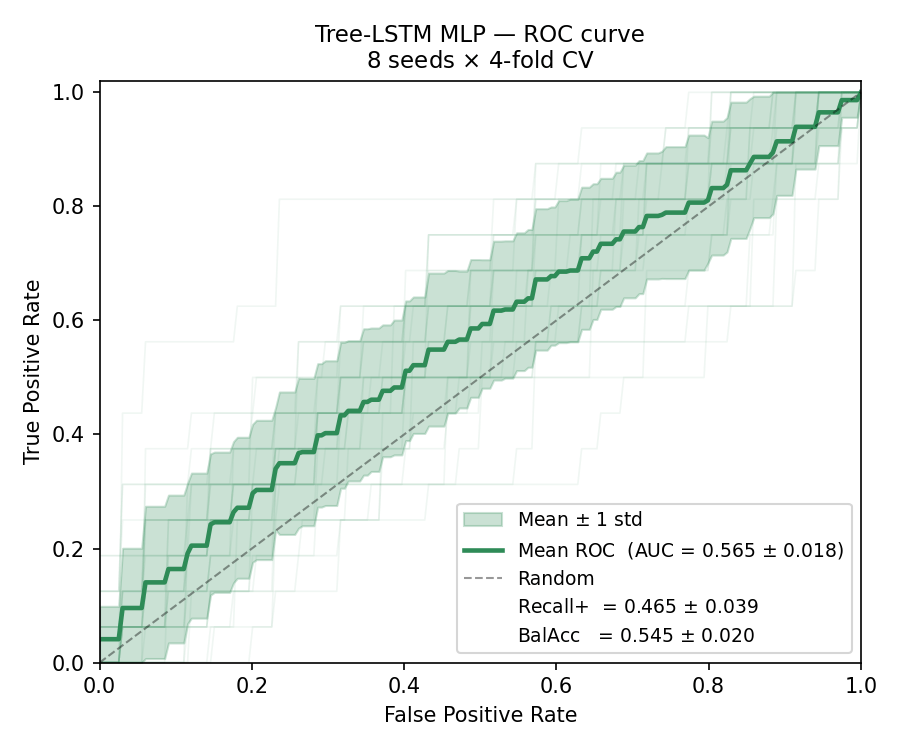
Comparing with a flat neural network trained directly on the ratios, and Tree-LSTM embeddings (50-dim).
(but why? is it better)
Interpretation. DWP answers the question: how much does each level of specificity in subtree b contribute to predicting the outcome?
The ratios at the leaves may be less important and more susceptible to gating noise: Depth 0 corresponds to the subtree root (most general population); increasing depth corresponds to increasingly specific subpopulations which may be less important.
Parameter efficient: The non-linear predictor is trained on a much low-dimensional embedding than the original vector (~2.3k dims) -> 64-dims. So the first layer of the neural network now only has 64 neurons instead of 2.3k neurons, this reduces the noise introduced by the model across runs (400x compression of parameters in the model, tighter error bars)
But this is not the end, there is still some finetuning to do, gunning for a 10% increase in the AUC/positive recall.
Discussion points for 30/04
- Is there a relative ranking or importance score we can assign to the different subtrees?
- What about tree pruning, would it make sense to prune out nodes with a very small count or ratio under a certain threshold as a way to further control for inherent noise?
- Modelling with counts rather than ratios, as ratios obscure the effect of small counts?
Next steps on the modelling side:
- Incorporate pairwise tree interaction terms which will measure covariance patterns between pairs of tree embeddings.
- Incorporate covariates to the full model.
By Vidhi Lalchand



