
Vidhi Lalchand
Postdoctoral Fellow, Broad and MIT
Vidhi Lalchand, Ph.D.
For IMU Biosciences
Data & Model
~300 samples, Ratios [On local parents]
stratify_labels = clean_response["agvhd34"].values
indices = np.arange(len(clean_tv_num))
train_indices, val_indices = train_test_split(
indices, train_size=250, stratify=stratify_labels, random_state=24
)
y = clean_response["agvhd34"].values
N = len(y)
X_raw = clean_tv_num.values.astype(float) # raw ratios
# 1) Log-transform counts (if they are non-negative)
X_log = np.log1p(X_raw) # log(1 + x), safe for x >= 0
# 2) Standardize to improve kurtosis / skewness
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X_log)Model Framework: Logistic Classification with Elastic net regularisation
For total samples NNN, positives N1N_1N1, negatives N0N_0N0
Threshold \(p_{i}\) to classify, \( y_{i} \in (0,1)\)
Total objective Loss:
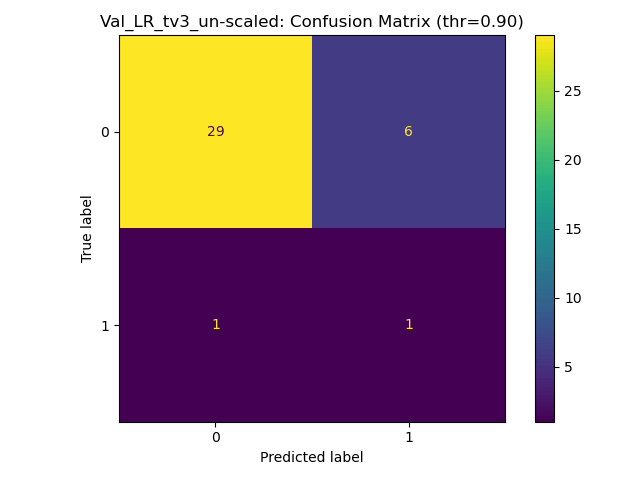
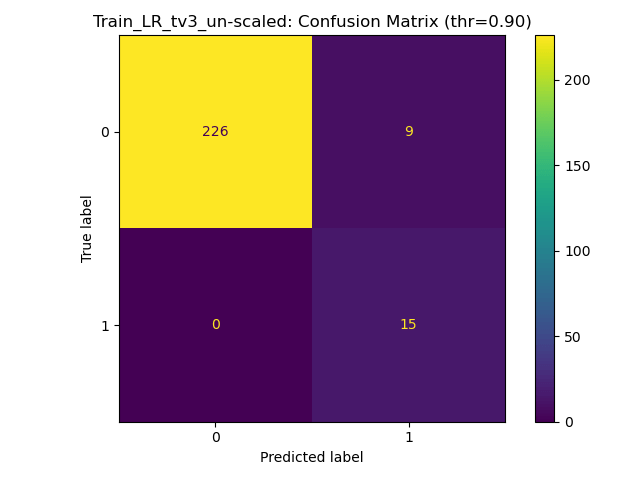
Results for Training on Raw - Ratios Tv5
Respectable but unreliable generalisation.
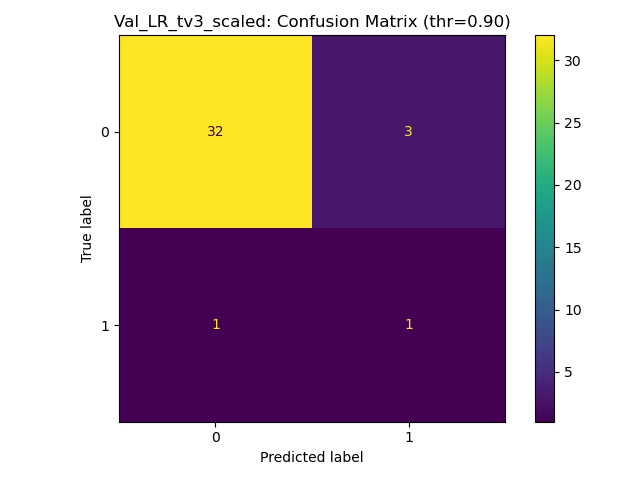
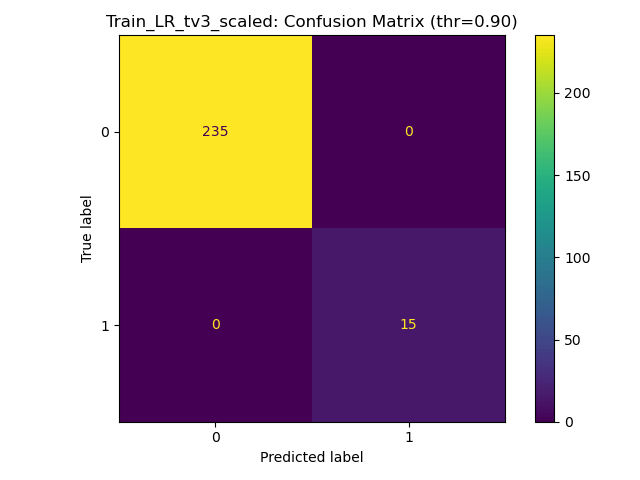
Results for Training on Scaled - Ratios Tv5
100% training acc, generalises with strong penalisation for false negatives, but can still produce FNs. Scaling the ratios is better for generalisation.
class TinyMLP(nn.Module):
def __init__(self, d_in, d_hidden=24, p=0.4):
super().__init__()
self.net = nn.Sequential(
nn.LayerNorm(d_in),
nn.Linear(d_in, d_hidden), nn.ReLU(), nn.Dropout(p),
nn.Linear(d_hidden, d_hidden//2), nn.ReLU(), nn.Dropout(p),
nn.Linear(d_hidden//2, 1)
)
def forward(self, x): return self.net(x).squeeze(-1)Alternative Framework: Small MLP w. dropout
Canonical MLP w. ReLU non-linearity and a dropout probability parameter of 0.4
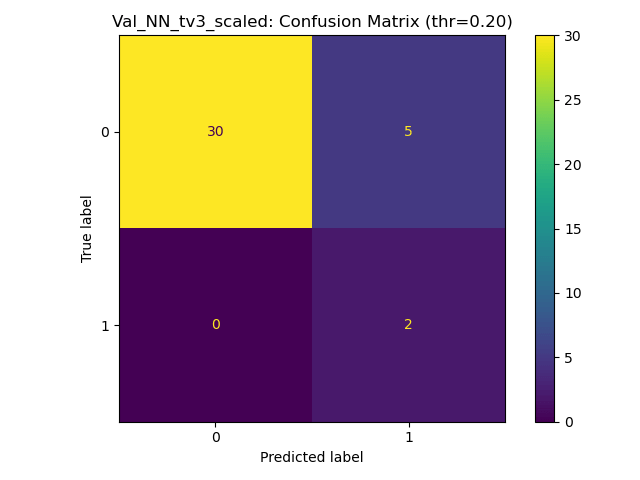
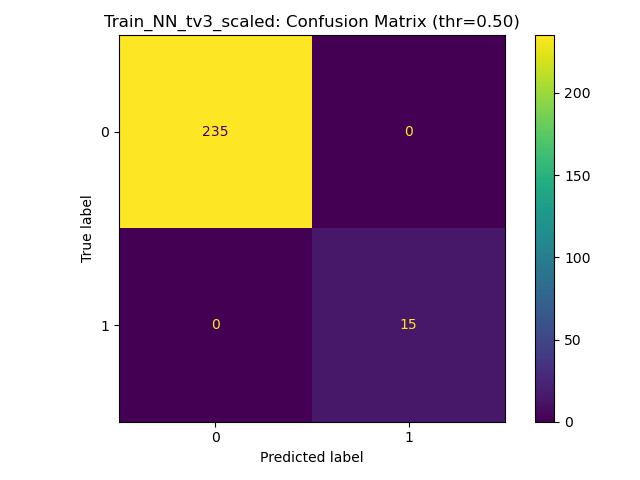
Results for Training with Small MLP w. aggressive dropout
100% training acc, generalises with strong penalisation for false negatives, over cautious
By Vidhi Lalchand



