miromind-ai/MiroMind-M1-RL-62K: (question, answer) for math reasoning
Dataset
Model
deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B: distillation model of R1
Background
Background
GRPO
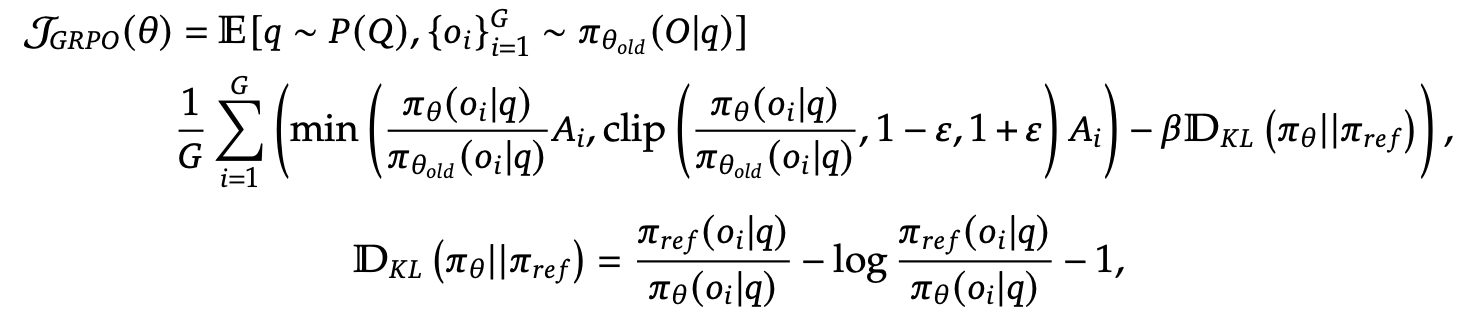
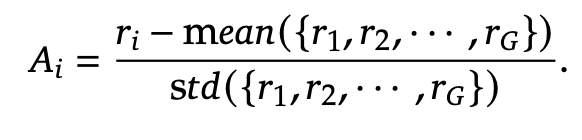
My Experiment
- First sample 32 responses for question in Training set
- Split the question by solve rate to five groups: (0.0, 0.2], (0.2, 0.4], (0,4, 0.6], (0.6, 0.8], (0.8, 1.0] 4k questions in each interval
- Train a model with each data split with grpo
Results
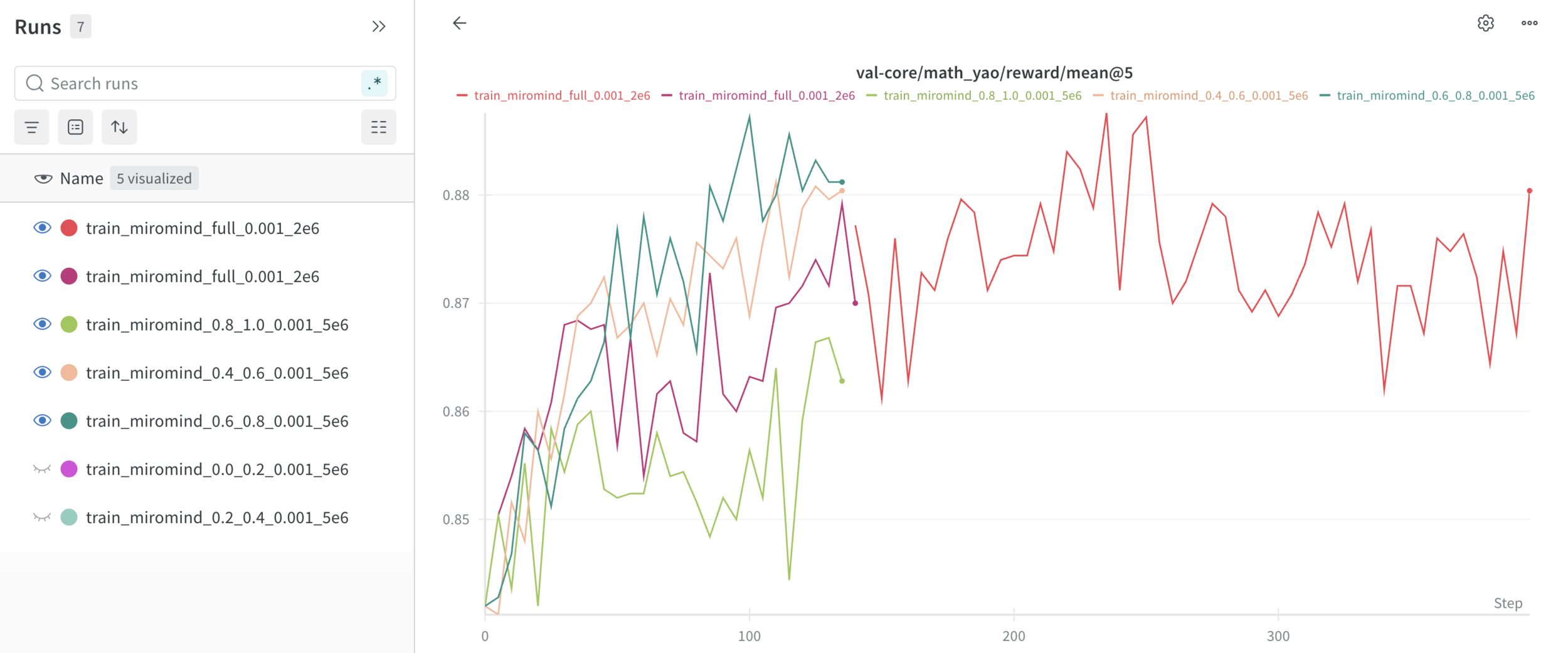
4k match the performance of 62k.
deck
By Yao



