💭
🤖
🤖
🤖
🤖
🤖
🤖
💭
💭
👨🏻💻
Vibe Coding
Agentic Engineering
from
to
How did we get here?
🤖
💭
AI Augmented Development

How did we get here?
🤖
💭
Context is 👑

AI had been around
for a while...
🤖
💭

AI has existed in universities and
big tech organizations for many years.
A friend of mine studied neural networks at the Technion about 20 years ago…
Deep Blue beat Gary Kasparov in 1996
IBM Watson, Siri & Alexa are old news...
Interactive timeline from 2015 - 2025
A famous interview
🤖
💭
It was a futuristic, geeky gimmick.


It did not significantly impact our lives.
The machine is sentient!
🤖
💭
In 2022, Blake Lemoine, a Google AI engineer, was fired from Google for violating its employee confidentiality and data security policies after he publicly claimed its LaMDA artificial intelligence was sentient.
Later that year, we had the GPT moment…

GPT moment!
🤖
💭
In late Nov 2022, OpenAI made ChatGPT
available to the public for free!
100 million monthly users in 2 months!

It reached 1 million users
within just 5 days of its launch!
476 million December 2024
1 billion monthly users by October 2025
But Chat GPT was just a Front!
🤖
💭
While ChatGPT was offered for free
to the general public...
The web exploded with AI services as a result.
OpenAI also offered its AI models
via a paid API platform

Multi-Domain Use cases of AI models
🤖
💭
Gen(erative) AI
Text & Language Generation
- Conversational AI (Chatbots, Assistants)
- Content creation (emails, stories, summaries)
- Translation & grammar correction
- Code generation
Image Generation
- Creating & editing images with Midjourney, DALL.E, GPT...
Video Generation
- Video from text or images, Deepfakes & Avatars, Auto-edits, Animation
Audio Generation
- Text-to-speech (TTS), AI voice cloning, Music generation
Perception AI (Understanding the real world)
Vision (object recognition, tracking), Speech Recognition, Sensor Fusion (e.g. for robotics, drones)
Predictive / Analytical AI
Fraud detection, Forecasting, Diagnostics, Recommendations etc.
Tech Giants had to join in
🤖
💭
Google was forced to change its strategy and integrate AI into its search results to stay relevant.
Google also made its own models available via API, along with other public tools like Gemini and NotebookLM.
Microsoft, Amazon, Meta, Apple, and X have integrated their own AI models into their services and are offering them as cloud services as well.








New players like Anthropic and Mistral had emerged.

The Open Source Eco System
🤖
💭
Open source experienced a significant growth as well.



Tools like Ollama, LM Studio, and OpenRouter make it easy to run models on your infrastructure (on prem).




Running models Locally require a strong infrastructure.
🤖
💭
Will you infer the model as a user, or as a part of your product, at runtime?
Is the LLM intended for general use?
Or will it need to be custom tailored for a specific use-case?
Can you use hosted LLMs over the network?
Or is "on-prem" a requirenment?
Some key questions to ask
Is the budget a consideration?
You may want to optimize for a faster customized model
Why do we need so many models?
The Everyday Choice: Model
🤖
💭
Pick capability per task, not one model for everything
Haiku → fast & cheap — lookups, summaries, simple edits
Sonnet → the daily driver — most coding & analysis
Default: live on Sonnet, reach for Opus when it's worth it.
Opus → heavy reasoning — the hardest ~10–15%
The Everyday Choice: Effort (Opus & Sonnet)
🤖
💭
Same model can think harder or lighter
Higher effort = deeper reasoning, more time & cost
Supported on Opus & Sonnet (not Haiku)
/effort in Claude Code: low → medium → high → xhigh → max
Range: Haiku = quick, then from Sonnet/low to Opus/max = deepest reasoning
The Equivalents in Codex
🤖
💭
Model: GPT-5.5 · GPT-5.4 · GPT-5.4-Mini · GPT-5.3-Codex · GPT-5.2
Reasoning: Low → Medium → High → Extra High (on every model)
Two dials always — plus a third when the model supports it
Speed: GPT-5.5 · GPT-5.4 models only.
~1.5× faster, higher credit use
Same mental model as Claude — model + effort — with an extra speed lever on the big models
How LLMs process text
🤖
💭

They operate by statistical probabilities.
While they may appear to understand, this is merely pattern matching, not human-like cognition.
LLMs do not "understand" text like humans do
Tokenization: converts text into tokens which can be
words, parts of words, or characters.
Embeddings: numerical representations that capture the meaning and context of these tokens.
Pattern recognition is the model's ability to find statistical relationships and structures within this numerical data.
Prediction: how the model determines the most statistically probable next word to generate coherent and relevant text.
Known issues when working with LLMs
🤖
💭
Training Data Limitations (a.k.a data cutoff)
Hallucination and Accuracy
Context Window Constraints
Reasoning Limitations
Inconsistency
Domain-Specific Limitation
Some of the solutions
🤖
💭
Web search tools, fact-checking tools
System prompts and Prompt engineering
Condense information before analysis
Break complex problems into smaller, sequential steps
Implement Retrieval Augmented Generation (RAG) systems
Implement human-in-the-loop workflows for critical decisions
Fine-tune models on domain-specific data when possible
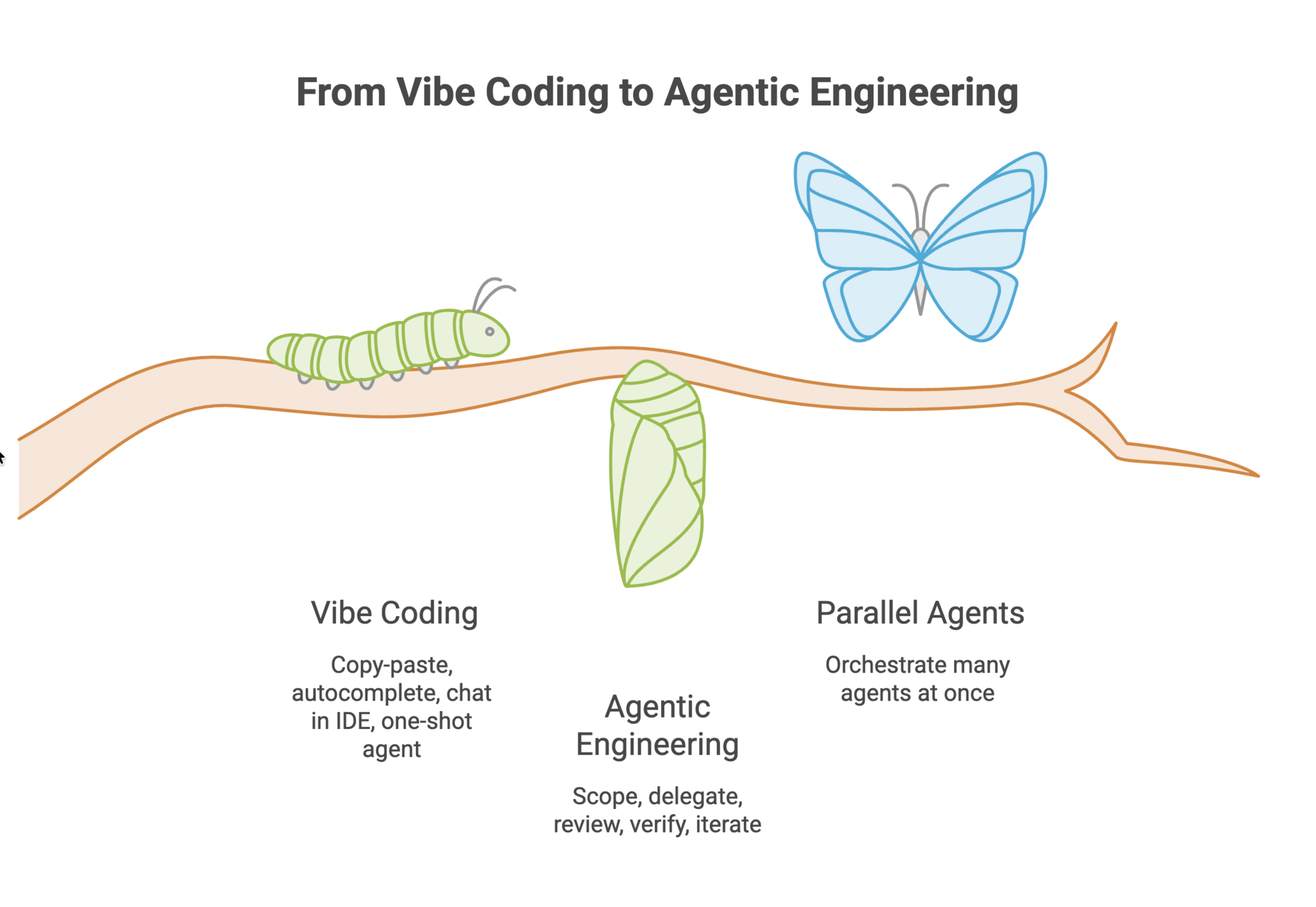
From Vibe Coding to Agentic Engineering
Vibe Coding
By Yariv Gilad




