Aimar Rodríguez Soto
aimar.rodriguez.s@gmail.com
Introduccion a NoSQL
Los fabricantes de BD Relacionales han presentado habitualmente su producto como la unica solucion para la persistencia de datos.
NoSQL propone que la capa de persistencia no tiene porque ser responsabilidad de un unico sistema, que la mejor herramienta para cada proposito sea utilizada.
NoSQL - Not Only SQL - es una categoria de sistemas de gestion de base de datos alternativa a los basado en el modelo relacional
Tanto los RDBMS como NoSQL son sistemas de almacenamiento estructurado, sin embargo, NoSQL no tiene schemas, no permite operaciones JOIN y es horizontalmente escalable
La diferencia principal es la forma en la que se almacenan los datos.
En una RDBMS hay que convertir nuestros datos a tablas, para despues se transformados en objetos usando un lenguaje de programacion.
En NoSQL simplemente se guardan los datos, sin necesidad de definir esquemas o estructura por adelantado.
Caracteristicas principales
-
Facil de usar en clústers de balanceo de carga convencionales - faciltan escalabilidad horizontal
- Almacenamiento de datos persistentes
- No tienen esquemas fijos
- Suelen tener un lenguaje de consultas propio en lugar de usar un estandar
- Tienen propiedades ACID (Atomicity, Consistency, Isolation, Durability) en cada nodo del cluster.
ACID / BASE
En el mundo relacional estamos familiarizados con las transacciones ACID. Las BBDD NoSQL son mas optimistan y siguen el modelo BASE:
- BAsic availability: El almacén funciona la mayoria del tiempo, incluso ante fallos, gracias al almacenamiento distribuido
- Soft-state: Los almacenes y sus replicas no tienen porque ser consistentes en todo momento. El programador puede verificar su consistencia.
- Eventual consistency: La consistencia se da eventualmente
Base es una alternativa a ACID para almacenes de datos que no se adhieren al modelo relacional
RDBMS / NoSQL
Las RDBMS tradicionales permiten definir la estructura de un modelo de datos que requiere reglas rígidas y garantizan ACID
Las aplicaciones web modernas presentan desafíos diferentes a aquellos inherentes a sistemas empresariales tradicionales
- Datos a escala web
- Alta frecuencia de lecturas y escrituras
- Cambios frecuentes en el modelos de datos
- No se requiere el mismo nivel de ACID
¿Cuando usar NoSQL?
Hay desafios en un sistema de informacion dificiles de resolver usando tecnologias de BD relacionales
- La BBDD no escala al trafico existente a un coste aceptable
- El tamaño del esquema de datos ha crecido desproporcionadamente
- El sistema genera muchos datos temporales que no corresponden al almacen principal. (configuración de usuario, carritos de compra, etc)
- Los datos tienen gran cantidad de texto, imágenes y/o columnas como BLOBs
- El modelo de datos puede variar o no requiere una estructura rigida
Arquitectura de las BBDD NoSQL
Habitualmente ofrecen garantias de consistencia débiles, como eventual consistency y/o transacciones restringidas a elementos de datos simples
Emplean una arquitectura distribuida, guardando los datos de modo redundante en distintos servidores
Suelen ofrecer estructuras de datos sencillas como arrays asociativos o almacenes de pares clave-valor
Existen diferentes tipos de BBDD NoSQL de acuerdo a su implementacion.

BBDD Clave / Valor
Usan un modelo tabular donde cada fila puede tener una configuración diferente de columnas
Son buenas en:
- Gestion de tamaño
- Cargas de escrituras masivas orientadas al stream
- Alta disponibilidad
- MapReduce
Ejemplos:
HBase, Hypertable, Cassandra, Riak
BBDD orientadas a Documentos
Usan como modelo de datos colecciones de documentos que contienen una serie de pares clave-valor.
Son buenas en:
- Modelado de datos natural
- Amigables al programador
- Desarrollo rapido
- Orientadas a la web: CRUD
Ejemplos:
MongoDB, CouchDB
BBDD orientadas a Grafos
Su modelo de datos es un grafo de propiedades formados por nodos, relaciones y propiedades de los nodos y las relaciones.
Son buenas en:
- Modelar un dominio en forma de grafo
- Buen rendimiento cuando los datos están interconectados y no son tabulares
- Operaciones transaccionales que exploten relaciones entre entidades
Ejemplos:
Neo4j
Teorema CAP
Es imposible para un sistema computacional distribuido oferecer simultaneamente las siguientes tres garantias:
- Consistencia: Todos los nodos ven los mismos datos al mismo tiempo
- Disponibilidad: Cada peticion recibe una respuesta acerca de si tuvo exito o no
- Tolerancia a la particion: El sistema continua funcionando a pesar de la perdida de mensajes
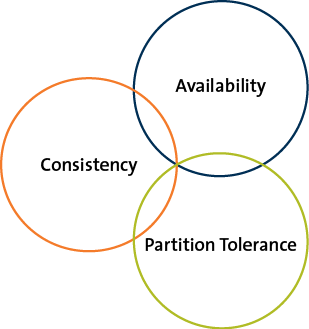
MongoDB
MongoDB es un sistema de base de datos NoSQL orientado a documentos.
MongoDB guarda datos en documentos tipo BSON (Binary JSON) con un esquema dinamico, haciendo la integracion de datos en ciertas aplicaciones mas facil y rapida.
Mongo tiene ciertas limitaciones:
- No hay tablas en la BBDD
- No hay operaciones JOIN
- No hay transacciones complejas
"MongoDB es una base de datos orientada a documentos, escalable, de codigo abierto y de alto rendimiento."
-10gen
Caracteristicas Principales
- Modelo de datos basado en documentos
- Consultas ad hoc
- Índices secundarios
- Replicación
- Velocidad y durabilidad
- Escalabilidad
-
Consultas ad hoc: MongoDB soporta busqueda por campos, consultas de rangos y expresiones regulares. Las consultas pueden devolver un campo especifico o puede ser una funcion JavaScript definida por el usuario.
-
Indexación: Cualquier campo de los documentos puede ser indexado. El concepto de indice es similar al de las BD relacionales.
-
Replicación: MongoDB soporta la replicacion maestro-esclavo.
- El maestro puede ejecutar comandos de lectura y escritura
- El esclavo puede copiar los datos del maestro que solo puede usar para lectura, pero no puede realizar escrituras.
- Balanceo de carga: Mongo escala de forma horizontal usando el concepto de shard.
- El desarrollador elige una llave shard, que determina como serán distribuidos los datos en una colección. Los datos se dividen en rangos y se distribuyen a través de múltiples redes
- Un shard es un maestro con uno o mas esclavos
- MongoDB puede ejecutarse en múltiples servidores, balanceando la carga y/o duplicando los datos para mantener el sistema funcionando en caso de fallo de hardware.
- Almacenamiento de archivos: MongoDB puede ser utilizado con un sistema de archivos usando múltiples servidores para el almacenamiento de archivos.
- Agregación: La función MapReduce y el operador aggregate pueden ser utilizados para el procesamiento por lotes de datos y operaciones de agregación. Esto permite a los usuarios obtener el tipo de resultado que se obtiene cuando se utiliza el comando SQL group-by
- JavaScript en el lado servidor: Mongo tiene la capacidad de realizar consultas usando JavaScript, haciendo que estas sean enviadas directamente a la base de datos para ser ejecutadas.
Casos de uso
- Almacenamiento y registro de eventos
- Sistemas de manejo de documentos y contenido
- Comercio Electrónico
- Juegos
- Problemas de alto volumen
- Aplicaciones móviles
- Almacén de datos operaciones de una página Web
- Manejo de contenido
- Proyectos ágiles
- Estadísticas en tiempo real
¿Cuándo usar MongoDB?
MongoDB puede ser usado como una alternativa directa a los RDBMS. Es importante considerarlo como una alternativa y no un reemplazo.
Puede hacer muchas cosasque otras herramientas puede hacer, algunas mejor otras peor. Recordar, NoSQL significa mas rendimiento pero menos funcionalidad
No usar esquemas puede ser comodo y agil, pero la mayoria de datos son estructurados. El beneficio es no tener que crear las estructuras antes de usarlas y reducir la distancia entre objetos y datos
Manipulación de datos
MongoDB guarda los datos en documentos tipo JSON con un esquema dinámico llamado BSON, por tanto, no existe un esquema predefinido.
Los elementos que contienen los datos son llamados documentos y se agrupan en colecciones.
Colecciones
Las colecciones pueden tener un número indeterminado de documentos.
Podemos pensar en las colecciones como tablas y en los documentos como sus filas, aunque cada documento de la misma colección puede tener campos diferentes.
Documentos
La estructura de un documento es muy simple, y sigue el mismo esquema que los objetos JSON.
Los documentos consisten en un conjunto de pares clave/valor, parecido a las matrices asociativas en un lenguaje de programación. Los pares que forman el documento pueden tener como valor números, cadenas, datos binarios e incluso otros documentos.
Conceptos clave
- MongoDB tiene el concepto de base de datos similar al de schema en el mundo relacional. Dentro de un servidor mongo puede haver 0 o más bases de datos
- Una base de datos puede tener una o más colecciones
- Las colecciones están formadas por 0 o más documentos
- Los documentos están compuestos por uno o varios campos
- Los índices en MongoDB funcionan como los de una RDBMS
- Los cursores son utilizados para acceder progresivamente a los datos recuperados en una consulta. Pueden usarse para contar o moverse hacia delante entre los datos
Ejemplo de documento
{
"_id":
ObjectId("4efa8d2b7d284dad101e4bc7"),
"Last Name": "PELLERIN",
"First Name": "Franck",
"Age": 29,
"Address": {
"Street": "1 chemin des Loges",
"City": "VERSAILLES"
}
}
BSON
Es una serialización codificada en binario de documentos JSON. Soporta documentos dentro de otros documentos y arrays. Contiene extensiones para datos que no son parte de JSON como Date.
Soporta los siguientes tipos de datos numérico:
- int32 - 4 bytes
- int64 - 8 bytes
- double - 8 bytes
Claves de los documentos
MongoDB siempre introduce a los documentos un campo adicional _id. Cada documento tiene un id unico, que puede tener un valor de cualquier tipo excepto un array.
El programador puede generar el identificador:
x = "55623123R"
y = ObjectId("507f191e810c19729de860ea")
O dejar a MongoDB que lo haga. En este ultimo caso el campo sera del tipo ObjectId. Por lo genera el preferible que MongoDB lo genere por nosotros.
El campo _id siempre esta indexado, lo que significa que sus detalles se guardan en la colección del sistema system.indexes
Utilidades
- mongo: Un shell interactivo que permite a los desarrolladores ver, insertar, eliminar y actualizar datos en su base de datos. También permite otras funciones como la replicación de información, configuración de shards y ejecución de JavaScript.
- mongostat: Es una herramienta de línea de comandos que muestra en resumen una lista de estadística de una instancia de MongoDB en ejecución.
- mongotop: Provee un metodo para dar seguimiento a la cantidad de tiempo que dura una lectura o escritura de datos en una instancia.
- mongoimport/mongoexport: Facilita la importación / exportación de contenido desde JSON, CSV o TSV.
Documentacion
La documentacion completa de MongoDB se puede encontrar en el siguiente enlace:
Instalación
Instalar MongoDB en Ubuntu es muy simple:
apt-key adv --keyserver keyserver.ubuntu.com --recv 7F0CEB10
echo "deb http://downloads-distro.mongodb.org/repo/ubuntu-upstart dist 10gen" | tee -a /ect/apt/sources.list.d/10gen.list
apt-get -y update
apt-get -y install mongodb-10gen
service mongodb start
O podemos instalar la version 2.4.9 con
apt-get install mongodb
El siguiente enlace tiene instrucciones para la instalacion en diferentes plataformas:
http://docs.mongodb.org/manual/installation/
Usando MongoDB
El comando mongo es un shell de JavaScript completo. Cualquier funcion de JavaScript, sintaxis o clase puede usarse en el shell.
Para ejecutar el comando sobre una base de datos local:
mongo base_de_datos
> j = { name : "mongo" };
{ "name" : "mongo" }
> t = { x : 3 };
{ "x" : 3 }
> db.things.save(j);
> db.things.save(t);
> db.things.find();
{ "_id" : ObjectId("51e50d3b70f9b7c7fdbd8d90"), "name" : "mongo" }
{ "_id" : ObjectId("51e50d3b70f9b7c7fdbd8d91"), "x" : 3 }
> for (var i = 1; i <= 20; i++) db.things.save({x : 4, j : i});
> db.things.find();
{ "_id" : ObjectId("51e50d3b70f9b7c7fdbd8d90"), "name" : "mongo" }
{ "_id" : ObjectId("51e50d3b70f9b7c7fdbd8d91"), "x" : 3 }
...
Type "it" for more
> // Iterate through the remaining items
> it
{ "_id" : ObjectId("51e50d3b70f9b7c7fdbd8da4"), "x" : 4, "j" : 19 }
{ "_id" : ObjectId("51e50d3b70f9b7c7fdbd8da5"), "x" : 4, "j" : 20 }
> // Store the cursor of the DB in a variable
> var cursor = db.things.find();
> while (cursor.hasNext()) printjson(cursor.next());
{ "_id" : ObjectId("51e50d3b70f9b7c7fdbd8d90"), "name" : "mongo" }
{ "_id" : ObjectId("51e50d3b70f9b7c7fdbd8d91"), "x" : 3 }
...
> // Use functional features of JavaScript
> db.things.find().forEach(printjson);
{ "_id" : ObjectId("51e50d3b70f9b7c7fdbd8d90"), "name" : "mongo" }
{ "_id" : ObjectId("51e50d3b70f9b7c7fdbd8d91"), "x" : 3 }
...
> // cursors like an array
> var cursor = db.things.find();
> printjson(cursor[4]);
{ "_id" : ObjectId("51e50d3b70f9b7c7fdbd8d94"), "x" : 4, "j" : 3 }
>
Mongo Shell
El shell mongo ofrece muchas funciones tipicas de Shells UNIX:
- Autocompletado
- Navegar la historia de comandos
- Ofrece un objeto implícito llamado db que representa la base de datos
- Las colecciones se crean automaticamente al insertar el primer documento
- El shell no distingue entre enteros y números de coma flotante, todo se representa como una coma flotante de 64 bits
Comandos
- help - muestra la ayuda
- db.help() - Muestra ayuda de los metodos de la BBDD
- db.<collection>.help() - Detalles de metodos aplicables a una coleccion
- show dbs - Imprime una lista de bases de datos del servidor
- use <database> - Cambia la base de datos, haciendo que db apunte a la BD seleccionada
- show collections - Muestra todas las colecciones de la BD actual
- show users - Imprime los usuarios de la BD
Se puede encontrar una guía en el siguiente enlace
Documentos de consulta
Documentos que indican un patron de claves y valores que deban ser localizados
SELECT * FROM things WHERE name="mongo"
db.things.find({name: "mongo"}).forEach(printjson);
Recuperar el primer elemento que cumple alguna restriccion:
printjson(db.things.findOne({name: "mongo"}));
Limitar el numero de resultados:
db.things.find().limit(3);
Selectores de consulta
Los selectores de consulta en MongoDB son lo equivalente a la cláusula where de una sentencia SQL
El selector es un objetos JSON, el mas sencillo es {} que sirve para seleccionar todos los documentos (null es equivalente).
Los operadores $lt, $lte, $gt, $gte, $ne son usados para operaciones menor que, menos o igual que, mayor que, mayor o igual que u operaciones desigual.
db.things.find({gender: "m", weight: {$gt: 500} });
El operador $exists se usa para comprobar la presencia o ausencia de un campo.
db.things.find({ name: { $exists: true } });
Para usar el operador booleano OR, habra que usar el operador $or y asociarle un array de tuplas clave/valor sobre los que realizar el OR.
db.things.find({gender: "m", $or: [{name: "me"}, {name: "Other"}] });
Los arrays en MongoDB son objetos de primera categoria. Por ello, se puede comprobar la inclusión de un elemento dentro de un array al igual que con un único valor.
{knows: "me"} encontrara cualquier documento donde el array knows tenga un valor "me"
Actualizar documentos
El comando update tiene dos argumentos, el selector a usar y el campo a actualizar.
db.things.update({ name:"me"}, {age: 22});
Cuidado! Esta sentencia los documentos con nombre "me" por otros que solo contienen un campo edad.
Para cambiar un unico campo hay que usar el modificador $set:
db.things.update({weight: {$lt: 100}}, {$set: {name: "Yo"}});
Ademas de $set se pueden usar otros modificadores
El modificador $inc se usa para incrementar el campo por una cantidad positiva o negativa
db.things.update({name: "me"}, {$inc: {age: -1}});
Tambien se pueden añadir valores nuevos a campos mediante el modificador $push.
db.things.update({name: "me"}, {$push: {knows: "someone"}});
Podemos escoger crear un documento si no existe. Para esto se coloca un tercer parámetro true en la llamada a update.
db.things.update({name: "me"}, {$inc: {age: -1}}, true);
Si queremos que update actualize todos los documentos que cumplen la expresión hay que poner un cuarto parámetro a true.
db.things.update({name: "me"}, {$inc: {age: -1}}, false, true);
Búsquedas Avanzadas
- Proyecciones: El comando find puede tomar un segundo parametro para seleccionar los campos a mostrar. Por defecto, _id se muestra a menos que se explicite al contrario.
- db.things.find(null, {name: 1, _id: 0});
- Ordenación: El metodo sort() functiona como el selector de las proyecciones. Hay que indicar los campos por los que ordenar, indicando orden ascendente con 1 y descendente con -1.
- db.things.find().sort({name: 1});
- Paginación: Se soporta con los métodos de cursor skip y limit.
- db.things.find().limit(2).skip(1);
- Conteo: Se puede contabilizar resultados
- db.things.count();
Scripting en MongoDB con JavaScript
Al escribir scripts en JS para el shell de mongo hay que tener en cuenta:
- Para asignar un valor a la variabe db hay que utilizar el metodo getDB() o el metodo connect().
- conn = new Mongo(); db = conn.getDB("myDatabase");
- db = connect("localhost:27020/myDatabase")
- Dentro del script se invoca a db.getLastError() para esperar a la conclusion de la operacion write.
- No se pueden usar comando de ayuda (show dbs, etc) dentro de un fichero JavaScript.
Para evaluar codigo desde la linea de comando:
mongo test --eval "printjson(db.getCollectionNames())"
Para ejecutar un fichero JS
mongo localhost:27017/test myjsfile.js
Para ejecutar un fichero desde el shell
load("myjsfile.js");
Mas documentacion en:
http://docs.mongodb.org/manual/tutorial/write-scripts-for-the-mongo-shell/
Herramientas graficas
- UMongo es una aplicación de sobremesa multiplataforma para navegar un cluster de MongoDB
-
Se puede acceder a una interfaz administrativa desde http://localhost:28017/
- Existen diferentes alternativas que pueden ser encontradas en http://docs.mongodb.org/ecosystem/tools/administration-interfaces/
Modelado de Datos en MongoDB
Mongo no tiene un esquema fijo, sin embargo, contiene un esquema orientado a documentos.
Hay que tener una serie de consideraciones a la hora de diseñar el modelo de datos:
- ¿Tiene sentido o es posible colocar los datos en una colección?
- ¿Es posible que se excedan los 16MB de limite para documentos?
- ¿Que datos pertenecen a un documento?
- ¿Se pueden cambiar los datos en un sitio central en lugar de cambiar el conjunto de documentos que contienen esos datos?
- ¿Se van a empotrar documentos o no?
Cuando se crea una aplicación que usa RDBMS se para un tiempo considerable diseñando las tablas y las relaciones entre ellas.
En MongoDB hablamos de diseño de datos dirigido por la aplicacion dado que el concepto de modelado de información es equivalente al modelado basado en objetos de OOP.
Tareas en el nivel de aplicación
Dado que las bases de datos NoSQL sacrifican funcionalidad por rendimiento, muchas responsabilidades típicas de los RDBMS se mueven al nivel de aplicación.
En MongoDB no existen restricciones, por lo tanto los datos habrán de ser validados a nivel de aplicación.
A menudo se realizaran pre-joins colocando datos dentro de un documento que de otro modo estarían repartidos en varias tablas. De esta forma nos ahorramos las "JOIN manuales" a nivel de aplicación y evitamos realizar tantas lecturas a la BD.
La principal diferencia con una RDBMS es la carencia de JOINs.
Esto se debe a que las JOIN no suelen ser escalables. Debido a esto, las JOIN se mueven al nivel de aplicación. Esto significa que si normalizamos los datos hay que hacer una segunda consulta por cada elemento a agregar.
Ejemplo:
db.employees.insert({_id: ObjectId("4d85c7039ab0fd70a117d730"),
name: 'Leto'})
db.employees.insert({_id: ObjectId("4d85c7039ab0fd70a117d731"),
name: 'Duncan', manager: ObjectId("4d85c7039ab0fd70a117d730")});
db.employees.insert({_id: ObjectId("4d85c7039ab0fd70a117d732"),
name: 'Moneo', manager: ObjectId("4d85c7039ab0fd70a117d730")});
db.employees.find({manager: ObjectId("4d85c7039ab0fd70a117d730")})
Relaciones
Se usan dos técnicas para modelar relaciones many-to-one y many-to-many.
Arrays
db.employees.insert({_id: ObjectId("4d85c7039ab0fd70a117d733"),
name: 'Siona',
manager: [ObjectId("4d85c7039ab0fd70a117d730"),
ObjectId("4d85c7039ab0fd70a117d732")] });Documentos empotrados
db.employees.insert({_id: ObjectId("4d85c7039ab0fd70a117d734"), name:
'Ghanima',
family: {mother: 'Chani', father: 'Paul', brother:
ObjectId("4d85c7039ab0fd70a117d730")} });Una tecnica alternativa es des-normalizar, replicar datos a traves de varias colecciones.
Esto se ha hecho históricamente en RDBMS por temas de rendimiento, sin embargo, introduce la complicación de tener que contrastar las restricciones de datos a nivel de aplicación.
Relaciones 1 a 1
Al modelar relaciones one-to-one hay que tener en cuenta los siguientes aspectos:
-
Frecuencia de acceso a documentos
-
Tamaño de los elementos (limitacion de 16MB)
-
La atomicidad y consistencia de los datos
En ocasiones simplemente es mas eficiente colocar un documento dentro de otro.
Relaciones 1 a N
Si hay muchas relaciones no tiene sentido empotrar todos los documentos, especialmente teniendo en cuenta el limite de tamaño.
Por ello se suele enlazar documentos entre colecciones, guardando en el documento que guarda muchas colecciones una referencia a otros documentos.
En relaciones de "1 a pocos" aun puede ser razonable empotrar documentos dentro de otros.
Relaciones N a M
Considerar la relación donde un candidato puede tener varios instructores y viceversa.
A los candidatos se les asignara una serie instructor y a los instructores se les asignara una serie de candidatos.
Esto quiere decir que no podemos empotrar documentos, dado que tenemos una relación bidireccional. La única alternativa que nos queda es almacenar referencias.
Hay que recordar mantener la consistencia en el nivel de aplicación.
Operaciones en MongoDB
CRUD en MongoDB
Create => Insert
Read => Find
Update => Update
Delete => Remove
Trabajamos siempre sobre un documento implicito db que representa la base de datos. Si no se especifica un BD trabajaremos sobre la base de datos test.
Al acceder a una coleccion, esta se creara automaticamente si no existia.
find() y findOne()
Estos metodos utilizan un documento como primer parametro y un segundo para indicar los campos sobre los que realizar la seleccion.
db.ships.findOne({'name':'USS Defiant'}, {'class':true,'_id':false})
El metodo find devuelve todos los documentos que encuentre y el metodo findOne devuelve solo el primero.
find tiene un limite de 20 resultados, para acceder a los siguientes hay que usar it en el shell.
db.ships.find({class:{$gte:'P'}}, {'name':true, '_id':false})
update()
El uso por defecto de update reemplaza el documento seleccionado con los campos del documento pasado en el segundo argumento, manteniendo solo la id. Es decir, borra el viejo y crea uno nuevo.
Por lo general solo queremos reemplazar campos obsoletos, con el operador $set. Tambien se puede usar $unset para quitar valores del documento
db.ships.update({name : 'USS Prometheus'}, {$unset : {operator : 1}})
remove() y drop()
Se reutiliza la sintaxis de find para indicar que documentos se quieren elminar.
Un remove sin argumentos eliminara uno a uno todos los elementos de la coleccion.
La operación drop hará lo mismo que el caso anterior pero mas rápido, ya que no trabaja a nivel de documento y elimina los indices.
db.ships.drop();
db.ships.remove({name : 'USS Prometheus'})
Índices
Los índices mejoran el rendimiento de las consultas y operaciones de ordenación en MongoDB. Operan de forma similar a las de los RDBMS, MongoDB las guarda como un B-Tree que permite la recuperación de listas de claves.
Se crean usando la sentencia ensureIndex identificando el sentido de ordenacion, 1 para ascendente y -1 para descendente.
db.unicorns.ensureIndex({name: 1});
Para obtener los indices de una colección se usa getIndexes.
db.unicorns.getIndexes()
Para eliminarlos se usa dropIndex
db.unicorns.dropIndex({name: 1});
Se pueden crear indices compuestos
db.unicorns.ensureIndex({name: 1, vampires: -1});
Y asegurar que un indice sea único
db.unicorns.ensureIndex({name: 1}, {unique: true});
Para saber si se esta usando un indice se usa explain
db.unicorns.find().explain()
Si la salida indica que se ha usado un cursos BasicCursor quiere decir que el campo no es indexado, se escanearan mas documentos y tardaran mas las búsquedas y ordenaciones.
{
"cursor" : "BasicCursor", // el campo no es indexado
"isMultiKey" : false,
"n" : 1,
"nscannedObjects" : 12,
"nscanned" : 12,
"nscannedObjectsAllPlans" : 12,
"nscannedAllPlans" : 12,
"scanAndOrder" : false,
"indexOnly" : false, // si la consulta se puede resolver mirando sólo el índice
"nYields" : 0,
"nChunkSkips" : 0,
"millis" : 0, // indica cuánto tardó la consulta
"indexBounds" : {
},
"server" : "obssidianPC:27017"Si se usa un indice el campo cursos tendra asociado un indice del tipo BtreeCursor.
{
"cursor" : "BtreeCursor name_1", // los campos de consulta son indexados
"isMultiKey" : false,
"n" : 1,
"nscannedObjects" : 1,
"nscanned" : 1,
"nscannedObjectsAllPlans" : 1,
"nscannedAllPlans" : 1,
"scanAndOrder" : false,
"indexOnly" : false,
"nYields" : 0,
"nChunkSkips" : 0,
"millis" : 0,
"indexBounds" : {
"name" : [
[
"Pilot",
"Pilot"
]
]
},
"server" : "obssidianPC:27017"
}
La coleccion db.system.indexes contiene detalles de todos los índices de una BD de Mongo.
db.system.indexes.find()
Escritura Asíncrona
Para comunicarnos con el servidor de MongoDB, mongod, debemos hacer uso de un driver que envía comandos desde la aplicación al servidor.
Las escrituras en MongoDB son asíncronas, se gana en rendimiento con el riesgo de perder datos si hay un server crash.
Colecciones restingidas
MongoDB soporta colecciones de tamaño limitado. Se crean con el comando db.createCollection()
db.createCollection('logs', {capped: true, size: 1048576}
En este caso cuando la colección alcance 1 MB de tamaño los documentos mas viejos se irán borrando para hacer espacio a los nuevos.
Transacciones
MongoDB soporta transacción atómicas en documentos, pero no soporta transacciones distribuidas y a través de colecciones.
Frente a esto no hay demasiadas opciones, sin embargo se puede:
- Tolerar un poco de inconsistencia
- Estructurar la aplicación de modo que quepa en un solo documento, y usar atomicidad a nivel de documento ($inc, $set, etc.)
- Programar las transacciones a nivel de aplicacion
MapReduce en MongoDB
MapReduce es un enfoque para procesar datos que tiene dos beneficios:
- Se puede paralelizar
- En mongo se puede escribir codigo JavaScript para hacer el procesamiento
Se realiza en dos pasos:
- Map: Mapear los datos transformando los documentos de entrada en pares clave/valor
- Reduce: Reducir las entradas conformadas por estos pares para producir el resultado final.

Ejemplo de MapReduce
Contar el número de hits en un día en un portal web. Para ello vamos a usar una clave compuesta por el recurso, día, año y mes.
var map = function() {
var key = {resource: this.resource, year: this.date.getFullYear(), month:
this.date.getMonth(), day: this.date.getDate()};
emit(key, {count: 1});
};
var reduce = function(key, values) {
var sum = 0;
values.forEach(function(value) {
sum += value['count'];
});
return {count: sum};
};
db.hits.mapReduce(map, reduce, {out: {inline:1}})
Pipeline de Agregación
MongoDB incorpora un mecanismo para agregar datos a documentos en diferentes pasos. Cada paso toma como entrada un conjunto de documentos y produce otro como resultado.
-
$project - Cambia el conjunto de documentos modificando claves y valores
-
$match - Operación de filtrado para reducir el conjunto de documentos
- $group - Reduce el numero de documentos agrupando en base a claves o datos indexados
- $sort - Ordenacion ascendente o descendente
- $skip - Permite saltar documento, es decir, avanzar hasta el documento numero X. Se suele usar juanto a $limit
- $limit - Limita el numero de documentos a procesar
- $unwind - Desagrega los elementos de un array en un conjunto de documentos. Es la unica que incrementa el numero de documentos.
Mas informacion en:

Replicacion y Sharding
La replicación funciona de forma similar a la replicación de una BD relacional.
Mediante la replicacion Master-Slave las escrituras son enviadas a un unico servidor, el maestro, que sincroniza su estado a uno o varios esclavos.
Mongo se puede configurar para soportar lecturas en esclavos o no.
Si el maestro se cae, un esclavo es promocionado como máster automáticamente.
El propósito de la replicación es mejorar la robustez, para mejorar el rendimiento se puede combinar con sharding.

Replica Set
Todos los writes van a un nodo primario (master) pero es posible leer de los nodos secundario (slave),
Al leer de un nodo esclavo no hay garantía de que el dato leído este actualizado.
Si solo se lee y escribe del máster si se garantiza la consistencia.
En el periodo entre la caída de un nodo primaria y el establecimiento de un nuevo maestro la consistencia esta comprometida. Todo nodo tiene un nivel de prioridad, para el proceso de elección. Si el nivel puesto es 0, no podrá ser maestro.
Existen 4 tipos de nodos para configurar un Replica Set.
- Regular: Puede votar y puede convertirse en maestro, el mas comun.
- Arbiter: Puede votar pero no puede convertirse en maestro. Se puede usar para asegurar un mínimo numero de nodos en el set.
- Delayed: Puede votar pero no puede convertirse en maestro. Suele usarse como un nodo de recuperación, los datos suelen estar atrasados por un par de horas.
- Hidden: Usados para analíticas en el replica set, no pueden votar ni ser maestros.
Se puede encontrar documentación y un listado de metodos para replicación desde las siguientes URL:
Sharding
MongoDB soporta auto-sharding una técnica de escalabilidad horizontal que separa datos a través de varios servidores.

Se puede encontrar mas informacion sobre el sharding en la documentacion de MongoDB:
El modus operandi de sharding consiste en dividir una colección en varios nodos y acceder después a sus contenidos a través de un nodo especial que actúa como router (mongos).
Es necesario que cada colección declare un shard-key. Esta clave se define para uno o varios campos de un documento y se usa para dividir la coleccion en fragmentos que serán distribuidos entre los nodos lo mas equitativamente posible.
La instancia mongos usa esta clave para determinar el fragmento, y por consiguiente el nodo.
Documentacion "Convert a Replica Set to a Replicated Sharded Cluster":
http://docs.mongodb.org/manual/tutorial/convert-replica-set-to-replicated-shard-cluster/
Programando MongoDB
MongoDB tiene soporte variado de lenguajes y librerias cliente. Podemos encontrar una lista de drivers para diversos entornos en el siguiente enlace:
http://docs.mongodb.org/ecosystem/drivers/
Node.js: Server-side JavaScript
Node.js es una plataforma basada en el runtime V8 de JavaScript que permite usar este lenguaje en la parte servidora.
Muchos somos probablemente familiares con este lenguaje ya que lo habremos usado para dar interactividad a paginas web. Dado que el shell de mongo es en esencia un interprete de JavaScript y almacena objetos en JSON puede ser una buena plataforma para comenzar con mongo.
Full-Stack JavaScript
Todos los navegadores tratan de incorporar las últimas capacidades de HTML5 a su repertorio.
La combinacion HTML5 + JavaScript tanto en el cliente como en el servidor se esta convirtiendo en una de las plataformas de aplicaciones web.
Este tipo de plataformas, conocidas como Full-Stack JavaScript, suelen promover el desarrollo ágil para lo que casi siempre usan MongoDB para su base de datos.

Mean.io
MEAN (MongoDB, Express, Angular, Node.js) es una plataforma fullstack javascript para aplicaciones web modernas.
- MongoDB es la BD NoSQL lider, ayudando a negocios a ser mas agiles y escalables.
- Express es un framework para el desarrollo de aplicaciones web minimalista y flexible, basado en Node.js.
- AngularJS es un framework para clientes web que permite extender el vocabulario de HTML con nuevas y potentes funciones.
- Node.js es una plataforma con construida sobre el runtime de JavaScript de Chrome para desarrolar facilmente aplicaciones red rapidas y escalables.

MongoDB y Node.js
MongoDB dispone de un driver oficial para Node.js que puede instalarse fácilmente usando el gestor de paquetes de Node, NPM.
npm install mongodb
El soporte de Node.js para MongoDB aparece detallado en la siguiente URL:
// Retrieve
var MongoClient = require('mongodb').MongoClient;
// Connect to the db
MongoClient.connect("mongodb://localhost:27017/exampleDb",
function(err, db) {
if(err) { return console.dir(err); }
var collection = db.collection('test');
var docs = [{mykey:1}, {mykey:2}, {mykey:3}];
collection.insert(docs, {w:1}, function(err, result) {
collection.find().toArray(function(err, items) {});
var stream = collection.find({mykey:{$ne:2}}).stream();
stream.on("data", function(item) {});
stream.on("end", function() {});
collection.findOne({mykey:1}, function(err, item) {});
});
});
Mongoose
Mongo ofrece un modelo de datos dinámico y ademas transfiere responsabilidades, como la de realizar transacciones complejas a la capa de aplicación.
Debido a esto, nos conviene usar herramientas que nos faciliten la programación cuando usamos MongoDB como base de datos.
Mongoose es una libreria para Node que permite modelar y manejar datos de una aplicación que use MongoDB. Esto reduce los errores que los programadores puedan crear, ademas de acelerar y facilitar el desarrollo de aplicaciones.
Mongoose nos ayuda con la validacion, el modelado y la logica de negocio.
Instalacion:
npm install mongoose
La documentacion oficial de Mongoose se puede encontrar en
Abrir una conexion
var mongoose = require('mongoose');
mongoose.connect('mongodb://localhost/test');
var db = mongoose.connection;
db.on('error', console.error.bind(console, 'connection error:'));
db.once('open', function callback () {
// BD abierta
}); Modelado de datos
En mongoose todo esta basado en un Schema.
Los schemas se corresponden a una coleccion en la base de datos. Definen que atributos contendran los documentos de la coleccion.
Ademas, se pueden definir atributos virtuales, metodos de validacion y metodos a ejecutar antes y despues de cada operacion.
Atributos
Los atributos de un Schema se definen mediante un objeto de JavaScript, una serie de pares nombre/valor.
var blogSchema = new Schema({
title: String,
author: String,
body: String,
comments: [{ body: String, date: Date }],
date: { type: Date, default: Date.now },
hidden: Boolean,
meta: {
votes: Number,
favs: Number
}
}); El nombre de cada atributo sera su nombre en los documentos, mientras que el valor sera su tipo.
Tipos de datos
Los siguientes son los tipos básicos que ofrece Mongoose
- String
- Number
- Date
- Buffer
- Boolean
Mixed
Un atributo del tipo Mixed puede contener cualquier cosa, incluido objetos de JavaScript. Esto permite incluir documentos dentro de documentos, entre otras cosas. Es el campo mas flexible.
Arrays
Los arrays en mongoose pueden especificarse sin un tipo concreto o con un tipo de Mongoose.
ObjectId
Los ObjectId son un campo especial de mongoose que se usa para almacenar referencias a otros documentos.
Aqui se guardan las relaciones existentes en la base de datos.
Operaciones con Mongoose
La operaciones de Mongoose se acceden desde los modelos que definamos para la aplicación. Para esto hay que compilar los esquemas a modelos:
var schema = new mongoose.Schema({ name: 'string', size: 'string' });
var Tank = mongoose.model('Tank', schema); Tank.find(function(err, tanks){
if(err) return err;
console.log(tanks);
});
La operacion de Mongoose populate es lo mas parecido a una JOIN que podemos encontrar para esta BD. Usando esta funcion, el ODM sustituira las referencias a otros documentos (campos ObjectId) por los documentos en si.
Blog.find().populate('author').exec(function(err, blogs){ if(err) return err;console.log(blogs); });
Extendiendo los esquemas
Los esquemas de Mongoose se pueden enriquecer con atributos virtuales, validaciones y middleware.
Validaciones
Existen validaciones predefinidas, como el máximo y mínimo de los números pero si estos no son suficientes, como es habitual, se pueden definir funciones de validación propias.
var Toy = mongoose.model('Toy', toySchema); Toy.schema.path('color').validate(function (value) { return /blue|green|white|red|orange|periwinkle/i.test(value); }, 'Invalid color');var toy = new Toy({ color: 'grease'});toy.save(function (err) {console.log(err.errors.color.message);});
Virtuals
Los virtuals son propiedades del documento que se pueden consultar y modificar pero que realmente no existen en la base de datos.
personSchema.virtual('name.full').get(function () { return this.name.first + ' ' + this.name.last; });var Person = mongoose.model('Person', personSchema);var bad = new Person({ name: { first: 'Walter', last: 'White' } });console.log('%s is insane', bad.name.full); // Walter White is insane
Para modificar los virtual se pueden definit setters para estos atributos.
personSchema.virtual('name.full').set(function (name) {
var split = name.split(' ');
this.name.first = split[0];
this.name.last = split[1];
});
...
mad.name.full = 'Breaking Bad';
console.log(mad.name.first); // Breaking
console.log(mad.name.last); Middleware
El middleware es una serie de funciones que se ejecutan durante los metodos init, validate, save y remove de un documento. Hay dos tipos de middleware pre y post que se llaman antes y despues de las operaciones, respectivamente.
Se puede definir middleware en serie o paralelo.
var schema = new Schema(..);
schema.pre('save', true, function (next, done) {
// calling next kicks off the next middleware in parallel
next();
doAsync(done);
}); Casos de uso de middleware
- Validaciones complejas
- Eliminar documentos dependientes
- Valores por defecto asincronos
- Notificaciones
Conclusiones
MongoDB es una buena opción para reemplazas las bases de datos relaciones tradicionales en nuevas aplicaciones, o para optimizar las ya existentes.
Las BBDD NoSQL son una clara alternativa a los RDBMS sobretodo en aplicaciones web y sociales que requieren una alta escalabilidad.
Pero NoSQL no es la panacea.
NoSQL propone usar la herramienta adecuada para tarea, no sustituir RDBMS con NoSQL. La mayoría de datos existentes son muy estructurados y deberían seguir viendo las RDBMS como primera opción.
La capacidad de hacer JOINs y las garantías ACID son muy importantes para muchas aplicaciones.
Cada herramienta es adecuada para un problema.
Aimar Rodríguez Soto
aimar.rodriguez.s@gmail.com
Copy of MongoDB
By yhoan andres galeano urrea




