Extracting & Printing
NAPLAN Writing Test Data
with NIAS
NIAS
A suite of tools designed to
provide help when working with NAPLAN Results Reporting Dataset.
Distributed as a single zip file containing binary executables for Windows, Mac & Linux.
-
NAPVAL
- Validates student registration information, coverts between xml and csv formats
-
NAPCOMP
- Compares results and registration data to highlight differences in student information
-
NAPRRQL
- Analytics and reporting engine for the results reporting dataset
-
NAP-WRITING-PRINT
- Creates html renderings of student writing responses for automated marking
all NIAS tools follow a common layout:
- /InstallationFolder
- /NiasTool
- /in - place files to be processed here
- /out - results of processing will be written here
- /NiasTool
throughout this presentation we will show files being copied via the command line between locations - there is no requirement to move files in this way, it is just as effective to copy and paste files using a file browser such as Finder on the Mac or Explorer on Windows
To extract & print writing responses:
>cd /nias-1-0-2/naprrql
nias-1-0-2/naprrql> ./naprrql --ingest
> cp /rrd-download-folder/jurisdiction-rrd.zip /nias-1-0-2/naprrql/incopy the RRD file to the /in folder of the naprrql tool:
navigate to the naprrql folder and launch naprrql with the --ingest flag to read the RRD datafile:
step 1, extract RRD data into nias
naprrql --ingest
2018/04/21 14:30:18 invoking data ingest...
2018/04/21 14:30:18 DB not initialised. Opening...
2018/04/21 14:30:18 Reading data file [in/Sample RRD.xml.zip]
2018/04/21 14:30:18 Data file read complete...
2018/04/21 14:30:18 Total tests: 19
2018/04/21 14:30:18 Total codeframes: 19
2018/04/21 14:30:18 Total testlets: 149
2018/04/21 14:30:18 Total test items: 1425
2018/04/21 14:30:18 Total test score summaries: 23
2018/04/21 14:30:18 Total events: 99
2018/04/21 14:30:18 Total responses: 75
2018/04/21 14:30:18 Total schools: 2
2018/04/21 14:30:18 Total students: 21
2018/04/21 14:30:18 ingestion complete for [in/Sample RRD.xml.zip]
2018/04/21 14:30:18 Compacting datastore...
2018/04/21 14:30:18 Datastore compaction completed.
2018/04/21 14:30:18 Closing datastore...
2018/04/21 14:30:18 Datastore closed.
ingests RRD files for analysis & reporting
Typical ingest response shows summary stats for ingested file, 30k student file should ingest in around 3 minutes:
step 2, extract writing responses using nias
nias-1-0-2/naprrql> ./naprrql --writingextract
stay at the same command prompt and launch naprrql this time with the --writingextract flag
this will invoke the query/reporting engine of nias, which will run 2 pre-defined data extract reports specifically created to work with writing responses, here's a typical output (for a 30k student file around 2 mins):
2018/04/21 14:51:05 DB not initialised. Opening...
2018/04/21 14:51:05 generating Writing item extract reports...
⇛ http server started on :1329
2018/04/21 14:51:05 QA Schools Summary report file writing... ./out/writing_extract/qaSchools.csv
2018/04/21 14:51:05 Writing extract file writing... ./out/writing_extract/writing_extract.csv
2018/04/21 14:51:05 Writing item extract reports generated...
2018/04/21 14:51:05 Closing datastore...
2018/04/21 14:51:05 Datastore closed.naprrql --writingextract
$ ls -l ./out/writing_extract/
total 272
-rw-r--r-- 1 534 21 Apr 14:51 qaSchools.csv
-rw-r--r-- 1 72158 21 Apr 14:51 writing_extract.csvperforms necessary joins across objects in datastore (see later slides) and outputs 2 report files to the
naprrql/out/writing_extract folder:
writing_extract.csv is the manifest file containing all of the information that will be printed, and which allows qa and reconciliation checks.
It is also the input file for the writing response printing tool.
qaSchools.csv is a summary report of all registered testing activity for each school in the RRD to provide context and cross-checking information
writing_extract.csv
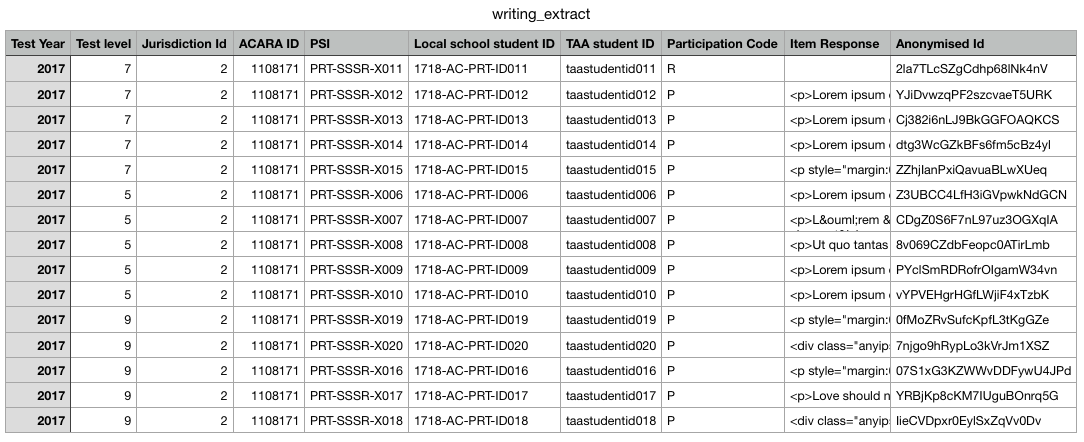
10 fields, allows reconciliation between anonymised id created by nias and platform (PSI) and local (TAA Id, Local School Id) for each writing record.
The HTML fragment created by the user is captured in the 'Item Response' field.
nias-1-0-2/naprrql>cd ../nap-writing-print
nias-1-0-2/nap-writing-print>./nap-writing-print
nias-1-0-2/naprrql > cp ./out/writing_extract/writing_extract.csv ../nap-writing-print/in
copy the writing_extract.csv file from the naprrql/out/writing_extract folder to the ./in folder of the nap-writing-print tool:
navigate to the nap-writing-print folder and launch the
nap-writing-print tool (it has no command-line options):
step 3, use nap-writing-print to create html files
nap-writing-print will use any .csv files it finds in the /in folder, you can have multiple files from different runs of naprrql, and you can rename the files to whatever you like as long as you keep the .csv extension.
nap-writing-print
/nap-writing-print $ ./nap-writing-print
2018/04/21 15:53:48 starting html writer...
2018/04/21 15:53:54 backup of input files created...
2018/04/21 15:53:54 ...all html files written.creates standard html output files in the nap-writing-print/out folder (see later slides for details of structures and file content) typical output when run is:
(output shown is for 5k student input file, which generates 20k output files)
The backup of input files is a precaution that creates a timestamped folder containing the last .csv file used to generate the html records. This means that in the future the same output of html files can always be recreated by using the relevant saved input file. Backup folders can be renamed to any helpful name e.g. /vic-gov-final
nap-writing-print output folder structure
├── in
└── out
├── schools
│ └── 1108171
│ ├── audit
│ └── script
└── yr-level
├── 5
│ ├── audit
│ └── script
├── 7
│ ├── audit
│ └── script
└── 9
├── audit
└── scriptoutput is organised in 2 folder structures:
- one with writing results by school (where schools are identified by their ACARA (ASL) IDs
- one where writing results are collected by year-level of students who took the writing test in all schools
nap-writing-print output folder structure
├── 5
│ ├── audit
│ │ ├── 2_P_0bl9Mx1Bl0j85TaNiuEaYD_audit.html
│ │ ├── 2_P_VmSt4ymRwsAL2HZFvZ2NGE_audit.html
│ │ ├── 2_P_Y7wC4Bw3mxJ3mmkViCKRte_audit.html
│ │ ├── 2_P_lpDiCaJmd4BXs9D3vaweCr_audit.html
│ │ └── 2_P_tm3RUXIfsi3wwNuRlCz6VB_audit.html
│ └── script
│ ├── 2_P_0bl9Mx1Bl0j85TaNiuEaYD_script.html
│ ├── 2_P_VmSt4ymRwsAL2HZFvZ2NGE_script.html
│ ├── 2_P_Y7wC4Bw3mxJ3mmkViCKRte_script.html
│ ├── 2_P_lpDiCaJmd4BXs9D3vaweCr_script.html
│ └── 2_P_tm3RUXIfsi3wwNuRlCz6VB_script.htmlwithin each folder (school or year-level), there are always 2 further folders:
- script: has the rendered html writing responses
- audit: the meta-data associated with the writing response
nap-writing-print output filenames
├── 5
│ ├── audit
│ │ ├── 2_P_0bl9Mx1Bl0j85TaNiuEaYD_audit.html
│ └── script
│ ├── 2_P_0bl9Mx1Bl0j85TaNiuEaYD_script.html
filenames are created as follows:
2_P_0bl9Mx1Bl0j85TaNiuEaYD_audit.html
State Identifier
2_P_0bl9Mx1Bl0j85TaNiuEaYD_audit.html
Participation Code of student, allows filtering of scripts for marking, but means a 1:1 reconciliation with students in RRD is possible
2_P_0bl9Mx1Bl0j85TaNiuEaYD_audit.html
the random identifier assigned to this script by nias
2_P_0bl9Mx1Bl0j85TaNiuEaYD_audit.html
suffix indicate a script or an audit file, both files refer to the same writing response record
nap-writing-print output notes
├── 5
│ ├── audit
│ │ ├── 2_P_0bl9Mx1Bl0j85TaNiuEaYD_audit.html
│ └── script
│ ├── 2_P_0bl9Mx1Bl0j85TaNiuEaYD_script.html
Audit and script files are placed in separate folders to allow for separated distribution with no risk of student meta-data being visible to anyone receiving a script file.
The naming convention means that audit and script files can be recombined in a single folder and will always appear next to one another in the correct sequence.
The main reason we separate by folder, though, is for safety on 32-bit Windows.
5k user records would result in 20k html files being written, if this is not split across multiple folders it will be too many files for a single folder under Win32.
nap-writing-print output samples, scripts:


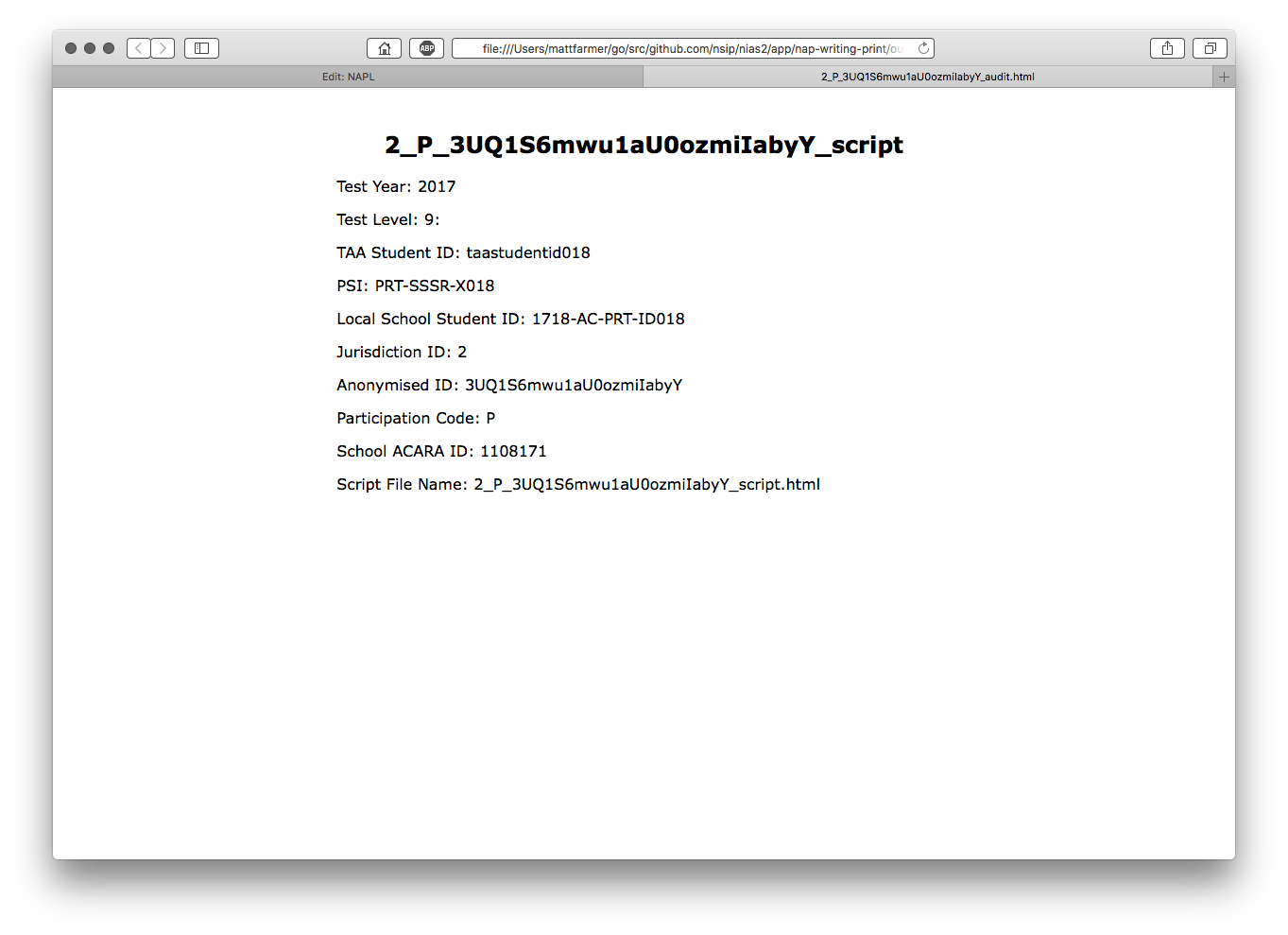
nap-writing-print output samples, audit:
what happens in this process....
Results Reporting Dataset
(RRD)
- Large zipped xml file
- Contains all student test information for all years
- Contains registration data, testing data and results data
- Also contains school-level data such as aggregate domain scores
- Conceptual structure is...
we start with an output from the NAPLAN online platform...
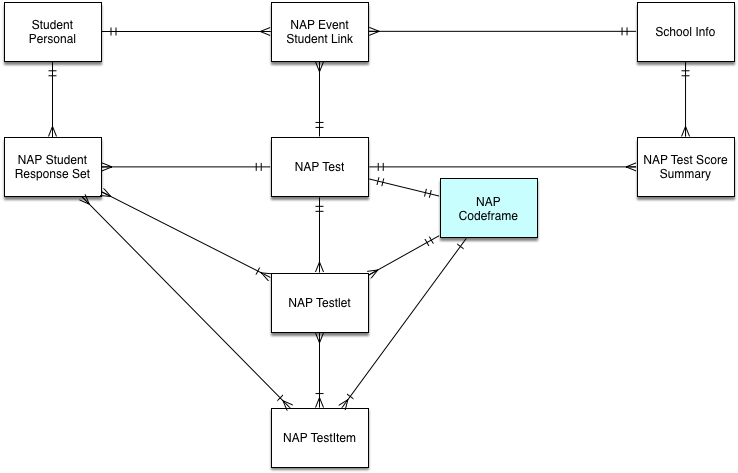
The internal structure of the results file is a series of linked entities (a graph) rather than a series of records...
To get to the minimum data set for extracting writing tests, we need to traverse the connections between these objects.
when you run naprrql it traverses these links and creates the writing extract report file from the RRD data.
once you have a writing extract file it can be processed by
nap-wrtiting-print to produce standardised html files that represent the student's writing responses:
within the writing extract file (and within the RRD) only a fragment of html has been captured from the online environment
<p>Love should not be wasted. People think that love is endless ,
but the reality is that love does have constraints. Be careful who you love ,
and how much energy you expend on it.
If you love the wrong person ,
and the love is not recripcated ,
then oppurtunites will be missed. </p>this fragment does not contain enough html structure at this point to render correctly in a browser nor to enforce the same display standards as the original online editor.
to resolve this as part of nap-writing-print creating the html files it injects the necessary html scaffolding and styling directives to ensure that the 'printed' output exactly matches the user's original input
<html>
<head>
<style>
p,
li,
h2 {
font-family: Verdana, Arial, sans-serif;
}
.response-body {
width: 600px;
margin-top: 25px;
margin-bottom: 30px;
margin-left: auto;
margin-right: auto;
}
</style>
</head>
<body>
<div class="response-body"><h2 style="text-align: center;">2_P_mdSbBKgMBj6dTPOfWELHEi_script</h2><p>Love should not be wasted. People think that love is endless , but the reality is that love does have constraints. Be careful who you love , and how much energy you expend on it. If you love the wrong person , and the love is not recripcated , then oppurtunites will be missed. </p><h2 style="text-align: center;">2_P_mdSbBKgMBj6dTPOfWELHEi_script</h2>
</div>
</body>
</html>
we add
A 'header' and 'footer' of the full filename of the script file.
Large margins so that the printed output is like the narrow editor in which the user created their original text.
All text displayed in the script resembles the online input as closely as it can, specifically:
- Only the Verdana font is used
- Only 16 and 18 px text sizes are supported
- Underlned text is displayed
- Bold text is displayed
- Italic text is displayed
- Paragraph breaks and spacing are maintained
- Centring of text is maintained
- Bullet lists are maintained
- Numbered lists are maintained
we ensure
have the same bold header of the script file-name to allow meta-data and script to be reconciled manually if necessary, all of the fields from the writing extract report are printed:
audit files
downloads available from:
https://github.com/nsip/nias2/releases/latest
includes full help manual
questions or help
ww.nsip.edu.au
info@nsip.edu.au
NAPLAN Writing Extract with NIAS
By matt_farmer



