Santander NEOs Challenge
March 14, 2016

Santander Group
The Santander Group is the largest bank in the Eurozone with a market capitalization of €65,792M [4Q’15].
Europe
82.4%
America
17.1%
Rest of the world
0.5%
[1]
[1]
[1] Quarterly Shareholder Report October - December 2015
Worldwide presence:
Methodology

Task 1:Business Problem
- Which customers will become inactive by March 2015?
Data
Process
Output
Active Customers
1.8M
Active Customers
1.7M
Inactive Customers
99K
Data from:
October 2012 to
December 2014.
62M+ Records
Data contains:
Customer Activities
Based on historical data, we want to identify inactive customers (99K)
Define active/inactive
Data Preprocessing
Predictive Analytics
Data Mining
Model Evaluation
Visualization
Task 1:Data Understanding/Preparation
Active Customers
1.8M
62M+ Records
Data contains:
Customer Activities
-
Performs at least 3 transaction with the account in the last 90 day
-
Have an average volume in the last 6 months >= pre-determine amount
Data
- A client is considered active if the client:
Task 1:Data Mining
Process
Feature Selection
163 variables
- Difficult to directly select attributes
- Manually identified certain fields that are not useful
- Weight by Information Gain operator which calculates the weight of attributes
- Selecting attributes
- Balance in the second package checking account
- Number of products a customer has
- CRM ID of the customer income segment (A , B, C, D,S)
- Total balance of the ATM transactions made by the customer
- Total number of ATM transactions made by the customer Identifies
- Top Attributes
Task 1:Data Modeling
Model
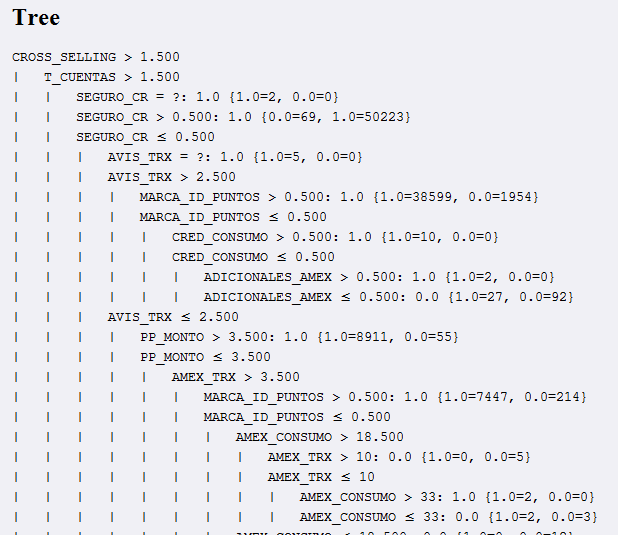
Model Selection
TP – Predicted as inactive and are truly inactive
TN – Predicted as active and are truly active
FP – Predicted as inactive and are truly active
FN – Predicted as active and are truly inactive
Precision rate - TP / (TP + FP)
Recall rate - TP / (TP + FN)
Task 1:Model Evaluation
Model
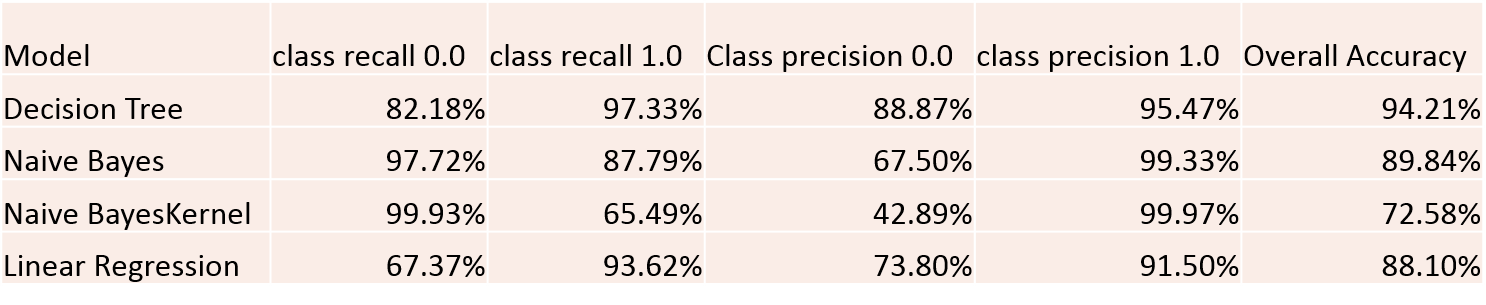
Two models Decision Tree and Naïve Bayes are selected based on the class recall and class precision.
Model Selection
Task 1:Results
- The model scored 97885 as inactive.
- Remaining 1159 IDs are picked from the IDs scored as 1 but with a low confidence.
Decision tree is used for scoring Dec 2014 active customers (N0)
Output
Inactive Customers
99K
Task 1:Challenges
- Memory crunch to process massive data of 62 million records.
- Takes lot of time to perform any operations in SQL on huge database.
- Need to do roll up activities and then calculate fields
- Applying several models on huge data
Task 2: Nivel Satisfacción
Cost (Acquiring new customers) > Cost (retaining a customer)
Can we use transactional data to predict the level of satisfaction of a customer?
Dependent variable:
1. Nivel Satisfaccion ~ nominal variable with values 0,1,2.
2. Predict_binary ~ binary variable with values 0 (for 0) and 1 (for 1 and 2).
Task 2: Nivel Satisfacción
Predict the customer satisfaction level
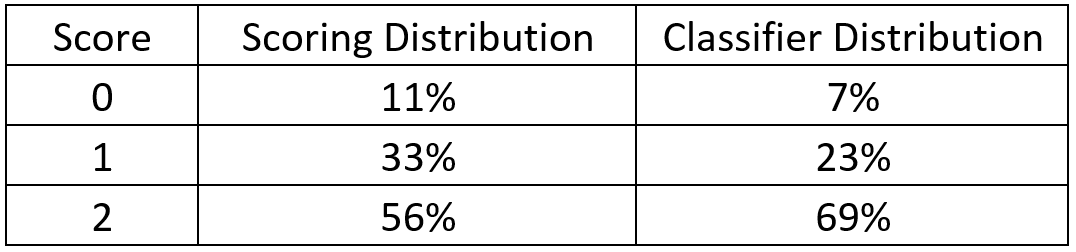
- Satisfaction data given for 30,000 customers
- Satisfaction score will have values 0, 1 or 2
- Need to score customer IDs that corresponds who were surveyed during Q1 2015
- Scoring distribution:
0's - 133 ~ 10.6%
1's - 419 ~ 33.4%
2's - 703 ~ 56%
Task 2:Data Mining
Process
Feature Selection
200+ variables
- Difficult to directly select attributes
- Weka ‘Select Attribute’ feature is used to determine 32 features
- Selecting attributes
- Top 5 Attributes

Task 2:Model Evaluation
Model
Cost sensitive-Random forest is selected based on the class recall and class precision.
Model Selection
W-simplekmeans
Cost sensitive-Random forest
K-star
Multilayer perception
Neural net
Naïve Bayes
Decision Tree
Task 2:Results
Cost sensitive-Random forest is used for scoring satisfaction for 1Q15
Output
Satisfaction Scores
0, 1 and 2
Task 2: Challenges
- Unlike task 1, in task 2 there were no good predictors of nivel_satisfaccion.
- There was no access to the actual survey or knowledge as to why certain individuals may have had several surveys administered to them.
- Certain attributes related to the satisfaction were on the training set but not in the scoring set
Next Steps
- Segment the different "personas" and create the right intervention to prevent customers from becoming inactive
- Understand the tradeoff between an accurate model vs. a model that allows you enough time to make an intervention
- Understand the tradeoff between an accurate model vs. a model that allows you enough time to make an intervention


Thank You!
Santader
By acast317



