Patience is all you need
Adam Lass
Supervised by Luca Maria Aiello
Assessing the Impact of Partial Observations
when Fine-Tuning LLMs using Reinforcement Learning
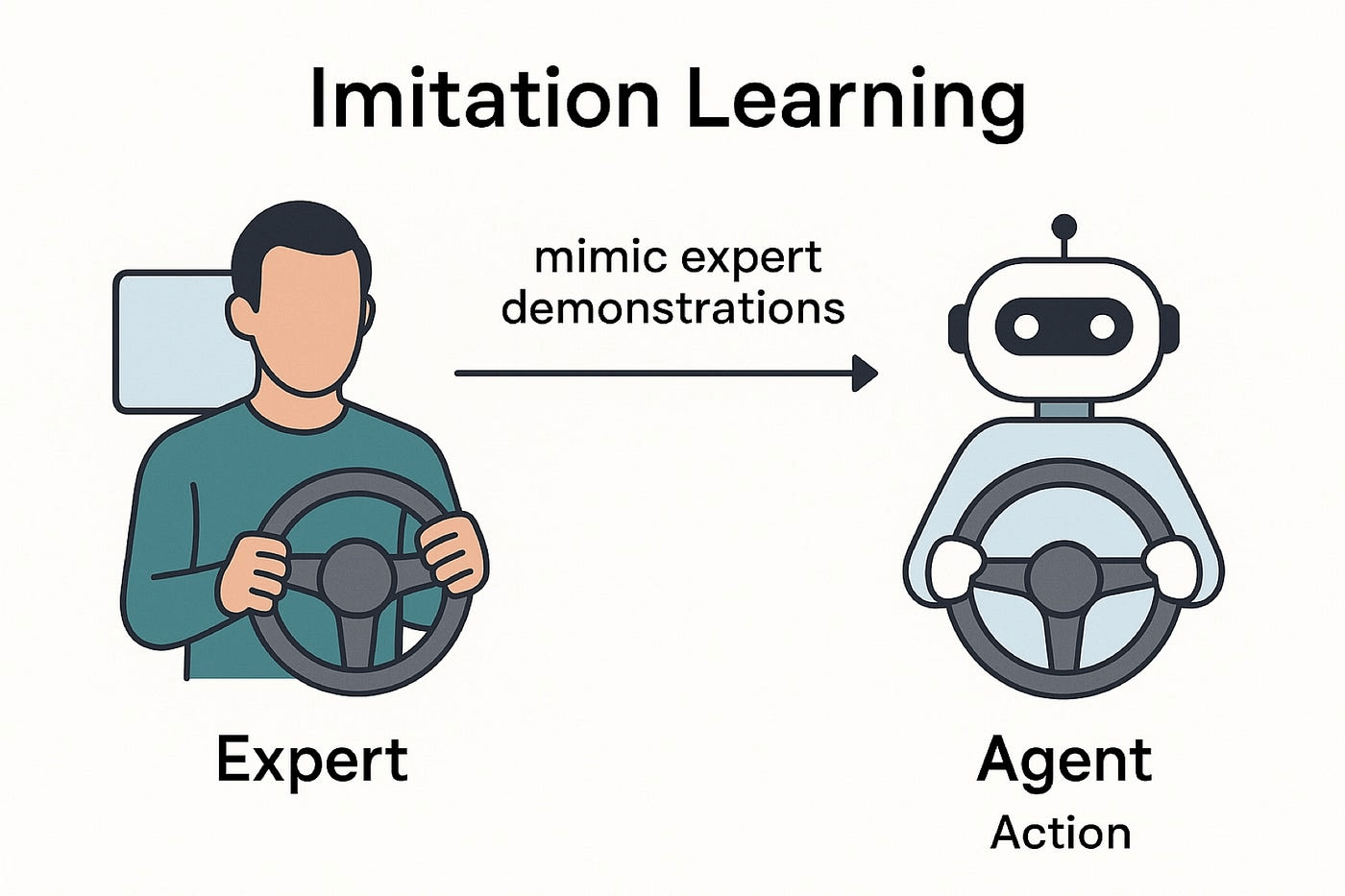
Despite the emerging capabilities of large-language models (LLMs) bringing AI into the public discourse, the technology itself often struggles to engage responsively in such conversational settings. Being primarily pre-trained to solve tasks in fully realised contexts, LLMs often have difficulty interpreting the partial observations inherent to these low-latency inference settings. While previous work has explored more efficient adaptations to address these challenges, their methods and training often rely on extensive prompt engineering and/or imitation learning, making their approaches less scalable and robust to novel settings. Meanwhile, recent reinforcement learning (RL) practices have begun to ground LLM agents in online environments successfully; however, whether this performance holds with partial observations remains unknown. We propose Hold The Line (HTL), a novel RL environment tailored to test how input fragmentation affects the performance of an LLM agent tasked to patiently navigate an Interactive Voice Response (IVR) system based on a user goal. Peaking only at 13% terminal accuracy, we discover that receiving partial observations has a significant negative impact on performance when compared to the corresponding result of 91% with full observations. Here, we discuss how several challenging factors, such as sparsity, reasoning derailment, and reward-sensitivity, might drive this gap, and suggest future directions to help mitigate them.
Despite the emerging capabilities of large-language models (LLMs) bringing AI into the public discourse, the technology itself often struggles to engage responsively in such conversational settings. Being primarily pre-trained to solve tasks in fully realised contexts, LLMs often have difficulty interpreting the partial observations inherent to these low-latency inference settings.
Despite the emerging capabilities of large-language models (LLMs) bringing AI into the public discourse, the technology itself often struggles to engage responsively in such conversational settings. Being primarily pre-trained to solve tasks in fully realised contexts, LLMs often have difficulty interpreting the partial observations inherent to these low-latency inference settings.
While previous work has explored more efficient adaptations to address these challenges, their methods and training often rely on extensive prompt engineering and/or imitation learning, making their approaches less scalable and robust to novel settings. Meanwhile, recent reinforcement learning (RL) practices have begun to ground LLM agents in online environments successfully; however, whether this performance holds with partial observations remains unknown.
Complication
Despite the emerging capabilities of large-language models (LLMs) bringing AI into the public discourse, the technology itself often struggles to engage responsively in such conversational settings. Being primarily pre-trained to solve tasks in fully realised contexts, LLMs often have difficulty interpreting the partial observations inherent to these low-latency inference settings.
While previous work has explored more efficient adaptations to address these challenges, their methods and training often rely on extensive prompt engineering and/or imitation learning, making their approaches less scalable and robust to novel settings. Meanwhile, recent reinforcement learning (RL) practices have begun to ground LLM agents in online environments successfully; however, whether this performance holds with partial observations remains unknown.
Complication
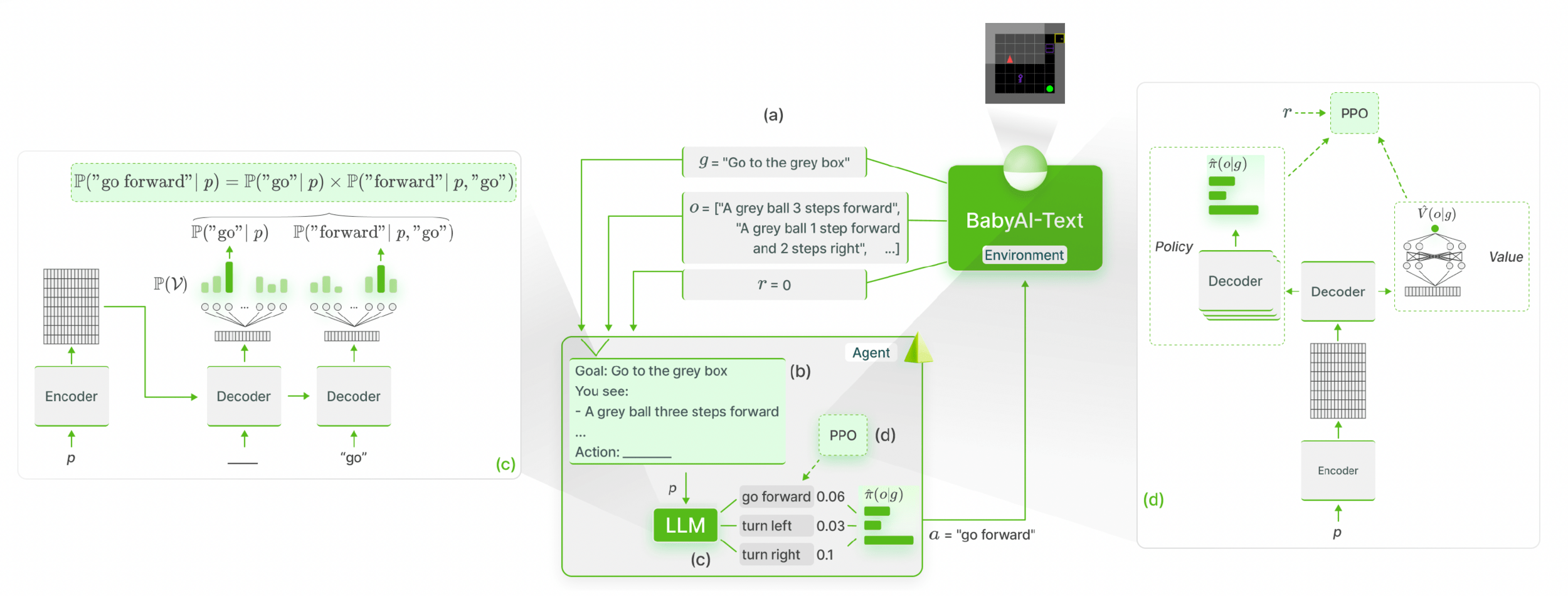
We propose Hold The Line (HTL), a novel RL environment tailored to test how input fragmentation affects the performance of an LLM agent tasked to patiently navigate an Interactive Voice Response (IVR) system based on a user goal.
Proposal
Despite the emerging capabilities of large-language models (LLMs) bringing AI into the public discourse, the technology itself often struggles to engage responsively in such conversational settings. Being primarily pre-trained to solve tasks in fully realised contexts, LLMs often have difficulty interpreting the partial observations inherent to these low-latency inference settings.
While previous work has explored more efficient adaptations to address these challenges, their methods and training often rely on extensive prompt engineering and/or imitation learning, making their approaches less scalable and robust to novel settings. Meanwhile, recent reinforcement learning (RL) practices have begun to ground LLM agents in online environments successfully; however, whether this performance holds with partial observations remains unknown.
Complication
We propose Hold The Line (HTL), a novel RL environment tailored to test how input fragmentation affects the performance of an LLM agent tasked to patiently navigate an Interactive Voice Response (IVR) system based on a user goal.
Proposal
Peaking only at 13% terminal accuracy, we discover that receiving partial observations has a significant negative impact on performance when compared to the corresponding result of 91% with full observations. Here, we discuss how several challenging factors, such as sparsity, reasoning derailment, and reward-sensitivity, might drive this gap, and suggest future directions to help mitigate them.
Contribution
- Introduction
- Related Work
- Hold The Line
- Fine-Tuning Methods
- Experiments
- Results
- Discussion
- Conclusion
- Questions
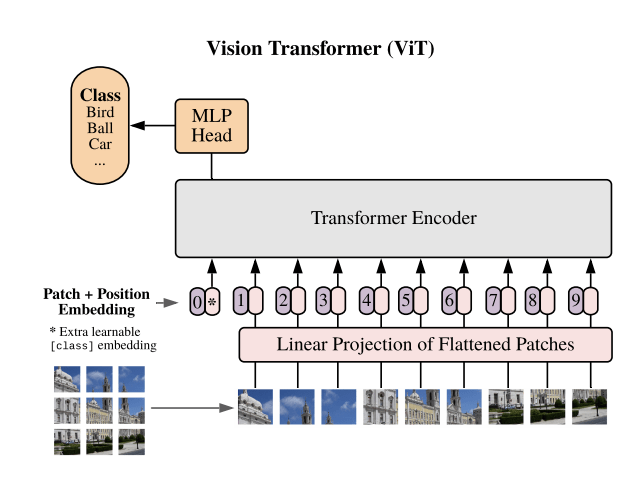





Attention
Computational Requirements
Low-latency Environments
Examples of Low-latency Environments



Implications of Low-latency Environments
High frequency inference
Input fragmentation
Implications of Low-latency Environments
High frequency inference
Input fragmentation
Embodied
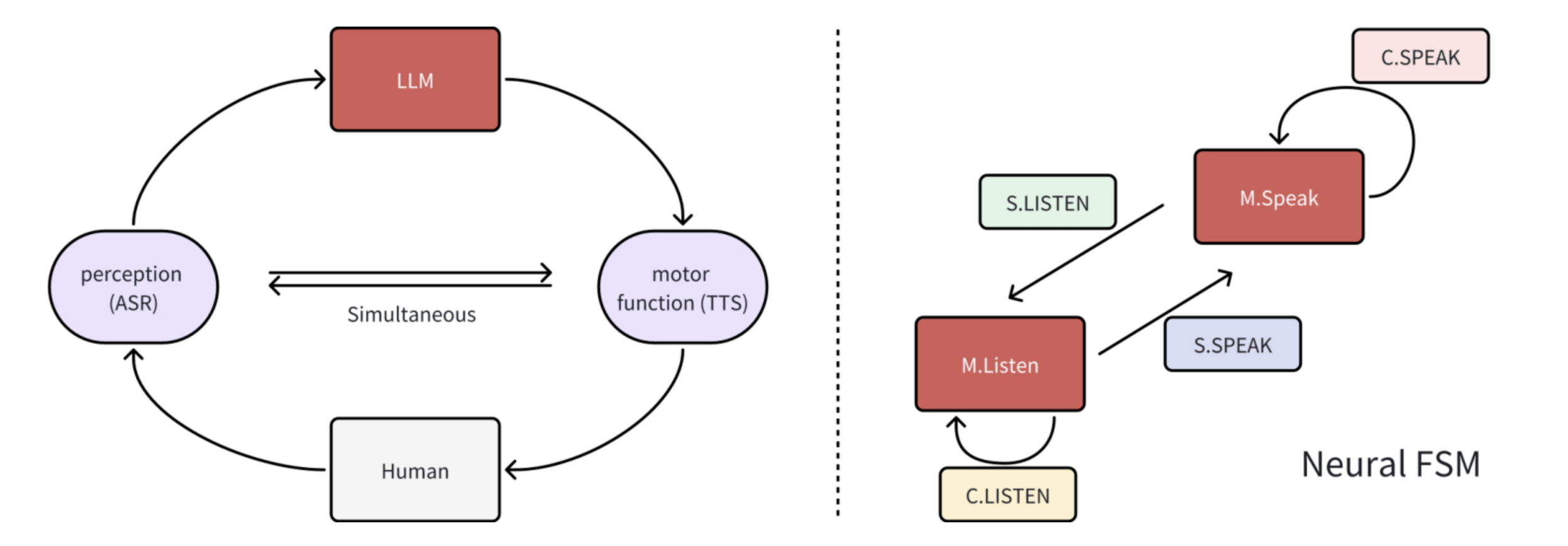
Full-duplex Dialogue
What is Full-duplex Dialogue?

What is Full-duplex Dialogue?
What is Full-duplex Dialogue?
What are partial observations exactly?
What are partial observations exactly?
Action
Full observation of object (sentence)
What are
partial observations
exactly?
Partial observations
What are
partial observations
exactly?
Action
Action
Action
Hypothesis
Full-duplex Dialogue
Evolution of Spoken Dialogue Systems
Intelligent Assistants
such as Google Assistant, Siri and Alexa
Dialogue State Tracking
Evolution of Spoken Dialogue Systems
Google Duplex
DulVRS
POI attribution acquisition by Baidu
A Full-duplex Speech Dialogue
Scheme Based On Large Language Model
Wang et al., 2024

Wang et al., 2024

Wang et al., 2024
Prompt Engineering

Wang et al., 2024
Reinforcement Learning
Proximal Policy Optimisation Algorithms
(PPO)
Schulman et al., 2017 (OpenAI)
PPO
Schulman et al., 2017

PPO
Schulman et al., 2017
Actor



Critic

+1
-1
PPO
Schulman et al., 2017
Actor
Critic
+1
-1
Advantage
Value
Reward
PPO
Schulman et al., 2017
Actor
Critic
+1
-1
Advantage
+ Advantage
Value
Reward
PPO
Schulman et al., 2017
Actor
Critic
+1
-1
Advantage
Value
- Advantage
Reward
PPO
Policy Probability Ratio
Advantage
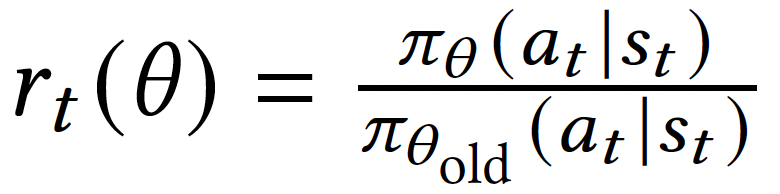
PPO
Schulman et al., 2017
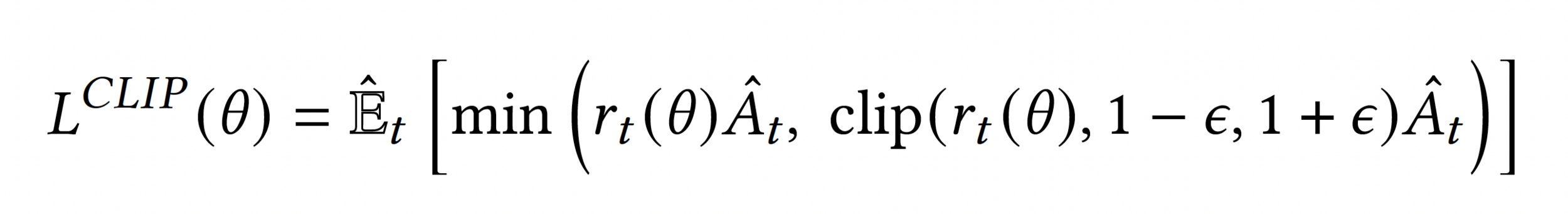
Clipped
Surrogate
Objective
Advantage Function
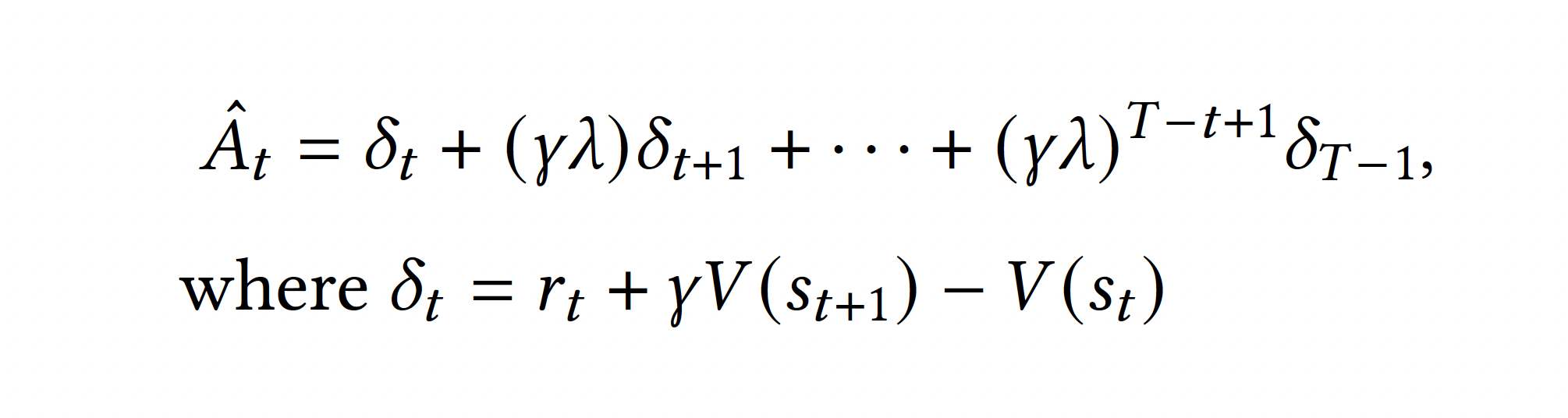
PPO
Policy Probability
Ratio
Advantage Function
Clipped Surrogate Objective
PPO
Clipped Surrogate Objective
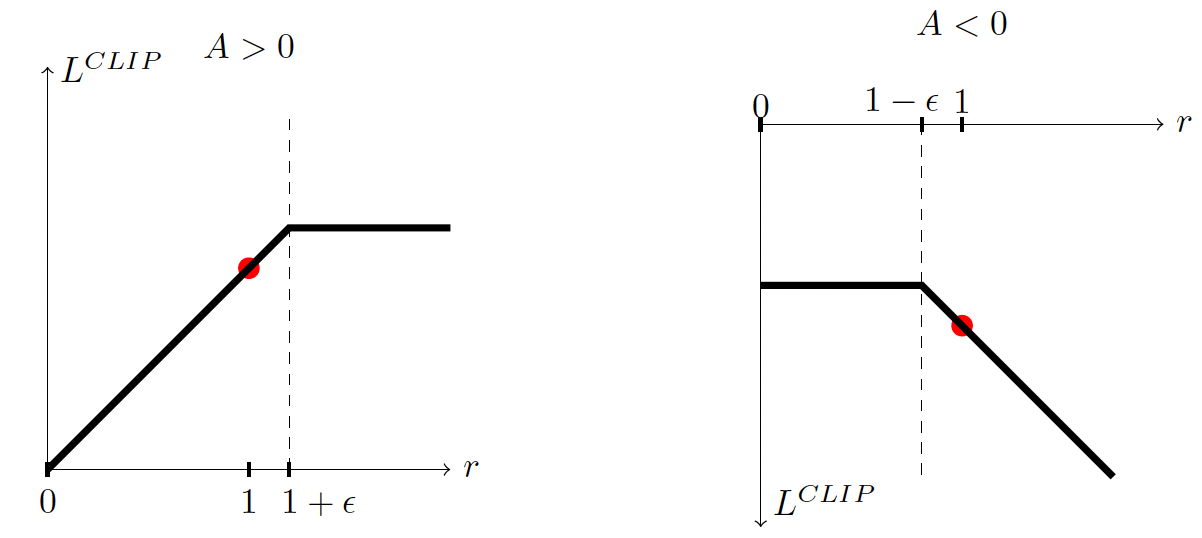
PPO
Schulman et al., 2017
Actions are
single probabilities
LLM Compatibility Problem
Grounding Large Language Models in Interactive
Environments with Online Reinforcement Learning
(GLAM)
Carta et al., 2023
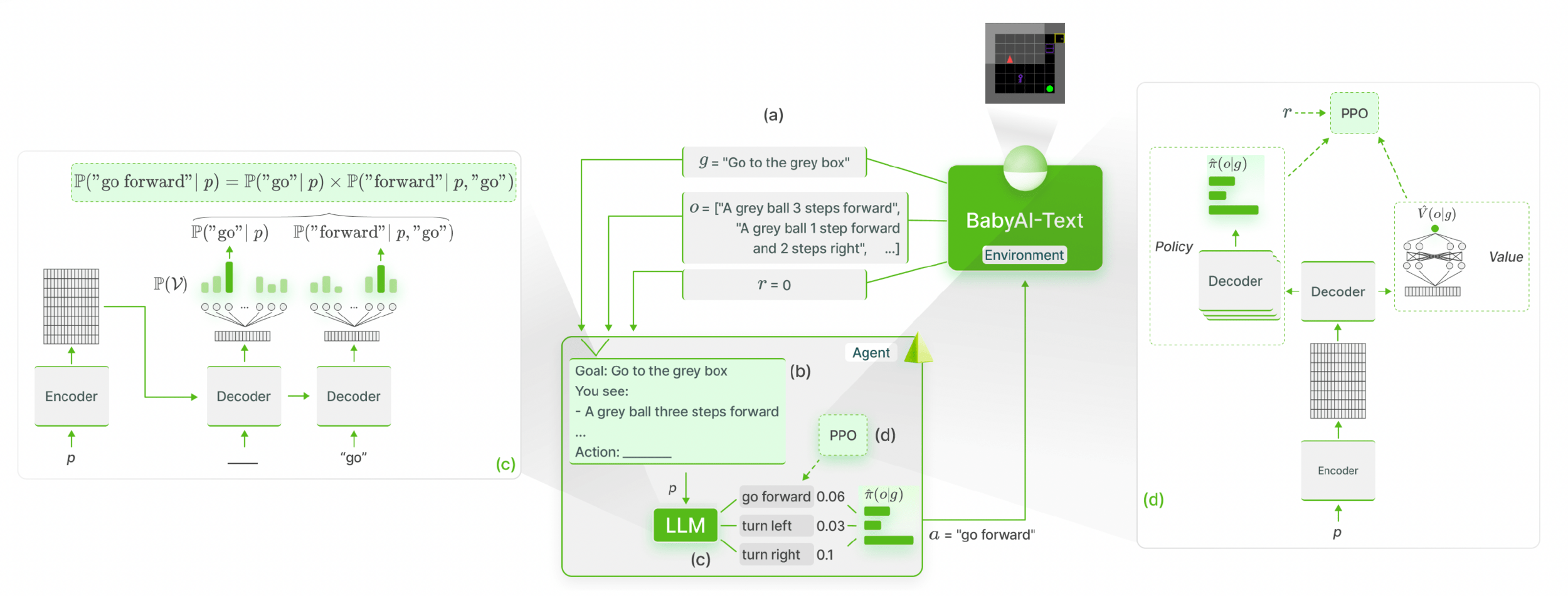
GLAM
Carta et al., 2023
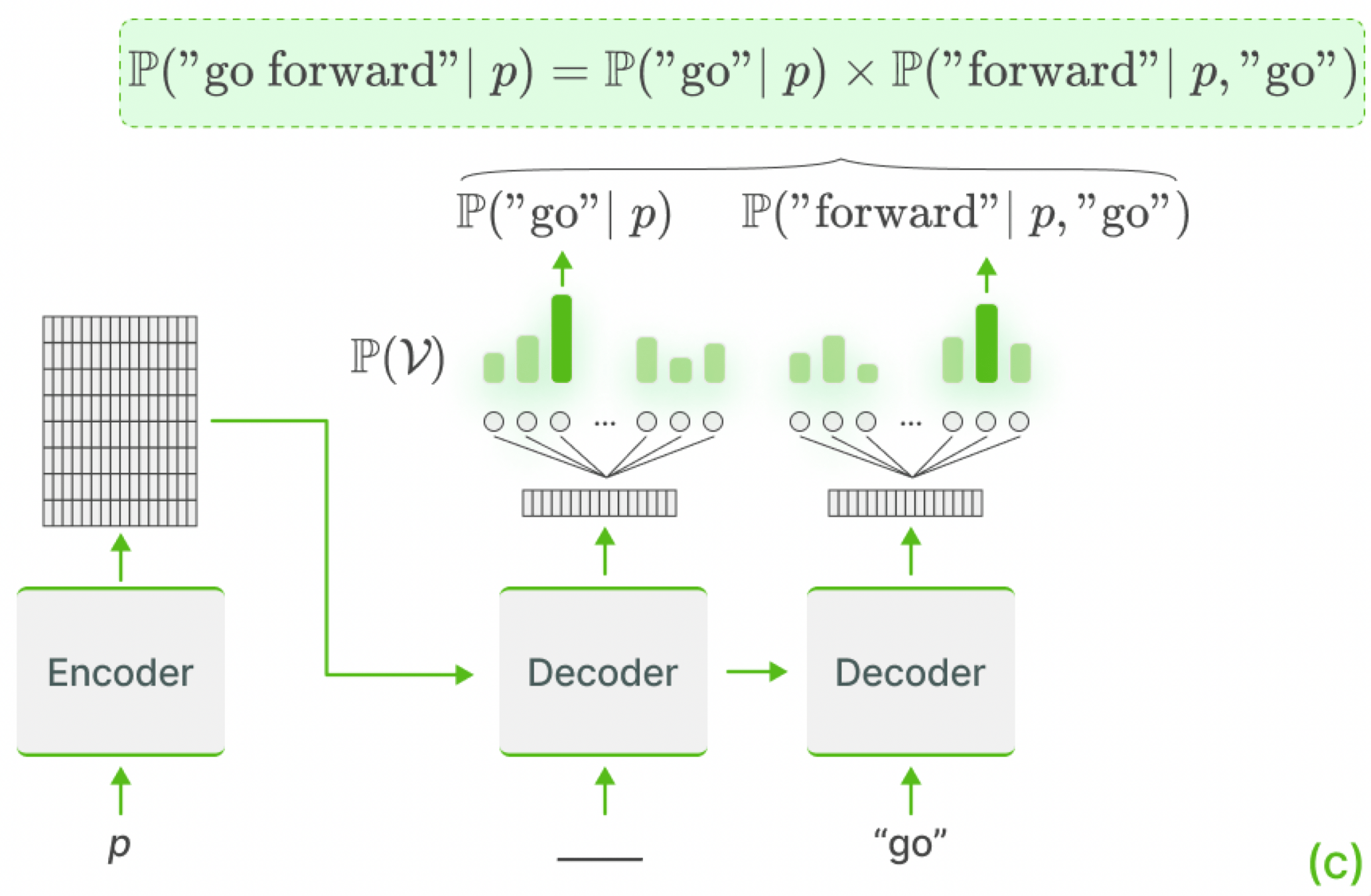
Action Probability as the Product of its Token Probabilities
GLAM
Carta et al., 2023
GLAM
Carta et al., 2023
Action Probability as the Product of its Token Probabilities
Small
Encoder-Decoder
Model
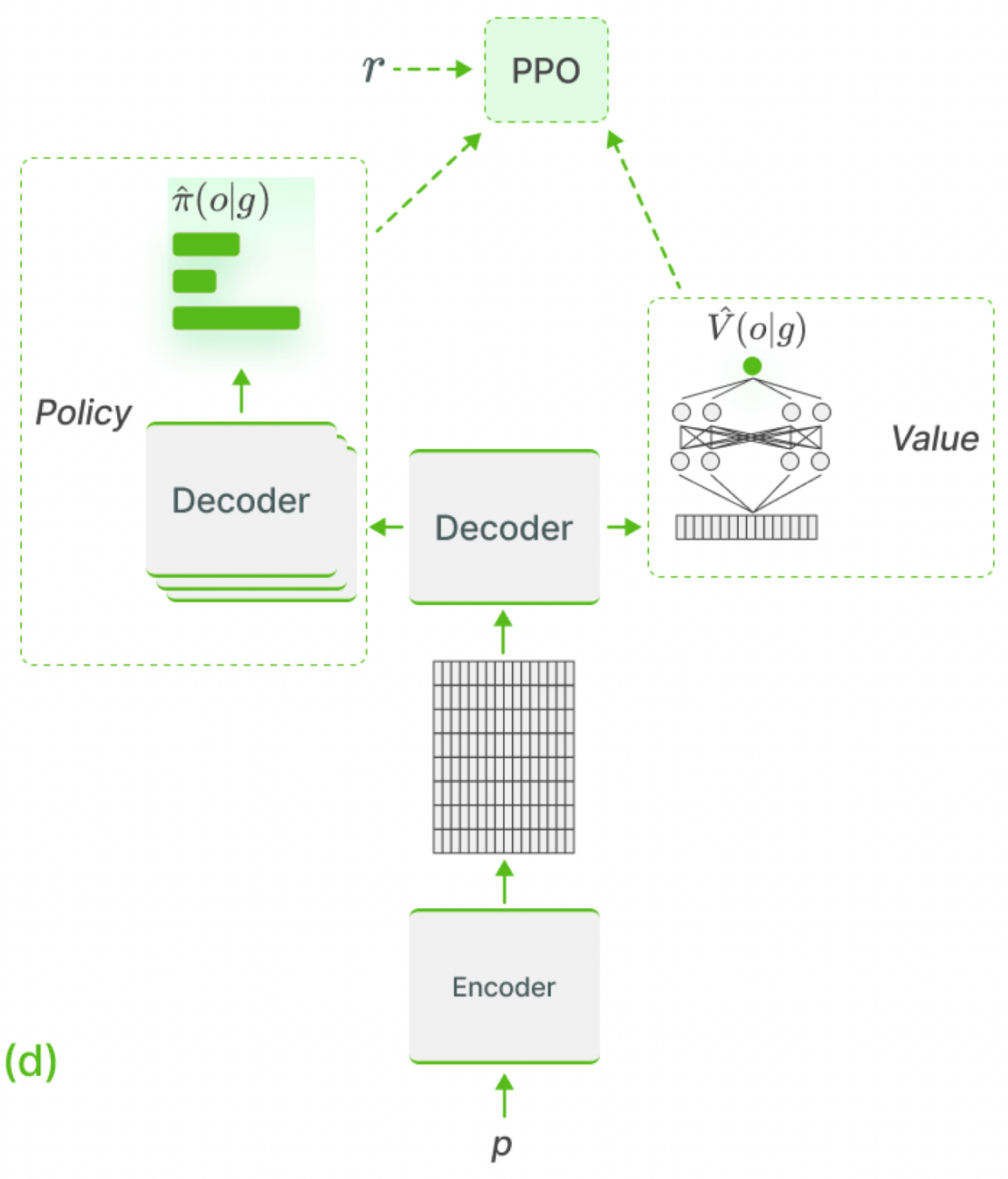
FLAN-T5 780M
Value head (Critic)
added to the Model
GLAM
Carta et al., 2023
Action Probability as the Product of its Token Probabilities
Small Encoder-
Decoder Model
Value head (Critic)
added to the Model
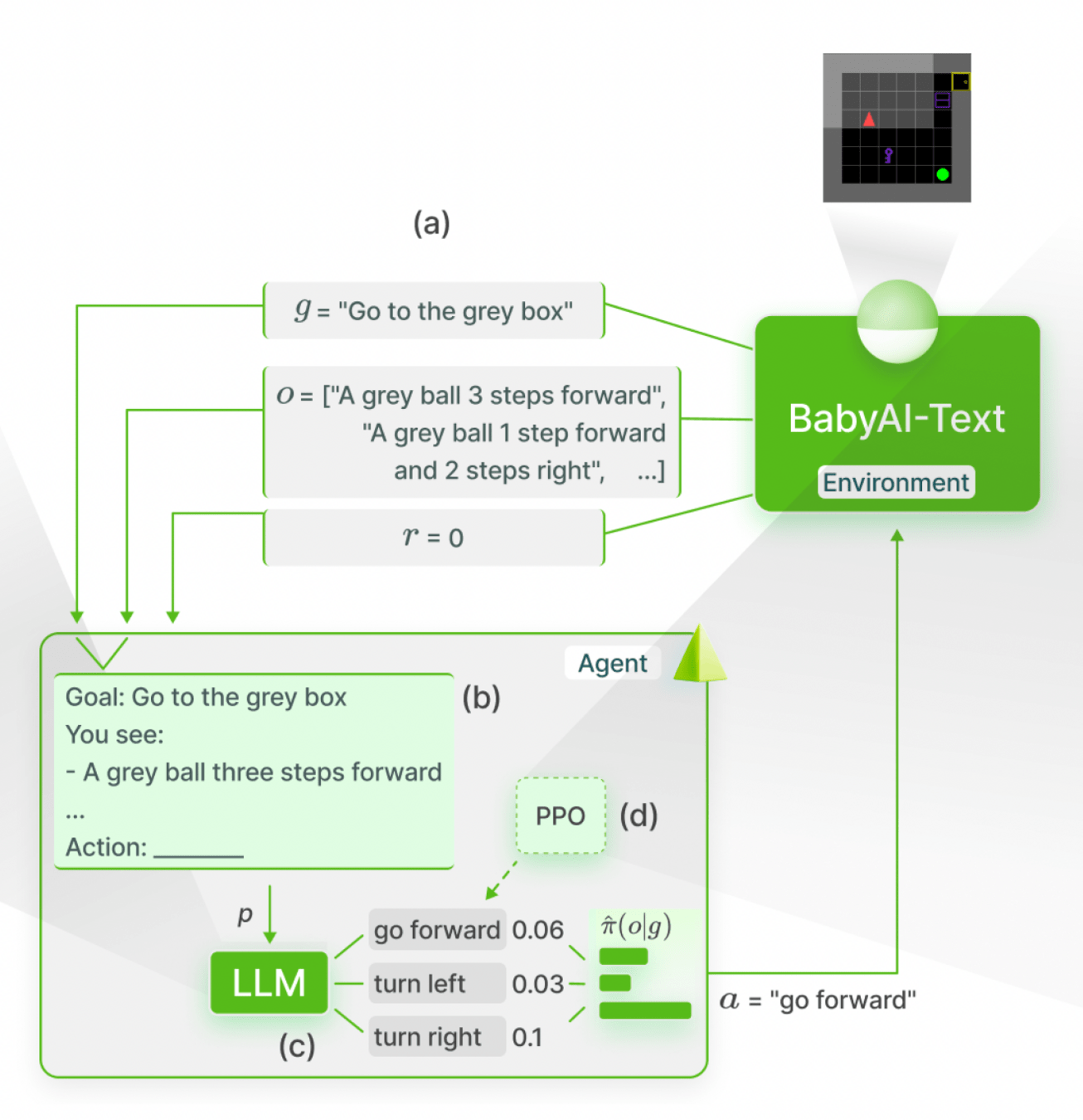
Minimalistic
System Prompt
GLAM
Carta et al., 2023
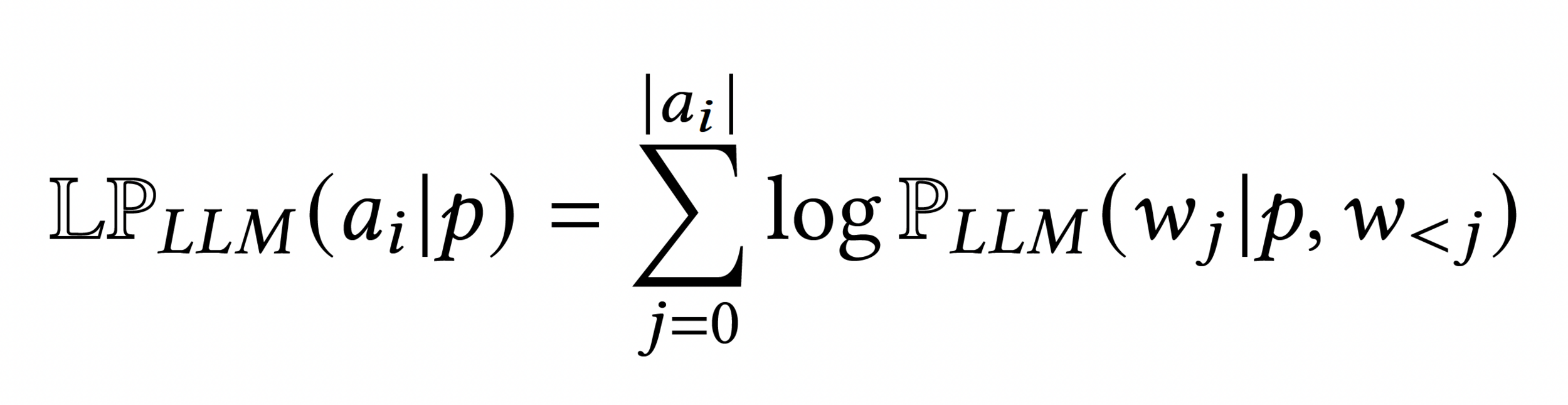
GLAM
Carta et al., 2023
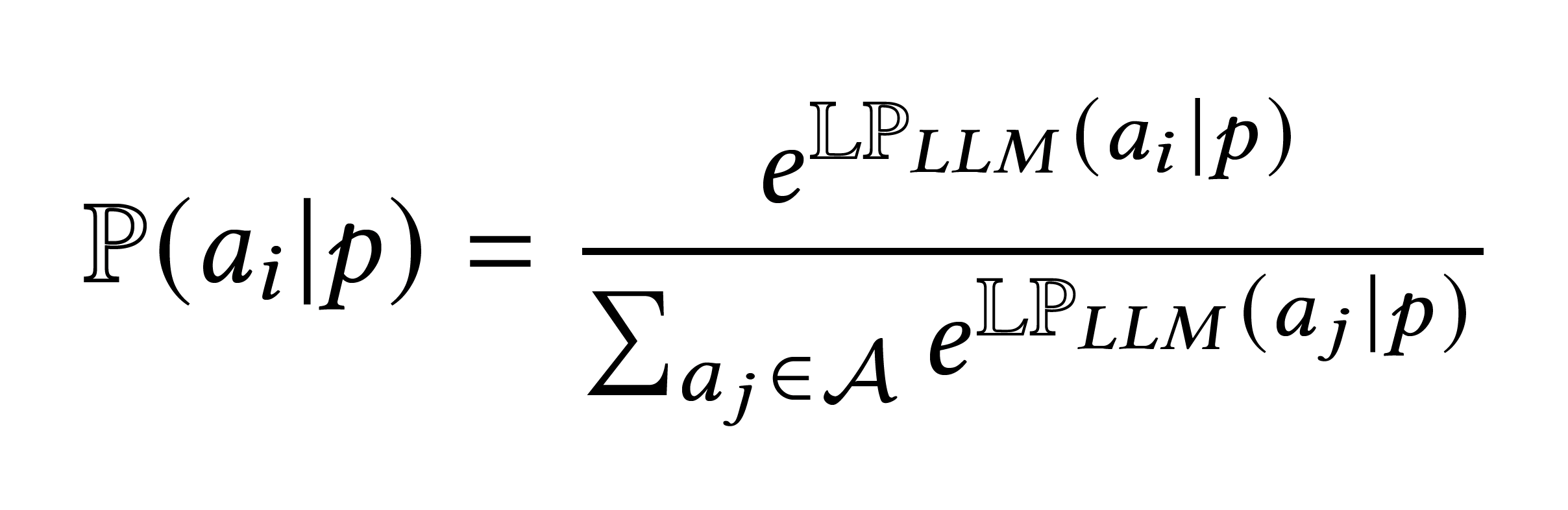
GLAM
Carta et al., 2023
TRUE KNOWLEDGE COMES FROM PRACTICE:
ALIGNING LLMS WITH EMBODIED ENVIRONMENTS
VIA REINFORCEMENT LEARNING
(TWOSOME)
Tan et al., 2024
TWOSOME
Tan et al., 2024
Token & Word
Normalisation
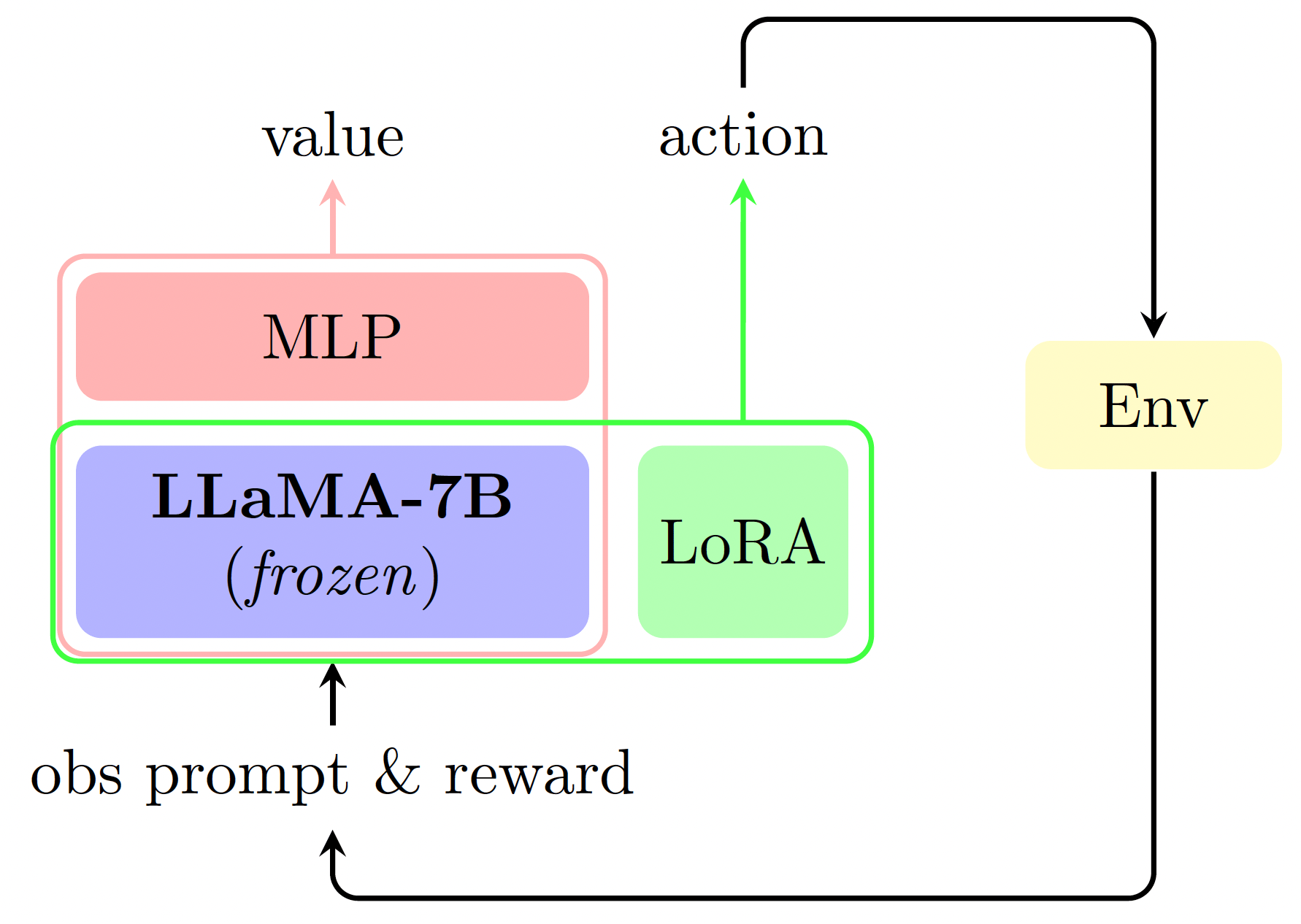
Decoder only model
LoRA
Adapter
TWOSOME
Full Duplex Dialogue
RL using LLMs
GLAM
BAD/POAD
Wang et al.
LSLM
SyncLM
Moshi
SALMONN-omni
TWOSOME
Full Duplex Dialogue
RL using LLMs
GLAM
BAD/POAD
Wang et al.
LSLM
SyncLM
Moshi
SALMONN-omni
Full Duplex Dialogue
RL using LLMs
Low latency
Partial Observations
Full Observations
Turn based
Imitation Learning
RL in embodied
Environments
Full Duplex Dialogue
RL using LLMs
Low latency
Partial Observations
Full Observations
Turn based
Imitation Learning
RL in embodied
Environments
The Gap
Research Question
How do partial observations impact the fine-tuning of LLMs when using reinforcement learning?
"
"
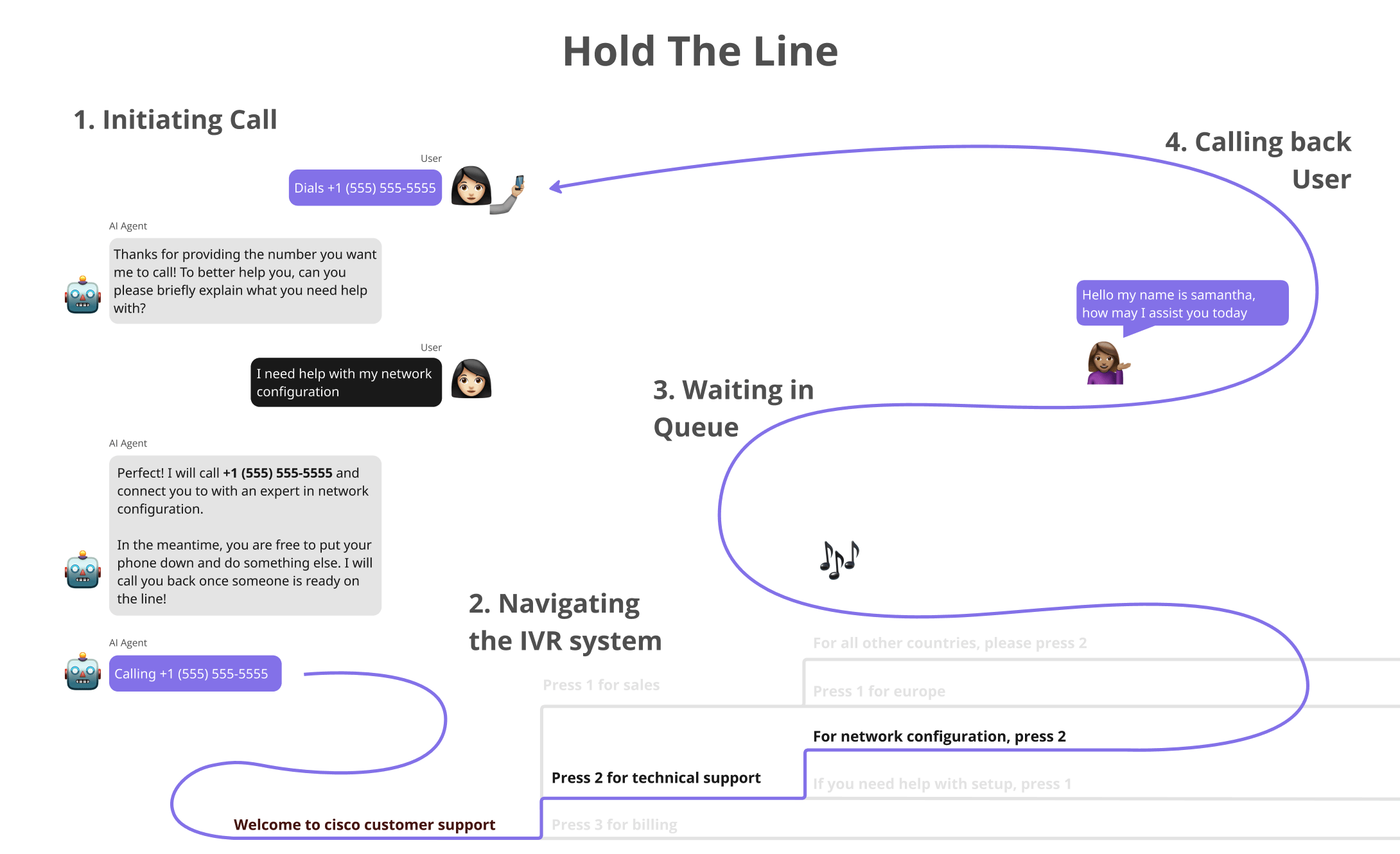
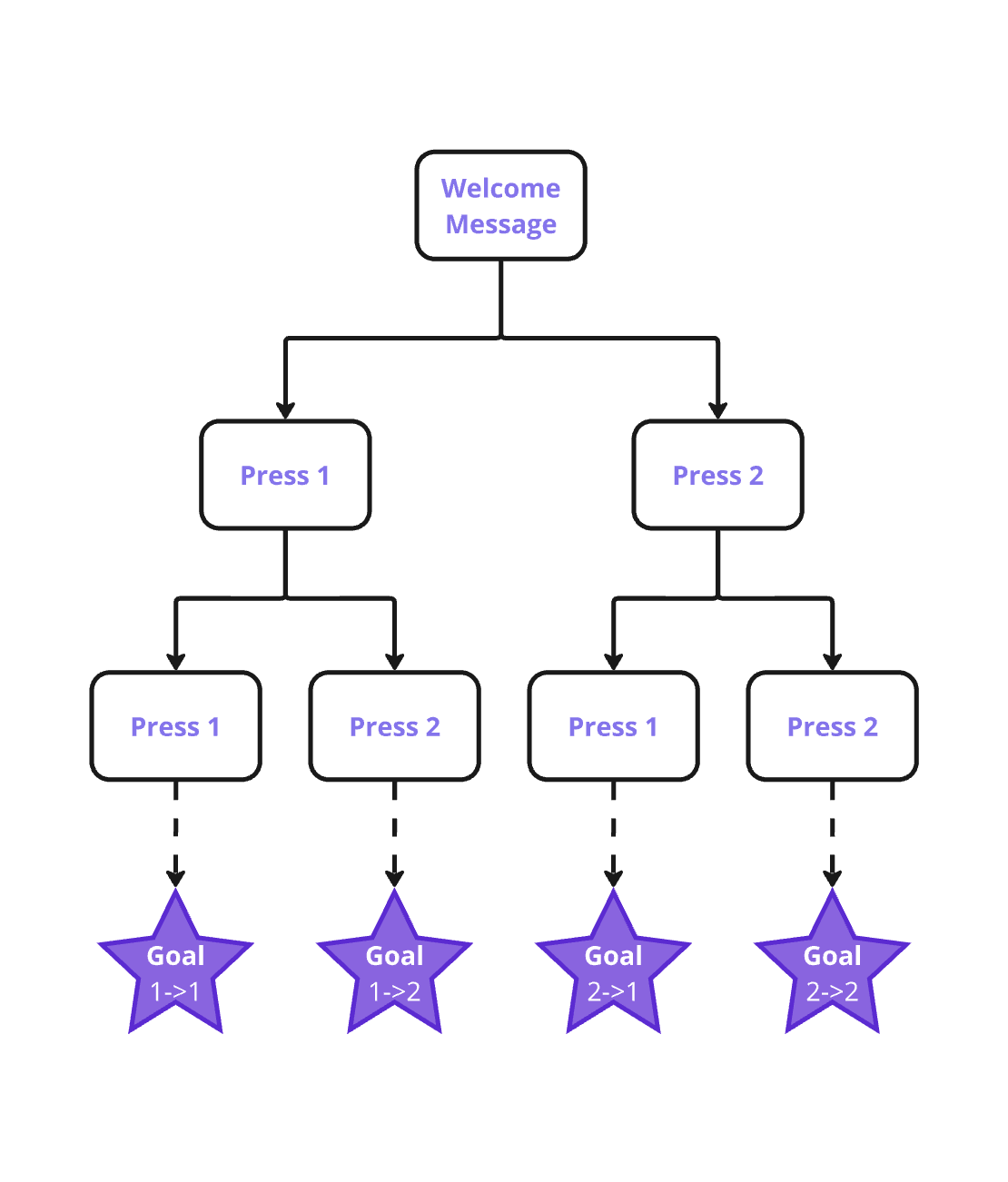
Scope
Data Generation
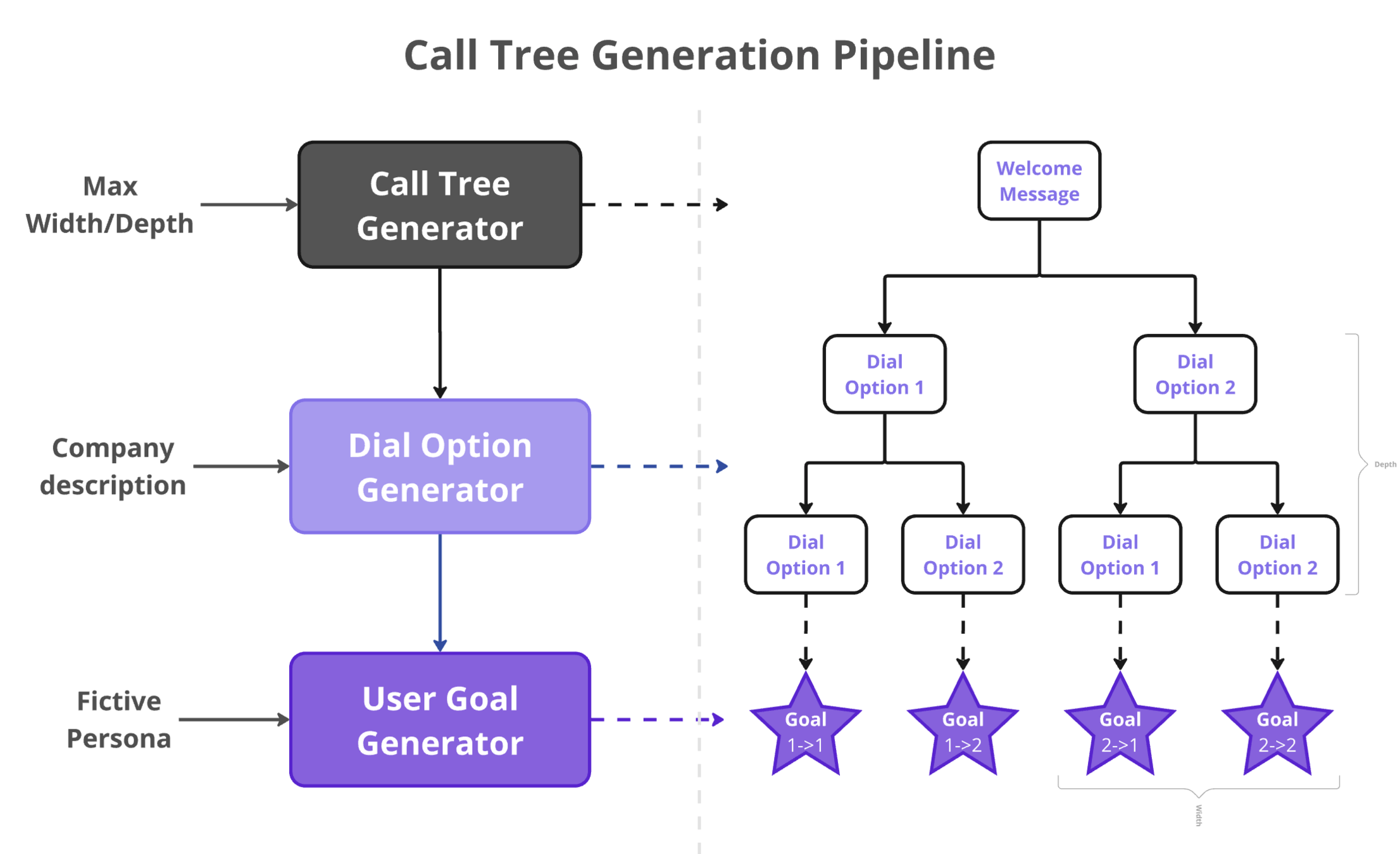
o4-mini
o4-mini
Simulation Design
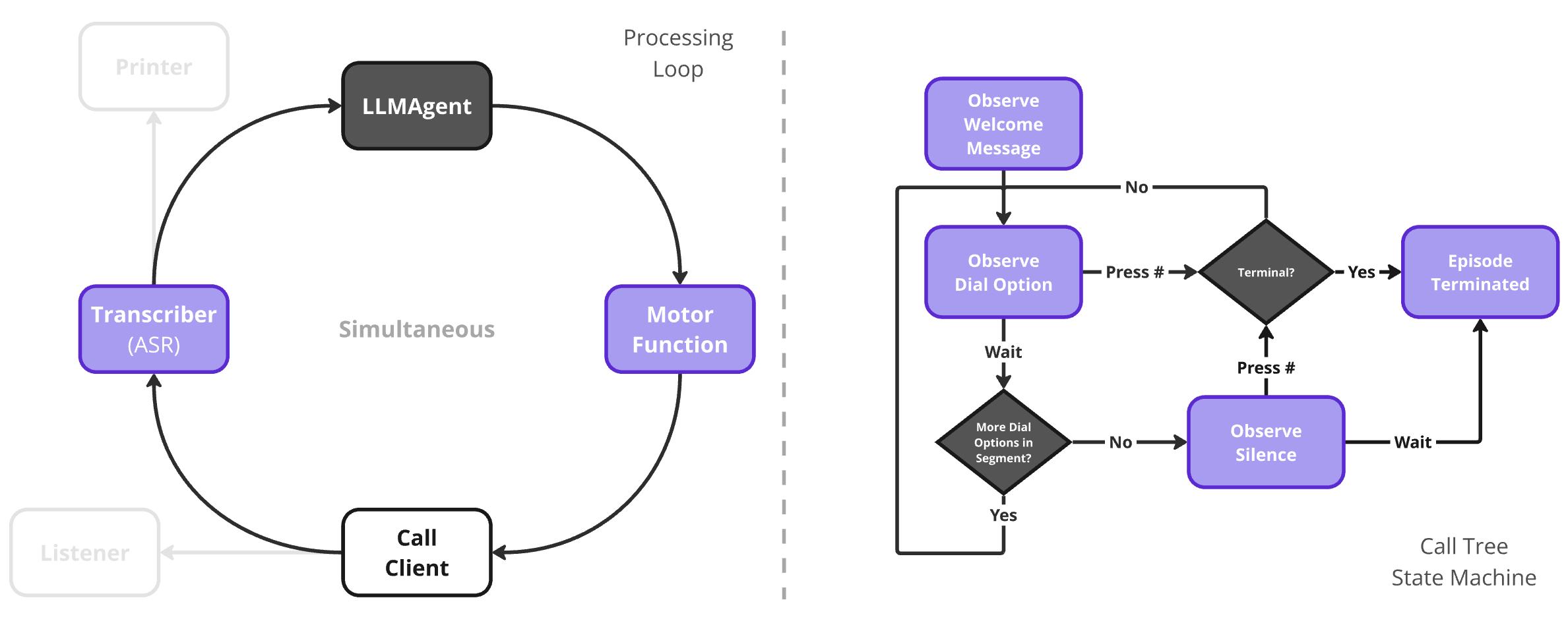
Fine-Tuning Methods
TWOSOME
GLAM
Fine-Tuning Methods
TWOSOME
GLAM
Equal-length
Action Space
Integrated
Value head (Critic)
Minimalistic
System Prompt
Decoder only model
LoRA
Adapter
Advantage
Normalisation
Methodological Advancements
Memory Optimisations
Key-Value
Caching
Chat
Completion
Optimised Action Sampling
Transceiver Pattern
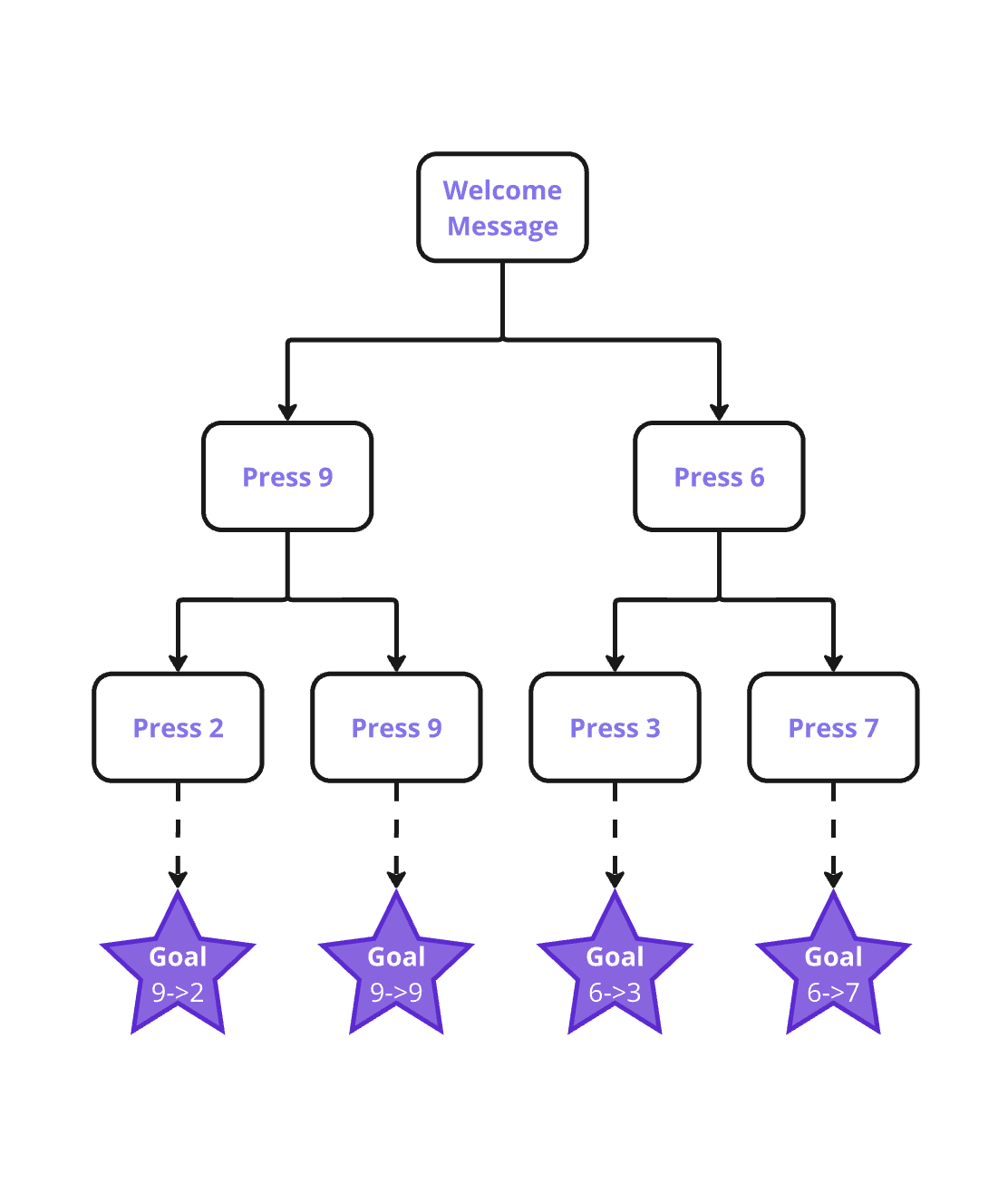
Randomising Dial Numbers
Randomising Dial Numbers
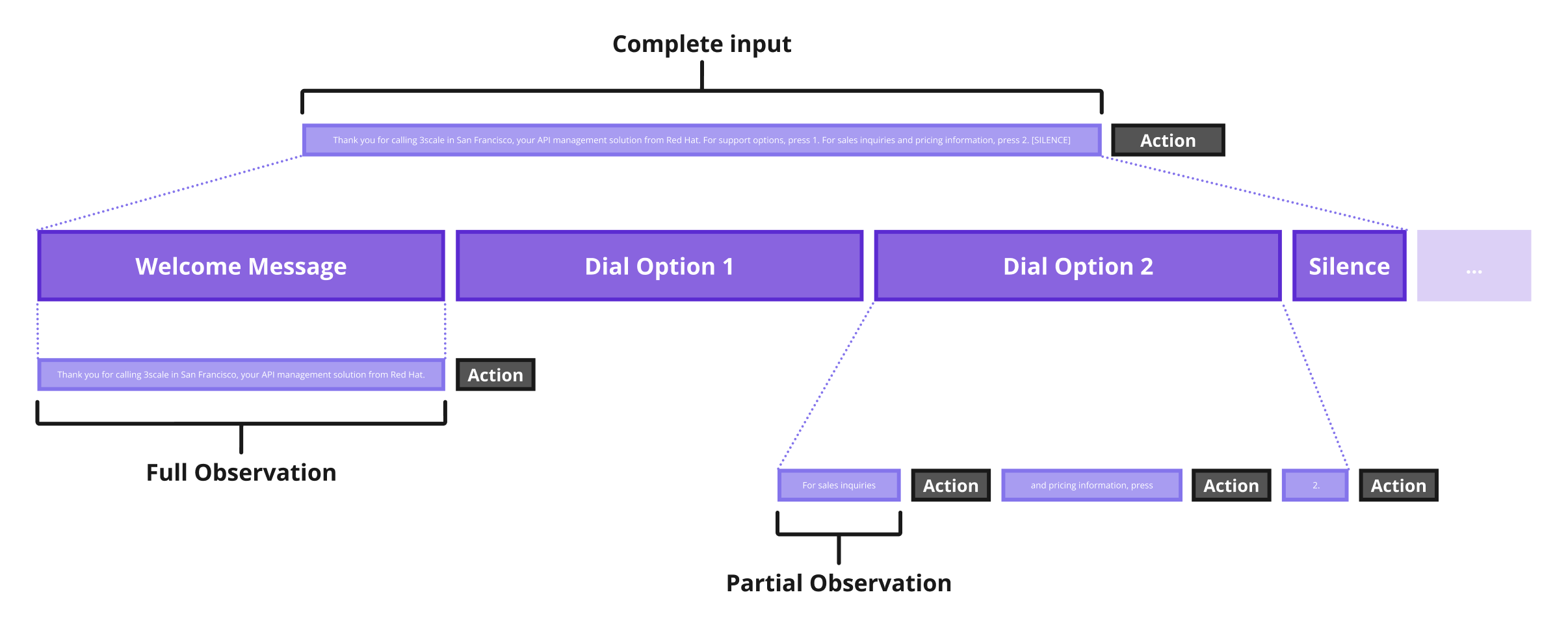
Complete Input
84% Initial Terminal Accuracy
Correctly Guessing between 9 Dial Options
2 consecutive times:
(1/9)^2 = 1.2% Terminal Accuracy
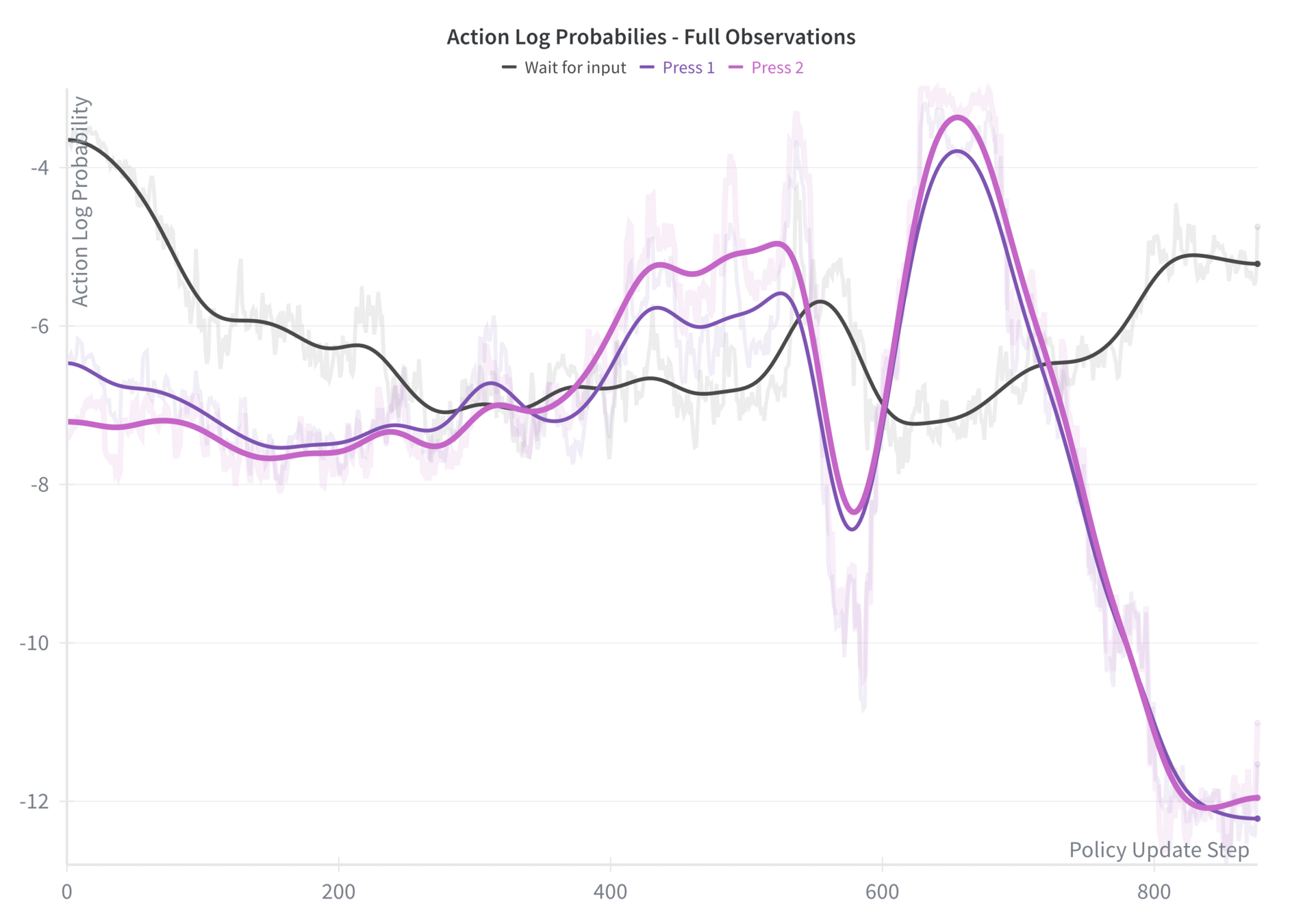
Full Observations
Full Observations
50% Initial
Terminal Accuracy
91% Peak
Terminal Accuracy
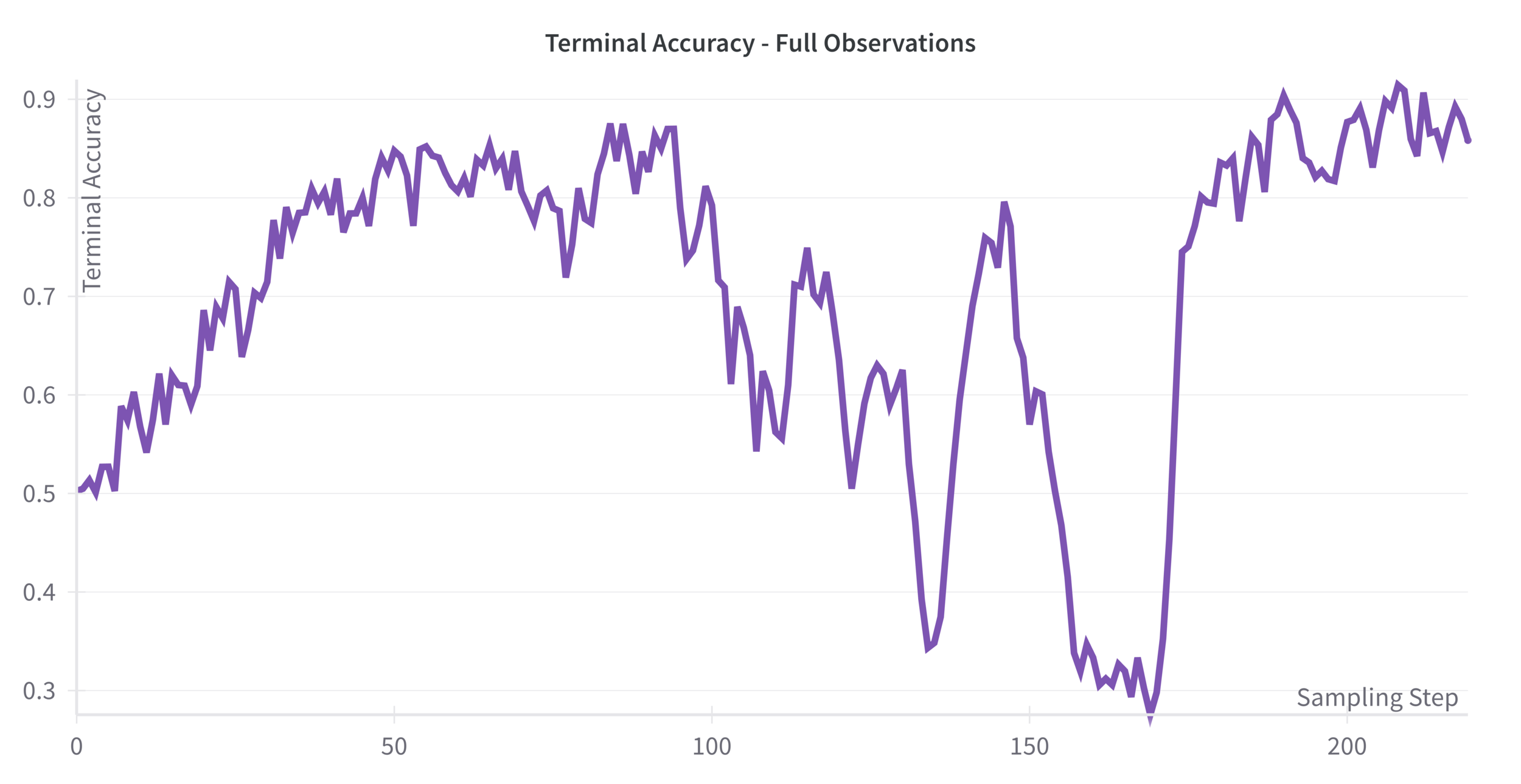
Full Observations
Partial Observations
Partial Observations
1.1% Initial
Terminal Accuracy
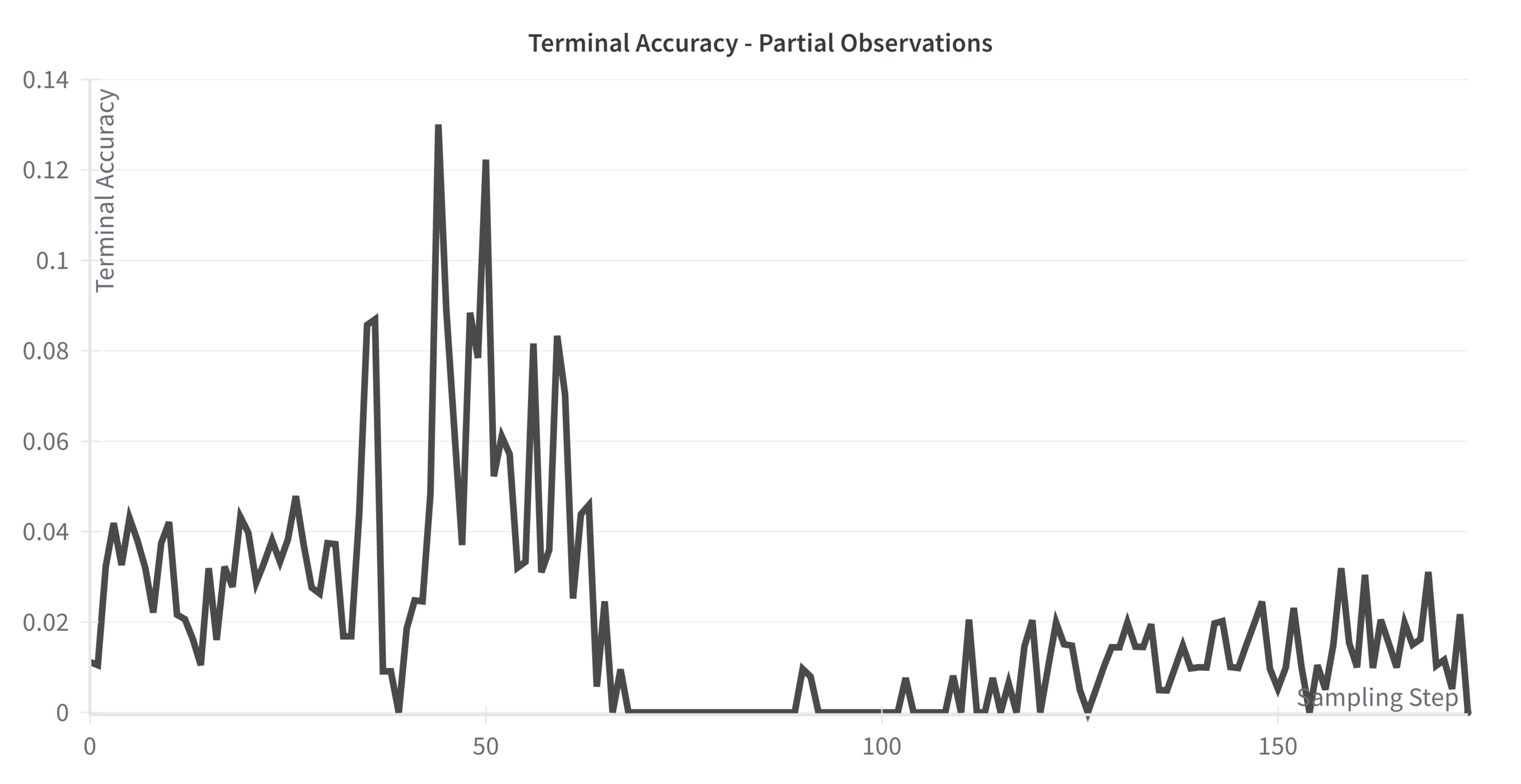
13.0% Peak
Terminal Accuracy
Partial Observations
Full Observations
Partial Observations
Full Observations
Full Observations
91% Peak Terminal Accuracy
Perfect Wait for Welcome Ability
Appropriate Patience
Partial Observations
Partial Observations
Only 13% Peak Terminal Accuracy
10x Improvement
Chance-level Initial Terminal Accuracy
Impact of Observational Settings
Can we trust the Evaluation?
Data Quality
Impact of Overfitting
Non-Deterministic Evaluation
Can we trust the Evaluation?
Can we trust the Evaluation?
Yes (for the most part)
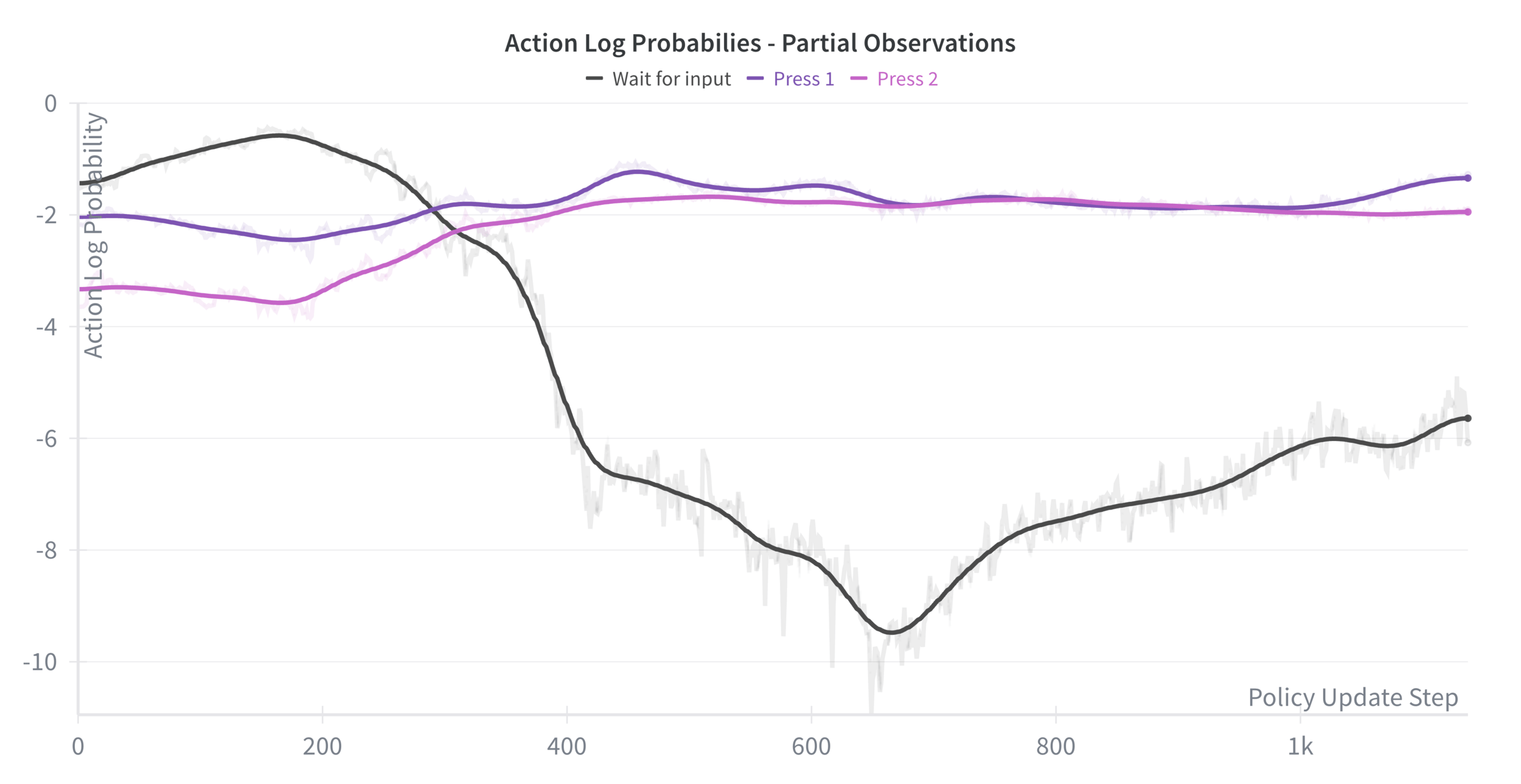
Investigating Partial Observations
What if we extended the fine-tuning?
Investigating Partial Observations

What if we extended the fine-tuning?
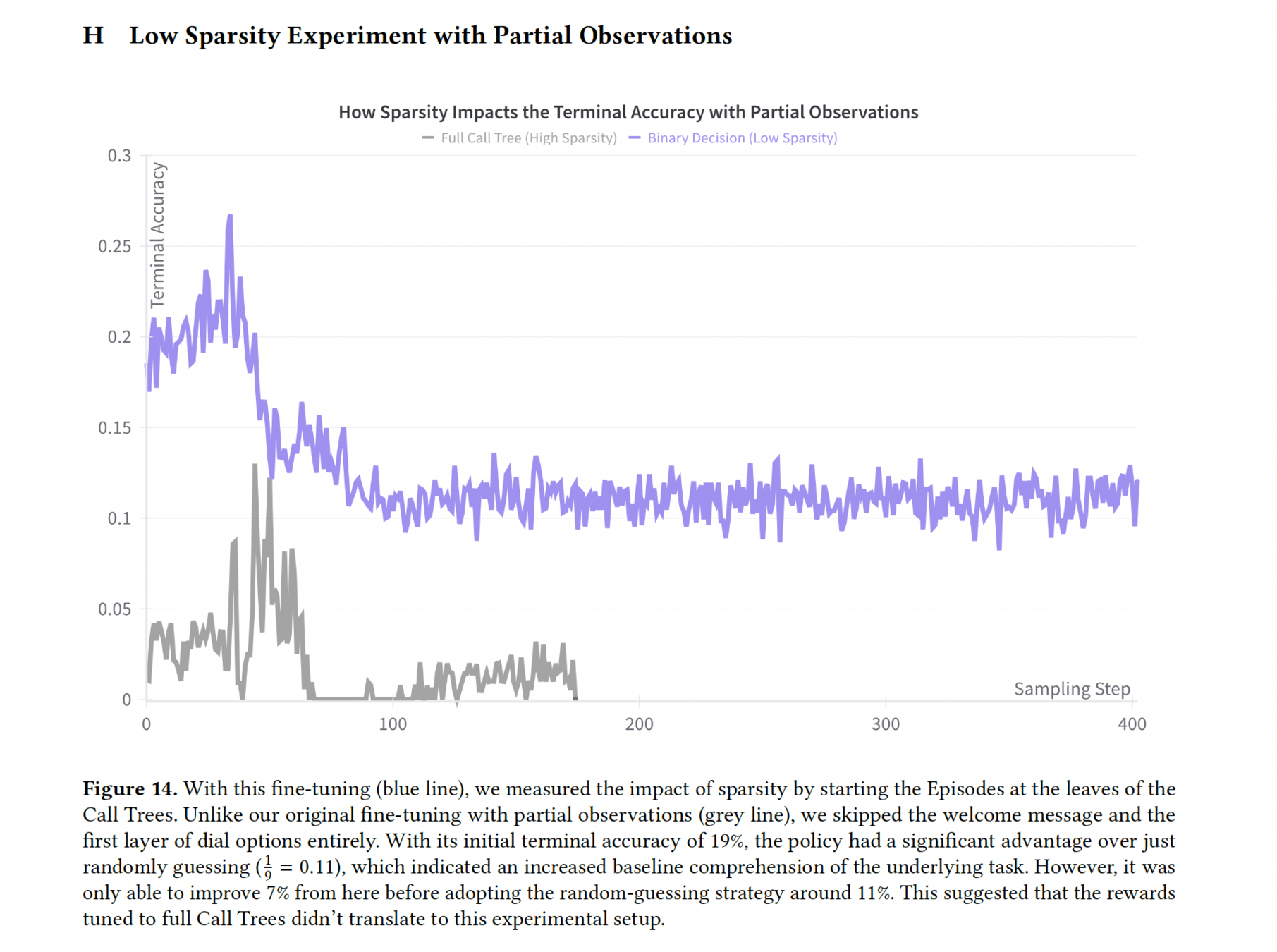
Sparsity
Hypothesis
Sparse rewards confuse the policy and critic on the objective of the environment
Sparsity
Experiment 1
Reduced Call Trees to a binary decision to test the impact of shorter episode lengths
Sparsity
Experiment 1
Reduced Call Trees to a binary decision to test the impact of shorter episode lengths
Finding (1)
Potential sensitivity to the reward function
Finding (2)
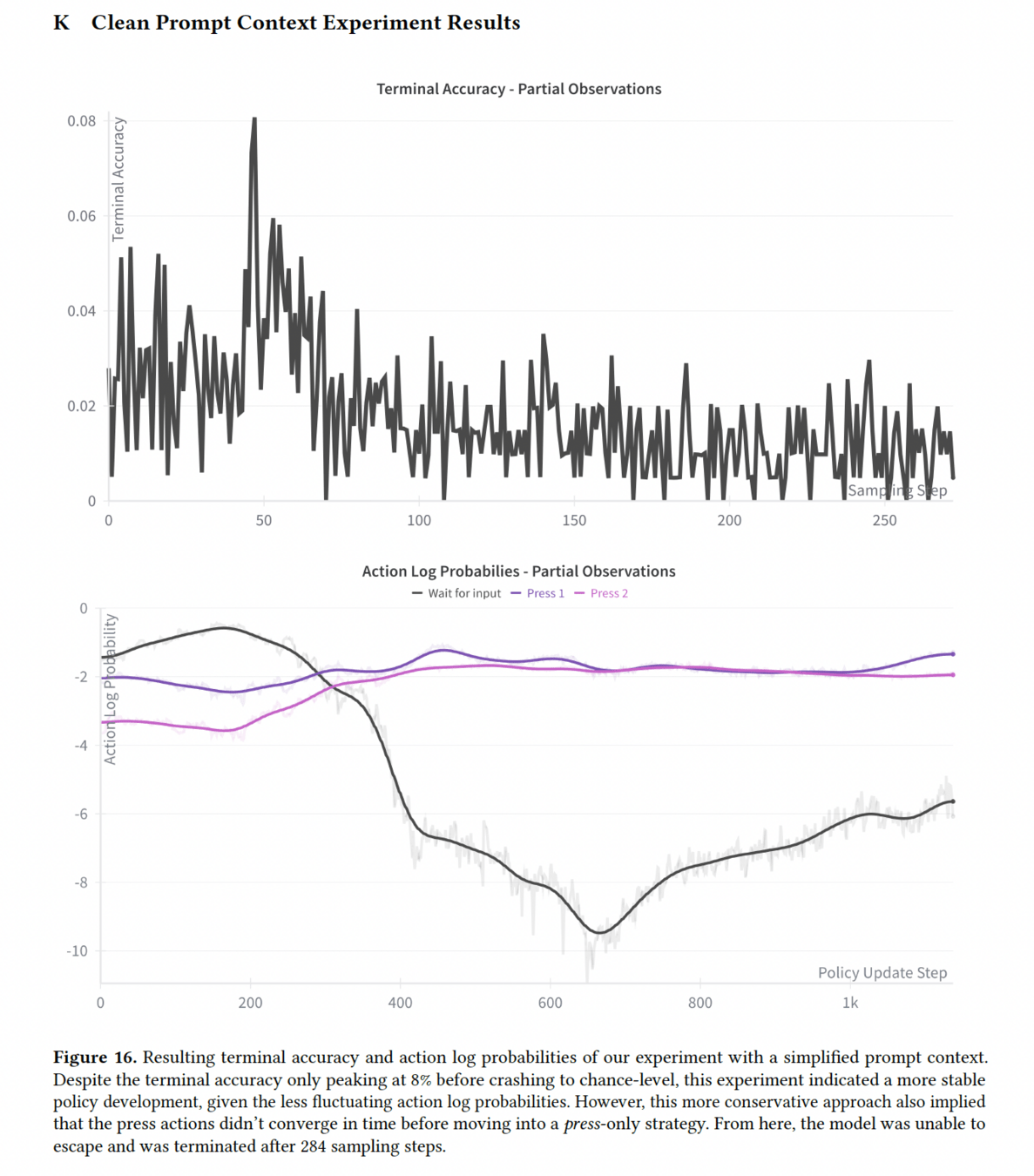
Baseline performance improvement indicated that cleaning the prompt context improved the model's baseline understanding ability
Sparsity
Experiment 2
Incremented chunking frequency to test the impact on baseline performance

Sparsity
Experiment 2
Finding
Sparsity seems to hurt the model’s baseline understanding ability
Prompt Context Noise
Hypothesis
Previous observations and actions can negatively impact future reasoning
Prompt Context Noise
Experiment
Removed wait for input from the prompt context
technical support
Wait
press 8.
Press 8
For billing
Wait
Prompt Context Noise
Experiment
Removed wait for input from the prompt context
technical support
press 8.
Press 8
For billing
Press 8
Prompt Context Noise
Experiment
Removed wait for input from the prompt context
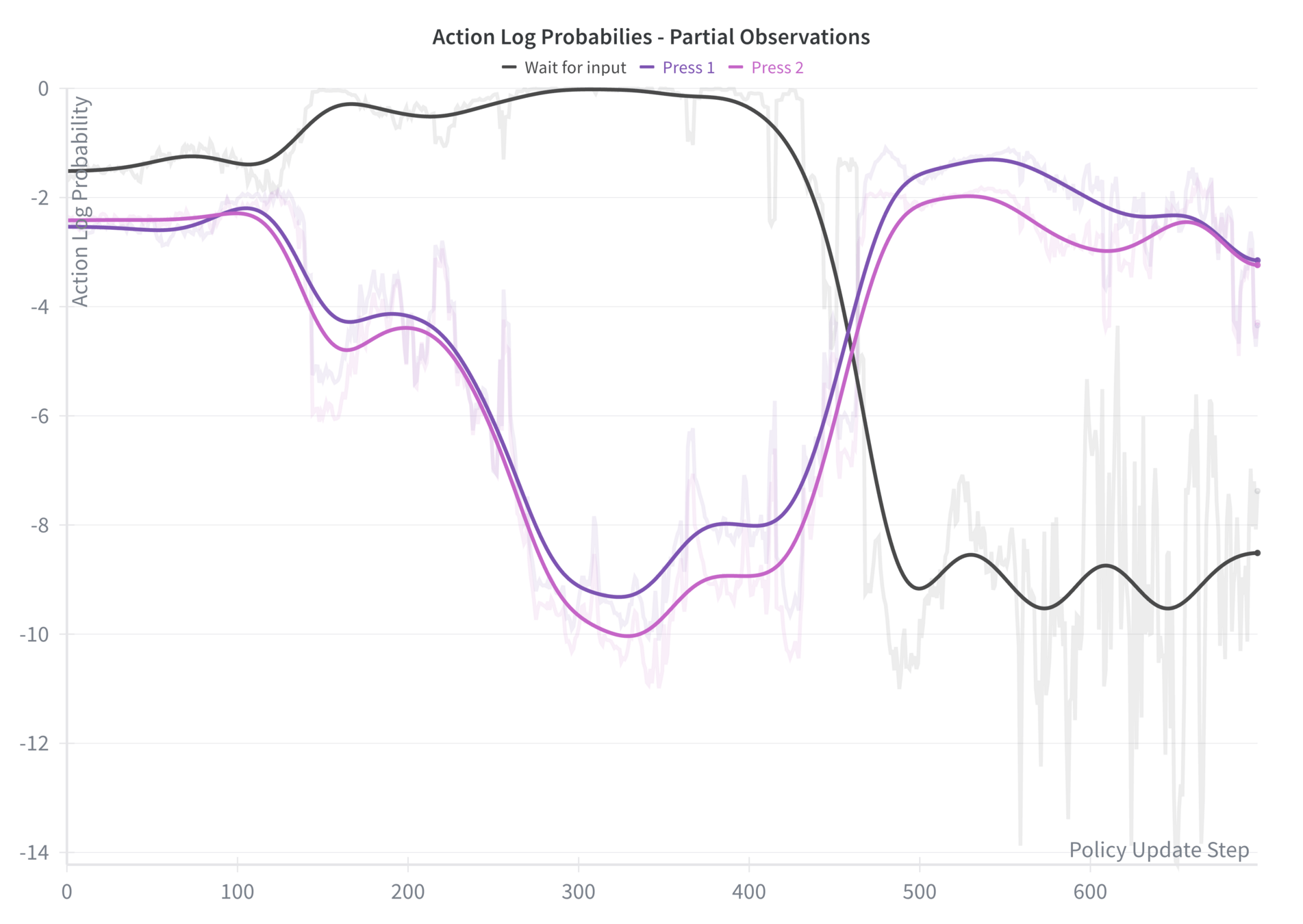
Prompt Context Noise
Experiment
Removed
wait for input
from the prompt context
Finding
Signs of reasoning derailment
Reward Sensitivity
Hypothesis
Slight variations in the reward function can cause dramatically different outcomes
Reward Sensitivity
Experiment
Slightly lowered the punishment
of waiting on silence
Reward Sensitivity
Experiment
Slightly lowered the punishment
of waiting on silence
Finding
The fine-tuning seemed to be to sensitive the reward function
Conclusion
Confirmed that Partial Observations
hurts RL fine-tuning
Sparsity
Reasoning Derailment
Reward Sensitivity
Future Directions
HTL: A Novel RL Environment
Patience Is All You Need






Thesis
By Adam Lass



