X
NEO4j
Uniiverse x neo4j
Adam Meghji
Co-Founder, CTO
Uniiverse.com
e: adam@uniiverse.com
t: @AdamMeghji
WHO AM I

Co-Founder and CTO at @uniiverse.
Entrepreneur & hacker. Rails APIs, EmberJS, DevOps.
http://djmarmalade.com.
Always inspired!
Sell tickets, promote & manage your events!
Provide tools to event organizers so they can sell more tickets.
Social marketing tools, re-engage buyers.
via Web, Embed, FB, iOS, Android, Blackberry apps!
WHY DO WE NEED A
GRAPH DATABASE?
Persist Social Data
Ad-hoc Querying
Daily Email Recommendations
Social Invite Tools
Business Intelligence

Persist Social Data
Event organizers connect their social graphs to
market events to their social communities.
Buyers connect their social graphs to discover
what friends and foafs are doing in real life.
AD-HOC QUERYING
Using Pacer
Using CYPHER
DAILY EMAIL RECOMMENDATIONS
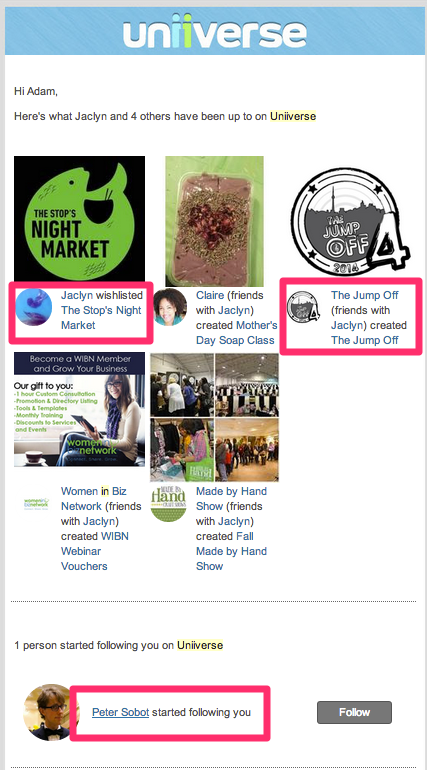
SOCIAL INVITE TOOLS
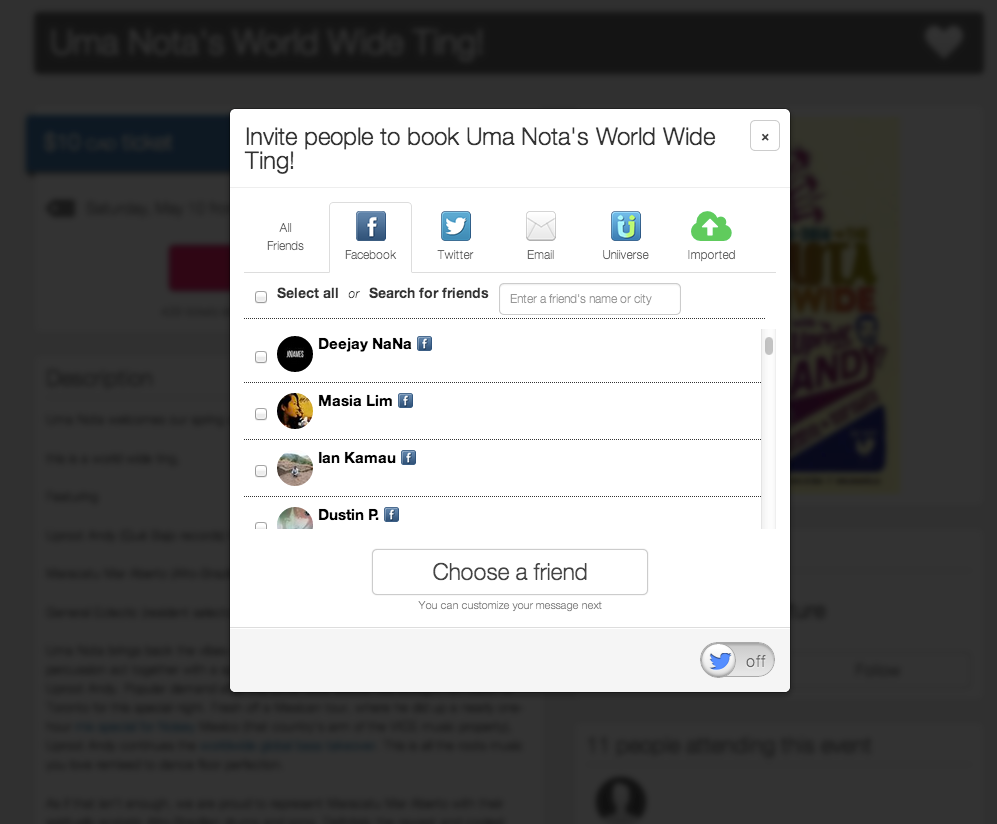
bUSINESs INTElLIGeNce
How wide is our social reach?
BUSINESS INTELLIGENCE
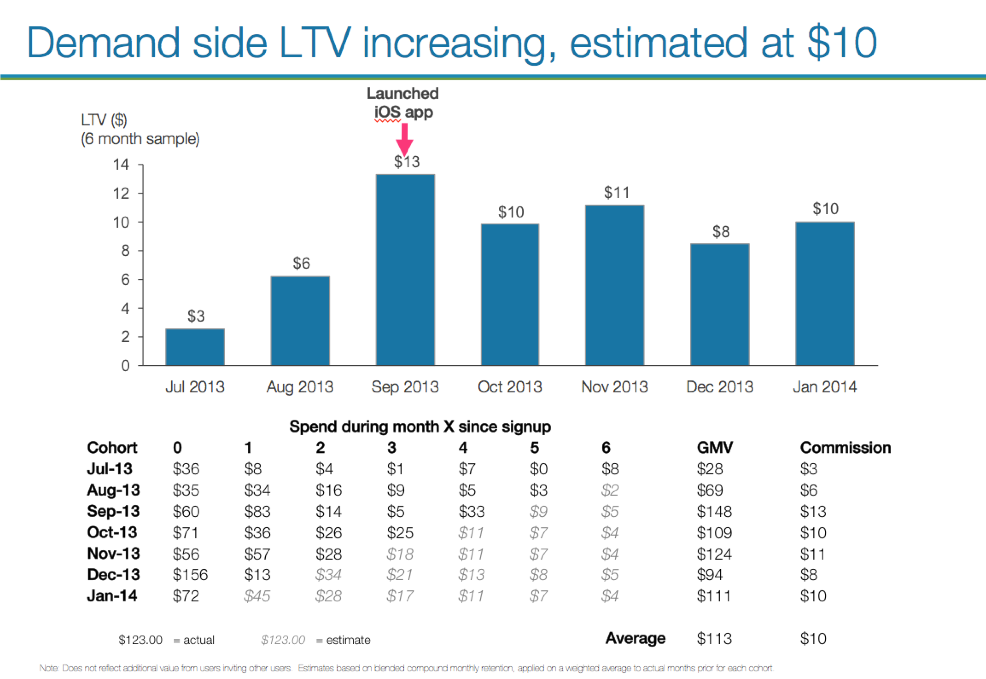
BUSINESS INTELLIGENCE
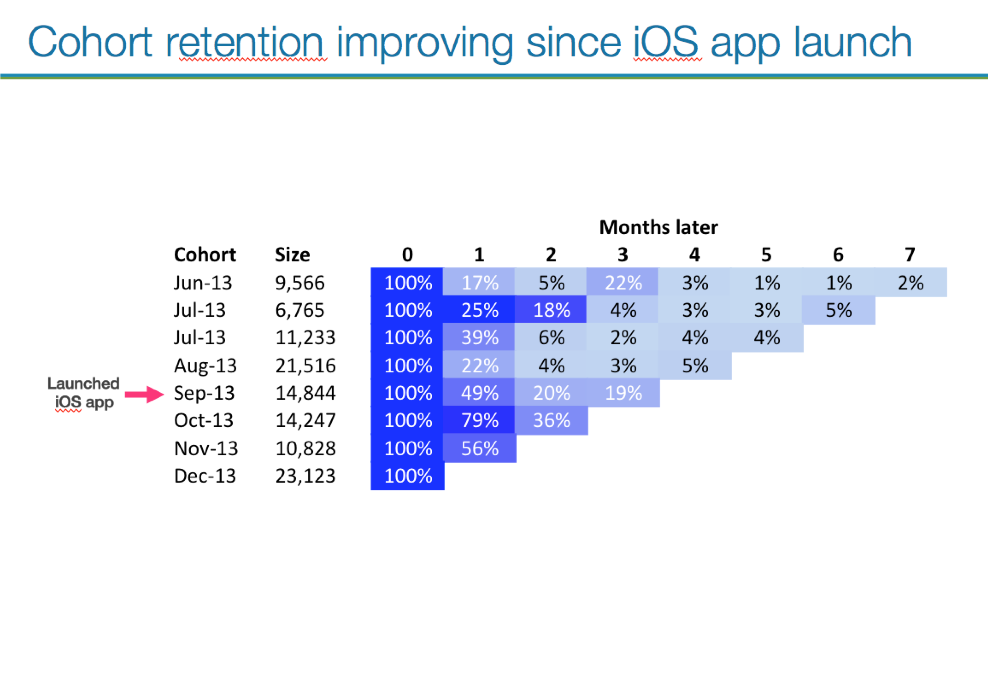
NUMbers
Vertices: 300MM
1' Vertices: 30MM
Size on Disk: 68G
GRAPH API STACK
JRuby 1.7
pacer-neo4j
Embedded Graphs
Embedded Graphs
jrjackson
Sinatra
Trinidad
INTEGRATING WITH OUR RAILS API
INTEGRATING WITH OUR RAILS API
Rails models (User, Listing, etc) are also
vertex types in the graph.
@user.graph_id -> v(:user).id
v(:user).mongo_id -> @user.id
USER.rb
class User
include Mongoid::Document
field :graph_id, type: String
after_create :insert_in_graph
def insert_in_graph
set :graph_id, create_vertex
end
def create_vertex
attrs = {name: @user.name}
raw_json = RestClient.post("http://graph.db/uniiverse/users", attrs)
JSON.parse(raw_json)[:id]
end
end
USER.rb
PROBLEMS WITH THIS APPROACH:
after_create callback will perform graph operations synchronously
If graph API is unavailable (heavy load, restarting, down, etc)
then web API responses will be affected.
i.e. user signs up -> vertex creation
i.e. ticket purchase -> edge creation
USER.RB + Sidekiq!
class User
include Mongoid::Document
field :graph_id, type: String
after_create :insert_in_graph
def insert_in_graph
InsertUserVertexWorker.perform_async(id)
end
end
SIDEKIQ VERTEX WORKER
class InsertUserVertexWorker
include Sidekiq::Worker
def perform(user_id)
@user = User.find(user_id)
@user.set :graph_id, create_vertex
end
def create_vertex
attrs = {name: @user.name}
raw_json = RestClient.post("http://graph.db/uniiverse/users", attrs)
JSON.parse(raw_json)[:id]
end
end
ASYNC BENEFITS
1. web requests are unaffected by graph service availability
2. pausing workers will suspend traffic to graph
3. limit # of worker processes subscribed to control throttling
4. if you upsert into graph, async job is idempotent,
so can safely retry failed jobs ....
EXAMPLE: UPSERT WORKER
class UpsertUserVertexWorker
include Sidekiq::Worker
sidekiq_options retry: true
def perform(user_id)
@user = User.find(user_id)
graph_id = find_vertex || create_vertex
@user.set :graph_id, graph_id
end
def find_vertex
raw_json = RestClient.get("http://graph.db/uniiverse/users/find_by_mongo_id/#{@user.id}")
JSON.parse(raw_json)[:id]
rescue RestClient::ResourceNotFound
# not found -- that's okay.
end
def create_vertex
attrs = {name: @user.name}
raw_json = RestClient.post("http://graph.db/uniiverse/users", attrs)
JSON.parse(raw_json)[:id]
end
end
Upsert will find or create the vertex,
so is idempotent, and retry-safe!
LISTING.RB + SIDEKIQ!
class ListingCreateWorker include Sidekiq::Worker def perform(listing_id) @listing = Listing.find(listing_id) create_vertex # same as other slide create_edge end # user-[created]->listing def create_edge RestClient.post("http://graph.db/uniiverse/users/#{@listing.host.graph_id}/created_listing/#{@listing.graph_id}")endend
FACEBOOK VERTEX
User OAuth's Facebook,
so let's upsert them in our graph.
class FacebookAccount
field :uid, type: String
field :graph_id, type: String
belongs_to :user
after_create :upsert_in_graph
end
class FacebookVertexWorker
def perform
@facebook.set :graph_id, find_vertex || create_vertex
end
def find_vertex
raw_json = RestClient.get("http://graph.db/facebook/users/find_by_uid/#{@facebook.uid}")
JSON.parse(raw_json)[:id]
end
def create_vertex
# do stuff
end
end FACEBOOK FRIENDS
Rails' model fetches latest friends from FB Graph API,
and pushes them to our Graph.
class FacebookAccount
def update_friends
fb = Koala::Facebook::API.new(token)
friends = fb.get_connections("me", "friends", fields: "name,id,location").map |friend|
{ uid: friend[:uid], etc. }
end
RestClient.patch("http://graph.db/facebook/users/#{graph_id}/friends", friends)
end
end
PATCH FRIENDS API
Our Graph API accepts PATCH requests,
upserts friend vertexes,
and builds user-[:friend]-user edges.
patch "/facebook/users/:id/friends" do
v1 = find_by_id(params[:id])
params[:friends].each do |friend|
v2 = find_or_create_vertex(friend)
create_edge_between v1, v2, :friend, FACEBOOK_GRAPH
end
end FRIENDS SORTED BY
MUTUAL FRIEND COUNTS
SLOW APPROACH:
tallying mutual friends within query,
then applying as order clause.
VERY FAST APPROACH:
denormalize the mutual_friend count as an
edge property, then order by that.
DENORMALIZING
MUTUAL FRIEND COUNTS
CYPHER update statement:
START a=node(#{id})
MATCH a-[:friend]-b-[:friend]-c, a-[r:friend]-c
WITH COUNT(distinct b) AS mutual_friend_count, r
SET r.mutual_friends = mutual_friend_count;
FRIENDS ORDERED BY
MUTUAL FRIEND COUNTS
CYPHER query:
START n=node(#{id})
MATCH n-[e:friend]-x
WITH x, e.mutual_friends? AS mutual_friends
ORDER BY mutual_friends desc
RETURN mutual_friends, x
NOTE: e.mutual.friends? since field can be null.
SEE IT IN ACTION!
lessons learned
PROBLEM:
JVM HEAP out of memory
Neo4j Cache Settings
Object cache
"caches individual nodes and relationships
and their properties in a form that is
optimized for fast traversal of the graph"
NEO4J CACHE SETTINGS
| cache_type | use case |
|---|---|
| strong |
very aggressive, but fast! best if your graph fits entirely in RAM. |
| soft |
DEFAULT: less aggressive, good for traversals. for us, lots of OutOfMemoryErrors!! |
| weak | RECOMMENDED: well-suited to large graphs or diverse working sets, most reliable. |
PROBLEM:
Excessive disk usage
Neo4j logical logs
keep_logical_logs
i.e. journal settings
needed for HA or incremental backups
RECOMMENDED: set to something small: "100M"
PROBLEM:
MiGRATIONS
MIGRATIONS
Since graph is embedded, 1 instance of either server or
console need to be open.
Embedded graphs lock the data directory,
so if you run rake migrations,
web will be down.
SOLUTION!
Execute migrations via HTTP:
get "/system/migrations/remove_attended_edges" do
Thread.new do
UNIIVERSE_GRAPH.e(:attended).delete!
end
200
end
TIP: kick off long running migrations in a Thread.new!
Problem:
performance in the cloud
PERFORMANCE
Uniiverse runs on AWS.
Uniiverse Graph API is running Neo4j Community Edition
on 1 "precious instance"
On AWS, CPU + RAM + IO was usually 100% saturated.
Large graph operations were horribly slow.
AWS c1.xlarge
7GB RAM
8 cores
UnixBench score: 1774.7
I/O rate: 34.7 MB/second
Price $417.60
:(
AWS m3.xlarge
15GB RAM
4 cores
UnixBench score: 1117.7
I/O rate: 37.4 MB/second
Price $324.00
:(
DigitalOcean 48GB SSD
48GB RAM !!
16 CPU !!
UnixBench score: 4773.5 !!
I/O rate: 148.0 MB/second !!
Price $480.00
<3 (((o(*゚▽゚*)o))) <3
DIGITALOCEAN ROCKS.
48GB RAM: Can allocate a large JVM heap size,
helps with large migrations or graph-wide operations.
48GB RAM: Gives java.nio more room to breathe.
16 Cores: Parallelize large operations!
IO: 4x faster than AWS.
May 5: today is that box's 1 year uptime anniversary!
PROBLEM:
Aws + DiGITALOCEAN
+ secure connections
DIGITALOCEAN LIMITATIONS?
Security: needs to be privately accessible to web cluster.
On AWS, we use Security Groups to firewall traffic
between the graph API + any box in the web API cluster.
Traffic must be encrypted.
AWS -> DigitalOcean securely needs a little
more configuration ....
SOLUTION: AUTOSSH!
"autossh is a program to start a copy of ssh and monitor it, restarting it as necessary should it die or stop passing traffic"
AUTOSSH + MONIT:
monit keeps autossh process up:
check process graph_autossh_production with pidfile "/var/run/graph_autossh_production.pid"
start program = "/etc/init.d/graph_autossh_production.sh start"
stop program = "/etc/init.d/graph_autossh_production.sh stop"
AUTOSSH + INIT.d:
Launches autossh, which opens the tunnel and keeps it open.
DAEMON=/usr/bin/autossh
DAEMON_OPTS="-2 -f -N -L $PORT:localhost:$PORT $SSH_HOSTNAME -p $SSH_PORT"
start-stop-daemon --start --quiet --exec $DAEMON -- $DAEMON_OPTS
Web API makes graph requests on a local port,
i.e. http://localhost:9090
problem:
MONITORING THE JVM
(heap size, old gen, threads)
JCONSOLE
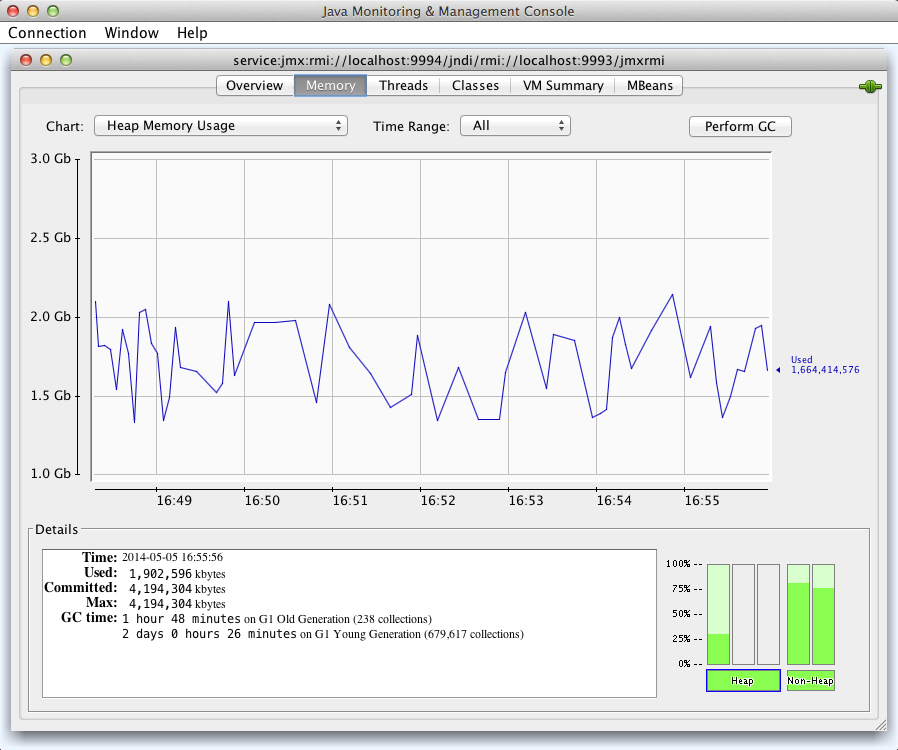
1. launch ssh tunneL
ssh -N -L9993:localhost:9993 -L9994:localhost:9994 graph.db
2. OPEN JCONSOLE
AGAINST PRODUCTION
wget http://archive.apache.org/dist/tomcat/tomcat-7/v7.0.32/bin/extras/catalina-jmx-remote.jar 1> /dev/null 2> /dev/null
jconsole -debug -J"-Djava.class.path=$$JAVA_HOME/lib/tools.jar:$$JAVA_HOME/lib/jconsole.jar:catalina-jmx-remote.jar" service:jmx:rmi://localhost:9994/jndi/rmi://localhost:9993/jmxrmi
BACKUP
NEO4j + BACKUP
Available in Neo4j Enterprise
Used to be $30k per JVM
Startup Plan starts at $12k/year
Two modes: incremental & full
BACKUP USING NEO4j COMMUNITY
How to backup using Neo4j Community?
We're a startup! Can we save $12k annually?
YES! But how? Backups need to be consistent,
downtime needs to be minimal.
SOLUTION: LVM2
"LVM2 refers to the userspace toolset that provide logical volume management facilities on linux"
LVM2 has the ability to instantly freeze a snapshot a filesystem while the original FS runs uninterrupted.
LVM2 Setup:
apt-get install -y lvm2
# tell LVM2 to use block device /dev/xvdf for its physical volume
pvcreate /dev/xvdf
# tell LVM2 to create a new volume group called "galileo_production" on that physical volume
vgcreate galileo_production /dev/xvdf
# => creates /dev/galileo_production
# finally, create a usable logical volume for our new filesystem,
# but reserve 50% of the space for a realtime snapshot
lvcreate -n db --extents 50%FREE galileo_production
# => creates /dev/galileo_production/db
# format it and mount it:
mkfs.ext4 /dev/galileo_production/db
mkdir -p /mnt/db_production
echo "/dev/galileo_production/db /mnt/db_production auto defaults,nobootwait,comment=cloudconfig 0 2" >> /etc/fstab
mount /mnt/db_production TAKING A SNAPSHOT:
# immediately snapshot the production data
sudo lvcreate -L32G -s -n production_backup /dev/galileo/production
# mount the snapshot temporarily
sudo mkdir -p /mnt/snapshot
sudo mount /dev/galileo/production_backup /mnt/snapshot
# tgz it up!
sudo tar -zcvf /mnt/snapshot.tgz /mnt/snapshot
# unmount and destroys the snapshot
sudo umount /mnt/snapshot
sudo lvremove /dev/galileo/production_backup -f LET's AUTOMATE THIS!
Backup gem: https://github.com/meskyanichi/backup
We use it with MongoDB, PostgreSQL, Redis
.. why not Neo4j?
https://github.com/adammeghji/backup/blob/master/lib/backup/database/neo4j.rb
OVERVIEW
1. lock_database (recommended):
- POST "http://localhost:4242/system/shutdown"
i.e. does 'graph.stop' in pacer
2. unmount_snapshot:
- unmounts any stale snapshots via `umount`, then destroys via `lvremove`
3. mount_snapshot:
- lvcreates the snapshot immediately
- mounts it
lock_database if @lock_url
4. unlock_database (needed if locked):
- POST "http://localhost:4242/system/startup"
i.e. does 'graph.start' in pacer
5. tar, gzip, split into 5G chunks, and upload!
OH OH! DIGITALOCEAN ..
This strategy needs 1 dedicated block device to snapshot
DO strictly includes 1 large root volume, and cannot use a custom partition scheme.
DO doesn't provide block storage like EBS, so you can't add new volumes in /dev.
So, how can we create the required new LVM2 block device?
Loopback Filesystem FTW
To create a "virtual" disk, use a loopback device.
Adds a small amount of CPU overhead (~5% of 1 core), but a really powerful workaround.
# create a blank 120GB ISO file
dd if=/dev/zero of=/data/production.iso bs=1024 count=125829120 # 120GB * 1024*1024
# configure as a loopback device
losetup /dev/loop0 /data/production.iso
mkfs.ext4 /dev/loop0
# setup LVM2 physical volumes similar to above, but with loop0
pvcreate /dev/loop0
vgcreate galileo_production /dev/loop0 QUESTIONS?
THANK YOU!
http://www.uniiverse.com
@AdamMeghji
adam@uniiverse.com
UNIIVERSE X NEO4j
By adammeghji




