Data Generation and Simulation For Behavior Cloning
Adam Wei






Planar Pushing
Preparing Toast
Flipping Pancakes
Flipping Pages
Peeling Vegetables
Unpacking Boxes
Behavior Cloning
Behavior Cloning
Behavior Cloning Algorithm
\mathcal{D} = \{(O_i, A_i)\}_{i=1}^N
Policy
Ex. Diffusion Policy

?
How can we obtain the dataset \(\mathcal{D}\)?
Robot Data Diet

Big data
Big transfer gap
Small data
No transfer gap

Ego-Exo
robot teleop


Open-X
simulation
How can we obtain the dataset \(\mathcal{D}\)?
Cotrain from different data sources (ex. sim and real)

Let us consider a simple example...
- Simple problem, but encapsulates core challenges in contact-rich manipulation:
-
Hybrid system:
- Where to make contact?
- What motion in each contact mode?
- Underactuated system
- Stay collision-free (between contacts)
- Output-feedback control
Goal: Manipulate object to target pose
Potential Solutions
- Behavior Cloning (BC) can solve this!
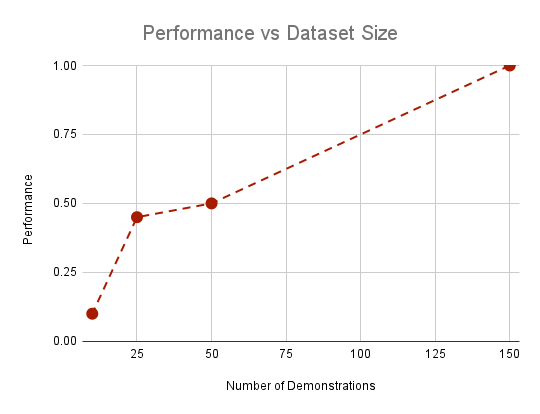
- Given 136 human demonstrations
Goal: Manipulate object to target pose
“Diffusion Policy: Visuomotor Policy Learning via Action Diffusion.”, C. Chi et al., RSS 2023
Potential Solutions
Goal: Manipulate object to target pose
“Diffusion Policy: Visuomotor Policy Learning via Action Diffusion.”, C. Chi et al., RSS 2023
- Performance suffers below 50 demonstrations ( < 50%)
- Poses challenges for scaling
- Can we generate high-quality demonstrations in simulation using trajectory optimization?
Cotraining For Contact-Rich Tasks
Behavior Cloning Algorithm
Policy
Real-World Data \(\mathcal{D}_{real}\)
Simulated Data \(\mathcal{D}_{sim}\)
- How can we reliably and efficiently generate data for contact-rich tasks?
- How should we cotrain from multiple different data sources? What properties in \(\mathcal{D}_{sim}\) are important for cotraining?
...happy to chat afterwards!
A new method based on convex optimization
1. Global
(A few percent from global optimality)
2. Reliable
(Works 100%
of the time)
3. Efficient
(Scales polynomially, not exponentially)

Step 1: Planning in a fixed mode
- Already hard:
- Rotation matrices: \( \textrm{SO}(2) \)
- Torque = arm \( \times \) force
- Use convex semidefinite programming (SDP) relaxation
- Approximate planning (in a fixed mode) as convex program
\( \} \)
Bilinear (nonconvex) constraints

Step 2: Composing the contact modes
- Graph of Convex Sets (GCS) framework
“Shortest Paths in Graphs of Convex Sets,”
Marcucci et al., SIAM OPT. 2024
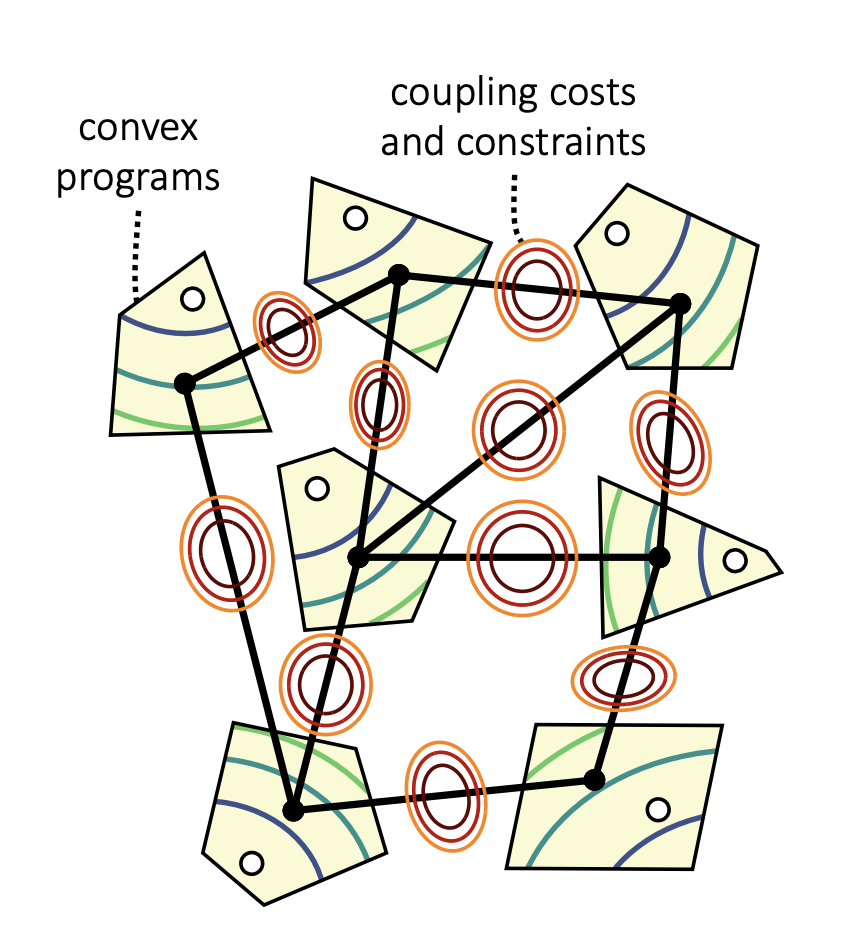
- High-level: Compose convex programs with GCS
- Vertix = motion planning in a mode
- Path = mode sequence
- Contact-rich planning = Solve Shortest Path Problem in GCS (convex program) + quick rounding step
Step 2: Composing the contact modes
- Graph of Convex Sets (GCS) framework
“Shortest Paths in Graphs of Convex Sets,”
Marcucci et al., SIAM OPT. 2024
- High-level: Compose convex programs with GCS
- Vertix = motion planning in a mode
- Path = mode sequence
- Contact-rich planning = Solve Shortest Path Problem in GCS (convex program) + quick rounding step
Hardware Results
Caveats
- Executing pre-planned trajectories (unable to replan in real-time)
- Requires a low-level tracking controller
- Explicit state estimation
Fundamental progress towards real-time output-feedback control through contact, but not a complete solution... yet
Diffusion Policy
\mathcal{D}_{sim}



Robot Poses
A
O
Rollout plans in sim
(render observations)
Instead of running the plans directly on hardware...
Generate plans (GCS)
Cotrain a diffusion policy on both \(\mathcal{D_{real}}\) and \(\mathcal{D_{sim}}\)
- Teacher-student (distilling GCS plans into a policy)
Diffusion Policy Results
Real-time re-planning
Low-level control
No explicit state estimation;
pixels to actions
50 real demos, 500 sim demos
Performance Improvements
10 real demos
2000 sim demos
50 real demos
500 sim demos
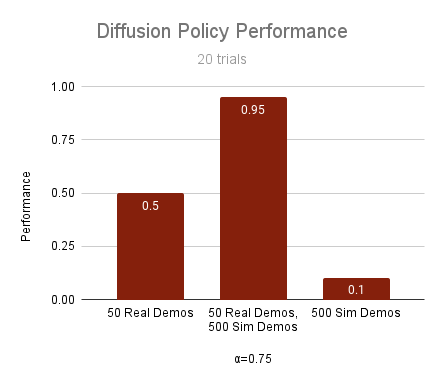
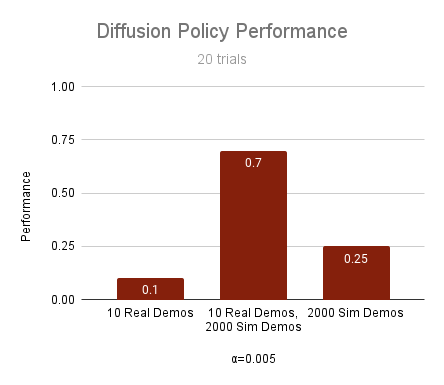
How impactful is cotraining?
Cotraining For General Robotics
Behavior Cloning Algorithm
Policy
Real-World Data \(\mathcal{D}_{real}\)
Simulated Data \(\mathcal{D}_{sim}\)
GCS
(contact-rich tasks & motion planning)
Optimus
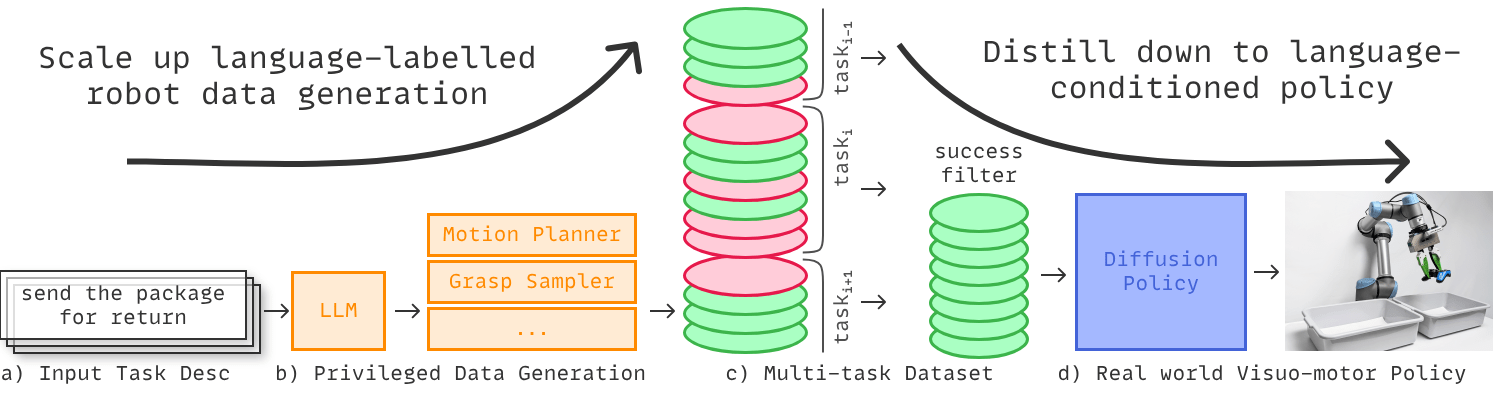
Scaling Up Distilling Down
(TAMP & semantic reasoning)
Studying the Cotraining Problem
Why study co-training?
- Cotraining can drastically improve policy performance
- The community is investing in simulation and data generation
Some initial insights...
- Co-training unanimously improves policy performance in the low-data regime
- Policy performance is highly sensitive to the weighting of the co-training mixture. Scaling sim data reduces this sensitivity.
- Distribution shifts in the sim data have varying affects on the optimal mixture and policy performance; some shifts are more harmful than others
...happy to chat afterwards!

Future Work
- Finetuning to improve co-training results
- New co-training formuations (Ex. classifier-free guidance)
- Multi-task experiments
- Real2Sim→Data Generation in Sim (ex. GCS, LucidSim)→Sim & Real co-training
- GCS + SLS for information gathering and uncertainty-aware data generation (see Glen's poster)
Connections to other projects
Control Through Contact - Amazon
By Adam Wei



