Results: performance of the system
Simulation parameters
- 870 peers
- 10 GB to backup, 32 fragments
- 50 GB of local space to store data
- 97 days period
- Scheduling every 5 min
- Class of availability (multiples of 0.1)
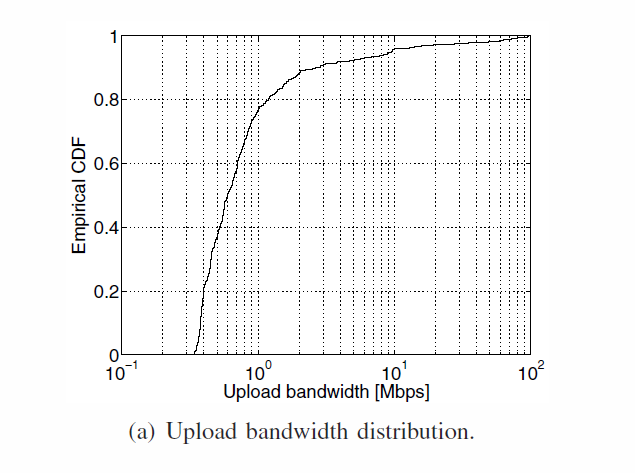
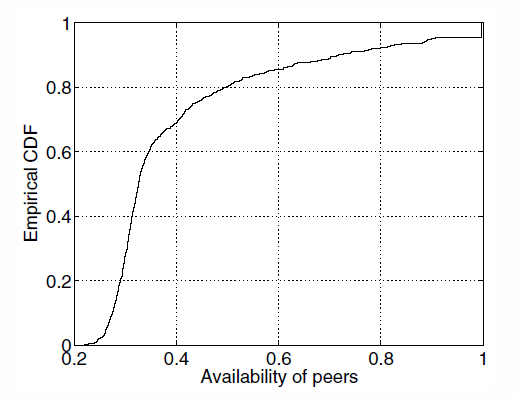
Results: performance of the system
TTB (Time to backup) : time needed to complete the backup. The number of uploaded fragments x+s respect the successful backup condition
Notions :
x\geq p(s)
x≥p(s)
TTR (Time to restore) : time needed to dowload the sufficient amount of fragment to reconstruct the original object
Cost : the amount of resources stored on the storage server
DC, PA-O, PA-P, P2P: respectively centralized, peer-assisted optimistic, pessimistic and Peer to peer approaches.
Results: performance of the system
General overview
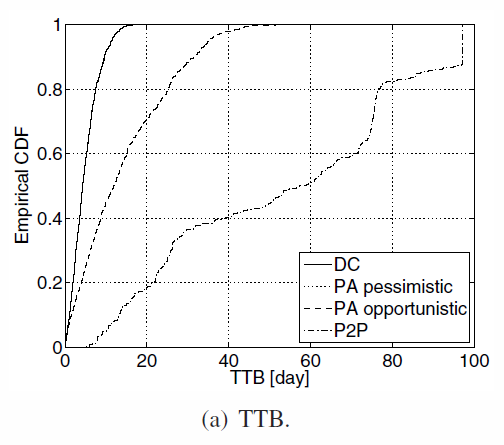
- DC and PA-P have best results since all the data is uploaded on the storage server first.
- PA-O is worse, because more fragments have to be send to peers and server (redudancy)
- P2P is the worst : some peers don't backup in time because of the redudancy and the online behavior that can interrupt download
TTB distribution
Results: performance of the system
General overview
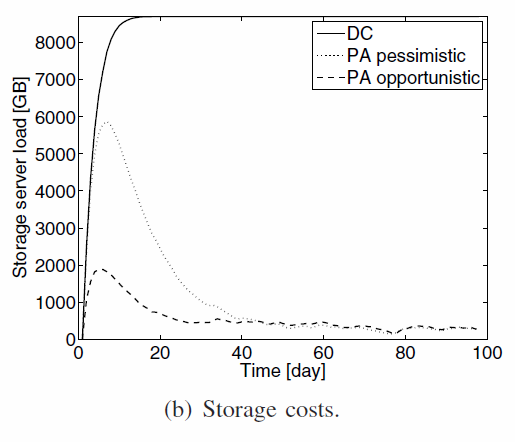
- Max costs for DC
- PA-P first high costs : everything is uploaded to the server, then lower costs after optimization
- PA-O : low cost for low server load.
- Always something on the server because of the maintenance
Text
Storage cost in time
Results: performance of the system
General overview
- TTR: almost the same curves, less than a day.
Finally, TTB is really low for PA-P, but it costs more.
Performances compare to Client-Server approach, with much lower costs.
Results: performance of the system
Data placement (random) and fairness
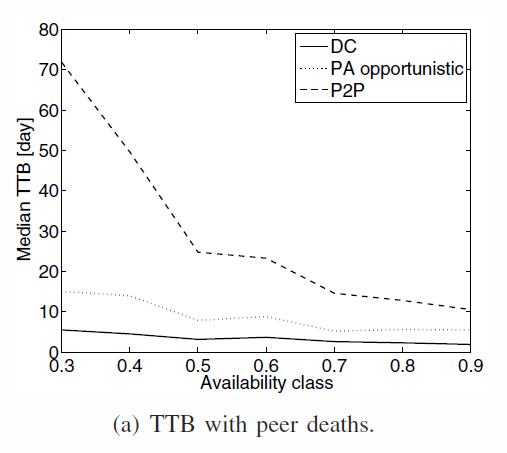
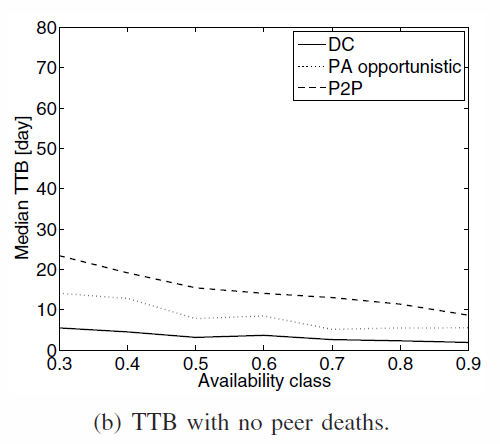
PA and DC are not affected by peer death. P2P is. Close to DC approach without P2P problems
TTB in the different availability classes
Results: performance of the system
Data placement and fairness
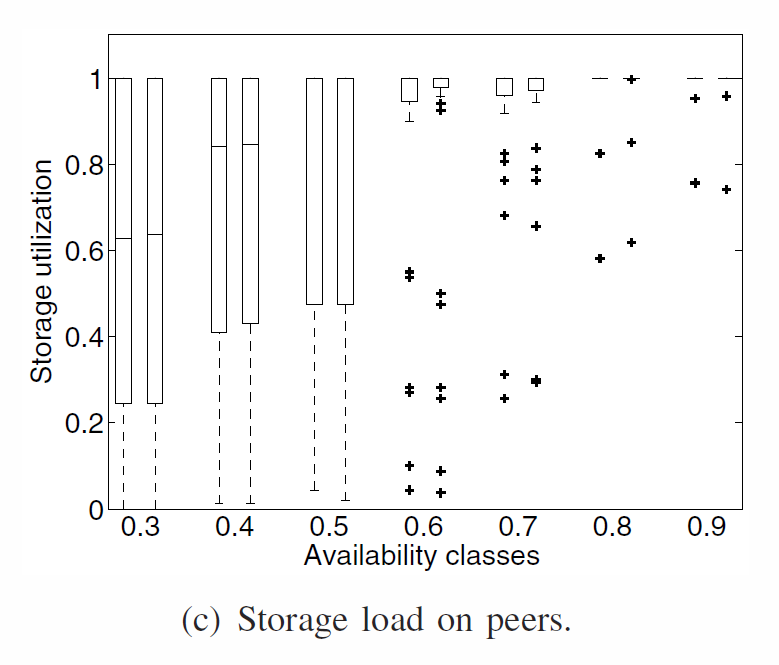
Uneven distribution :
- Most available classes receive more data because they are often online. Capacity exploited by peers with low-availability
- Solve this by using symetric selective approach
storage load in the different availability classes
Results: performance of the system
Data placement and fairness
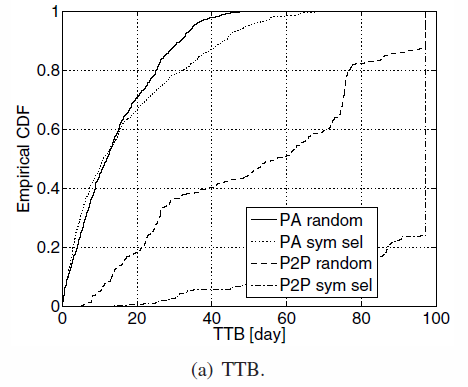
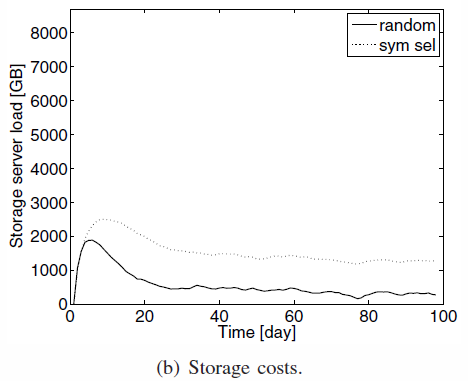
- TTB repartition : P2P cannot handle both, while PA can handle symetric selection with not a lot of impacts
- Storage costs : Symetric selection costs more since it's harder to find a peer from the same availability class: storage is more used
TTB repartition and storage costs of selections
Results: performance of the system
Fragments size
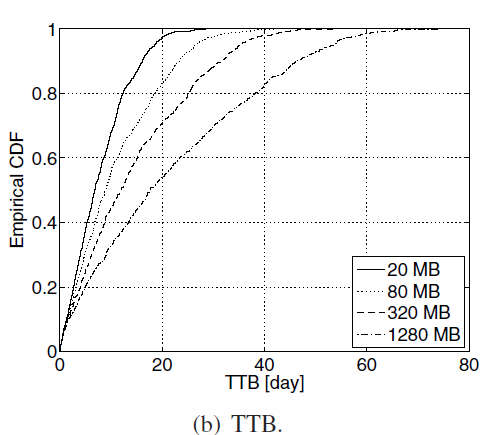
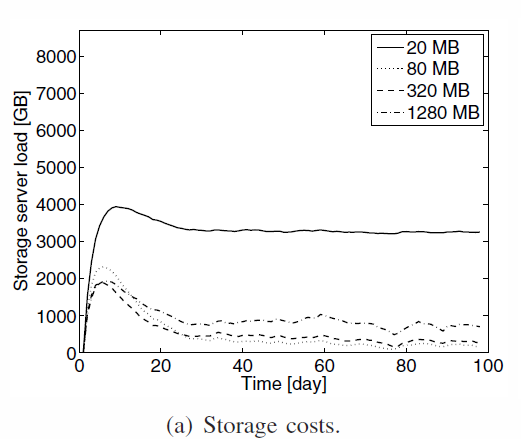
- Small fragments => more distinct peer to store data => higher cost
- Large fragments => long time to upload, more risks of interruption
(optimistic approach and random selection)
- Delicate choice
- Depends on bandwidth distribution, scheduling decision and redundancy
- Extremes are not good, find a value not too large, not too small
Results: performance of the system
Fragments size
Results: performance of the system
Scalability and heterogeneity
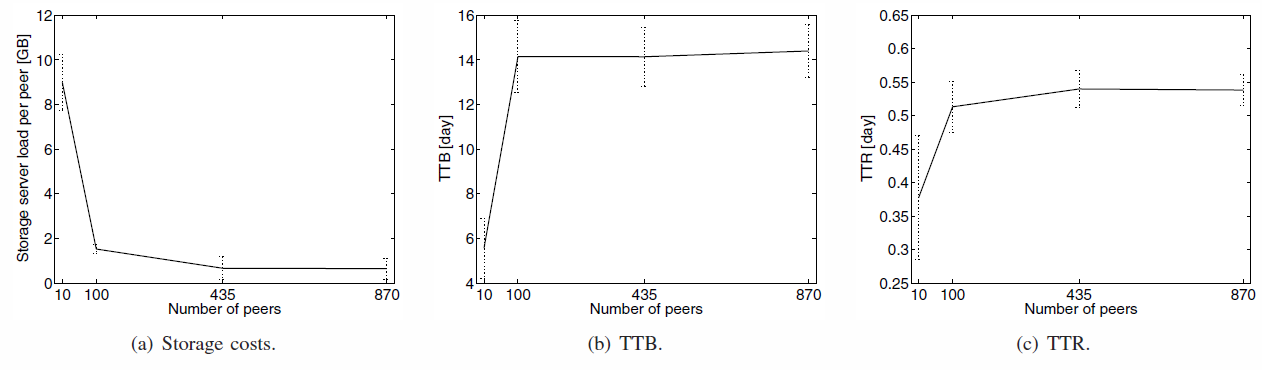
- Threshold on TTB and TTR as scale grows
- Costs decrease with the number of peers increasing : more peers to store data, less an the server
=> highly scalable, storage server prevents Bootstrap
Heterogeneity in peers' capacity is compensated by the server
Conclusion
- Mixing client-server architecture (low time to backup and restore) by avoiding the costs using peer-assisted design
- Cloud provider used temporarily
- Unfairness provided with a cost : higher cost for low available users
- Highly scalable, larger system implies lower costs
- Future work : study the effects of correlation in the online behavior of peers.
deck
By Adrien Duffy-coissard



