Tinkoff Python
Episode 5
Основы веб сервисов. Threads. GIL
WiFi
90599-55254
Вопросы по ДЗ?
В предыдущей серии
- Магия работы с сетью
- HTTP
- WSGI
План лекции
- Разработка веб сервисов на Flask
- Multithreading
- GIL

Почему Flask?
- Легко освоить
- Гибко настраивается
- Широко используется
- Идеален для микросервисов
, etc. ?
Основные принципы точно такие же, отличаются набором встроенных/подключаемых библиотек, интерфейсами, принципами организации приложиений

Simple server
# app.py
from flask import Flask
app = Flask(__name__)
@app.route('/')
def hello_world() -> str:
return 'Hello, World!'
Flask run
$ flask run
* Environment: production
WARNING: Do not use the development server in a production environment.
Use a production WSGI server instead.
* Debug mode: off
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
Запросы логгируются
$ flask run
* Environment: production
WARNING: Do not use the development server in a production environment.
Use a production WSGI server instead.
* Debug mode: off
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
127.0.0.1 - - [05/Mar/2019 15:45:07] "GET / HTTP/1.1" 200 -
Exception
# app.py
from flask import Flask
app = Flask(__name__)
@app.route('/')
def hello_world() -> str:
raise Exception('error')
[2019-03-05 15:39:19,658] ERROR in app: Exception on / [GET]
Traceback (most recent call last):
File ".../flask/app.py", line 2292, in wsgi_app
response = self.full_dispatch_request()
File ".../flask/app.py", line 1815, in full_dispatch_request
rv = self.handle_user_exception(e)
File ".../flask/app.py", line 1718, in handle_user_exception
reraise(exc_type, exc_value, tb)
File ".../flask/_compat.py", line 35, in reraise
raise value
File ".../flask/app.py", line 1813, in full_dispatch_request
rv = self.dispatch_request()
File ".../flask/app.py", line 1799, in dispatch_request
return self.view_functions[rule.endpoint](**req.view_args)
File "./app.py", line 7, in hello_world
raise Exception('error')
Exception: error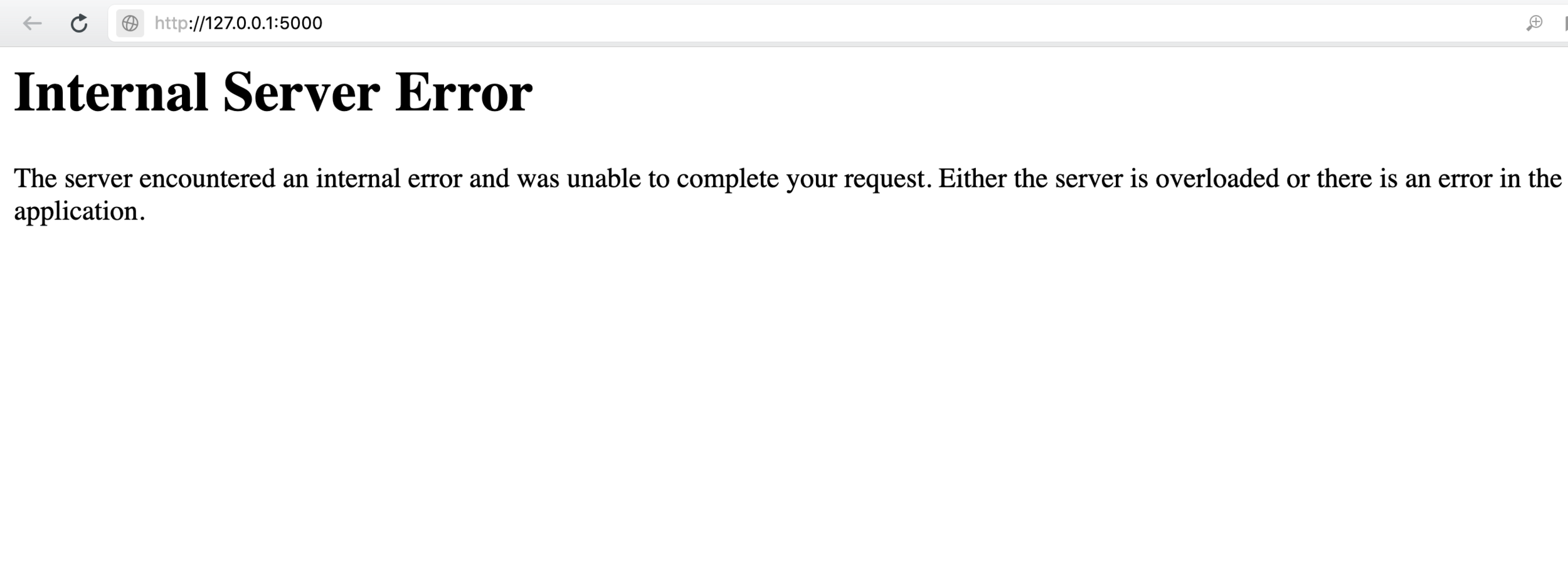
Почему?
HTTP status_code
500 Internal Server Error
Режим разработки
$ FLASK_ENV=development flask run
* Environment: development
* Debug mode: on
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
* Restarting with stat
* Debugger is active!
* Debugger PIN: 227-656-595
- Сервер автоматически перезапускается при изменении кода
- При получении ошибок, открывается debug форма
Exception
# app.py
from flask import Flask
app = Flask(__name__)
@app.route('/')
def hello_world() -> str:
raise Exception('error')
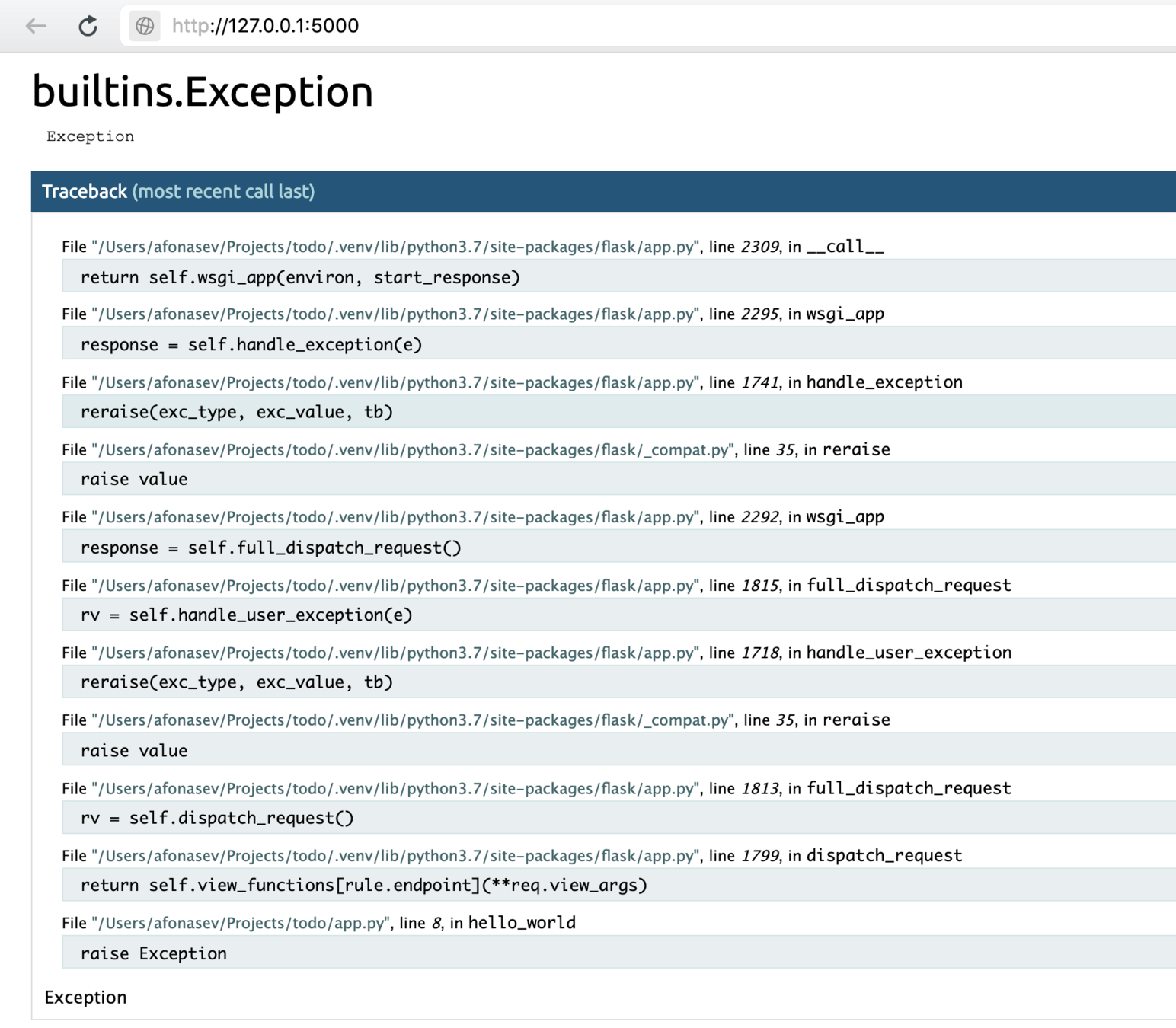
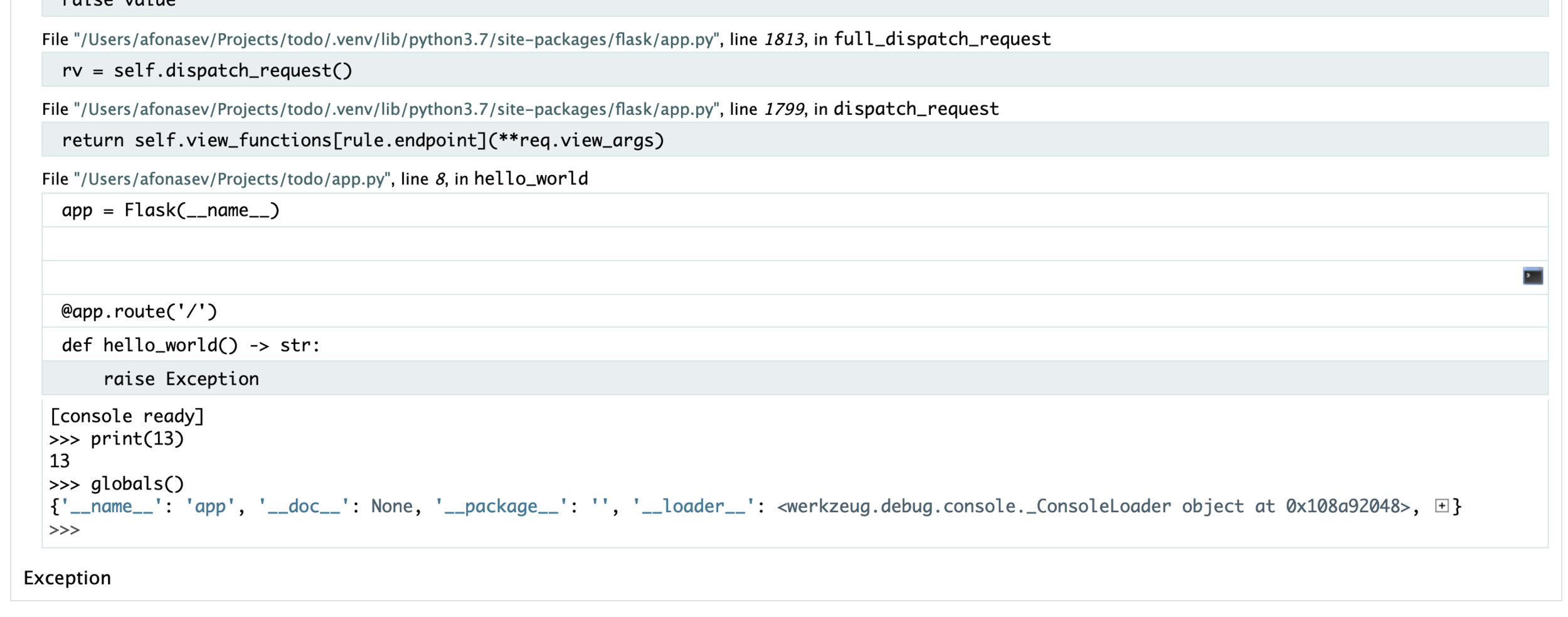
Удобная навигация по трейсбэку
Отладочная консоль (небезопасно!)
Как тестировать?
# server.py
from flask import Flask
app = Flask(__name__)
@app.route('/')
def hello_world() -> str:
return 'Hello, World!'
pytest-flask
import pytest
from server import app as server_app
@pytest.fixture
def app():
return server_app
def test_hello_world(client):
response = client.get('/hello_world')
assert response.status_code == 200
assert response.data.decode() == 'Hello, World!'
# server.py
from flask import Flask
app = Flask(__name__)
@app.route('/')
def hello_world() -> str:
return 'Hello, World!'
@app.route('/error')
def error() -> str:
raise Exception
Протестируем ошибки
def test_internal_error(client):
response = client.get('/error')
assert response.status_code == 500
def test_not_found(client):
response = client.get('/wrong_route')
assert response.status_code == 404
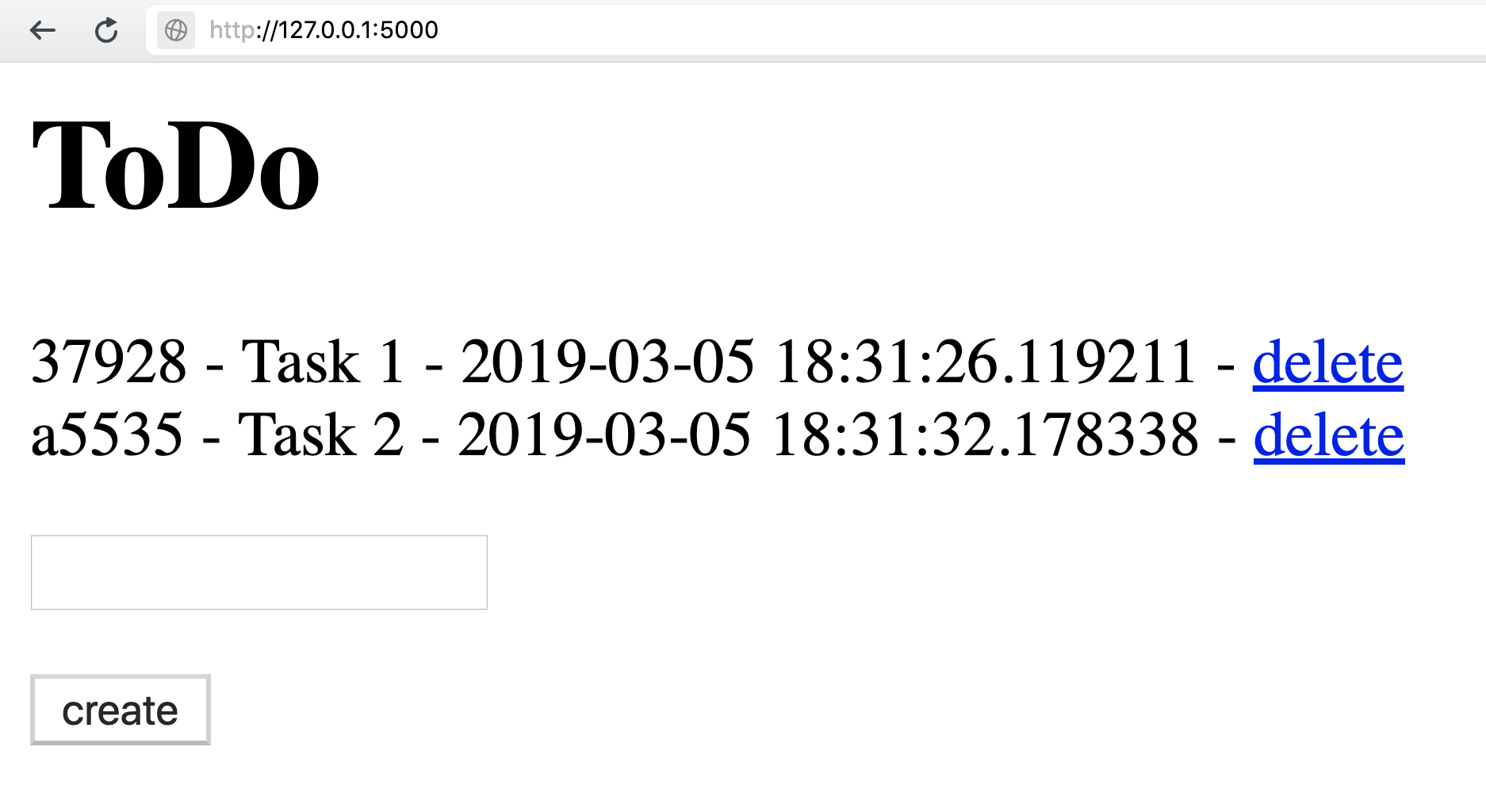
ToDO
task manager web service
Структура
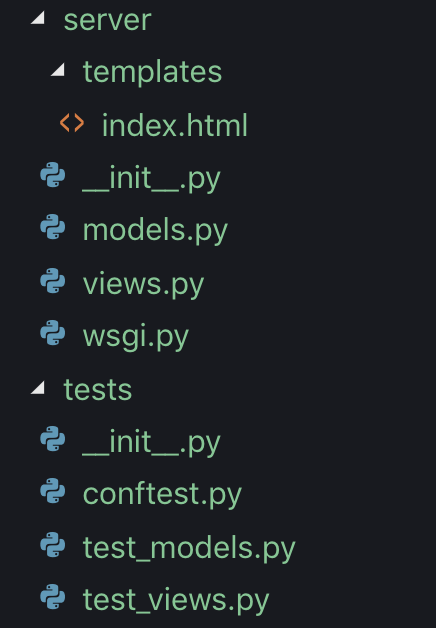
server/wsgi.py
# pylint: skip-file
from flask import Flask
app = Flask(__name__)
# register handlers
from .views import * # noqa isort:skip
test/conftest.py
import pytest
from server import wsgi
@pytest.fixture
def app():
return wsgi.app
server/models.py
from datetime import datetime
from typing import Dict, NamedTuple
from uuid import uuid4
class Task(NamedTuple):
id: str
description: str
created_at: datetime
# in memory storage
tasks: Dict[str, Task] = {}
def create_task(description: str) -> Task:
task = Task(
id=uuid4().hex, description=description, created_at=datetime.now()
)
tasks[task.id] = task
return task
def delete_task(task_id: str) -> None:
tasks.pop(task_id)
tests/test_models.py
from server.models import create_task, delete_task, tasks
def test_create_task():
task = create_task('very important task')
assert task.id in tasks
assert task.description == 'very important task'
assert task.created_at
def test_delete_task():
task = create_task('old task')
delete_task(task.id)
assert task.id not in tasks
tests/conftest.py
import pytest
from server import wsgi
from server.models import tasks
@pytest.fixture
def app():
return wsgi.app
# Добавим фикстуру для очистки данных между тестами
@pytest.fixture(autouse=True)
def clean_tasks():
yield
tasks.clear()
server/views.py
from flask import render_template
from .models import tasks, create_task, delete_task
from .wsgi import app
@app.route('/')
def index():
return render_template('index.html', tasks=tasks)
server/templates/index.html
<h1>ToDo</h1>
{% for task in tasks.values() %}
<tr>
<td>{{ task.id[:5] }}</td> -
<td>{{ task.description }}</td> -
<td>{{ task.created_at }}</td>
<br>
</tr>
{% endfor %}
<form action="/create" method="post">
<p><input type=text name=description>
<p><input type=submit value=create>
</form>
FLASK_ENV=development FLASK_APP=server.wsgi flask run
Запуск сервера
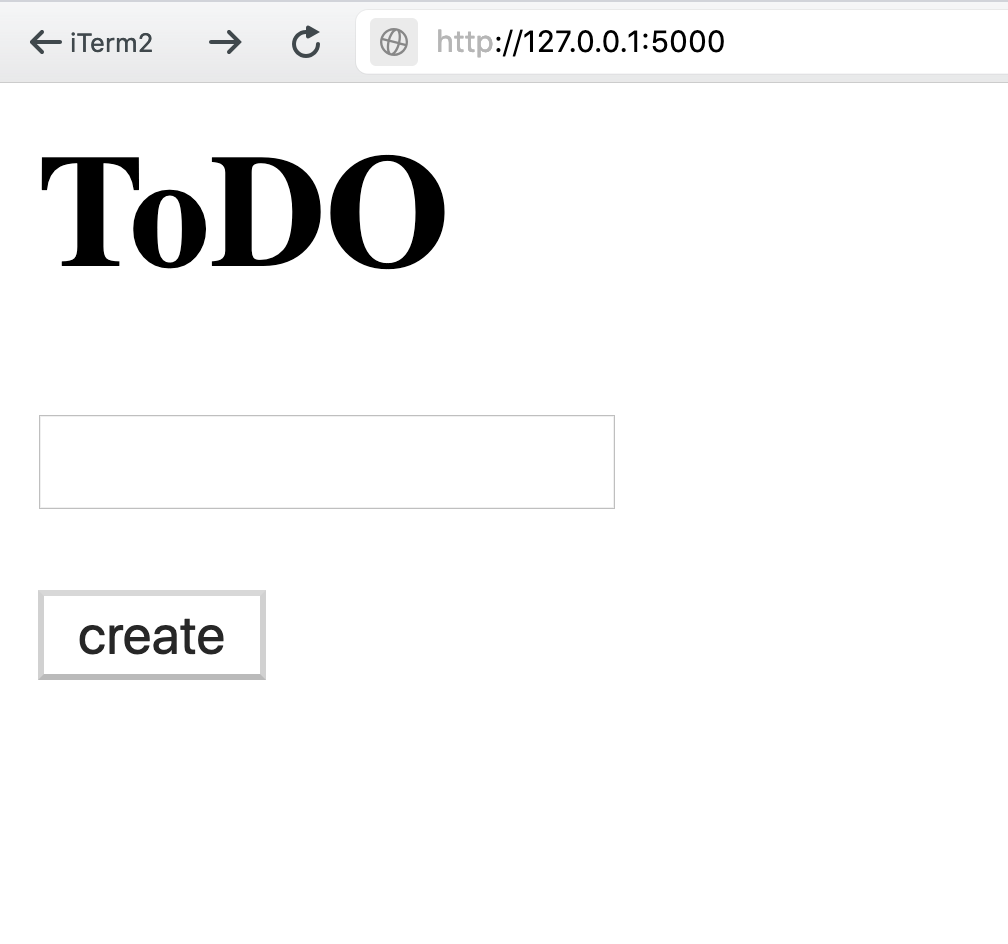
tests/test_views.py
from http import HTTPStatus
import pytest
from flask import url_for
from server.models import create_task
def test_index_without_tasks(client):
response = client.get(url_for('index'))
assert response.status_code == HTTPStatus.OK
assert '<h1>ToDo</h1>' in response.data.decode()
def test_index_with_tasks(client):
task = create_task('task')
response = client.get(url_for('index'))
assert response.status_code == HTTPStatus.OK
assert task.id[:5] in response.data.decode()
server/views.py
from flask import redirect, render_template, request, url_for
from .models import create_task, delete_task, tasks
from .wsgi import app
...
# напишем эндпоинт для создания задач
@app.route('/create', methods=['POST'])
def create():
description = request.form['description']
create_task(description)
return redirect(url_for('index'))
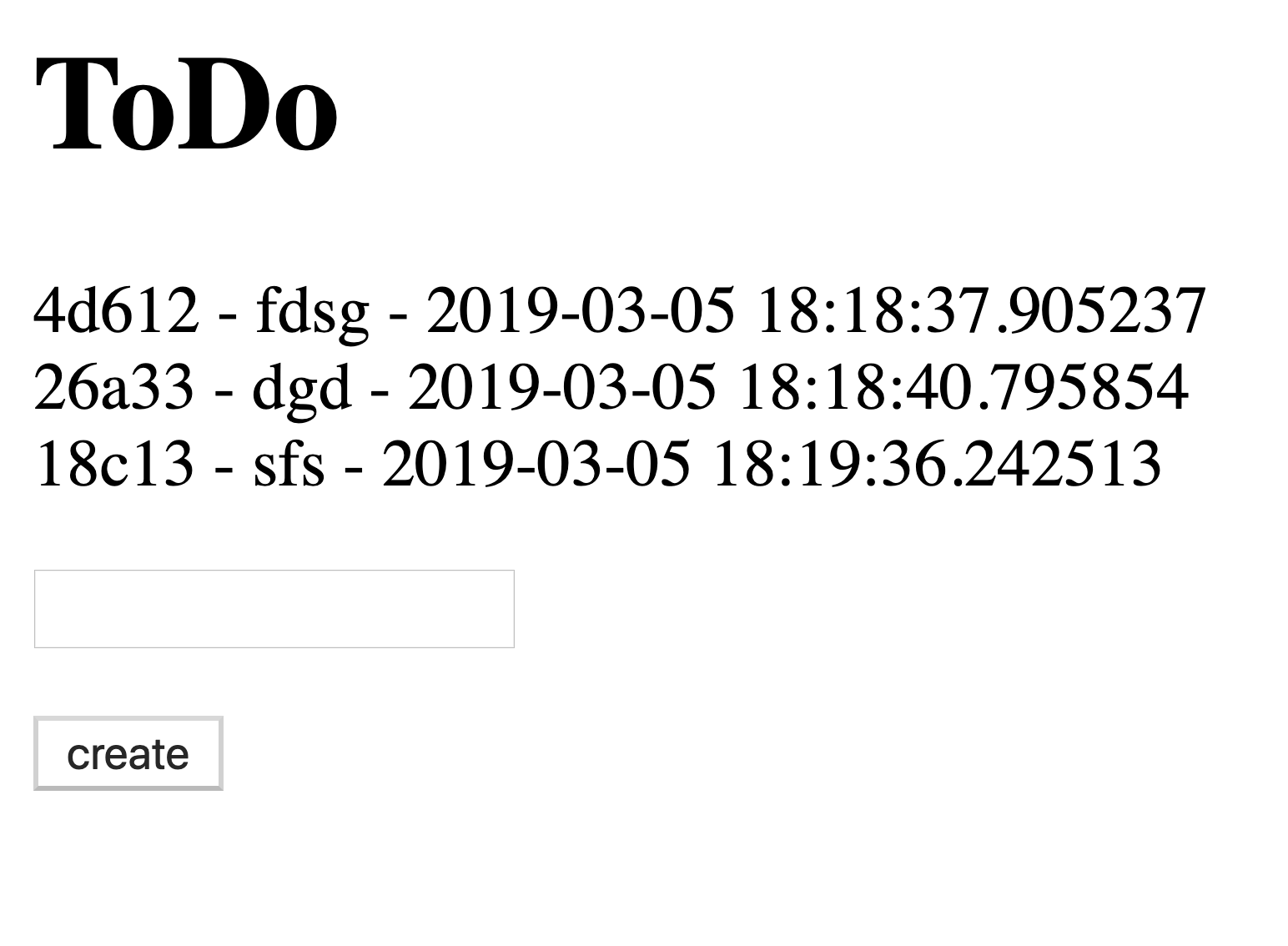
tests/test_views.py
from http import HTTPStatus
import pytest
from flask import url_for
from server.models import create_task
...
def test_create_task(client):
task_description = 'task_description'
response = client.post(
url_for('create'),
data={'description': 'task_description'},
follow_redirects=True,
)
assert response.status_code == HTTPStatus.OK
assert task_description in response.data.decode()
server/views.py
from http import HTTPStatus
import pytest
from flask import url_for
from server.models import create_task, delete_task
...
@app.route('/delete/<task_id>')
def delete(task_id):
delete_task(task_id)
return redirect(url_for('index'))
./index.html
<h1>ToDo</h1>
{% for task in tasks.values() %}
<tr>
<td>{{ task.id[:5] }}</td> -
<td>{{ task.description }}</td> -
<td>{{ task.created_at }}</td> -
<a href="/delete/{{ task.id }}"> delete </a>
<br>
</tr>
{% endfor %}
<form action="/create" method="post">
<p><input type=text name=description>
<p><input type=submit value=create>
</form>
tests/test_views.py
from http import HTTPStatus
import pytest
from flask import url_for
from server.models import create_task
...
def test_delete_task(client):
task = create_task('task')
response = client.get(
url_for('delete', task_id=task.id), follow_redirects=True
)
assert response.status_code == HTTPStatus.OK
assert task.id not in response.data.decode()
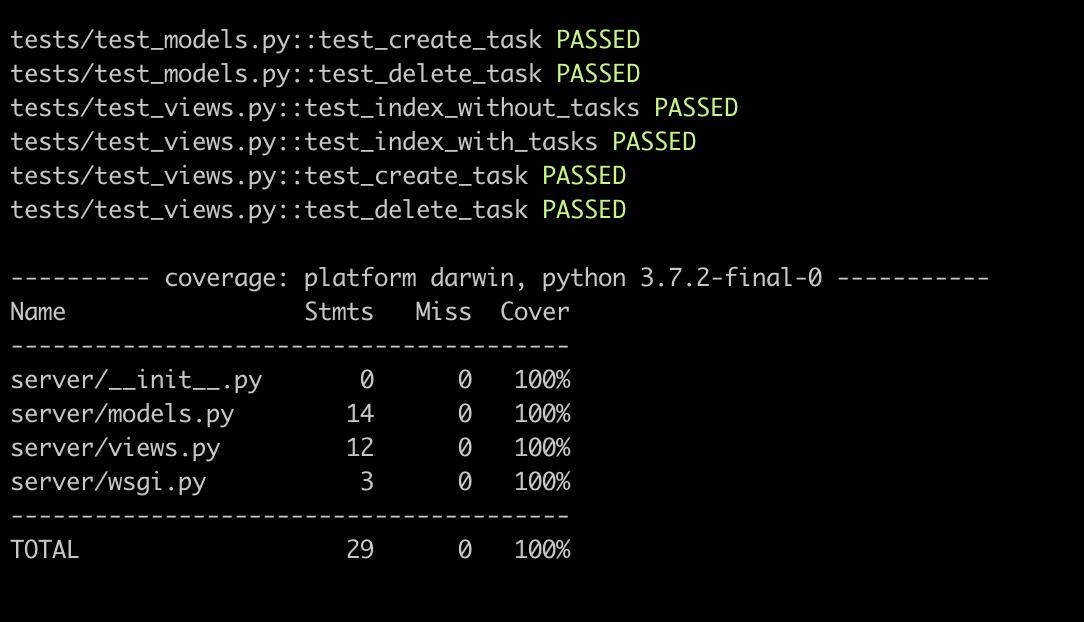
Но 100% coverage еще не значит, что мы проверили все!
Структура again
Валидация входных данных
- Должна осуществляться как можно раньше (зачастую во views)
- Никогда не доверяем данным от пользователя (injections, etc.)
- Это же касается приведения данных к нужным типам
Для валидации html форм отлично подходит WTF Forms

from flask_wtf import FlaskForm
from wtforms import StringField
from wtforms.validators import DataRequired
class MyForm(FlaskForm):
name = StringField('name', validators=[DataRequired()])
template = """
<form method="POST" action="/">
{{ form.hidden_tag() }}
{{ form.name.label }} {{ form.name(size=20) }}
<input type="submit" value="Go">
</form>
"""
@app.route('/submit', methods=('GET', 'POST'))
def submit():
form = MyForm()
if form.validate_on_submit():
return redirect('/success')
return render_template('submit.html', form=form)
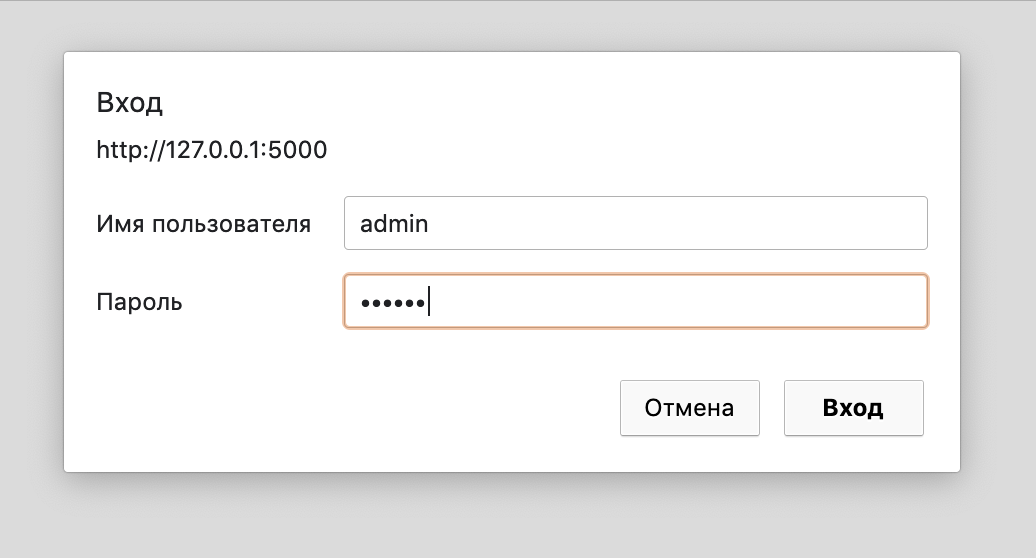
Basic Auth
def check_auth(username, password):
"""This function is called to check if a username /
password combination is valid.
"""
return username == 'admin' and password == 'secret'
def authenticate():
"""Sends a 401 response that enables basic auth"""
return Response(
'Could not verify your access level for that URL.\n'
'You have to login with proper credentials', 401,
{'WWW-Authenticate': 'Basic realm="Login Required"'})
def requires_auth(f):
@wraps(f)
def decorated(*args, **kwargs):
auth = request.authorization
if not auth or not check_auth(auth.username, auth.password):
return authenticate()
return f(*args, **kwargs)
return decorated
@app.route('/secret-page')
@requires_auth
def secret_page():
return render_template('secret_page.html')
Session Auth
from flask import Flask, session, redirect, url_for, escape, request
app = Flask(__name__)
# Set the secret key to some random bytes. Keep this really secret!
app.secret_key = b'_5#y2L"F4Q8z\n\xec]/'
@app.route('/')
def index():
if 'username' in session:
return 'Logged in as %s' % escape(session['username'])
return 'You are not logged in'
@app.route('/login', methods=['GET', 'POST'])
def login():
if request.method == 'POST':
session['username'] = request.form['username']
return redirect(url_for('index'))
return '''
<form method="post">
<p><input type=text name=username>
<p><input type=submit value=Login>
</form>
'''
@app.route('/logout')
def logout():
# remove the username from the session if it's there
session.pop('username', None)
return redirect(url_for('index'))Важно!
flask.session хранит данные на стороне клиента в открытом виде с криптографической подписью, т.е. позволяет на клиенте прочитать данные из сессии, но не позволяет их изменить.
А так же множество библиотек...
Static
Для раздачи статических файлов кладем их в пакет с сервером (например ./server/static/style.css)
и они будут доступны по адресу
127.0.0.1:5000/static/style.css
В продакшен системах статику обычно раздают отдельные приложения (nginx)
Перерыв?
flask run запускает сервер, который последовательно обслуживает запросы, один за другим
Медленные запросы
import time
@app.route('/')
def slow_route():
time.sleep(5)
return 'Hello!'
# три одновременных запроса
# будут выполняться в сумме 15 секундДля локальной разработки можно решить эту проблему флагом --with-threads
flask run --with-threads
В продакшене используются обычно специализированные веб сервера, e.g gunicorn
gunicorn --workers 4 myproject:app
Но, запустив ToDo сервер таким образом, мы столкнемся с тем, что данные постоянно то появляются, то пропадают

В чем же дело?
Можно решить так
gunicorn --workers 1 --threads 4 myproject:app
Процессы и потоки
Процесс
Проце́сс — программа, которая выполняется в текущий момент и обладает набором ресурсов:
- образом исполняемого машинного кода
- памятью
- дескрипторами ресурсов (файлов, сокетов)
- etc.
Процессы изолированы друг от друга операционной системой.
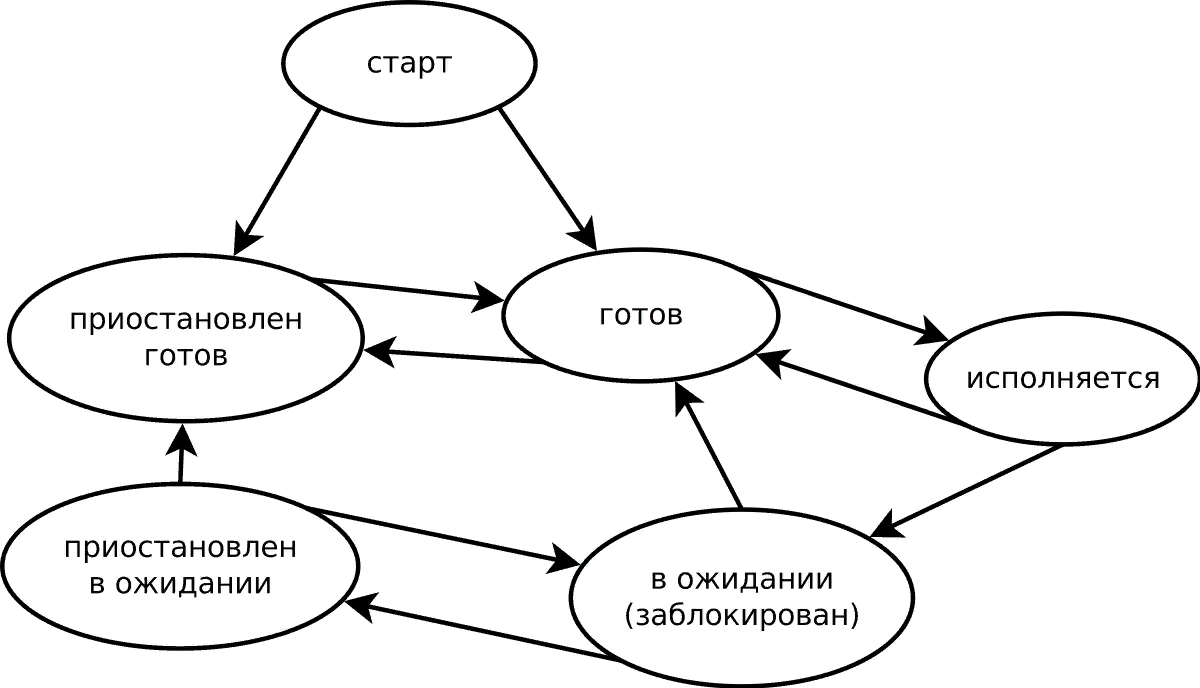
Процессы могут порождать новые процессы, для которых будут скопированы ресурсы текущего процесса (fork)
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main()
{
// make two process which run same
// program after this instruction
fork();
printf("Hello world!\n");
return 0;
}
// out:
// Hello world!
// Hello world!#include <stdio.h>
#include <sys/types.h>
int main()
{
fork();
fork();
fork();
printf("hello\n");
return 0;
}
/**
out:
hello
hello
hello
hello
hello
hello
hello
hello
**/Почему?
fork (); // Line 1
fork (); // Line 2
fork (); // Line 3
L1 // There will be 1 child process
/ \ // created by line 1.
L2 L2 // There will be 2 child processes
/ \ / \ // created by line 2
L3 L3 L3 L3 // There will be 4 child processes
// created by line 3#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
void forkexample()
{
int x = 1;
if (fork() == 0)
printf("Child has x = %d\n", ++x);
else
printf("Parent has x = %d\n", --x);
}
int main()
{
forkexample();
return 0;
}
Copy on Write
Идея подхода copy-on-write заключается в том, что при чтении области данных используется общая копия, в случае изменения данных — создается новая копия. Например таким образом новые процессы, порожденные вызовом fork в unix системах, не копируют сразу всю память родительского процесса.
Но для Python программ это не дает большого выигрыша! Интерпретатор постоянно создает и удаляет объекты, перезаписывая разные области памяти
Можно распараллелить работу, запустив несколько независимых процессов (multiprocessing), например запустив несколько экземпляров вашей программы
from multiprocessing import Process
import os
def info(title):
print(title)
print('module name:', __name__)
print('parent process:', os.getppid())
print('process id:', os.getpid())
def f(name):
info('function f')
print('hello', name)
if __name__ == '__main__':
info('main line')
p = Process(target=f, args=('bob',))
p.start()
p.join()from concurrent.futures import ProcessPoolExecutor
import math
PRIMES = [
112272535095293,
...
]
def is_prime(n):
if n % 2 == 0:
return False
return True
if __name__ == '__main__':
with ProcessPoolExecutor() as executor:
for result in executor.map(is_prime, PRIMES):
print(result)
Потоки (threads)
Пото́к выполне́ния - наименьшая единица обработки, исполнение которой может быть назначено ядром операционной системы.
Потоки являются частью процесса и имеют доступ к его ресурсам (например памяти), но имеют собственное состояние процессора (регистры) и стек вызовов.
В каждом процессе есть хотя бы 1 поток, обычно называемый "главным" (main thread)
В один момент времени 1 CPU выполняет только один поток, при этом ОС постоянно переключает исполняемые потоки, что создает иллюзию одновременной работы
Можно распараллелить работу, запустив несколько потоков в одном процессе (multithreading)
- Потоки более "легковесны" (можно создать больше)
- Быстрее стартуют
- Не требуют копирования памяти
- Не требуют сложных способов передачи данных между собой (так как работают с одной памятью)
import threading
def worker(num):
"""thread worker function"""
print 'Worker: %s' % num
return
threads = []
for i in range(5):
t = threading.Thread(target=worker, args=(i,))
threads.append(t)
t.start()
for t in threads:
t.join()
import concurrent.futures
import urllib.request
URLS = ['http://www.foxnews.com/', ...]
def load_url(url, timeout):
with urllib.request.urlopen(url, timeout=timeout) as conn:
return conn.read()
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
futures = {executor.submit(load_url, url, 60) for url in URLS}
for future in futures:
print(future.result())
Race conditions
# Thread 1 and Thread 2 are executing in different processes at the same time
# For purposes of illustration, they're placed side by side here
# They're vertically spaced to show what code is executing at each point in time
# Thread 1 # Thread 2
def increment():
def increment():
# get_count returns 0
count = db.get_count()
# get_count returns 0 again
count = db.get_count()
new_count = count + 1
# set_count called with 1
db.set_count(new_count)
new_count = count + 1
# set_count called with 1 again
db.set_count(new_count)Race conditions
# Thread 1 # Thread 2
def increment():
# get_count returns 0
count = db.get_count()
def increment():
# get_count returns 0 again
count = db.get_count()
# set_count called with 1
new_count = count + 1
db.set_count(new_count)
# set_count called with 1 again
new_count = count + 1
db.set_count(new_count)
from threading import Lock
lock = Lock()
data = {}
def func(key, value):
with lock:
if key not in data:
data[key] = value
Используем примитивы синхронизации
Thread safe
Код и коллекции, которые могут корректно работать/обрабатываться в нескольких тредах одновременно
Deadlock
from threading import Lock
lock_a = Lock()
lock_b = Lock()
data = {}
def func_a():
with lock_a:
with lock_b:
pass
def func_b():
with lock_b:
with lock_a:
pass
Но если мы попробуем распараллелить какие-то математические вычисления, мы заметим, что общее время выполнения не только не уменьшилось, но и увеличилось

GIL - Global Interpreter Lock
case TARGET(LOAD_CONST): {
PREDICTED(LOAD_CONST);
PyObject *value = GETITEM(consts, oparg);
Py_INCREF(value);
PUSH(value);
FAST_DISPATCH();
}
GIL — это блокировка, которая обязательно должна быть взята перед любым обращением к Питону (а это не только исполнение питоновского кода, а еще и вызовы Python C API).
Зачем нужен GIL?
Он не позволяет "сломать" состояние интерпретатора одновременным изменением внутренних структур или объектов из разных потоков. Код интерпретатора не thread safe.
Почему изначально решили его использовать?
- Упрощает написание интерпретатора (например сборки мусора на основе подсчета ссылок)
- Позволяет минимизировать overhead для однопоточных программ, так как отдельные структуры не имеют своих собственных блокировок.
Как же работает GIL?
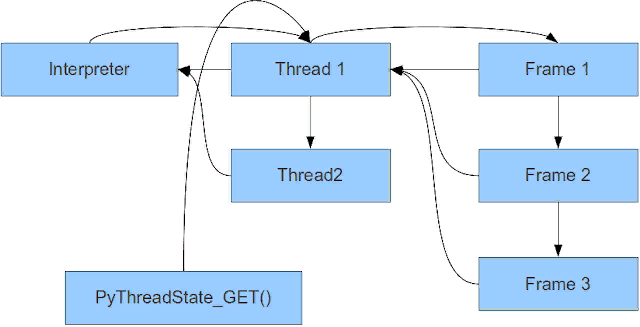
Как представлены потоки в интерпретаторе?
struct PyInterpreterState {
PyInterpreterState *next;
PyThreadState *tstate_head;
PyObject *modules;
PyObject *sysdict;
PyObject *builtins;
PyObject *modules_reloading;
PyObject *codec_search_path;
PyObject *codec_search_cache;
PyObject *codec_error_registry;
};struct PyThreadState {
PyThreadState *next;
PyInterpreterState *interp;
PyFrameObject *frame;
int recursion_depth;
Py_tracefunc c_profilefunc;
Py_tracefunc c_tracefunc;
PyObject *c_profileobj;
PyObject *c_traceobj;
PyObject *exc_type;
PyObject *exc_value;
PyObject *exc_traceback;
PyObject *dict; /* Stores per-thread state */
long thread_id;
};struct PyFrameObject {
PyObject_VAR_HEAD
PyFrameObject *f_back; /* previous frame, or NULL */
PyCodeObject *f_code; /* code segment */
PyObject *f_builtins; /* builtin symbol table (PyDictObject) */
PyObject *f_globals; /* global symbol table (PyDictObject) */
PyObject *f_locals; /* local symbol table (any mapping) */
PyThreadState *f_tstate;
int f_lasti; /* Last instruction if called */
};Frame — объект кадра стека
PyObject *
PyEval_EvalFrameEx(PyFrameObject *f, int throwflag)
{
PyThreadState *tstate = PyThreadState_GET();
/* ... */
for (;;) {
/* ... */
if (_Py_atomic_load_relaxed(&eval_breaker)) {
/* ... */
if (_Py_atomic_load_relaxed(&gil_drop_request)) {
/* Give another thread a chance */
if (PyThreadState_Swap(NULL) != tstate)
Py_FatalError("ceval: tstate mix-up");
drop_gil(tstate);
/* Other threads may run now */
take_gil(tstate);
if (PyThreadState_Swap(tstate) != NULL)
Py_FatalError("ceval: orphan tstate");
}
}
/* instruction processing */
}
}Гил может переключиться между обработками opcode`ов
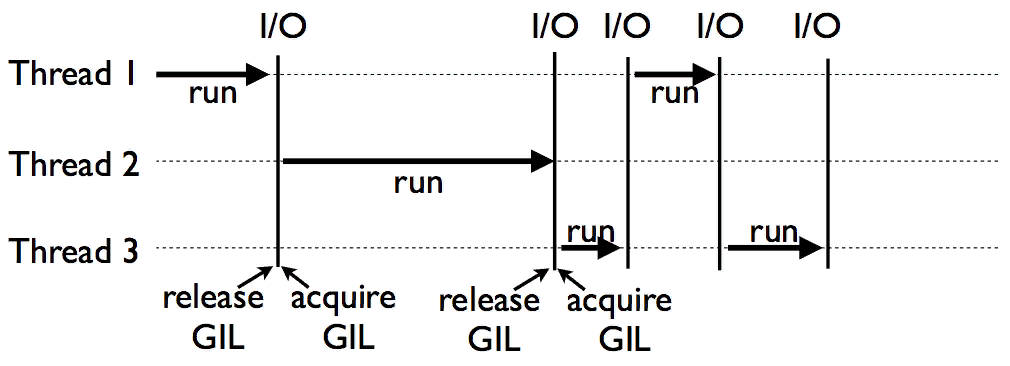
В Python3 поток отпускает GIL через 5мс, если есть другие потоки, ожидающие освобождения
Также GIL отпускается перед системными вызовами. Чтение из файла, к примеру, может занимать длительное время и совершенно не требует GIL — можно дать шанс другим потокам поработать
В итоге:
- поток, владеющий GIL, не отдает его пока об этом не попросят.
- если уж отдал по просьбе, то подождет окончания переключения и не будет сразу же пытаться захватить GIL назад.
- поток, у которого сразу не получилось захватить GIL, сначала выждет 5 мс и лишь потом пошлет запрос на переключение, принуждая текущего владельца освободить ценный ресурс. Таким образом переключение осуществляется не чаще чем раз в 5 мс, если только владелец не отдаст GIL добровольно перед выполнением системного вызова.
Вывод, когда использовать потоки, а когда процессы?
- Для IO bound (web, crawlers) приложений потоки отлично работают
- Для CPU bound (math, image processing) используем процессы или специальные C extension (numpy), которые умеют параллелиться без GIL
- В вебе почти всегда комбинация обоих вариантов, т.е. N процессов и в каждом M тредов
Homework
Каталог клиентов с возможностью добавления, поиска, фильтрации
Усложнение 1: добавить возможность сохранять и просматривать в реестре аватарки клиентов
Усложнение 2: Добавить регистрацию/аутентификацию пользователей, для каждого пользователя свой каталог. Пользователи не должны иметь доступа к каталогам другим пользователей
Вопросы?
Tinkoff Python 5
By Afonasev Evgeniy



