Tinkoff Python
Episode 9
Асинхронный web
WIFI
96790-49282
В предыдущей серии...
Синхронный и асинхронный
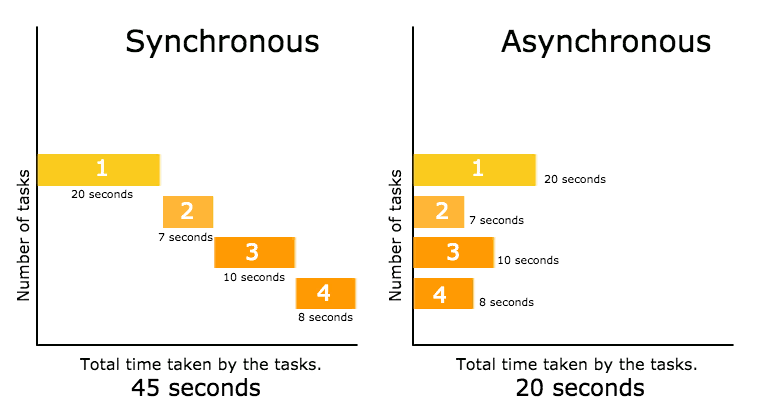
В синхронных операциях задачи выполняются друг за другом.
В асинхронных задачи могут запускаться и завершаться независимо друг от друга.
Асинхронные задачи не блокируют (не заставляют ждать завершения выполнения задачи) поток и обычно выполняются в фоновом режиме.
Non-Blocking
import threading
import time
import random
def worker(number):
sleep = random.randrange(1, 10)
time.sleep(sleep)
print("I am Worker {}, I slept for {} seconds".format(number, sleep))
for i in range(5):
t = threading.Thread(target=worker, args=(i,))
t.start()
print("All Threads are queued, let's see when they finish!")Threads
Проблемы синхронных вебсерверов

Долгие IO операции при выполнении http запросов
Если запрос выполняются 1 секунду, то мы не можем обрабатывать больше запросов чем кол-во наших потоков в секунду, а потоки не бесплатны.
Если мы хотим держать постоянное соединение (longpolling, ws, etc.), то нам потребуется отдельный поток на каждого клиента
Современное железо может поддерживать работу огромного кол-ва одновременных потоков, но требования по нагрузке зачастую растут намного быстрее
Потоки не бесплатны!
ОС переключает выполняемые ядром потоки очень часто, что приводит к большому кол-ву дорогих переключений контекста, вместо того, чтобы переключать контекст только тогда, когда это нужно
Потоки не бесплатны!
Не актуально
10M connections problem !!!

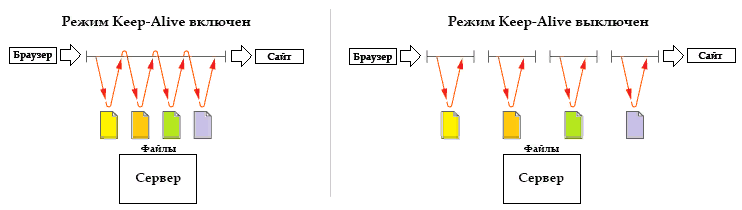
Зачем в web нужны постоянно поддерживаемые коннекты?
Установка соединения сравнительно долгая операция
Обычно можно решить с помощью keep-alive и асинхронного прокси (nginx) перед веб сервером.
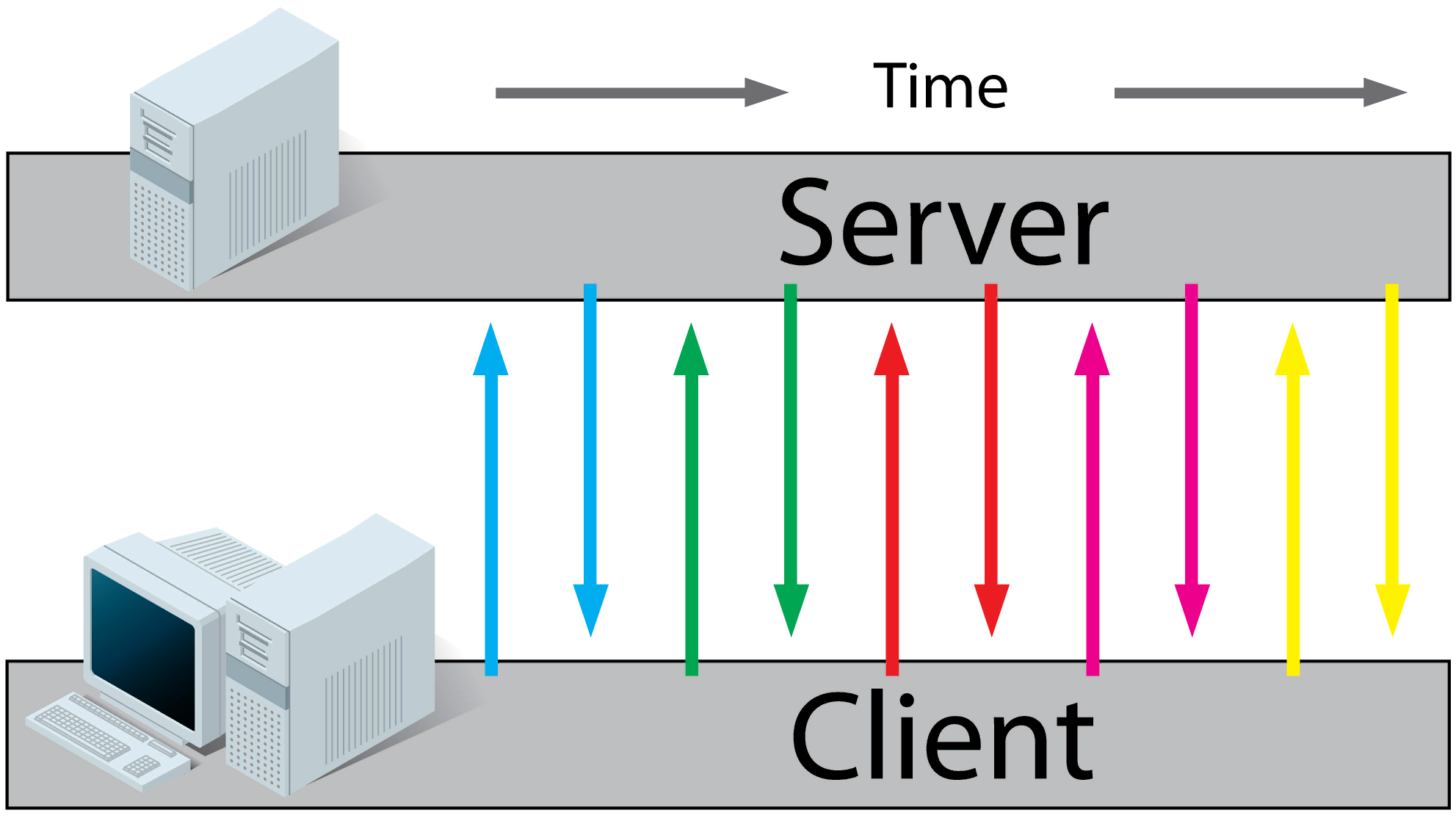
Нужно отправлять события от сервера клиенту
- polling
- longpolling
- websocket
- server-side events (SSE)
polling
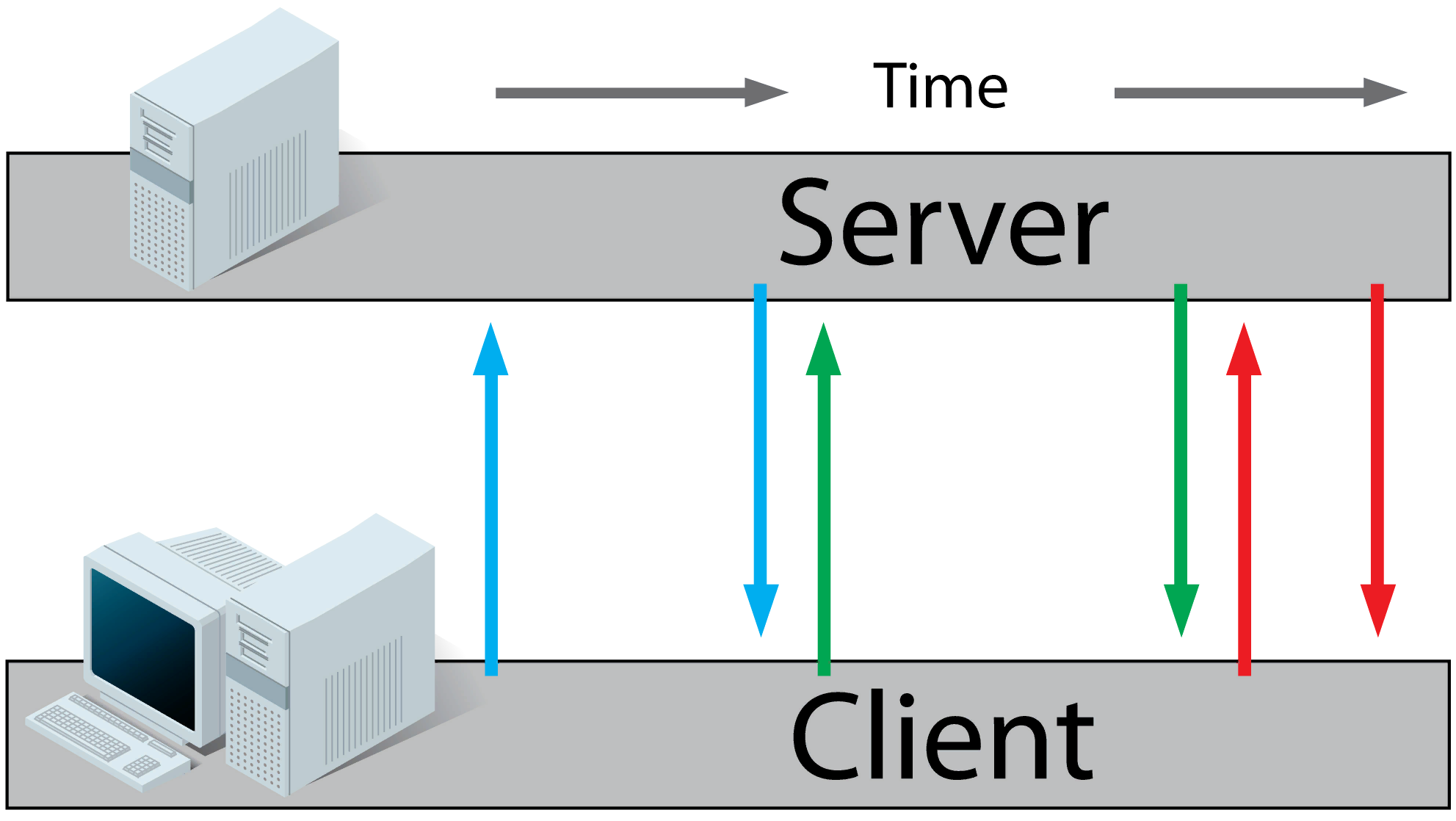
longpolling
websockets
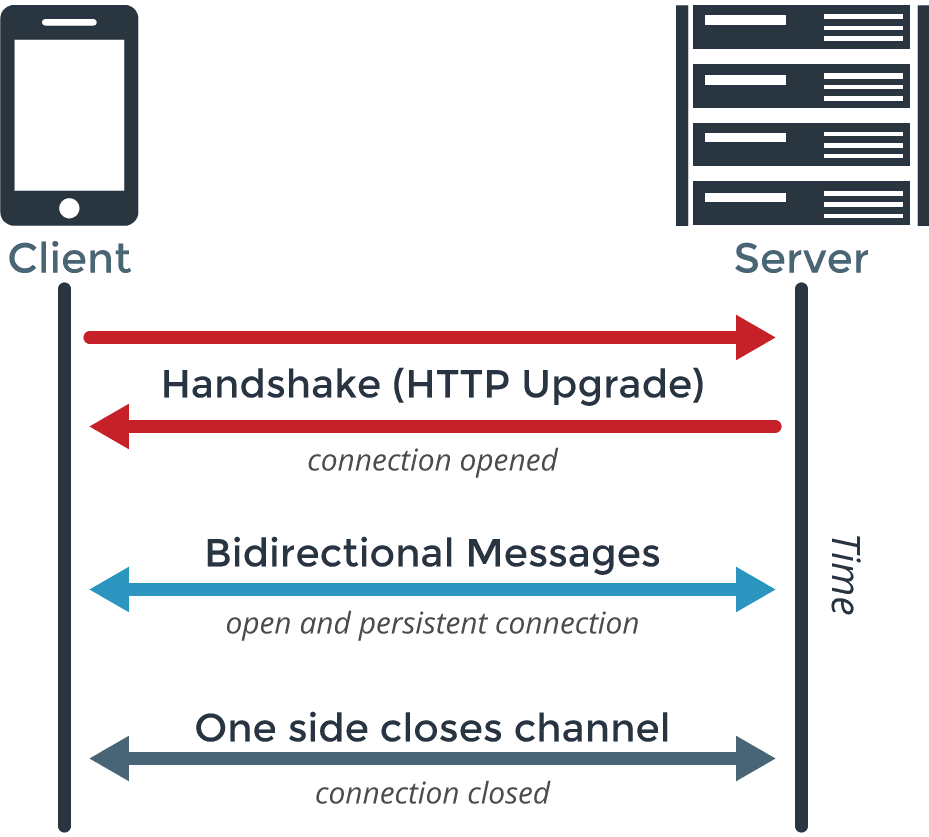
server-side events

Удобен вместе с http2 и rest api
server-side events
non-blocking socket
Если в буфере нет ответа, сразу отдает специальный ответ и не блокирует поток выполнения. Результат можно будет получить позднее.
select/poll/epoll
Команды ядра ОС, позволяющие осуществлять неблокирующий IO
Эти методы позволяют после вызова неблокирующих IO операций, асинхронно ждать ответа и наблюдать за состоянием дескриптора
Poll
// два события
struct pollfd fds[2];
// от sock1 мы будем ожидать входящих данных
fds[0].fd = sock1;
fds[0].events = POLLIN;
// а от sock2 - исходящих
fds[1].fd = sock2;
fds[1].events = POLLOUT;
// ждём до 10 секунд
int ret = poll( &fds, 2, 10000 );
// проверяем успешность вызова
if ( ret == -1 )
// ошибка
else if ( ret == 0 )
// таймаут, событий не произошло
else
{
// обнаружили событие, обнулим revents чтобы можно было переиспользовать структуру
if ( pfd[0].revents & POLLIN )
pfd[0].revents = 0;
// обработка входных данных от sock1
if ( pfd[1].revents & POLLOUT )
pfd[1].revents = 0;
// обработка исходящих данных от sock2
}
Абстракция над асинхронными методами обработки дескрипторов. Решает проблему мультиплатформенности
import selectors
import socket
sel = selectors.DefaultSelector()
def accept(sock, mask):
conn, addr = sock.accept() # Should be ready
print('accepted', conn, 'from', addr)
conn.setblocking(False)
sel.register(conn, selectors.EVENT_READ, read)
def read(conn, mask):
data = conn.recv(1000) # Should be ready
if data:
print('echoing', repr(data), 'to', conn)
conn.send(data) # Hope it won't block
else:
print('closing', conn)
sel.unregister(conn)
conn.close()
sock = socket.socket()
sock.bind(('localhost', 1234))
sock.listen(100)
sock.setblocking(False)
sel.register(sock, selectors.EVENT_READ, accept)
while True:
events = sel.select()
for key, mask in events:
callback = key.data
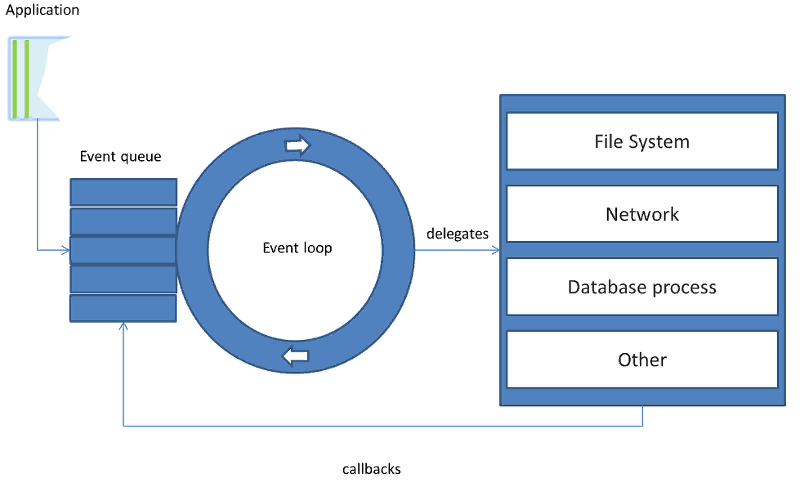
callback(key.fileobj, mask)event loop (reactor)
Цикл, который проверяет состояние дескрипторов
Перерыв?
История асинхронного IO в python (не в хронологическом порядке)
Callbacks
twisted
from twisted.web import server, resource
from twisted.internet import reactor, endpoints
class Counter(resource.Resource):
isLeaf = True
numberRequests = 0
def render_GET(self, request):
self.numberRequests += 1
request.setHeader(b"content-type", b"text/plain")
content = u"I am request #{}\n".format(self.numberRequests)
return content.encode("ascii")
server = endpoints.serverFromString(reactor, "tcp:8080")
server.listen(server.Site(Counter()))
reactor.run()twisted
from twisted.web.resource import Resource
from twisted.web import server
from twisted.internet import reactor
from twisted.python.util import println
class ExampleResource(Resource):
def render_GET(self, request):
request.write("hello world")
d = request.notifyFinish()
d.addCallback(lambda _: println("finished normally"))
d.addErrback(println, "error")
reactor.callLater(10, request.finish)
return server.NOT_DONE_YET
resource = ExampleResource()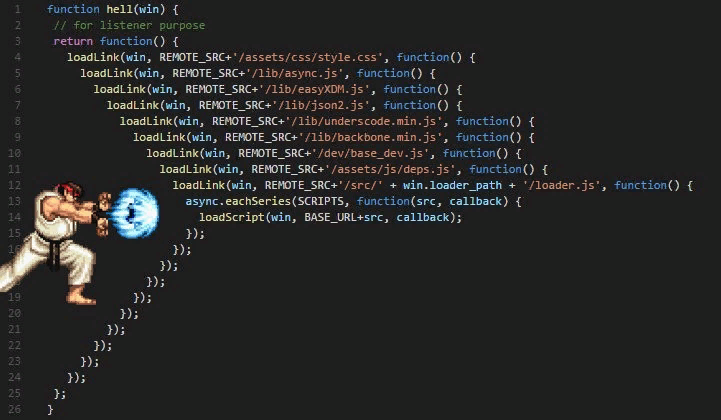
Callback hell
Callbacks problems
- callback hell
- код сложнее читать
- traceback`и и отладка усложняется
- нужно таскать контекст с переменными между колбэками
twisted
from __future__ import print_function
import sys
from twisted.internet import protocol, defer, endpoints, task
from twisted.mail import imap4
from twisted.python import failure
@defer.inlineCallbacks
def main(reactor, username=b"alice", password=b"secret",
strport="tls:example.com:993"):
endpoint = endpoints.clientFromString(reactor, strport)
factory = protocol.Factory.forProtocol(imap4.IMAP4Client)
try:
client = yield endpoint.connect(factory)
yield client.login(username, password)
yield client.select('INBOX')
info = yield client.fetchEnvelope(imap4.MessageSet(1))
print('First message subject:', info[1]['ENVELOPE'][1])
except:
print("IMAP4 client interaction failed")
failure.Failure().printTraceback()
task.react(main, sys.argv[1:])Coroutine
Сопрограммы (англ. coroutines) — методика связи программных модулей друг с другом по принципу кооперативной многозадачности: модуль приостанавливается в определённой точке, сохраняя полное состояние (включая стек вызовов и счётчик команд), и передаёт управление другому. Тот, в свою очередь, выполняет задачу и передаёт управление обратно, сохраняя свои стек и счётчик.
class GenAsyncHandler(RequestHandler):
@gen.coroutine
def get(self):
http_client = AsyncHTTPClient()
response = yield http_client.fetch("http://example.com")
do_something_with_response(response)
self.render("template.html")Корутина должна возвращать специальный объект Future, который является представлением отложенного результата. Его можно проверять на состояние выполнения (завершен/не завершен), ошибки, или получить результат, если выполнение завершено.
Coroutine
Event loop получает из стэка вложенных генераторов future, берет результат, когда он будет готов, и отправляет его внутрь генератора (.send) для последующего выполнения
Важно!
- Корутинами нужно делать только те функции, которые будут делать неблокирующее IO
- Код без IO пишем как обычно
- Если сделать блокирующую IO операцию в корутине event loop "встанет"
- Операции IO, которые нельзя сделать неблокирующими, вызываем в отдельных потоках (например работа с файлами)
green threads
Зеленый поток — это обычный поток, за исключением того, что переключения между потоками производятся в коде приложения (user space), а не в ядре (kernel space)

import eventlet
from eventlet.green import urllib2
urls = [
"http://www.google.com/intl/en_ALL/images/logo.gif",
"https://wiki.secondlife.com/w/images/secondlife.jpg",
"http://us.i1.yimg.com/us.yimg.com/i/ww/beta/y3.gif",
]
def fetch(url):
return urllib2.urlopen(url).read()
pool = eventlet.GreenPool()
for body in pool.imap(fetch, urls):
print("got body", len(body))
Monkey patching

import gevent.monkey
from urllib.request import urlopen
gevent.monkey.patch_all()
urls = ['http://www.google.com', 'http://www.yandex.ru']
def print_head(url):
print('Starting {}'.format(url))
data = urlopen(url).read()
print('{}: {} bytes: {}'.format(url, len(data), data))
jobs = [gevent.spawn(print_head, _url) for _url in urls]
gevent.wait(jobs)Gevent problems
- Не стал стандартном
- Не любой код можно патчами сделать асинхронным без доработок
- Неявность усложняет отладку и понимание происходящих в программе вещей
import asyncio
import datetime
import random
async def my_sleep_func():
await asyncio.sleep(random.randint(0, 5))
async def display_date(num, loop):
end_time = loop.time() + 50.0
while True:
print("Loop: {} Time: {}".format(num, datetime.datetime.now()))
if (loop.time() + 1.0) >= end_time:
break
await my_sleep_func()
loop = asyncio.get_event_loop()
asyncio.ensure_future(display_date(1, loop))
asyncio.ensure_future(display_date(2, loop))
loop.run_forever()
yield from позволяет прозрачное двустороннее взаимодействие между вложенным генератором и вызывающим кодом.

Итоги:
+ Асинхронное IO позволяет нам иметь намного больше одновременных соединений, чем потоки ОС.
+ Можно делать множество сетевых вызовов во время обработки http запросов
- Писать асинхронный код сложнее (можно заблокировать loop)
- Нужно писать новые библиотеки/фрэймворки для работы с асинхронным IO
- Во многих случаях выигрыш от перехода может быть несущественен
Серебряной пули нет
Асинхронные фрэймворки не сделают ваш код автоматически быстрым и могут больно выстрелить в ногу, если не понимать, что у них под капотом

Применять, когда в коде много (очень много!!!) медленных сетевых IO операций или нужна обработка длительных соединений (ws, longpoling, sse)
Ну, или если просто "хочется" =)
Курсовая =)

Вопросы?

Tinkoff Python 9
By Afonasev Evgeniy



