Run faster Python
MYSELF

Python, Rust, Zig
Tech Blog
Short Stories Writer
Sr Data Engineer @ Singaporean Bank
Twitter Handle
Why Python is Slow ?
Reasons - CPython
- Syntax is parsed, compiled to bytecode and then runs in the VM
- Garbage collection to deallocate objects with zero references
- Types are tagged to objects and there are various sanity checks before the operation is performed. Ex: 1+"1" errors before operation
- In multi-thread environment python makes sure only one thread is running all the time because VM isn't threadsafe i.e, two threads operating on object's reference count is not thread safe. Ref
Use Zig/C to bypass cpython restrictions
- Just run the machine code in runtime period.
- NO VM as it's simply Zig
- NO locking of threads, one thread waits for the external zig program to return a value, another thread can keep running simultaneously. Ref
- NO automatic memory management
- NO housekeeping tasks like garbage collector
Benefits - Zig/C and Cpython


Python
C


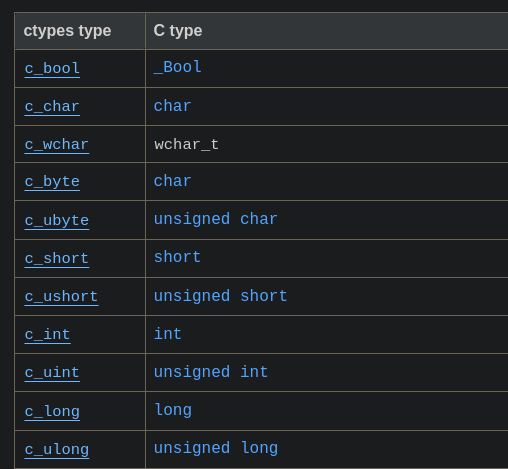
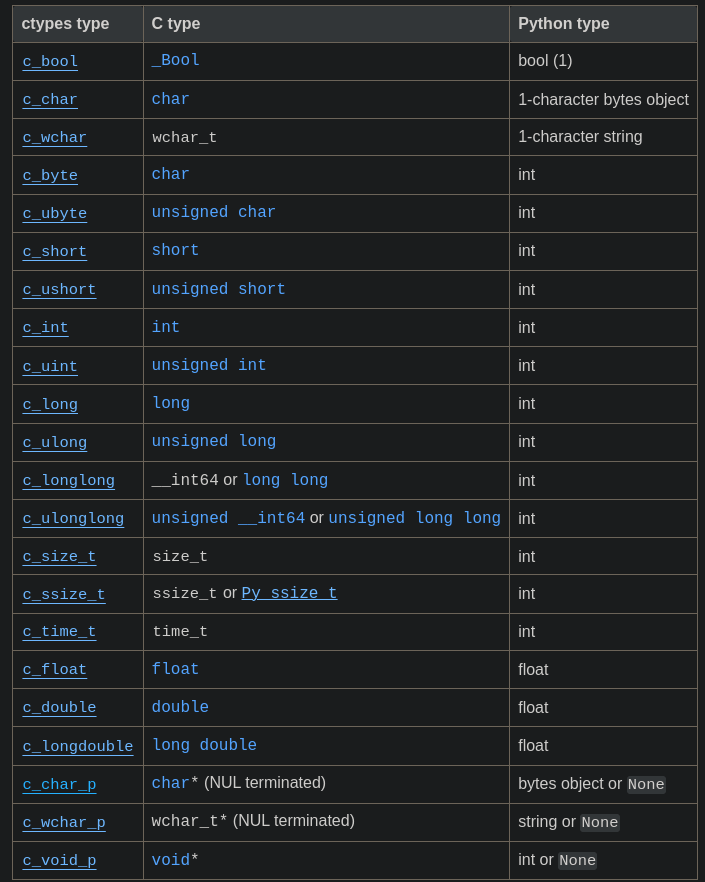
What are ctypes ?
- It's python module offering c like data types and calls functions from C-ABI compatible shared libraries created using any language
Let's understand with few examples


Addition of Integers
add.c
add.py
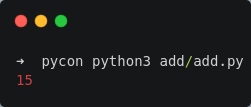
result
String Concatenation

concat.c

concat_c.py
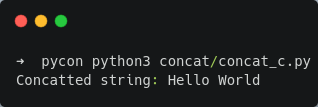
Result
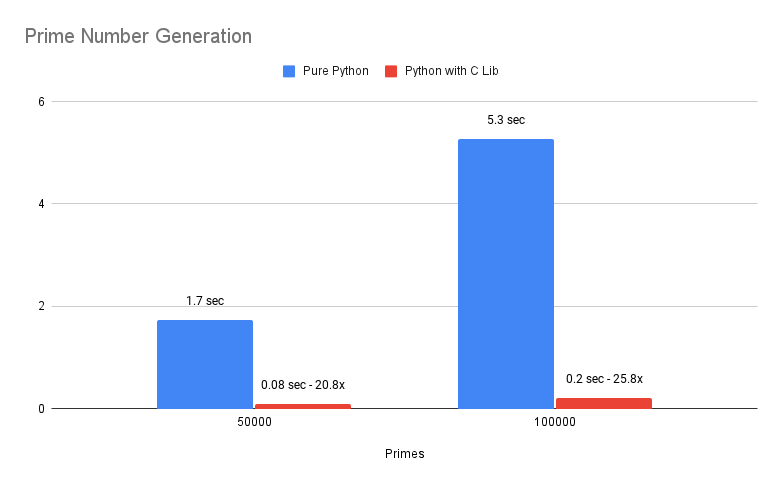
Prime Number Generation Performance
- Calculate first 50,000 and 1,00,000 primes in Pure Python and C lib interfaced Python

prime.c
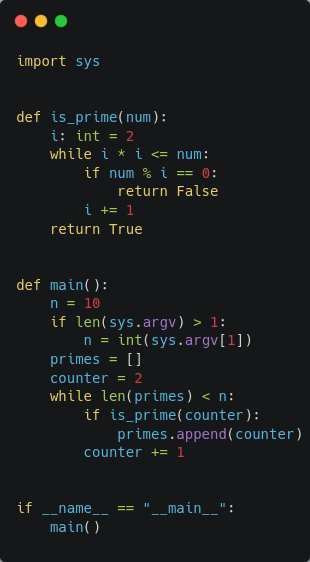
prime.py
Prime Number Generation Performance
Let's build the fastest LLM tokenizer library using ctypes
What's LLM Tokenizer
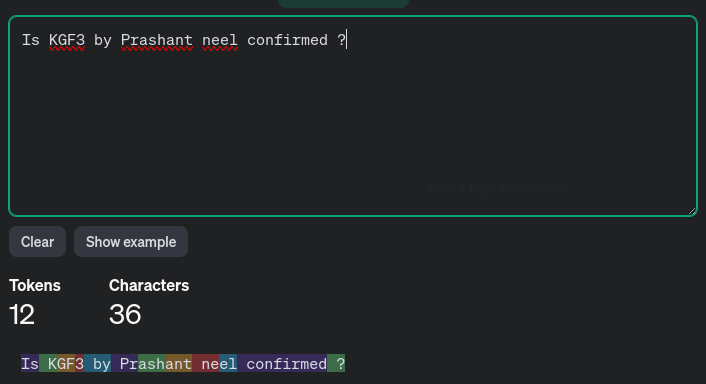
[3957, 735, 37432, 18, 555, 2394, 1003, 519, 841, 301, 11007, 949]
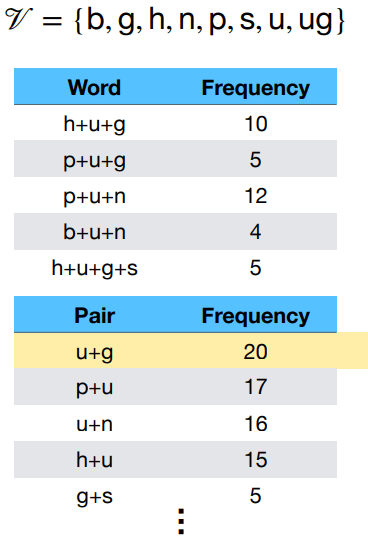
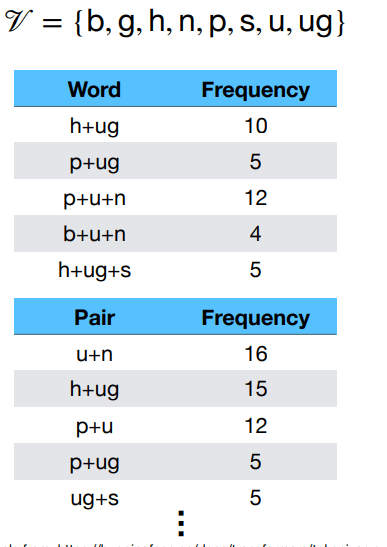
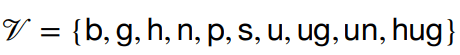
Tokenizer Explaination - BPE
LLM Tokenizer Lib Signature
Note: size param in token_ranker is length of name string

LLM Tokenizer Lib Signature - Details
- There are two functions one to initialise the tokenizer and other is to encode the text
- token_ranker function receives name of the tokenizer as parameter, initialises the tokenizer and return the pointer to tokenizer in memory.
- encode function receives tokenizer pointer as context, text to be encoded and size pointer will point to the value of number of generated tokens. The function will return a pointer to sequence of tokens.
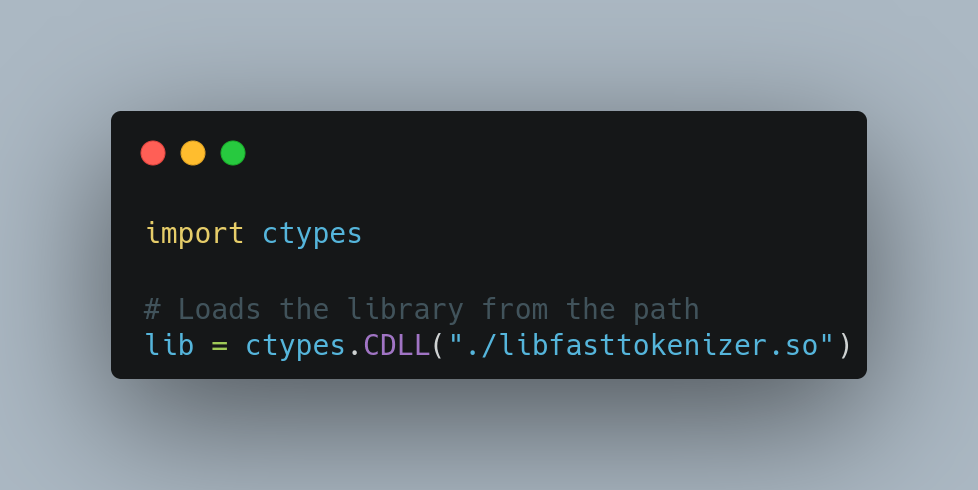
Loading library into Python
Defining signatures for token_ranker in Python

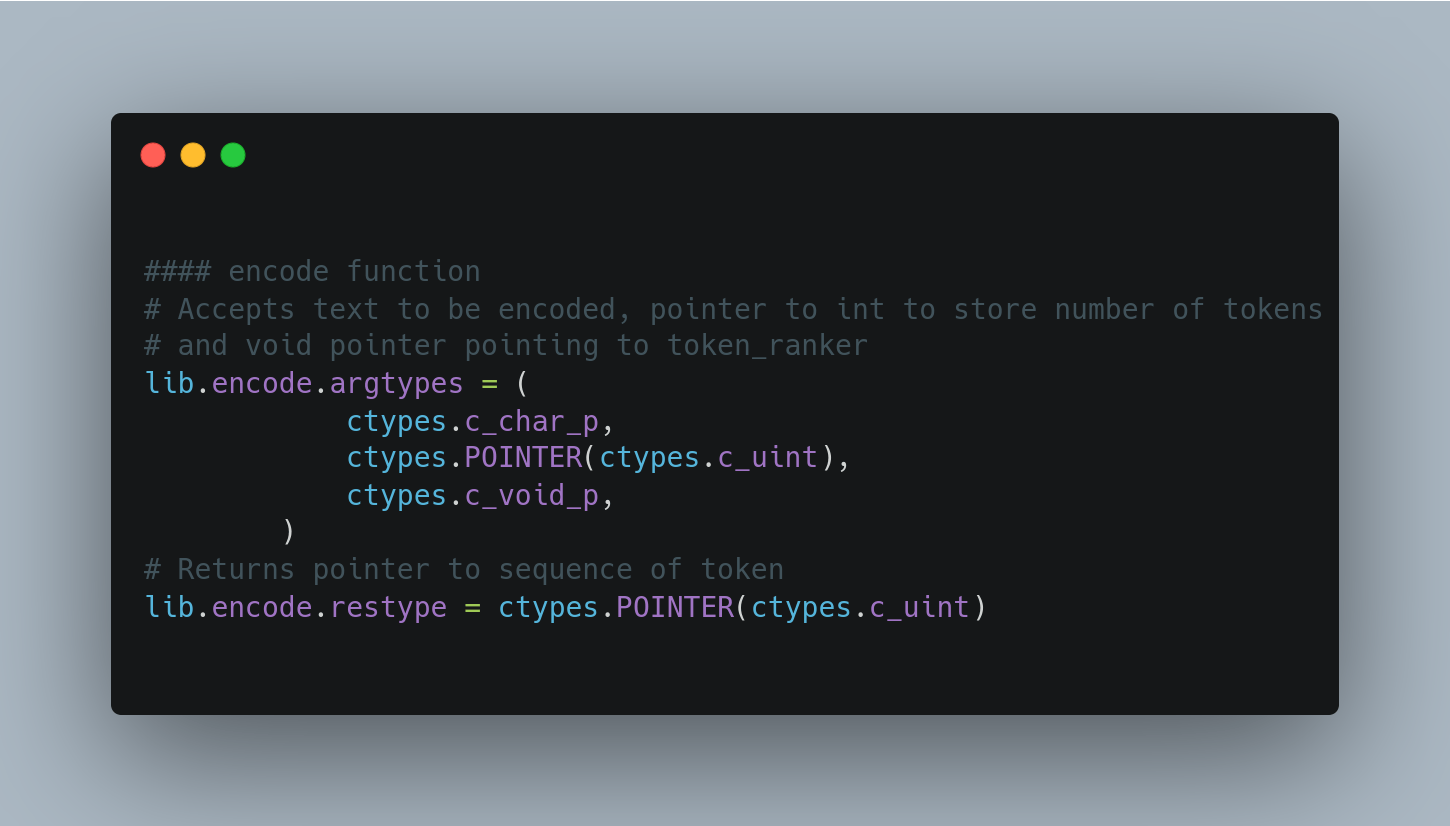
Defining signatures for encode in Python

Simple single file python LLM lib
Perfomance
Test Against Typical Input context to LLMs
| File | Size | No: of Words |
|---|---|---|
| Naatu Naatu Song Lyrics | 1.5KB | 202 |
| Pycon Code of Conduct | 5.2KB | 757 |
| Oxford Dictionary | 4.5MB | 731K |
Results
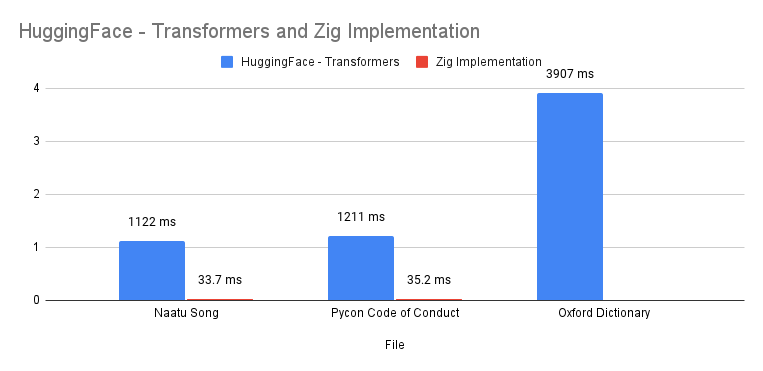
Note: Zig uses PCRE2 for Regex operations
Major Bottleneck - Regex (Dictionary Use Case)


Results
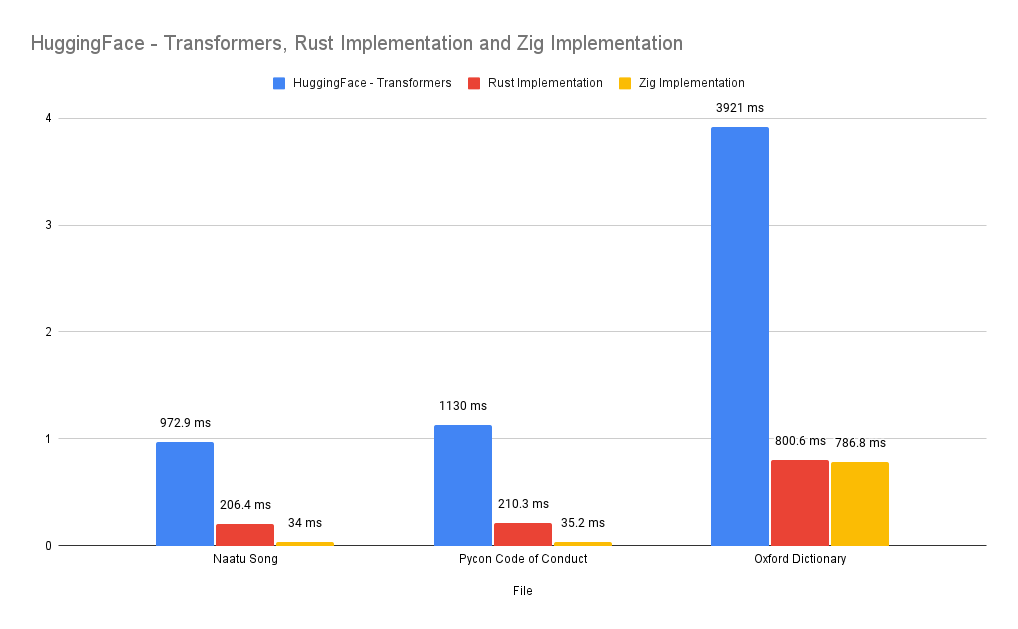
Note: All implementations are run on single thread
Rust implementation is Tiktoken library
Zig uses FancyRegex for Regex operations
Thank You!

Pycon2024 - BLR
By Akhil G


