MySQL 實戰 45 講
Backend 讀書會
12/29
15:00~16:30
@Universe Tech
從刪庫到跑路

從刪庫到跑路
rm -rf /*drop database golden_prod;從刪庫到跑路
-
DELETE Rows
- DROP/TRUNCATE Table
- DROP Database
- rm -rf /*
從刪庫到跑路
-
DELETE Rows - Flashback
- 对于 insert 语句,对应的 binlog event 类型是 Write_rows event,把它改成 Delete_rows event 即可;
- 同理,对于 delete 语句,也是将 Delete_rows event 改为 Write_rows event;
- 而如果是 Update_rows 的话,binlog 里面记录了数据行修改前和修改后的值,对调这两行的位置即可。
Flashback 恢复数据的原理,是修改 binlog 的内容,拿回原库重放。
而能够使用这个方案的前提是,需要确保 binlog_format=row 和 binlog_row_image=FULL。從刪庫到跑路
-
DELETE Rows - Flashback
(A)delete ...
(B)insert ...
(C)update ...從刪庫到跑路
-
DELETE Rows - Flashback
(reverse C)update ...
(reverse B)delete ...
(reverse A)insert ...從刪庫到跑路
-
DELETE Rows
- 把 sql_safe_updates 参数设置为 on。这样一来,如果我们忘记在 delete 或者 update 语句中写 where 条件,或者 where 条件里面没有包含索引字段的话,这条语句的执行就会报错。
- 代码上线前,必须经过 SQL 审计。
從刪庫到跑路
-
DROP/TRUNCATE Table
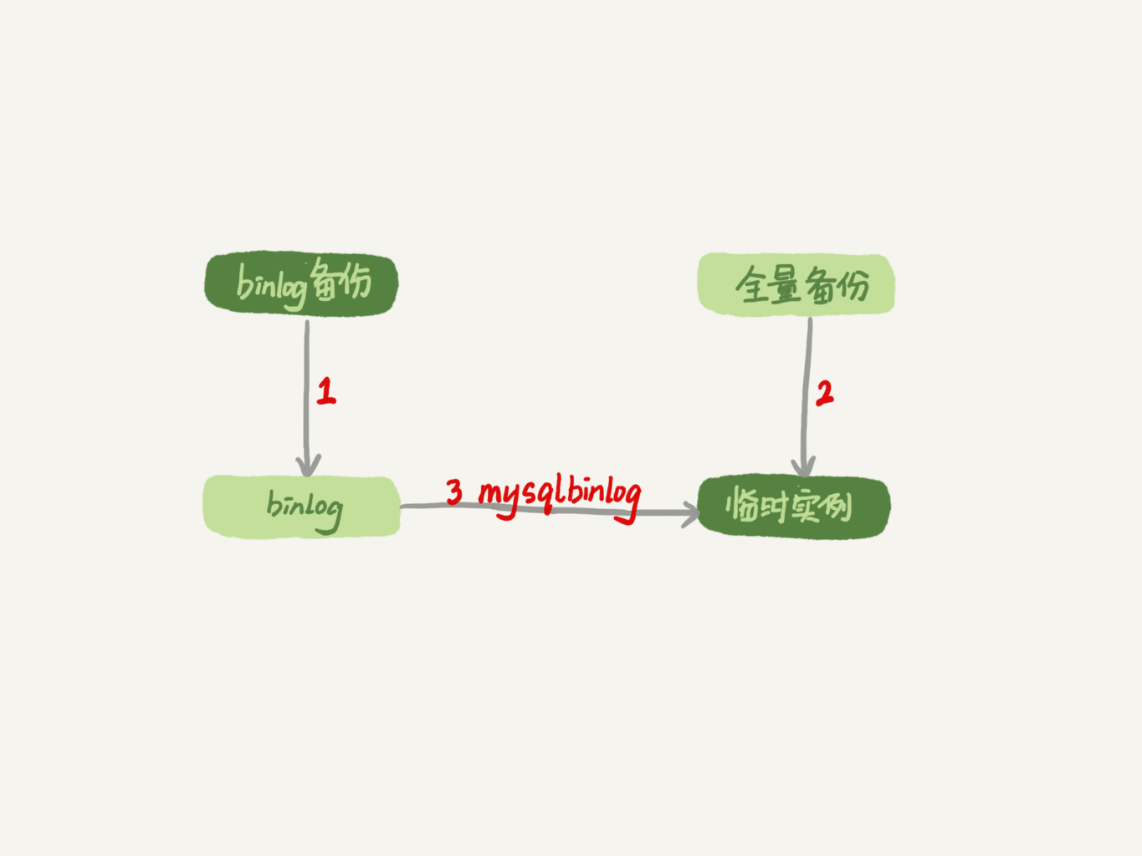
- 取最近一次全量备份,假设这个库是一天一备,上次备份是当天 0 点;
- 用备份恢复出一个临时库;
- 从日志备份里面,取出凌晨 0 点之后的日志;
- 把这些日志,除了误删除数据的语句外,全部应用到临时库。
從刪庫到跑路
-
DROP/TRUNCATE Table
- 为了加速数据恢复,如果这个临时库上有多个数据库,你可以在使用 mysqlbinlog 命令时,加上一个–database 参数,用来指定误删表所在的库。这样,就避免了在恢复数据时还要应用其他库日志的情况。
- 在应用日志的时候,需要跳过 12 点误操作的那个语句的 binlog:
- 如果原实例没有使用 GTID 模式,只能在应用到包含 12 点的 binlog 文件的时候,先用–stop-position 参数执行到误操作之前的日志,然后再用–start-position 从误操作之后的日志继续执行;
- 如果实例使用了 GTID 模式,就方便多了。假设误操作命令的 GTID 是 gtid1,那么只需要执行 set gtid_next=gtid1;begin;commit; 先把这个 GTID 加到临时实例的 GTID 集合,之后按顺序执行 binlog 的时候,就会自动跳过误操作的语句。
從刪庫到跑路
-
DROP/TRUNCATE Table
- 不过,即使这样,使用 mysqlbinlog 方法恢复数据还是不够快,主要原因有两个:
- 如果是误删表,最好就是只恢复出这张表,也就是只重放这张表的操作,但是 mysqlbinlog 工具并不能指定只解析一个表的日志;
- 用 mysqlbinlog 解析出日志应用,应用日志的过程就只能是单线程。
- 不过,即使这样,使用 mysqlbinlog 方法恢复数据还是不够快,主要原因有两个:
從刪庫到跑路
-
DROP/TRUNCATE Table
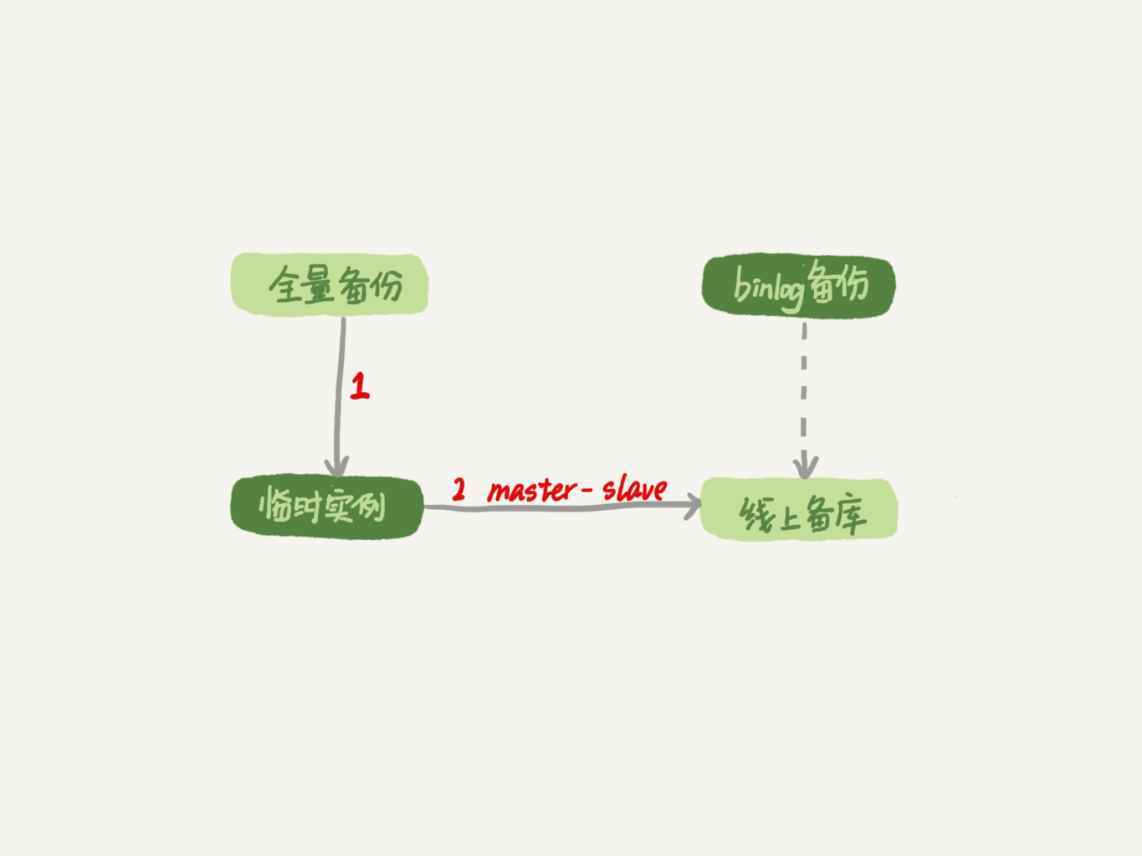
- 在 start slave 之前,先通过执行 change replication filter replicate_do_table = (tbl_name) 命令,就可以让临时库只同步误操作的表;
- 这样做也可以用上并行复制技术,来加速整个数据恢复过程。
從刪庫到跑路
-
DROP/TRUNCATE Table
- 延迟复制备库
CHANGE MASTER TO MASTER_DELAY = N從刪庫到跑路
-
DROP/TRUNCATE Table
- 账号分离。这样做的目的是,避免写错命令。比如:我们只给业务开发同学 DML 权限,而不给 truncate/drop 权限。而如果业务开发人员有 DDL 需求的话,也可以通过开发管理系统得到支持。即使是 DBA 团队成员,日常也都规定只使用只读账号,必要的时候才使用有更新权限的账号。
- 制定操作规范。这样做的目的,是避免写错要删除的表名。比如:在删除数据表之前,必须先对表做改名操作。然后,观察一段时间,确保对业务无影响以后再删除这张表。改表名的时候,要求给表名加固定的后缀(比如加 _to_be_deleted),然后删除表的动作必须通过管理系统执行。并且,管理系删除表的时候,只能删除固定后缀的表。
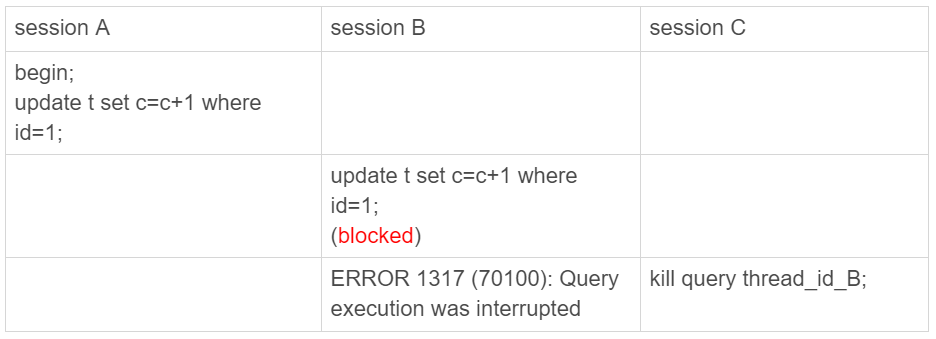
Kill Process
SHOW PROCESSLIST;Kill Process
Kill Process

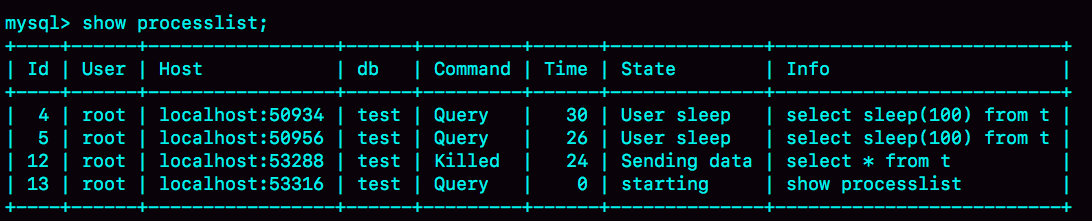
set global innodb_thread_concurrency=2;Kill Process
Kill Process
- 线程没有执行到判断线程状态的逻辑。
- 超大事务执行期间被 kill。这时候,回滚操作需要对事务执行期间生成的所有新数据版本做回收操作,耗时很长。
- 大查询回滚。如果查询过程中生成了比较大的临时文件,加上此时文件系统压力大,删除临时文件可能需要等待 IO 资源,导致耗时较长。
- DDL 命令执行到最后阶段,如果被 kill,需要删除中间过程的临时文件,也可能受 IO 资源影响耗时较久。
Kill Process
- 关于客户端的误解
- 如果库里面的表特别多,连接就会很慢。

执行 show databases;
切到 db1 库,执行 show tables;
把这两个命令的结果用于构建一个本地的哈希表。DB Lock in Laravel
<?php
$product = Product::whereId(10)
->lockForUpdate()
->first();
if ($product->amount <= 0) {
$product->amount--;
$product->save();
}
DB Lock in Laravel
<?php
DB::transaction(function () {
$product = Product::whereId(10)
->lockForUpdate()
->first();
if ($product->amount <= 0) {
$product->amount--;
$product->save();
}
});
Phantom Read
CREATE TABLE `t` (
`id` int(11) NOT NULL,
`c` int(11) DEFAULT NULL,
`d` int(11) DEFAULT NULL,
PRIMARY KEY (`id`), KEY `c` (`c`)
) ENGINE=InnoDB;insert into t values
(0,0,0),(5,5,5),
(10,10,10),(15,15,15),
(20,20,20),(25,25,25);Phantom Read
begin;
select * from t where d=5 for update;
commit;
-
Will this operation lock the whole table?
Phantom Read
-
Will this operation lock the whole table?

Phantom Read
-
Phantom Read means inconsistent results in the same transaction. -
Consistent Read is default behavior for the transaction. -
Consistent Read is based on undo log and MVCC. -
Locking Read is used in transaction locks. -
Locking Read will read all latest records.
Phantom Read
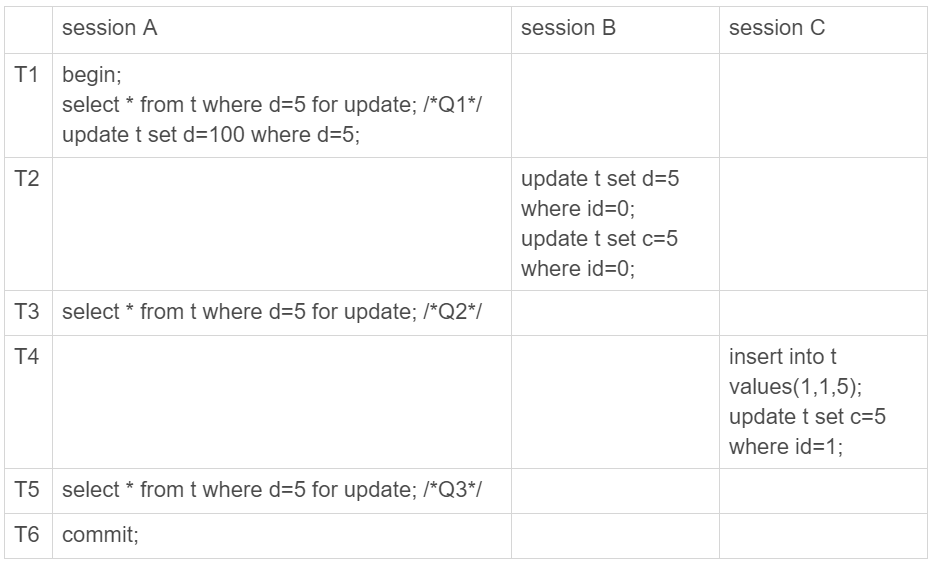
Phantom Read
update t set d=5 where id=0; /*(0,0,5)*/
update t set c=5 where id=0; /*(0,5,5)*/
insert into t values(1,1,5); /*(1,1,5)*/
update t set c=5 where id=1; /*(1,5,5)*/
update t set d=100 where d=5;/*所有d=5的行,d改成100*/Phantom Read
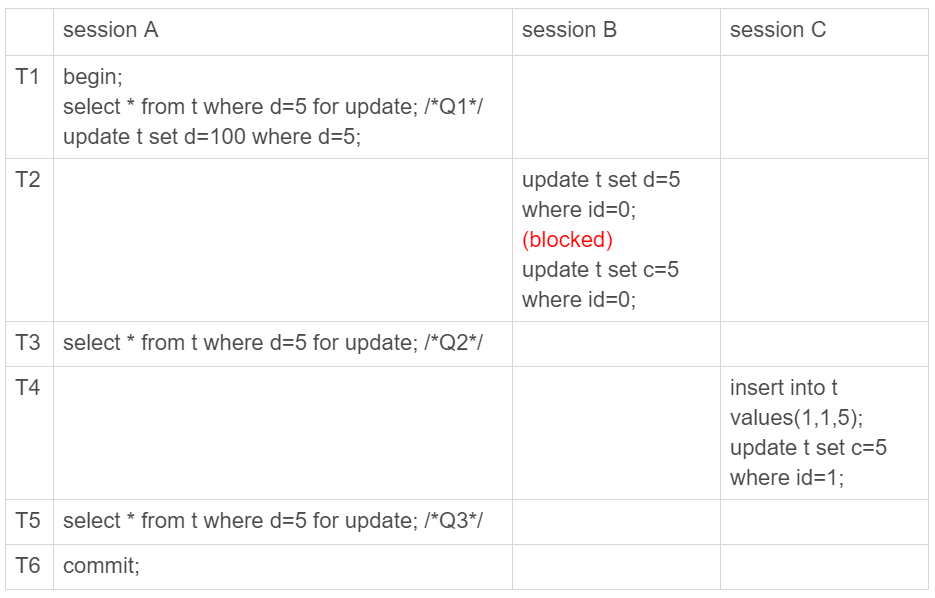
-
If we block all related rows
Phantom Read
-
If we block all related rows
insert into t values(1,1,5); /*(1,1,5)*/
update t set c=5 where id=1; /*(1,5,5)*/
update t set d=100 where d=5;/*所有d=5的行,d改成100*/
update t set d=5 where id=0; /*(0,0,5)*/
update t set c=5 where id=0; /*(0,5,5)*/Phantom Read
-
Gap Lock
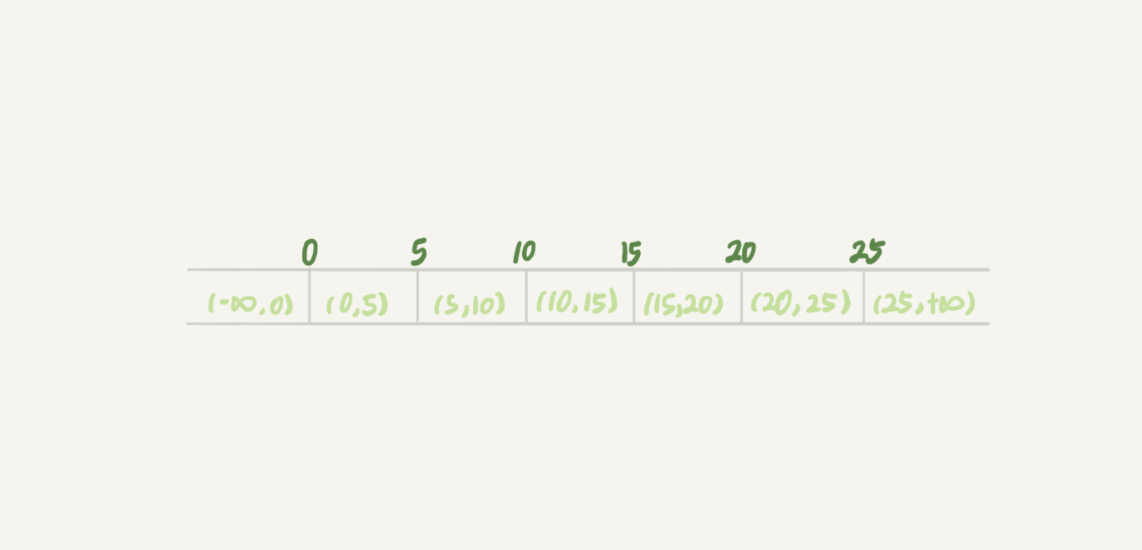
Phantom Read
-
Next-Key Lock

-
Next-Key Lock

How Does Lock Work?
-
Principles
-
原则 1:加锁的基本单位是 next-key lock。希望你还记得,next-key lock 是前开后闭区间。
-
原则 2:查找过程中访问到的对象才会加锁。
-
优化 1:索引上的等值查询,给唯一索引加锁的时候,next-key lock 退化为行锁。
-
优化 2:索引上的等值查询,向右遍历时且最后一个值不满足等值条件的时候,next-key lock 退化为间隙锁。
-
一个 bug:唯一索引上的范围查询会访问到不满足条件的第一个值为止。
-
How Does Lock Work?
-
Next-Key Lock

How Does Lock Work?
-
Next-Key Lock
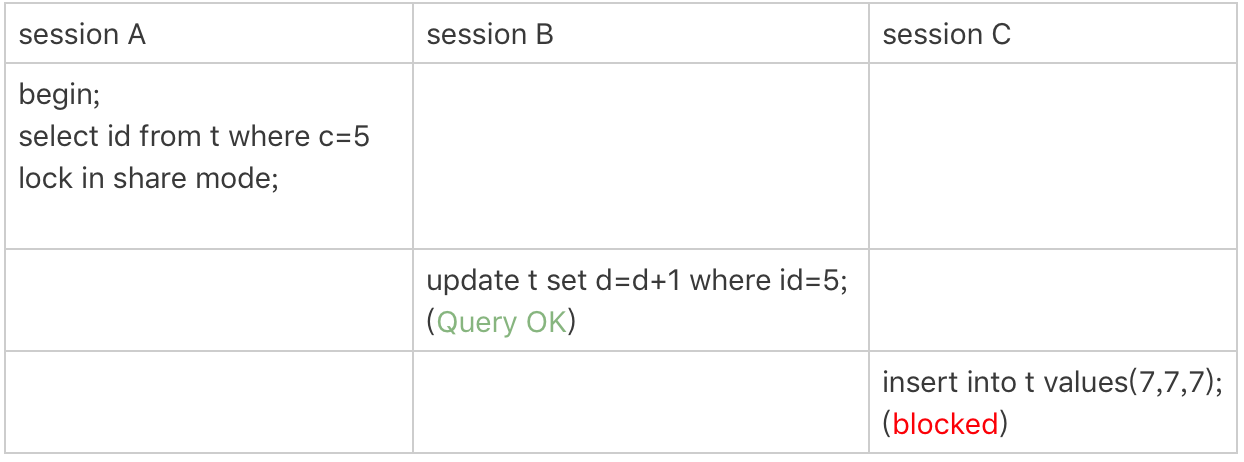
How Does Lock Work?
-
Next-Key Lock
How Does Lock Work?
-
Next-Key Lock

How Does Lock Work?
-
Next-Key Lock
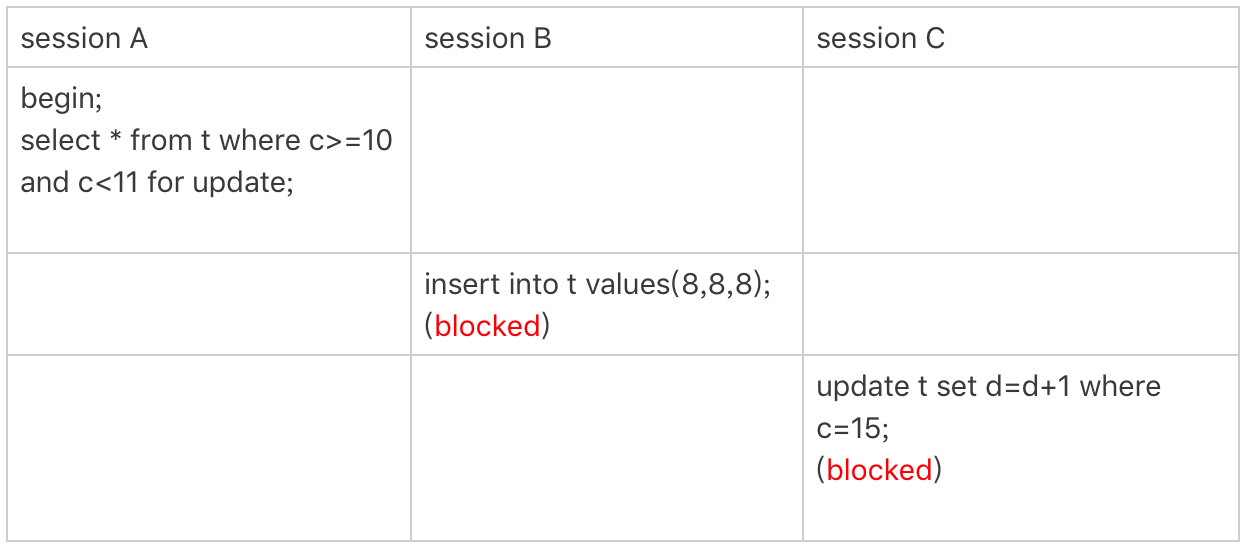
How Does Lock Work?
-
Next-Key Lock
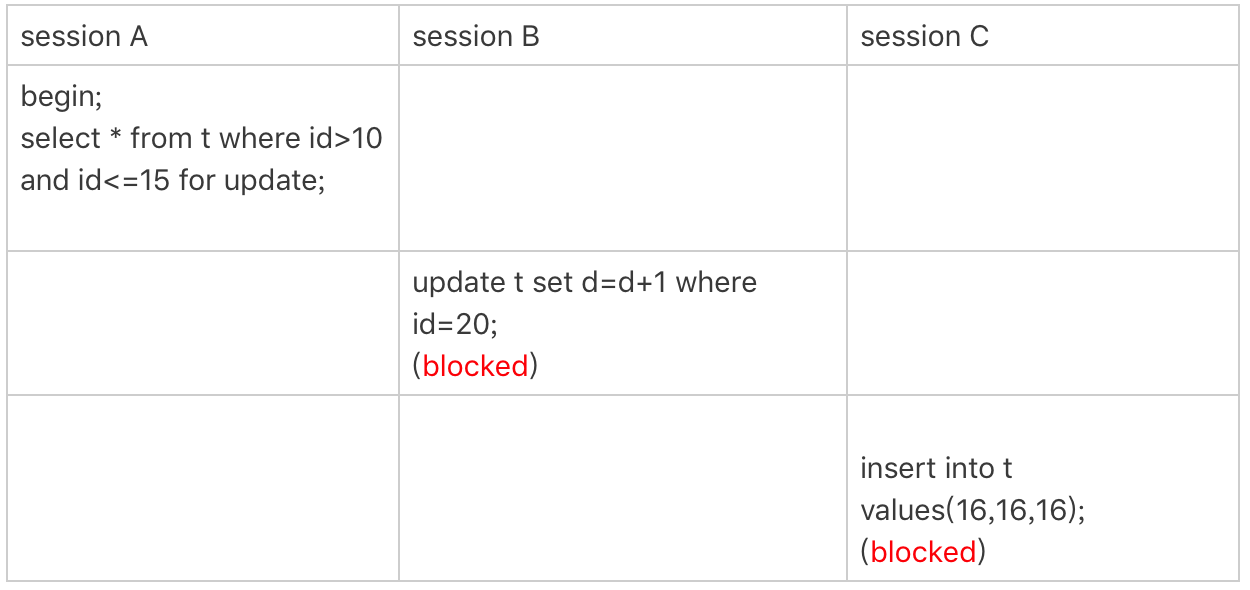
How Does Lock Work?
-
Next-Key Lock
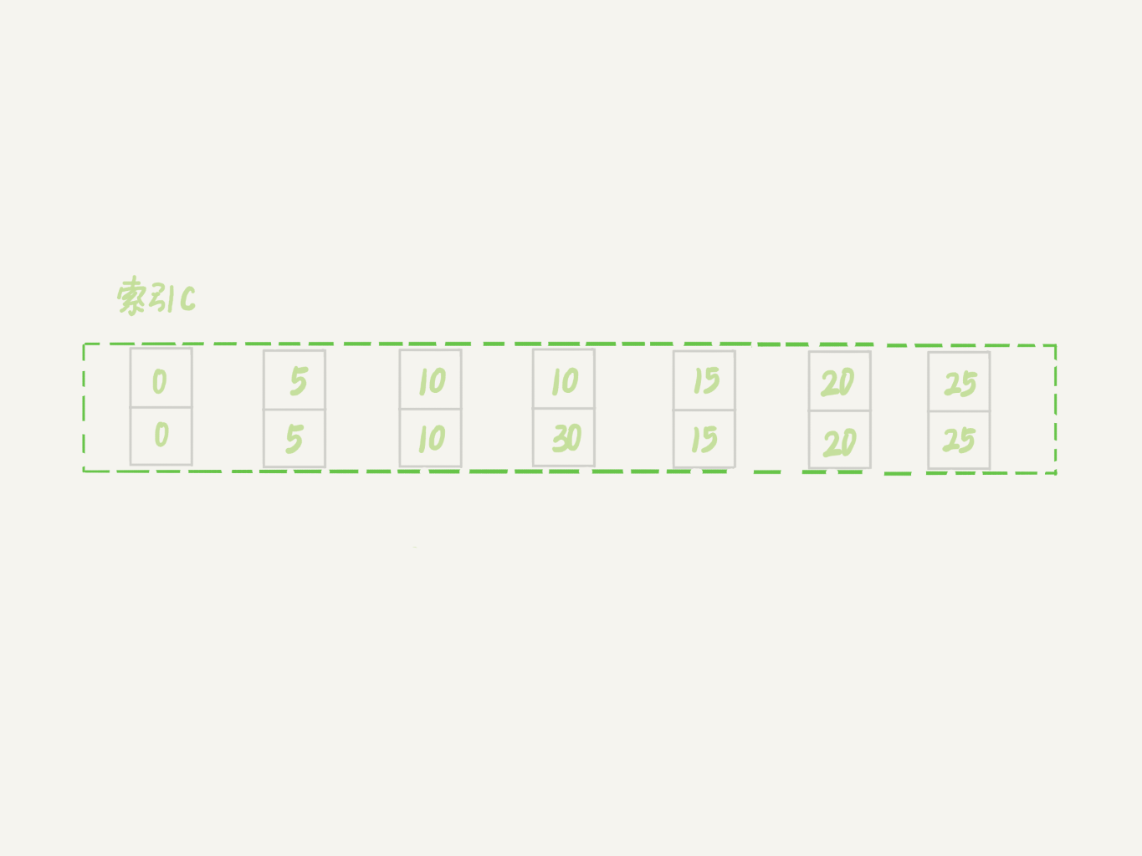
mysql> insert into t values(30,10,30);How Does Lock Work?
-
Next-Key Lock
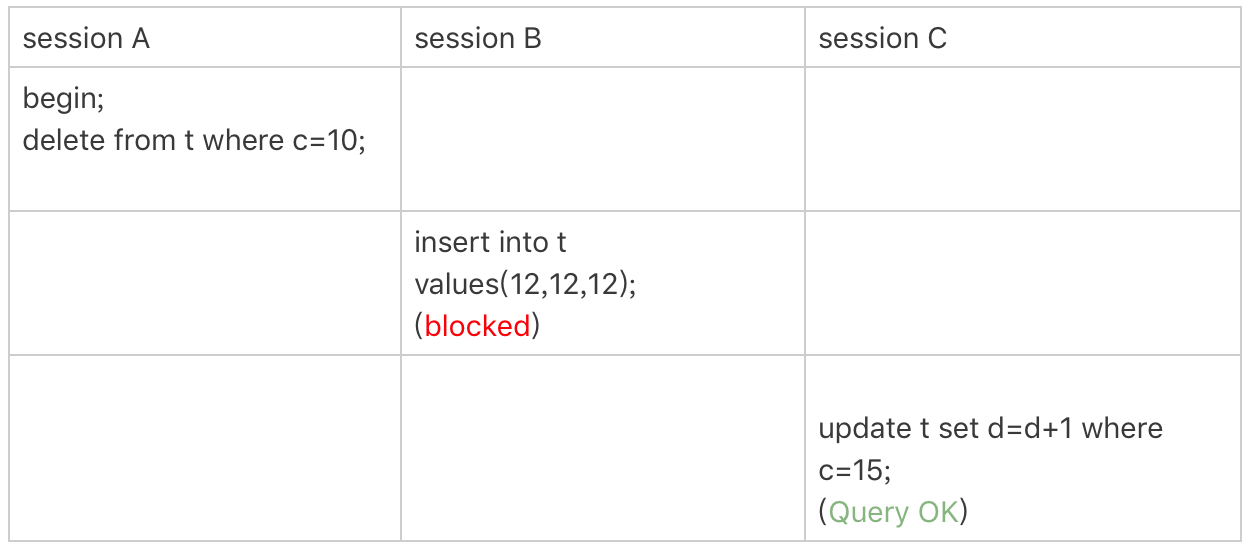
How Does Lock Work?
-
Next-Key Lock
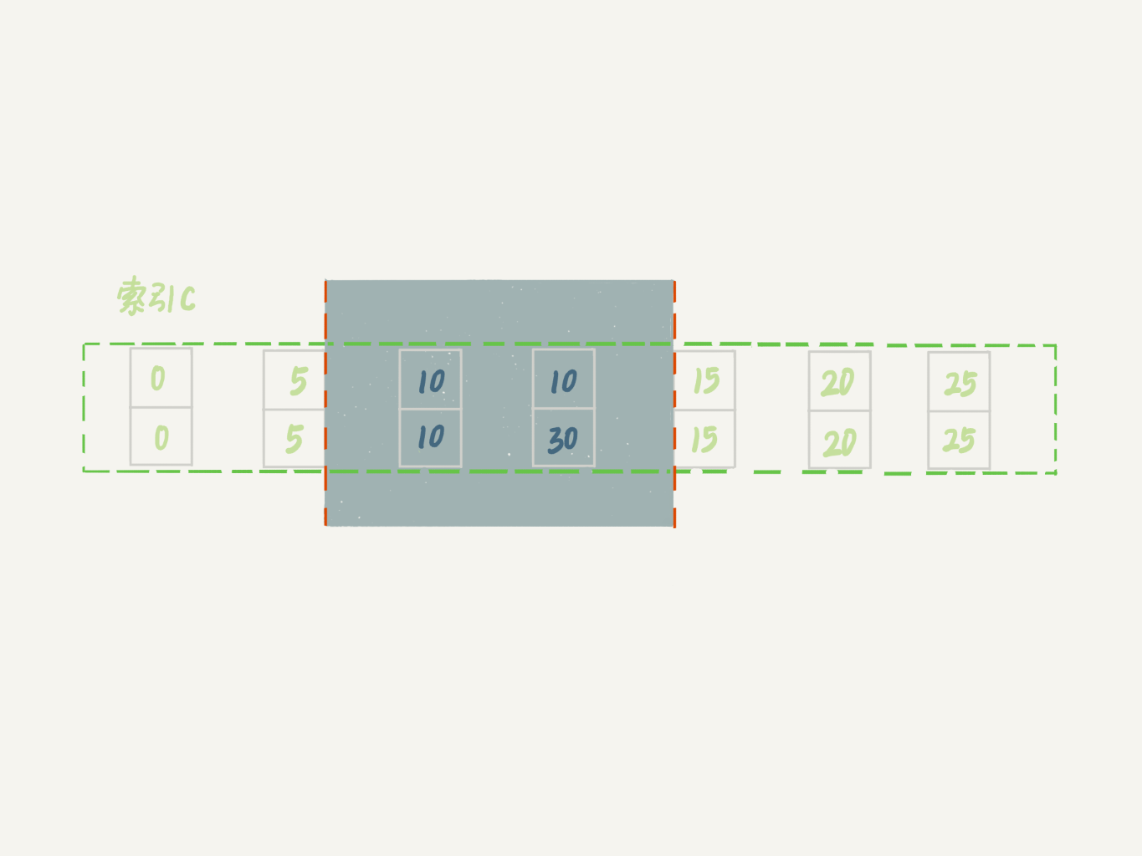
How Does Lock Work?
-
Next-Key Lock

How Does Lock Work?
-
Next-Key Lock
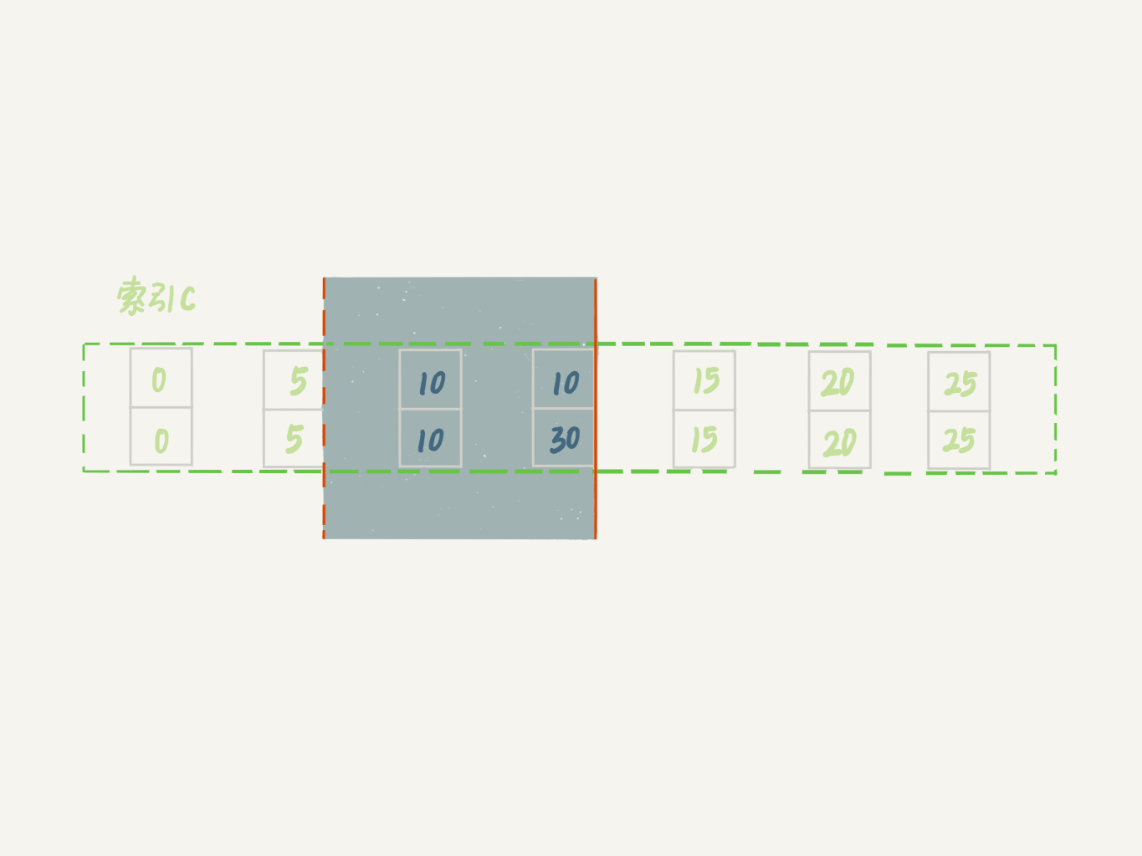
How Does Lock Work?
-
Next-Key Lock

How Does Lock Work?
Discussion
Copy of MySQL 實戰 45 講 - Backend 讀書會
By Albert Chen



