LLM Basics Workshop
Agenda
Agenda
Theory
Hands-On
1. What is an LLM, I can't even 😳
2. Running models
a. Local models
b. Deployed models
3. Understanding System Prompts
4. Prompt Engineering
What is an LLM?

What is an LLM?



How many 'r' letters are in the word 'strawberry'?
Uhh, like 2?
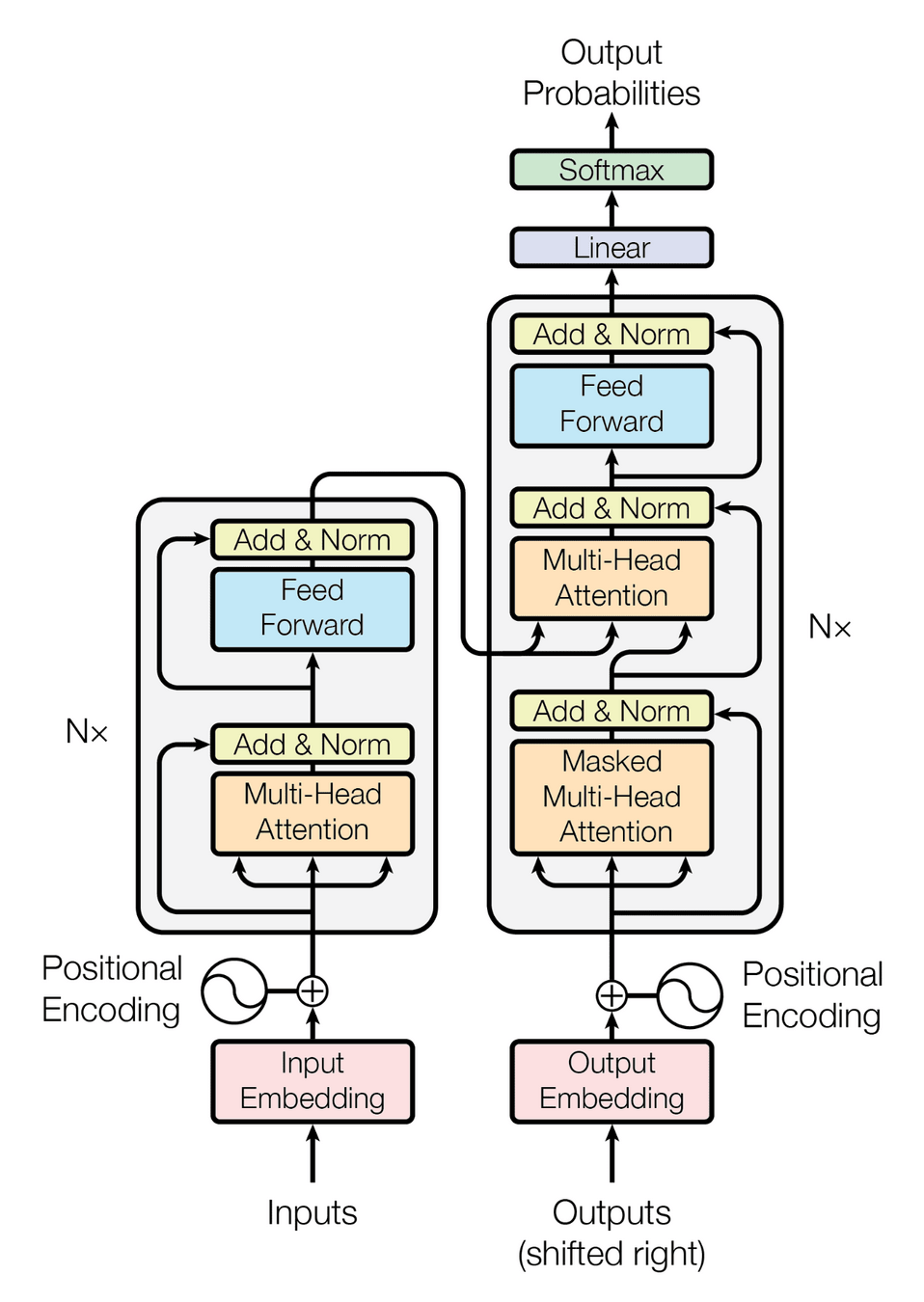
Transformer Architecture

Transformer Architecture Overview
Linear
Softmax
Output Probabilities
Output Embedding
+
+
Positional Encoding
Input Embedding
Positional Encoding
Add & Norm
Multi-Head Attention
Feed Forward
Masked Multi-Head Attention
Add & Norm
Multi-Head Attention
Multi-Head Attention
Multi-Head Attention
Add & Norm
Feed Forward
Add & Norm
Outputs (shifted right)
Add & Norm
Inputs
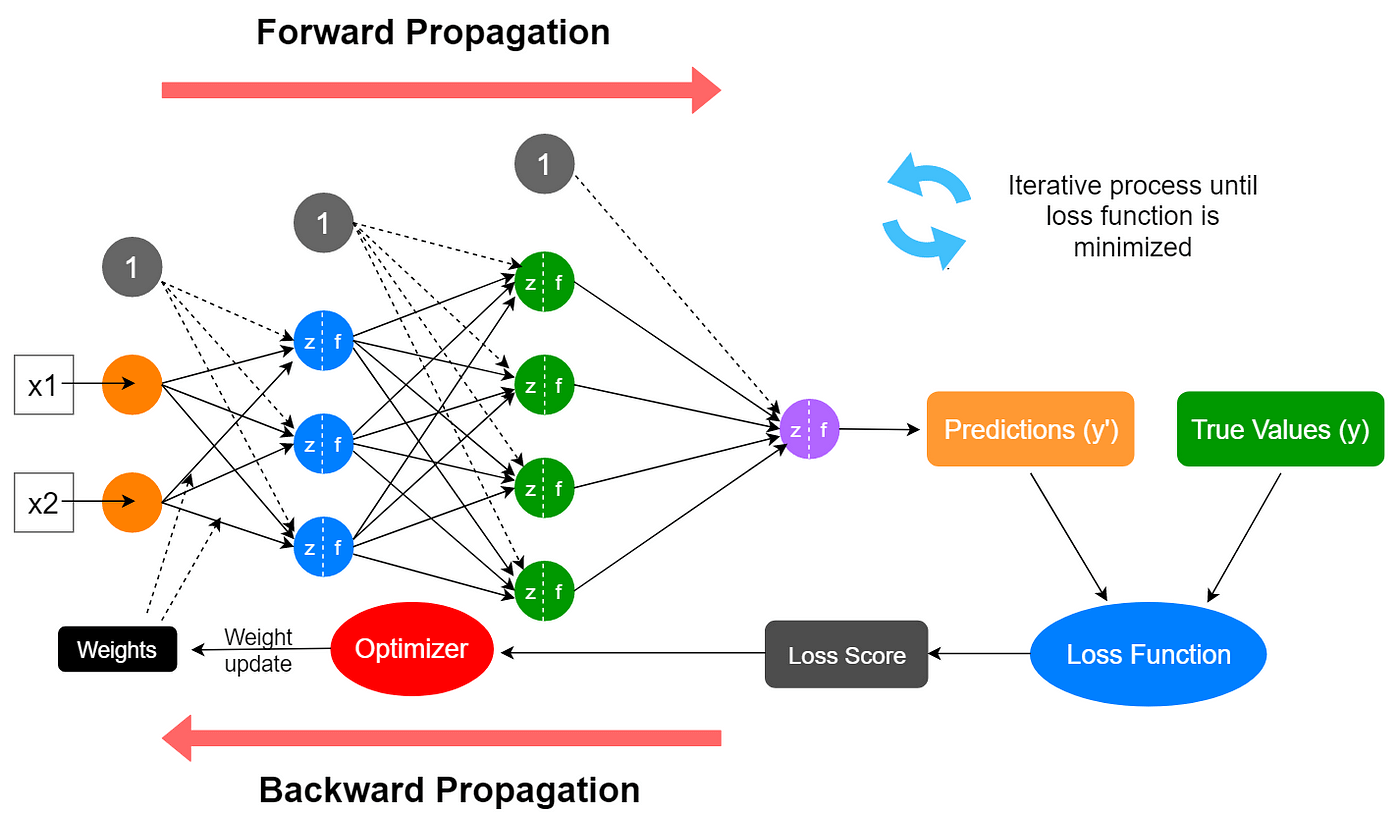
Neural Networks

Neural Networks
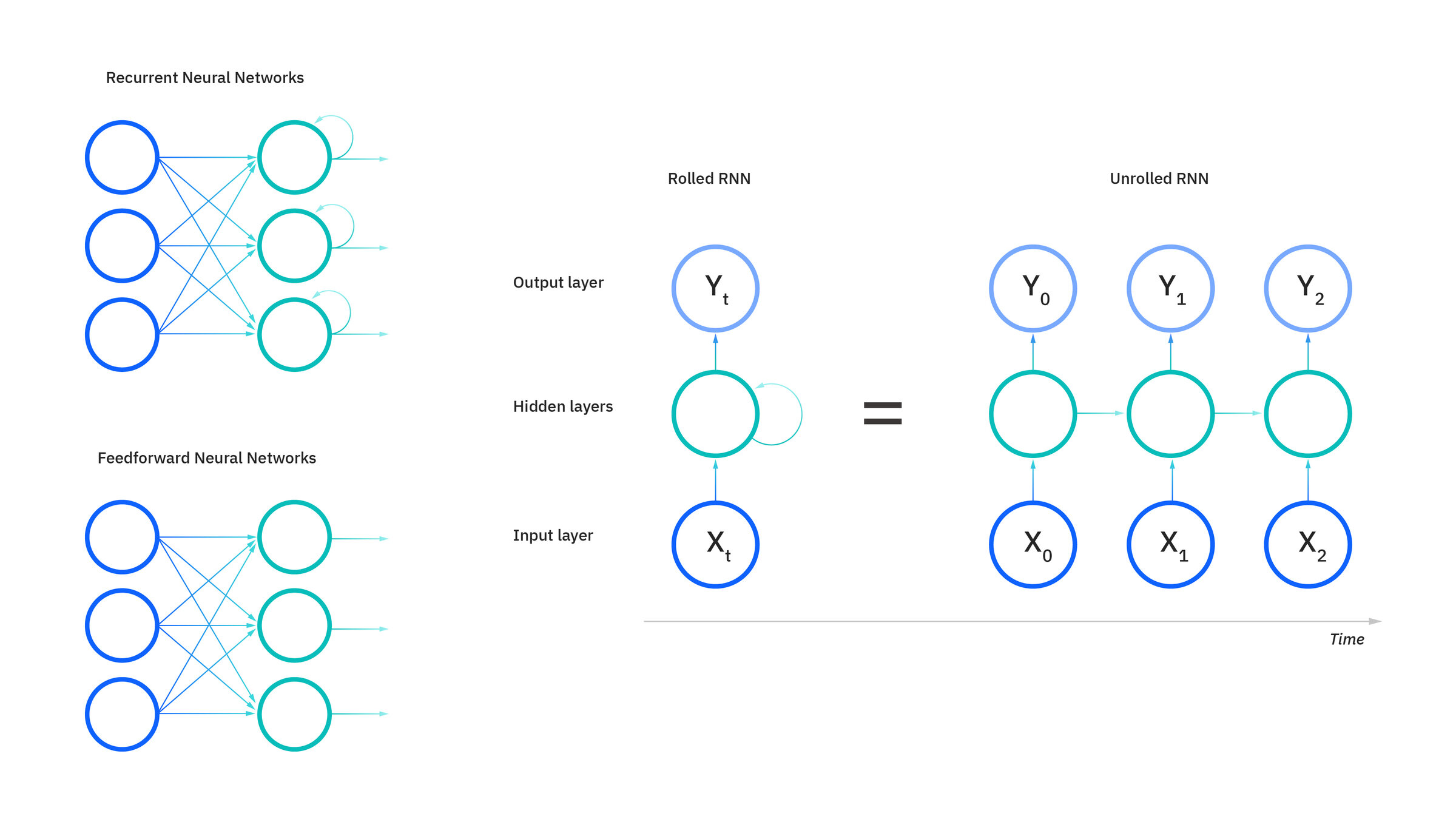
Neural Networks
Feed-Forward

Linear
Softmax
Output Probabilities
Output Embedding
+
+
Positional Encoding
Input Embedding
Positional Encoding
Add & Norm
Multi-Head Attention
Feed Forward
Masked Multi-Head Attention
Add & Norm
Multi-Head Attention
Add & Norm
Feed Forward
Add & Norm
Outputs (shifted right)
Add & Norm
Inputs
Feed-Forward
Tokenization

Tokenization
This workshop is high key slay
This
workshop
is
high
key
slay
0
1
2
3
4
5
356
53782
52
333
672
1
Token Embeddings

Linear
Softmax
Output Probabilities
Output Embedding
+
+
Positional Encoding
Input Embedding
Positional Encoding
Add & Norm
Multi-Head Attention
Feed Forward
Masked Multi-Head Attention
Add & Norm
Multi-Head Attention
Add & Norm
Feed Forward
Add & Norm
Outputs (shifted right)
Add & Norm
Inputs
Token Embeddings
This
workshop
is
high
key
slay
| 0.51 | 0.12 | 1 | 0 | 0 | 0.45 | 0.50 | 0.29 | ... | 0.77 |
|---|
| 0.98 | 0.32 | 0.63 | 0.92 | 0.17 | 0 | 0.07 | 0.83 | ... | 1 |
|---|
| 0.43 | 1 | 0.95 | 1 | 0.54 | 0.31 | 0.19 | 0 | ... | 0 |
|---|
| 0.53 | 0.52 | 0.51 | 0.92 | 0.78 | 0.71 | 0.99 | 0.84 | ... | 0.91 |
|---|
| 0.82 | 0.91 | 0.56 | 0.59 | 0.99 | 0.42 | 1 | 1 | ... | 0.72 |
|---|
| 0.60 | 0.15 | 0.75 | 0.59 | 0.01 | 0.07 | 0 | 0.27 | ... | 0.33 |
|---|
Token Embeddings
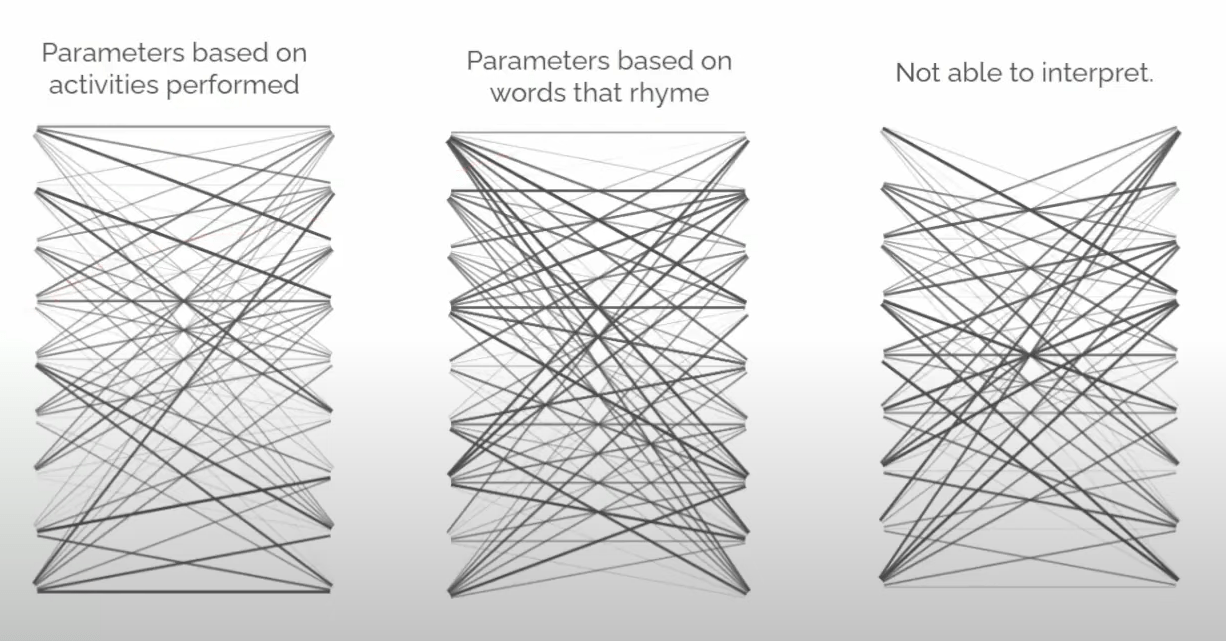
cat
dog
cluster
cult
| 0.75 | 0.61 | 0.98 | 0.02 | 0 | 0.12 | 0.17 | 0.29 | ... | 0.57 |
|---|
| 0.74 | 0.59 | 0.98 | 0.02 | 0.02 | 0.11 | 0.17 | 0.30 | ... | 0.56 |
|---|
| 0.59 | 0.95 | 0 | 0.85 | 1 | 0.67 | 0.15 | 0.72 | ... | 0.25 |
|---|
| 0.60 | 0.95 | 0 | 0.85 | 0.97 | 0.68 | 0.17 | 0.72 | ... | 0.23 |
|---|
Cat
Dog
I
We
Us
Cluster
Cult
Run
Walk
Cycle
Swim
Cat
Dog
I
We
Us
Cluster
Cult
Run
Walk
Cycle
Swim
Chat
Katze
Pisică
ネコ
Positional Encoding

Linear
Softmax
Output Probabilities
Output Embedding
+
+
Positional Encoding
Input Embedding
Positional Encoding
Add & Norm
Multi-Head Attention
Feed Forward
Masked Multi-Head Attention
Add & Norm
Multi-Head Attention
Add & Norm
Feed Forward
Add & Norm
Outputs (shifted right)
Add & Norm
Inputs
Positional Encoding
John eats pineapple
Pineapple eats John
0
1
2
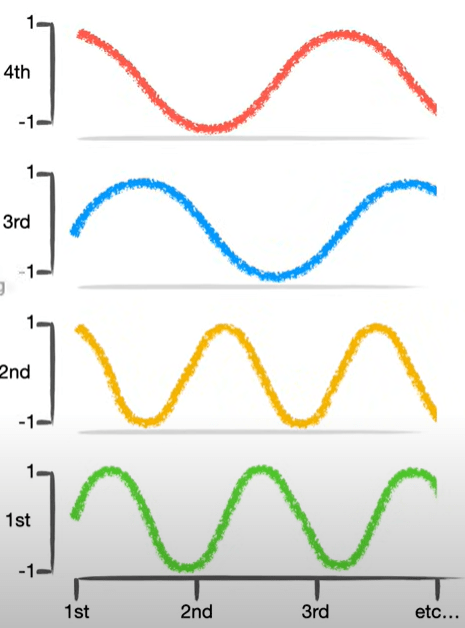
Positional Encoding
John ( i = 0 )
eats ( i = 1 )
| 0.75 | 0.61 | 0.98 | 0.02 | 0 | 0.12 | 0.17 | 0.29 | ... | 0.57 |
|---|
| 0.23 | 0.15 | 0.79 | 0.09 | 0 | 0.18 | 0.82 | 0.58 | ... | 0.73 |
|---|
pineapple ( i = 2 )
| 0.35 | 0.01 | 0.09 | 0.38 | 0.22 | 0 | 0 | 0.99 | ... | 1 |
|---|
| sin(0) 0 |
cos(0) 1 |
sin(0) 0 |
cos(0) 1 |
... | ... | ... | ... | ... | ... |
|---|
| sin(1/1) 0 |
cos(1/1) 0.54 |
sin(1/10) 0.1 |
cos(1/10) 1 |
... | ... | ... | ... | ... | ... |
|---|
| sin(2/1) 0.91 |
cos(2/1) -0.41 |
sin(2/10) 0.2 |
cos(2/10) 0.98 |
... | ... | ... | ... | ... | ... |
|---|
Self-Attention

Slay
Your pull request is kinda
I cometh h're to ev'ry peasant
slay
slay
Self Attention
Self Attention
Your
pull
request
is
kinda
slay
Your
pull
request
is
kinda
slay
pull request is kinda slay
Your pull is kinda slay
Your
request
| 0.74 | 0.59 | 0.98 | 0.02 | 0.02 | 0.11 | 0.17 | 0.30 | ... | 0.56 |
|---|
| 0.23 | 0.15 | 0.79 | 0.09 | 0 | 0.18 | 0.82 | 0.58 | ... | 0.73 |
|---|
Query:
Key:
Value:
Self Attention
What are we trying to find?
What are the key features of this token?
What is being retrieved?
Self Attention
...
0.74
0.59
0.98
0.02
0.02
0.11
0.17
0.30
0.56
...
0.31
0.75
1.5
-3.4
-0.5
1.23
0.91
-0.11
2
0.2
0.1
-0.2
0.15
0.9
-0.85
-0.52
0.6
0.5
Your
Query
Self Attention
...
0.74
0.59
0.98
0.02
0.02
0.11
0.17
0.30
0.56
...
1.5
-0.3
1.12
2.67
-0.1
-1.75
-2.12
0.63
0.95
Your
Key
Self Attention
...
0.74
0.59
0.98
0.02
0.02
0.11
0.17
0.30
0.56
...
0.71
0.81
-0.15
1.72
-0.9
-0.25
1.92
2.57
0.19
Your
Value
Self Attention
Query x Key = Similarity Vector
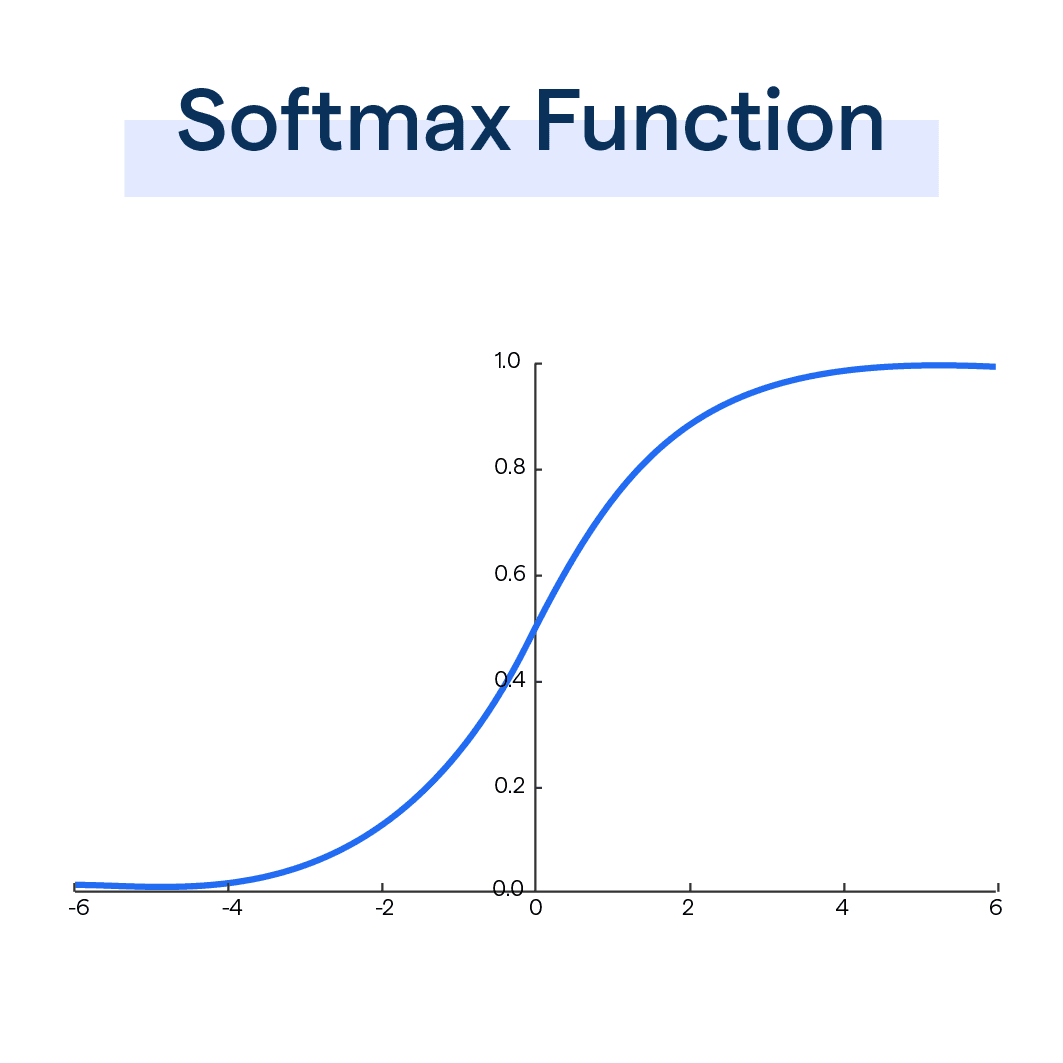
Similarity Vector + Softmax = Normalized Similarity Vector
Normalized Similarity Vector x Value = Self-Attention
| a0 | b0 | c0 | d0 | e0 | f0 | g0 | h0 | ... | z0 |
|---|
x
x
x
x
x
x
x
x
x
| a1 | b1 | c1 | d1 | e1 | f1 | g1 | h1 | ... | z1 |
|---|
| a0a1 | b0b1 | c0c1 | d0d1 | e0e1 | f0f1 | g0g1 | h0h1 | ... | z0z1 |
|---|
=
+
+
+
+
+
+
+
+
+
=
final similarity result
| 21 | -3.2 | 14.2 | 15.7 | -7.1 | 0.1 | 3.5 | -2.9 | ... | 0.2 |
|---|
| 0.994 | 0 | 0.001 | 0.005 | 0 | 0 | 0 | 0 | ... | 0 |
|---|
a0 x 0.994 + a1 x 0.994 + ... + an x 0.994 = self-attention value on index 0
b0 x 0 + b1 x 0 + ... + bn x 0 = self-attention value on index 1
| S0 |
|---|
Multi-Head Attention

Linear
Softmax
Output Probabilities
Output Embedding
+
+
Positional Encoding
Input Embedding
Positional Encoding
Add & Norm
Multi-Head Attention
Feed Forward
Masked Multi-Head Attention
Add & Norm
Multi-Head Attention
Add & Norm
Feed Forward
Add & Norm
Outputs (shifted right)
Add & Norm
Inputs
Multi Head Attention
Your
pull
request
is
kinda
slay
Your
pull
request
is
kinda
slay
request
is
kinda
slay
kinda
slay
Multi Head Attention
Your
pull
request
is
kinda
slay
Your
pull
request
is
kinda
slay
Your
pull
request
is
kinda
slay
Your
pull
request
is
kinda
slay
Your
pull
request
is
kinda
slay
Your
pull
request
is
kinda
slay
Your
pull
request
is
kinda
slay
Your
pull
request
is
kinda
slay
Multi Head Attention
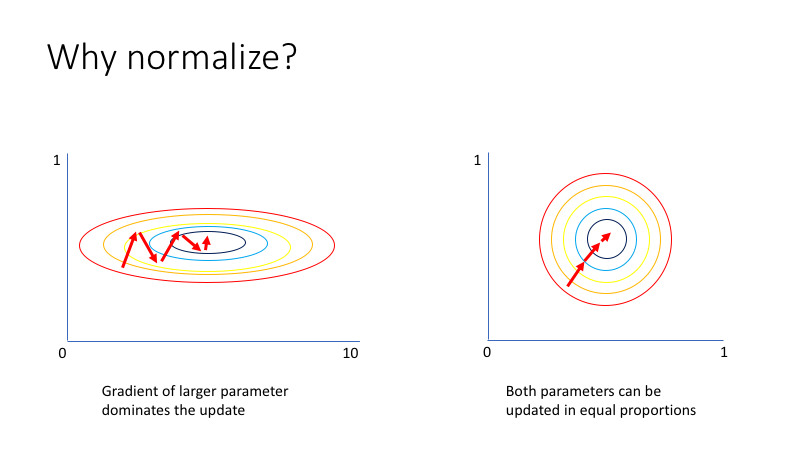
Normalization

Linear
Softmax
Output Probabilities
Output Embedding
+
+
Positional Encoding
Input Embedding
Positional Encoding
Add & Norm
Multi-Head Attention
Feed Forward
Masked Multi-Head Attention
Add & Norm
Multi-Head Attention
Add & Norm
Feed Forward
Add & Norm
Outputs (shifted right)
Add & Norm
Inputs
Normalization
Normalization

Processing the Output

Linear
Softmax
Output Probabilities
Output Embedding
+
+
Positional Encoding
Input Embedding
Positional Encoding
Add & Norm
Multi-Head Attention
Feed Forward
Masked Multi-Head Attention
Add & Norm
Multi-Head Attention
Add & Norm
Feed Forward
Add & Norm
Outputs (shifted right)
Add & Norm
Inputs
Processing the Output
This workshop is high key slay ______
| 0.74 | 0.59 | 0.98 | 0.02 | 0.02 | 0.11 | 0.17 | 0.30 | ... | 0.56 |
|---|
1x256
| -0.012 | 0.001 | 0.02 | 0 | -0.1 | -0.002 | 0.15 | -0.05 | ... | 0.042 |
|---|
1x50000
| 0% | 0% | 0% | 0% | 0% | 0% | 35% | 0% | ... | 1% |
|---|
Linear
Softmax
1x50000
| 0% | 0% | 0% | 0% | 0% | 0% | 35% | 0% | ... | 1% |
|---|
6
5
4
3
2
1
0
7
49999
This workshop is high key slay __6__
Processing the Output
This workshop is high key slay queen
LLM Basics
By alexgrigi




