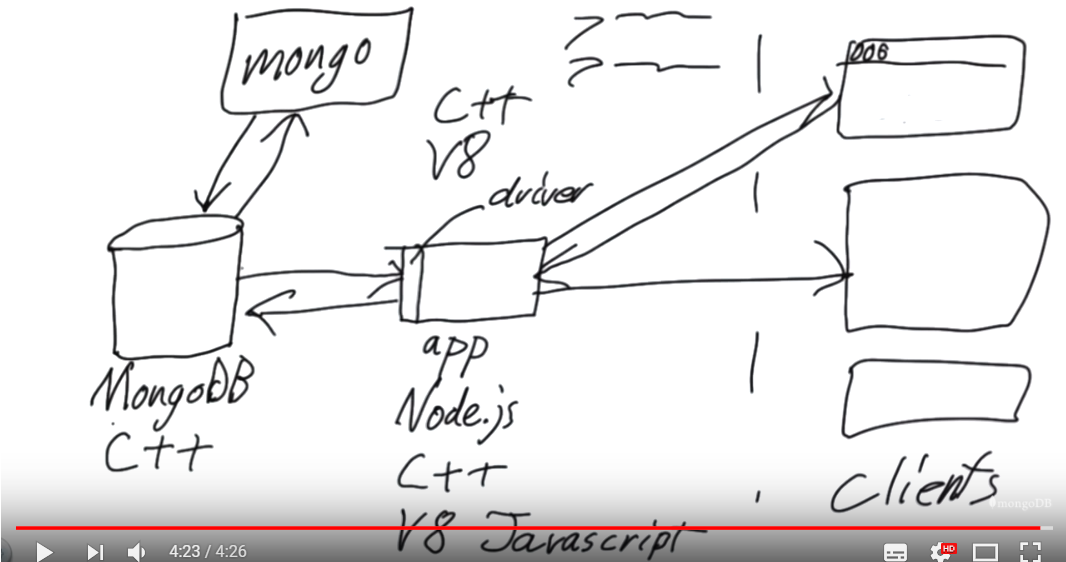
Mongo
MongoDB - document database.
Нереляционная база данных. Документо-ориентированная СУБД. Данные в MongoDB хранятся в документах, которые объединяются в коллекции. Каждый документ представляет собой JSON-подобную структуру. (BSON - binary JSON)
Mongo - shell
mongoD - server
Driver - library that handles all the connection to mongoDb

help
mongorestore directory
mongoimport -d
CRUD( create read update delete)
Create
db.collection.insert(<document or array of documents>)
db.collection.insertOne({})
db.collection.insertMany([{}, {}])
Read
Comparison: eq, gt(>), gte(>), lt(<), lte, in(any value in array), ne Logical : and, or, nor, not
exists, where
array: all, elemMatch, size
db.products.find( { qty: { $gt: 25 } }, { item: 1, qty: 1 } )
db.inventory.find( { $and: [ { price: { $ne: 1.99 } }, { price: { $exists: true } } ] } )
db.myCollection.find( { $where: "obj.credits == obj.debits" } );
{ tags: { $all: [ "ssl" , "security" ] } }
results: { $elemMatch: { product: "xyz", score: { $gte: 8 } } } Selects documents if element in the array field matches all the specified $elemMatch conditions.
For case where in array object has 2 fields and we need to match both of them
"actors" : ["Jeffry star", "aa a"] exact match = all
"actors" : "Jeffry star" exist in array
"actors.0" : "Jeffry star" 1place in array
""offices.countryCode" : ""IRL when offices is an array of object
db.collection.update(
<query>,
<update>,
{
upsert: <boolean>, create new one
multi: <boolean>, for many docs
}
)Update
Sort
cursor.sort({ field: value })
{ age : -1, posts: 1 } or
[[age, 1], [posts, -1]]
1 - ascending
-1 - descending
Skip, Limit
cursor.skip(10).limit(10)Use Update Operators such as $set, $unset, or $rename.
Delete
db.collection.deleteMany(
<filter>, // {"_id" :{$in : array}}
{
writeConcern: <document>,
collation: <document>
}
)Indexes
write - slower
read- faster
without index f.e sort would be in memory rather than in database
Вместо перебора большой коллекции целиком, мы перебираем индекс, который гораздо проще запихать в память и работать с ним. Помимо прочего, индексы в отличии от самих данных, более нормализованы для поиска/сравнения значений.
db.collection.createIndex(keys, options)
db.collection.getIndexes()
db.collection.dropIndex(key)
db.collection.createIndex("words: "text") //text indexes for sear strings
=> db.collection.find({$text: {$search : 'your string'}})
=> db.collection.find({$text: {$search : 'your string'}}, {score: {$meta : textScore}})
.sort({score: {$meta : textScore}) // the best matchdb.foo.createIndex( { a:1, b:1 } )
db.foo.insert({a: [1,2], b: [1, 2]}) // error only a or b can be arrayoptions:
unique
sparse- not include docs that missing a key
background doesn't block readers and writersREVIEW
1. Indexes are critical to perfomance
2. explain
3.hint (forse index)
4.Profiling
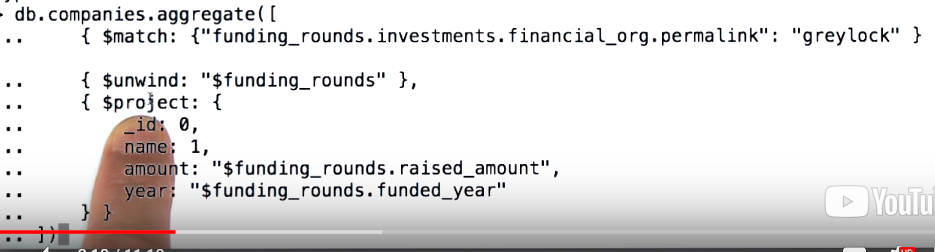
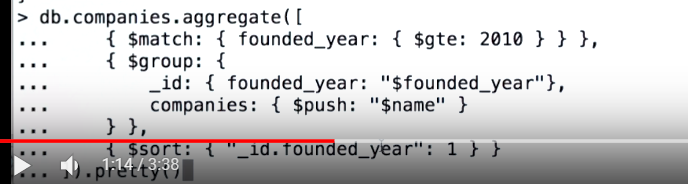
Aggregation is based on the concept of a pipeline. The idea is that we take input from mongodb collection and pass the documents through one or more stages, each of which performs a diffrent operation on its inputs. Содержит набор операций, которые могут быть объединены в цепочки (результат предыдущей операции является входными данными для последующей).
- match
- project
- sort
- skip
- limit
db.articles.aggregate(
[ { $match : { author : "dave" } } ]
);$ - give me the value identefied by this key
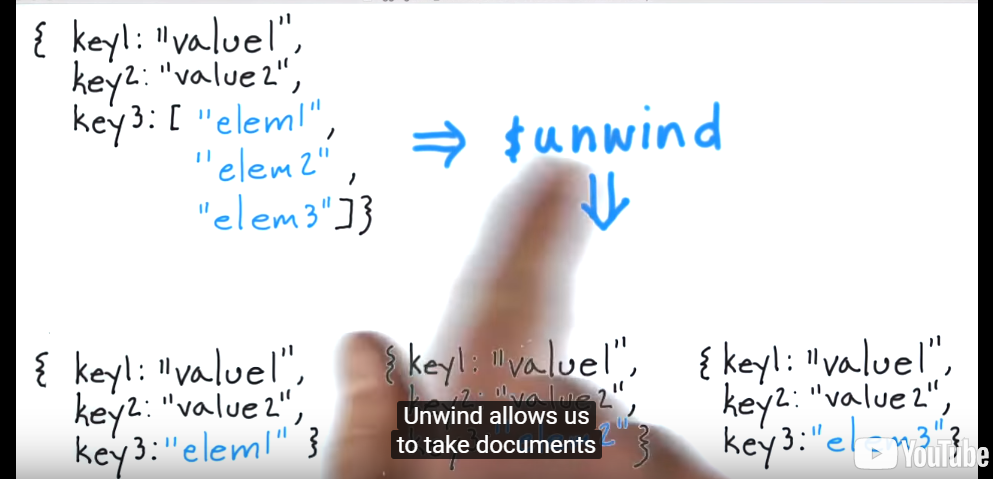
Unwind allows to take documents with an array valued field and produce 1 ouput document for each element of the array. Возвращает новый документ для каждого элемента массива: Массив заменяется значением элемента;

Array expressions
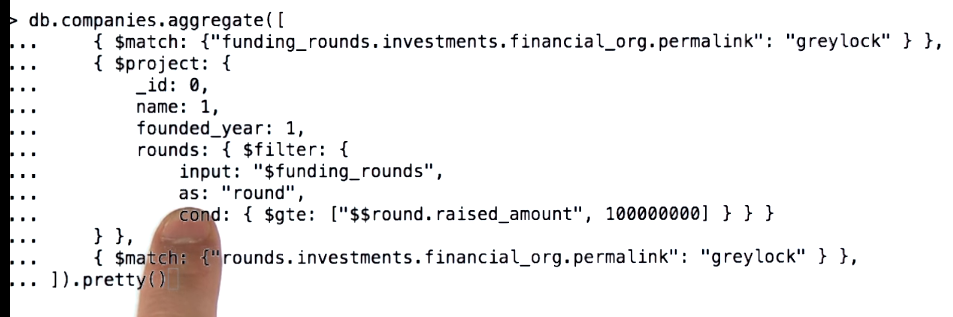
ArrayElementAt (position 0, -1), slice, concat

Groups documents by some specified expression and outputs to the next stage a document for each distinct grouping. The output documents contain an _id field which contains the distinct group by key. The output documents can also contain computed fields that hold the values of some accumulator expression grouped by the $group’s _id field.
{ $group: { _id: <expression>, <field1>: { <accumulator1> : <expression1> }, ... } }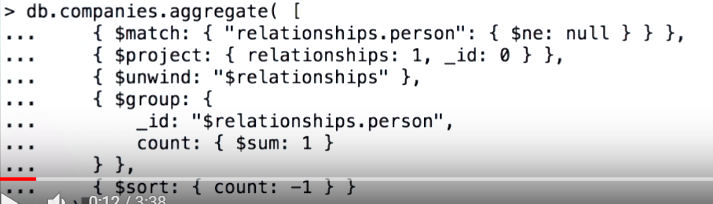
MySQl
Отношение находится в 1НФ, если все его атрибуты являются простыми, все используемые домены должны содержать только скалярные значения. Не должно быть повторений строк в таблице.

Вторая нормальная форма (2NF) предполагает, что каждый столбец, не являющийся ключом, должен зависеть от первичного ключа.
Третья нормальная форма (3NF) предполагает, что каждый столбец, не являющийся ключом, должен зависеть только от первичного ключа.
Первичный ключ уникально идентифицирует строку в таблице. В качестве первичного ключа необязательно должны выступать столбцы с типом int, они могут представлять любой другой тип.
USE productsdb;
CREATE TABLE Customers
(
Id INT,
Age INT,
FirstName VARCHAR(20),
LastName VARCHAR(20),
PRIMARY KEY(Id)
);Внешние ключи позволяют установить связи между таблицами. Внешний ключ устанавливается для столбцов из зависимой, подчиненной таблицы, и указывает на один из столбцов из главной таблицы. Как правило, внешний ключ указывает на первичный ключ из связанной главной таблицы.
CREATE TABLE Customers
(
Id INT PRIMARY KEY AUTO_INCREMENT,
Age INT,
FirstName VARCHAR(20) NOT NULL,
LastName VARCHAR(20) NOT NULL,
Phone VARCHAR(20) NOT NULL UNIQUE
);
CREATE TABLE Orders
(
Id INT PRIMARY KEY AUTO_INCREMENT,
CustomerId INT REFERENCES Customers (Id),
// FOREIGN KEY (CustomerId) REFERENCES Customers (Id) ON DELETE CASCADE
CreatedAt Date
);INSERT [INTO] имя_таблицы [(список_столбцов)] VALUES (значение1, значение2, ... значениеN)
INSERT Products(ProductName, Manufacturer, ProductCount, Price)
VALUES ('iPhone X', 'Apple', 5, 76000);С помощью оператора AS можно изменить название выходного столбца или определить его псевдоним:
SELECT ProductName AS Title, Price * ProductCount AS TotalSum
FROM Products;Для фильтрации данных в команде SELECT применяется оператор WHERE, после которого указывается условие:
WHERE условиеЛогические операторы
SELECT * FROM Products WHERE Manufacturer = 'Samsung' AND Price > 50000
SELECT * FROM Products WHERE Manufacturer = 'Samsung' OR Price > 50000
SELECT * FROM Products WHERE NOT Manufacturer = 'Samsung';Команда UPDATE применяется для обновления уже имеющихся строк.
UPDATE имя_таблицы
SET столбец1 = значение1, столбец2 = значение2, ... столбецN = значениеN
[WHERE условие_обновления]UPDATE Products
SET Manufacturer = 'Samsung',
ProductCount = ProductCount + 3
WHERE Manufacturer = 'Samsung Inc.';DELETE FROM имя_таблицы
[WHERE условие_удаления]IS NOT NULL (IS NULL)
SELECT * FROM topics WHERE id_author IS NOT NULL;
SELECT * FROM topics WHERE id_author IS NULL;IN (значение содержится)
SELECT * FROM topics WHERE id_author IN (1, 4);
SELECT * FROM topics WHERE id_author NOT IN (1, 4);LIKE (соответствие)
SELECT * FROM topics WHERE topic_name LIKE 'вел%';
SELECT * FROM topics WHERE topic_name NOT LIKE 'вел%';С помощью оператора DISTINCT можно выбрать уникальные данные по определенным столбцам.
SELECT DISTINCT Manufacturer FROM Products; (Manufacturer не будут повторяться)SELECT ProductName, ProductCount
FROM Products
ORDER BY ProductCount DESC;Сортировка
Text
Оператор LIMIT позволяет извлечь определенное количество строк и имеет следующий синтаксис:
LIMIT [offset,] rowcount
SELECT * FROM Products
LIMIT 2, 3;Агрегатные функции вычисляют некоторые скалярные значения в наборе строк.
-
AVG: вычисляет среднее значение
-
SUM: вычисляет сумму значений
-
MIN: вычисляет наименьшее значение
-
MAX: вычисляет наибольшее значение
-
COUNT: вычисляет количество строк в запросе
SELECT AVG(Price) AS Average_Price FROM Products
SELECT COUNT(*) FROM Products //число строк
SELECT COUNT(Manufacturer) FROM Products //количество строк по определенному столбцу,
//при этом строки со значениями NULL игнорируются
SELECT MIN(Price), MAX(Price) FROM Products
SELECT SUM(ProductCount) FROM Products
Операторы GROUP BY и HAVING позволяют сгруппировать данные. Они употребляются в рамках команды SELECT:
SELECT столбцы
FROM таблица
[WHERE условие_фильтрации_строк]
[GROUP BY столбцы_для_группировки]
[HAVING условие_фильтрации_групп]
[ORDER BY столбцы_для_сортировки]SELECT Manufacturer, COUNT(*) AS ModelsCount
FROM Products
GROUP BY ManufacturerИспользование HAVING во многом аналогично применению WHERE. Только есть WHERE применяется для фильтрации строк, то HAVING - для фильтрации групп.
Неявное соединение таблиц
SELECT * FROM Orders, Customers
WHERE Orders.CustomerId = Customers.Id;Общий формальный синтаксис применения оператора INNER JOIN:
SELECT столбцы
FROM таблица1
[INNER] JOIN таблица2
ON условие1
[[INNER] JOIN таблица3
ON условие2]SELECT O.CreatedAt, O.ProductCount, P.ProductName
FROM Orders AS O
JOIN Products AS P
ON P.Id = O.ProductId;В отличие от Inner Join внешнее соединение возвращает все строки одной или двух таблиц, которые участвуют в соединении.
SELECT столбцы
FROM таблица1
{LEFT|RIGHT} [OUTER] JOIN таблица2 ON условие1
[{LEFT|RIGHT} [OUTER] JOIN таблица3 ON условие2]...-
LEFT: выборка будет содержать все строки из первой или левой таблицы
-
RIGHT: выборка будет содержать все строки из второй или правой таблицы
Inner Join объединяет строки из дух таблиц при соответствии условию. Если одна из таблиц содержит строки, которые не соответствуют этому условию, то данные строки не включаются в выходную выборку. Left Join выбирает все строки первой таблицы и затем присоединяет к ним строки правой таблицы.
В случае с LEFT JOIN MySQL выбирает сначала всех покупателей из таблицы Customers, затем сопоставляет их с заказами из таблицы Orders через условие Orders.CustomerId = Customers.Id. Однако не у всех покупателей есть заказы. В этом случае покупателю для соответствующих столбцов устанавливаются значения NULL.
транзакция - это последовательность операций, которые должны быть или все выполнены или все не выполнены (все или ничего).
Методом контроля за транзакциями является ведение журнала, в котором фиксируются все изменения, совершаемые транзакцией в БД. Если во время обработки транзакции происходит сбой, транзакция откатывается - из журнала восстанавливаеться состояние БД на момент начала транзакции.
ORM-карты между объектной моделью и реляционной базой данных. ODM-карты между объектной моделью и базой данных документа.
ORM(Object-relational mapping). Вот преобразования или связка полей объектов с данными с БД и выполняет роль ORM.
Nginx/redis/apache
Redis (Remote Dictionary server) – нереляционная СУБД. размещаемое в памяти быстрое хранилище для структур данных «ключ-значение». Redis хранит все данные в памяти, доступ к данным осуществляется по ключу. Этот поход обеспечивает производительность в десятки раз выше реляционных СУБД. Опционально копия данных может храниться на диске.
Все данные Redis находятся в оперативной памяти сервера, в отличие от большинства систем управления базами данных, в которых данные хранятся на жестких дисках или твердотельных накопителях (SSD).
Redis позволяет пользователям хранить ключи, привязанные к различным типам данных. Основной тип данных – это строка, которая может состоять из текстовых или двоичных данных размером до 512 МБ. Redis также поддерживает списки строк (List of Strings), упорядоченные в порядке вставки; множества неупорядоченных строк (Sets of unordered Strings); упорядоченные по результату множества (Sorted Sets); хеш-таблицы (Hashes)
В Redis применяется архитектура «ведущий–подчиненный» и поддерживается асинхронная репликация, при которой данные могут реплицироваться на несколько подчиненных серверов. Это обеспечивает как улучшенные характеристики чтения (так как запросы могут быть распределены между серверами), так и восстановление при отключении основного сервера.
Примеры использования
Кэширование
Если Redis поместить «перед» другой базой данных, создается высокопроизводительный кэш в памяти, который уменьшает задержку доступа, увеличивает пропускную способность и уменьшает нагрузку на базу данных
Управление сессиями
Redis отлично подходит для задач управления сессиями. Можно просто использовать Redis как быстрое хранилище пар «ключ-значение» с соответствующим временем жизни (TTL) ключей сессии для управления информацией сессии.
Таблицы лидеров в режиме реального времени
С помощью структуры данных Redis Sorted Set элементы хранятся в списке, отсортированном по их результатам. Это позволяет легко создавать динамические таблицы лидеров, показывающие, кто побеждает в игре, или размещать наиболее понравившиеся сообщения,
Ограничение интенсивности
Redis может измерять и при необходимости ограничивать скорость наступления событий. Используя счетчик Redis, связанный с ключом API клиента, можно подсчитать количество запросов на доступ за определенный период времени и принять меры при превышении лимитов.
Чат и обмен сообщениями
Redis поддерживает стандарт «издатель-подписчик», а также сопоставления с шаблоном. Это позволяет использовать Redis для создания высокопроизводительных комнат чата, лент комментариев, работающих в режиме реального времени, и систем взаимодействия серверов.
Прокси-сервер (от англ. proxy — «представитель, уполномоченный») — промежуточный сервер (комплекс программ) в компьютерных сетях, выполняющий роль посредника между пользователем и целевым сервером , позволяющий клиентам как выполнять косвенные запросы (принимая и передавая их через прокси-сервер) к другим сетевым службам, так и получать ответы.
Грубо говоря, сервер может отдавать статическое или динамическое содержимое.
«Статическое» означает «отдается как есть». «Динамическое» означает, что сервер обрабатывает данные или даже генерирует их на лету из базы данных. Это обеспечивает больше гибкости, но технически сложнее в обслуживании, что делает его более сложным для создания веб-сайта.
Главная задача веб сервера принимать HTTP-запросы от пользователей, обрабатывать их, переводить в цифровой компьютерный код. Затем выдавать HTTP-ответы, преобразуя их из миллионов нолей и единичек в изображения, медиа-потоки, буквы, HTML страницы.

NGINX — программное обеспечение, написанное для UNIX-систем. Основное назначение — самостоятельный HTTP-сервер(веб-сервер), или, как его используют чаще, фронтенд для высоконагруженных проектов (http-прокси с переадресацией веб-запросов на другие сервера. )
Как правило, его используют либо как самостоятельный HTTP-сервер, используя в бекенде PHP-FPM, либо в связке с Apache, где NGINX используется во фронтэнде как кеширующий сервер, принимая на себя основную нагрузку, отдавая статику из кеша, обрабатывая и отфильтровывая входящие запросы от клиента и отправляя их дальше к Apache. Apache работает в бекэнде, работая уже с динамической составляющей проекта, собирая страницу для передачи её в кеш NGINX и запрашивающему её клиенту.
Session
JSON Web Token (JWT) — это открытый стандарт (RFC 7519) для создания токенов доступа, основанный на JSON формате. Как правило, используется для передачи данных авторизации в клиент-серверных приложениях. Токены создаются сервером, подписываются секретным ключом и передаются клиенту, который в дальнейшем использует данный токен для подтверждения своей личности.
Токен JWT состоит из трех частей: заголовок (header), полезная нагрузка (payload) и подпись или данные шифрования. Первые два элемента — это JSON объекты определенной структуры. Третий элемент вычисляется на основании первых и зависит от выбранного алгоритма. Токены могут быть перекодированы в компактное представление (JWS/JWE Compact Serialization): к заголовку и полезной нагрузке применяется алгоритм кодирования Base64-URL, после чего добавляется подпись и все три элемента разделяются точками («.»).
В заголовке указывается необходимая информация для описания самого токена.
Обязательный ключ здесь только один:
- alg: алгоритм, используемый для подписи/шифрования (в случае не подписанного JWT используется значение «none»).
Полезная нагрузка
В данной секции указывается пользовательская информация (например, имя пользователя и уровень его доступа), а также могут быть использованы некоторые служебные ключи. Все они являются необязательными:
Access и refresh токены
- Access-токен — это токен, который предоставляет доступ его владельцу к защищенным ресурсам сервера. Обычно он имеет короткий срок жизни и может нести в себе дополнительную информацию, такую как IP-адрес стороны, запрашивающей данный токен.
- Refresh-токен — это токен, позволяющий клиентам запрашивать новые access-токены по истечении их времени жизни. Данные токены обычно выдаются на длительный срок.
Схема работы
Как правило, при использовании JSON токенов в клиент-серверных приложениях реализована следующая схема:
- Клиент проходит авторизацию в приложении (к примеру, с использованием логина и пароля)
- В случае успешной авторизации сервер отправляет клиенту access- и refresh-токены.
- При дальнейшем обращении к серверу, клиент использует access-токен. Сервер проверяет токен на валидность и предоставляет клиенту доступ к ресурсам
- В случае, если access-токен становится не валидным, клиент отправляет refresh-токен, в ответ на который сервер предоставляет два обновленных токена.
- В случае, если refresh-токен становится не валидным, клиент опять должен пройти процесс авторизации
const SECRET_KEY = 'cAtwa1kkEy'
const unsignedToken = base64urlEncode(header) + '.' + base64urlEncode(payload)
const signature = HMAC-SHA256(unsignedToken, SECRET_KEY)Алгоритм base64url кодирует хедер и payload, созданные на 1 и 2 шаге. Алгоритм соединяет закодированных строки через точку. Затем полученная строка хешируется алгоритмом, заданным в хедере на основе нашего секретного ключа.
Cookie — это просто пара имя-значение, которую (точнее, которые) сервер может оставить у клиента (браузера). Наглядно:
1. Приходит клиент, спрашивает у сервера страницу.
2. Сервер в заголовках ответе может установить cookies. Например, выдав два заголовка: Set-Cookie: foo=123 и Set-Cookie: bar=baz — по-русски — «запомни, foo — 123, а bar — baz».
3. При следующем обращении клиент, если он решил запомнить, говорит серверу «Cookie: bar=baz; foo=123».
Упрощенно, не затрагивая тонкости — все, вот все, что представляют собой cookies.
Сессии — более эфемерное понятие, которое не привязано к какой-то конкретной реальной технологии. Это просто некая методика, которая позволяет отличить одного клиента от другого, и, как правило, где-то хранить связанные с каждым клиентом данные.
Как правило, сессии реализуются используя cookies и идентификаторы сессий. Т.е. сервер со своей стороны создает уникальный идентификатор, например, «1a2b3c» (session_id про который вы справшивали), а клиента просит его запомнить. Обычно — при помощи cookies, говоря что-то в духе Set-Cookie: PHPSESSID=1a2b3c (где «PHPSESSID» — имя сессии, обычно, оно только одно, вести параллельно несколько сессий нужно редко). Со своей стороны сервер где-то (зависит от реализации, иногда это файл, например, /tmp/1a2b3c, иногда запись в БД, иногда еще что-то) хранит различные данные, которые ему приказано связывать с этой сессией. Например, имя пользователя.
Чем cookies, отличаются от session. Сессии хранятся на сервере, ну точнее, где-то не на клиенте. Но, на клиенте в cookies хранится идентификатор сессии на сервере.
А cookies соответственно хранятся полностью на клиенте.
Реактивное программирование — это когда ты вместо обработки событий по одному объединяешь их в поток и затем работаешь уже только с ним.
(Дата, Подпись, Печать).
Everything you need to know
By Anastasia Shemetillo



