Computer Vision

1:30-3:30pm
-
Distant Reading, Distant Viewing
-
Activity with Pixplot and Princeton Slavic Collections
-
A Distant Viewing Toolkit for Image Collections
11:30-12:00
-
What is computer vision?
-
What and how does a computer "see?"
What is computer vision?
Image classification


Image description

Object detection


Facial recognition
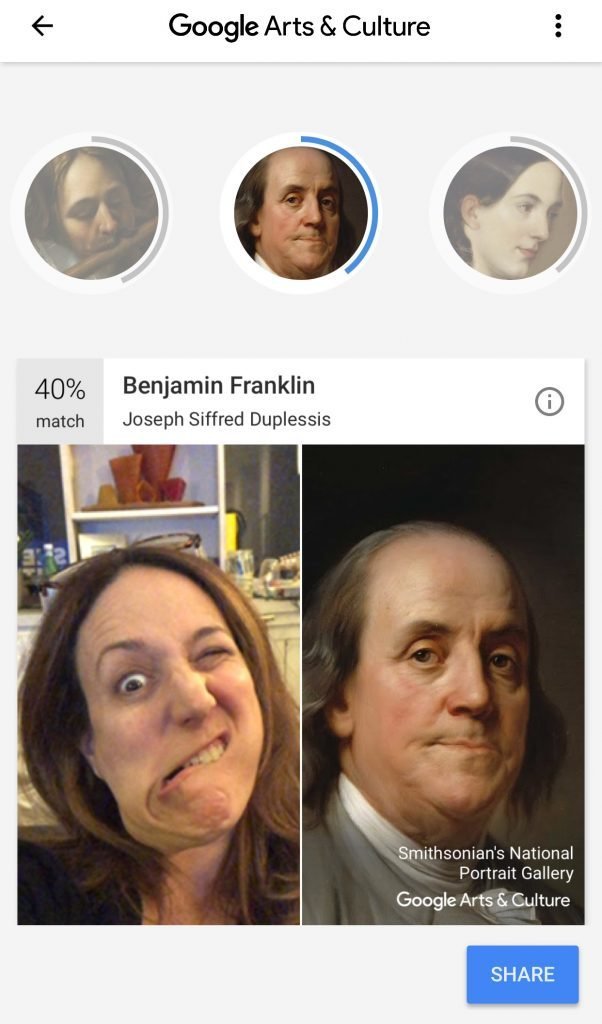
Text recognition

Image Inpainting


Colorization

CGANs
How and what do computers "see?"


Pixels are Numbers

Image Kernels
Distant Reading
Distant reading is the idea of processing content in...or information about... a large number of textual items without engaging in the reading of the actual text. The “reading” is a form of data mining that allows information in the text or about the text to be processed and analyzed.
Distant Viewing
...a methodological and theoretical framework for studying large collections of visual materials. Distant viewing is distinguished from other approaches by making explicit the interpretive nature of extracting semantic metadata from images.





Text
Ben Schmidt, machine reading the Hathi Trust (14 million volumes. About as many as there are books in the Library of Congress)
Activity (10 minutes)
a) click here
b) explore the image clusters
c) what is the machine able to see very clearly?
d) could these clusters be useful in art historical research?
Distant Viewing Toolkit
Video
vision models
JSON data for each frame
9-types of annotations
4 types of aggregators
BookNLP for Videos
Distant Viewing Toolkit
I really wanted to use DVT for this workshop however:
- It does not yet support single image files as input (it will)
- No means of tailoring the vision model to project-specific features.
- Output data is JSON, which is unfamiliar to many scholars.
A Distant Viewing Toolkit for Image Collections

A journey...
Objectives
- Create an accessible tool for the research of large image collections using computer vision
- Use IIIF URIs (and local folders)
- Both pre-trained models and customized models for research-relevant categories and objects.
- Export to CSV for use in visualization (Palladio) or exhibits (Omeka).

IIIF Manifest
pre-trained models
CSV file
Palladio
Omeka
Custom research-tailored computer vision models

IIIF Collection Manifest
- Ask a librarian for one (thank you Thomas!)
- Here is the manifest for Princeton's Slavic Collections
- { 'key' : 'value' } (try entering the URL here)
- It is a list of the manifests for each collection
- Each collection has a list of images and metadata
- With the manifest, we can generate a list of the URIs for all 8230 images
Pre-trained Models
Open this Notebook and see what results you get for your images with Google Vision
Vision label detection on a full image collection

Step-by-step
- Download the csv file
- Open Palladio and click Start >>
- Drag the CSV file into the "Load .csv or spreadsheet" box and "Load"
- Click the red dot in the "Labels" row, then enter a comma in the "Multiple values" field
- Switch to gallery and the change labels:
- Title - title
- Subtitle - Subject
- Text - labels
- Link - URI
- Image URL - URI
- Open facets add dimention for labels
- Add facet for timeline

Custom research-tailored computer vision models
Google AutoML Vision

Would this be useful in your research?
What would you need to use it?
What data would be most useful?
Further Reading
- Convolutional Networks
- Image Analysis with Deep Learning
- The visual digital turn: Using neural networks to study historical images
- Made by Machine: When AI Met the Archive
- Contextualising Bandera. Eine Distant Watching-Methode
- Attesting similarity: Supporting the organization and study of art image collections with computer vision

Computer Vision
By Andrew Janco



