New Tools for Old Documents




22 October
Updates
New model Qwen-VL
An open-source multi-modal large vision-language model (VLM) that is really good at reading handwriting.
1.
Marshall Diary
Qwen has read the diary and given us good text to work from.
- How best to review and edit the transcriptions?
2.
On to Istmina (EAP)
For the Istmina court materials, we will likely need to fine-tune the model on our materials. What does that mean? Why do it? How do we do it?
3.


Attention and next word prediction

Vision Transformer (ViT)











mensual para accionistas

Vision encoder
Text decoder
Intermediate representations (hidden state)
[1.2223,0.3343,3.2314,5.3343...]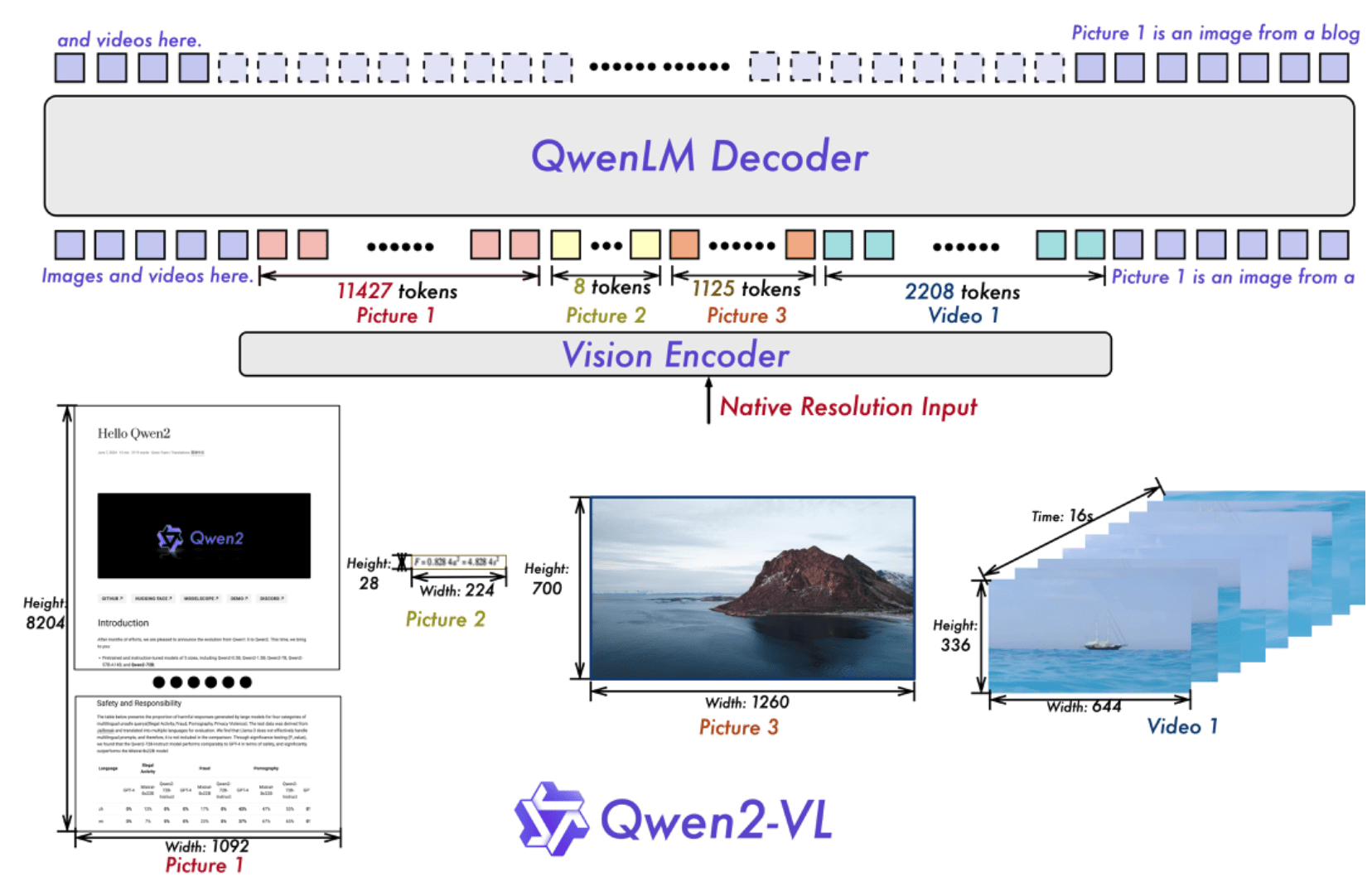
https://huggingface.co/spaces/GanymedeNil/Qwen2-VL-7B
2 billion parameter model
also 7 billion and 72 billion parameter variants
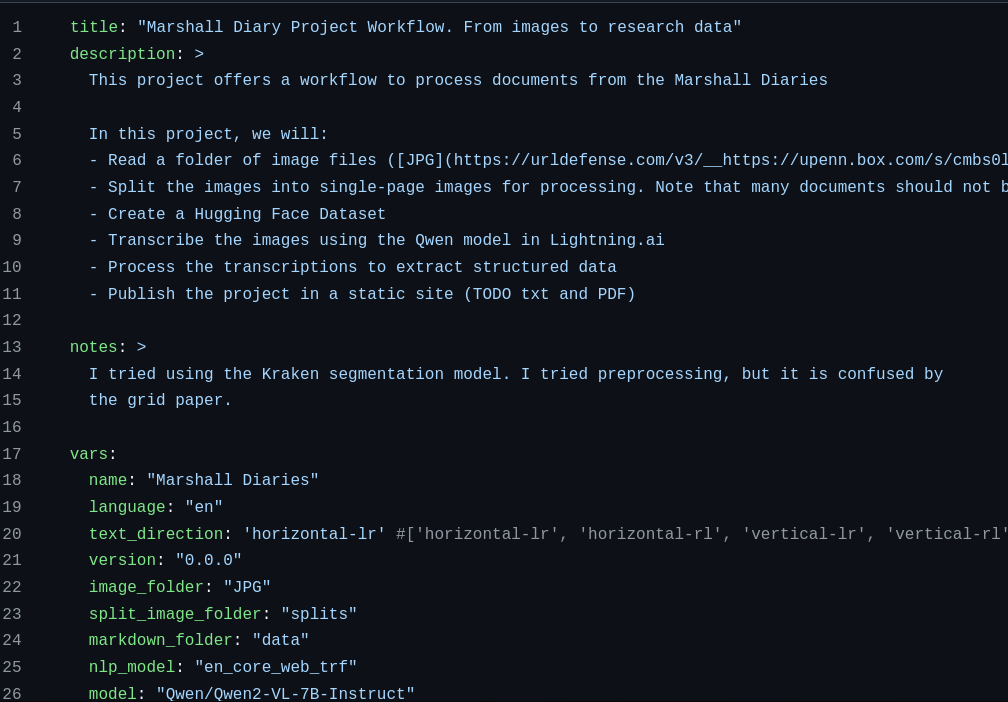
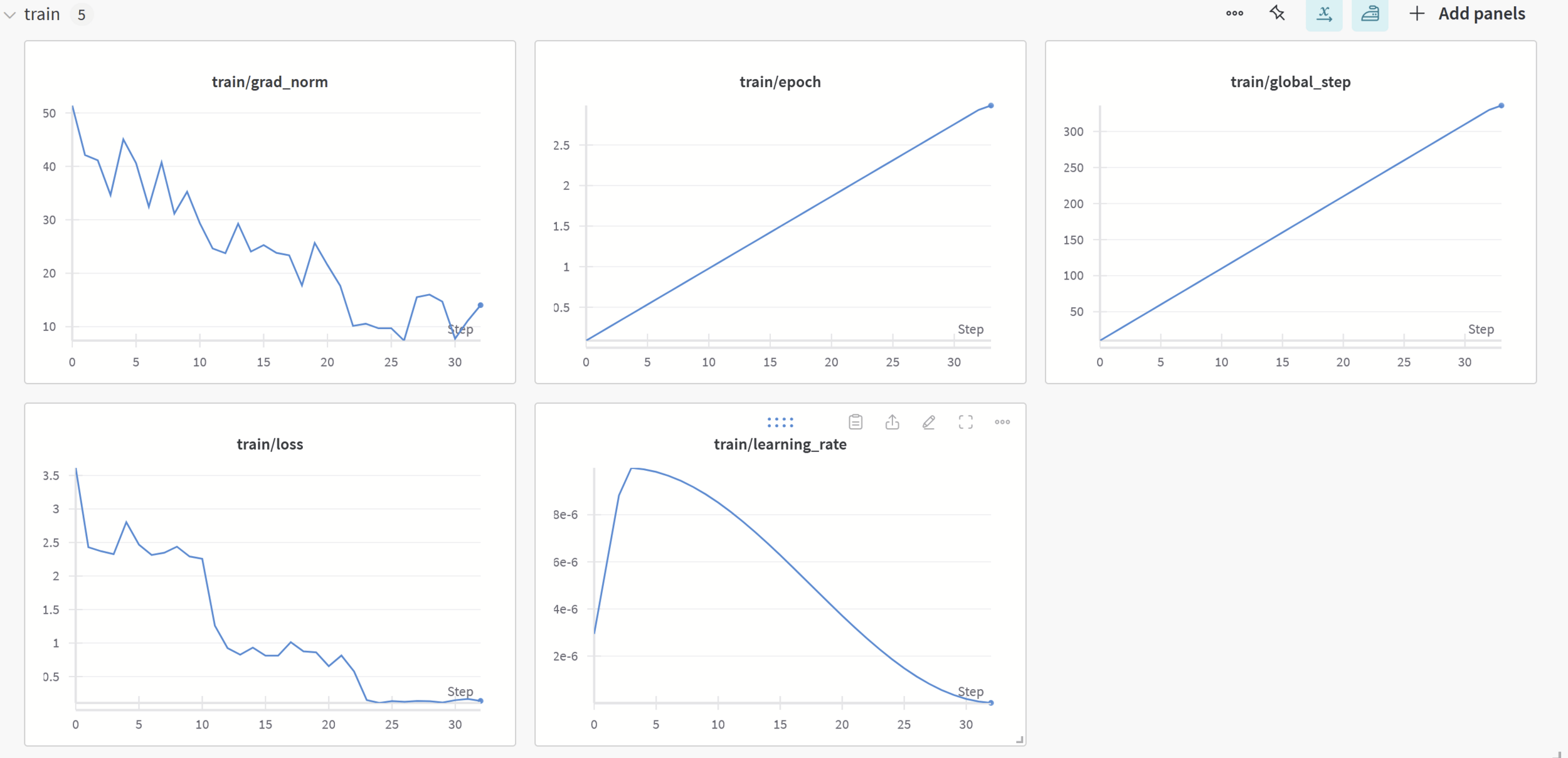
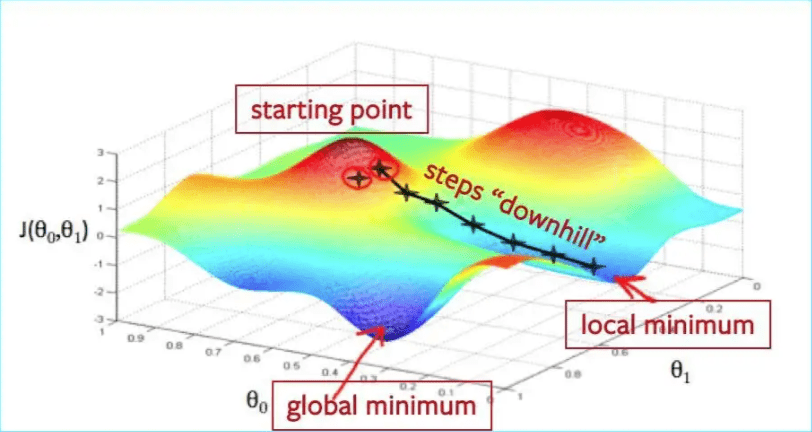
Fine-tuning Qwen2-VL

NewToolsOldDocs-Oct24
By Andrew Janco




