Cadet: A Tool to Add New Language Models to spaCy

Language Data + Models

Universal Dependencies
90 languages
StanfordNLP
53 languages
Polyglot 51 languages
DARIAH-RS
- Serbian is a bigraphic language: it can be written in both Cyrillic and Latin, but current UD data only contains Cyrillic
- Standard Serbian has two major dialects, Ekavian and Jekavian, which means that some words are not just pronounced but also written differently: млеко (mleko) vs. млијеко (mlijeko) = milk.

(Toma Tasovac)
To each project its own Data
To each project its own model

Every NLP project can benefit from the fine-tuning of statistical language models on project materials. This is especially true for:
- Languages without existing linguistic data or models
- Historical and regional variations of language
- Domain-specific language
- Multilingual texts

Always in tune
🌘 Cadet
in development


guest ~monolingualism
- Accesible to non-programmers
- Provide clear workflow for small teams to create new language and domain-specific models for spaCy

Interface to add or edit stop words, tokenization rules, lemmata, normalization rules, for base language object

Run as an external recommender for INCEpTION to generate annotation data
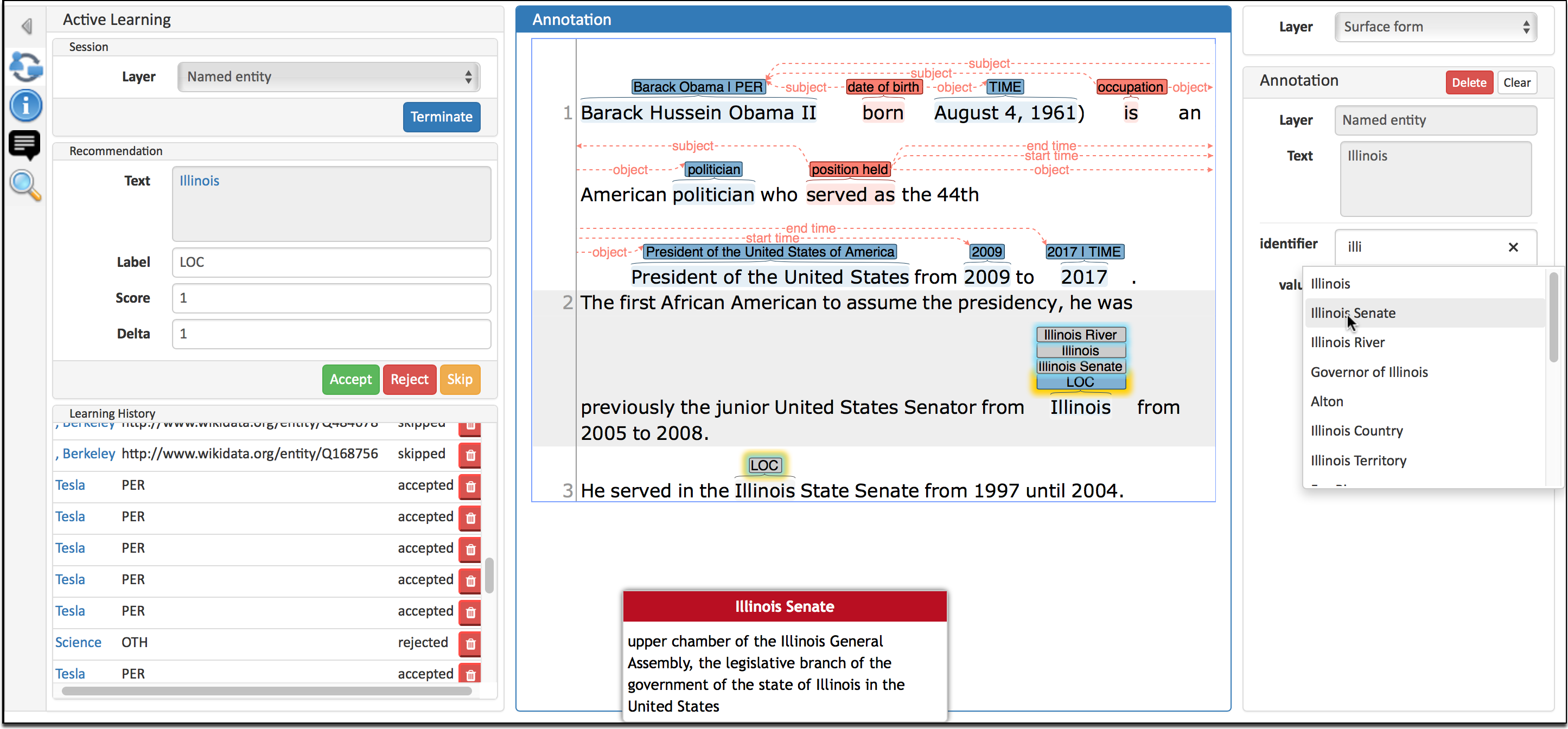
Actively update the spaCy model from annotations
Debug and batch train on annotation data
Package and export customized spaCy model

#TODO
Demo
- create project
- create custom language model
- serve the model to the web
- load INCEpTION and configure to load suggestions from cadet.apjan.co
- add annotations

Cadet
By Andrew Janco
Cadet
Disrupting Digital Monolingualism workshop, June 16, 2020



