How to work with the data:
Kaggle approach
Andrey Lukyanenko
MLE @ Meta

About me
- ~4 years as ERP-system consultant
- DS/MLE since 2017
- Lead a medical chatbot project, an R&D CV team
- Senior DS at Careem: anti-fraud, recommendation system, LLM-based products
- MLE at Meta: Monetization team
- Google Developer Expert: Kaggle category
Home Credit Default Risk
- The goal is to predict default risk
- Default risk is correlated to the interest rate
- Interest rate wasn't present in the data
- Based on AMT_CREDIT, AMT_ANNUITY, and CNT_PAYMENT we can derive interest rate
- Annuity x CNT payments / Amount of Credit = (1+ir) ^ (CNT payment /12)
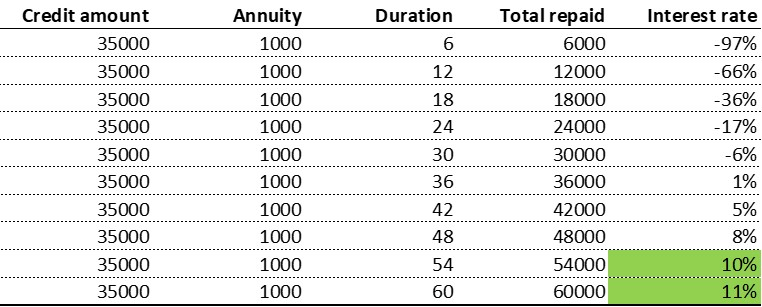
Sberbank Russian Housing Market
- Predict prices of Russian apartments
- The economy drives prices -> oil/gas prices are very important, information on sanctions is influential too
- Cleaning data was crucial; otherwise, it was too noisy: fixing outliers
- Proxy of "market temperature": number of sales per period
Rossmann Store Sales
- Predict daily sales of stores
- Test data included the end of summer break
- Weather, holidays, macro and search trends are important -> need to get external data
- Store ID -> State -> Weather Station
Predicting Red Hat Business Value
- Binary classification: predict customer potential value
- Data: train and test activity files, profile info
- Some people were in both the train and test and shared the label
- One categorical column almost always had the same label for all customers in it on the same date
- Train model for the remaining customers
Intel & MobileODT Cervical Cancer Screening
- Predict women's cervical type based on images
- The same patient could have images in both the train and the test set
- Patients identified by image matching or file name prefix
- It was crucial to use patient-based validation
- Manually removing bad quality images from the train data vs data augmentation
IEEE-CIS Fraud Detection
- No user_id in the data
- User ID Proxy: card info, billing zip, email, device info
- Create user-level features
- User-based validation
- All user-level transactions should have the same prediction
Quora Question Pairs
- Determine if two questions are duplicates
- It turned out that there is an overlap between train and test
- Many questions appeared multiple times
- The key: build a graph on train + test, then traverse and do Union-Find or BFS
- Neighbour statistics
Two Sigma Connect: Rental Listing Inquiries
- Predict interest (low, medium, high) for the listing
- Folder with images had timestamps
- Timestamps were correlated with the classes: newer listings had low interest, older listings had high interest
Instant Gratification
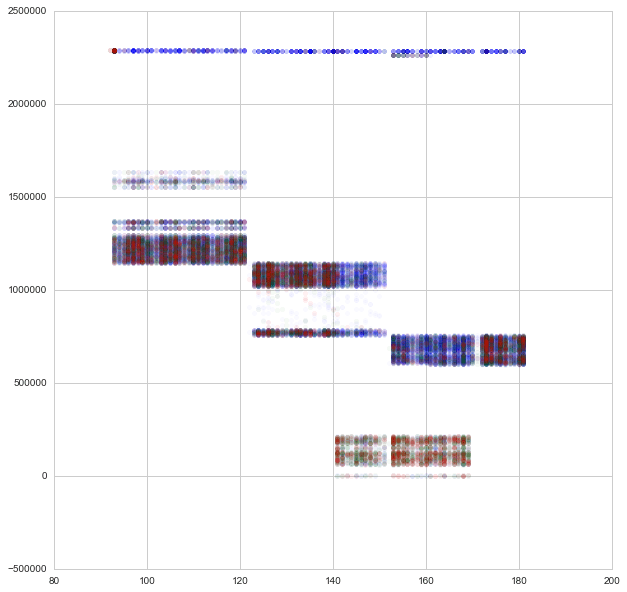
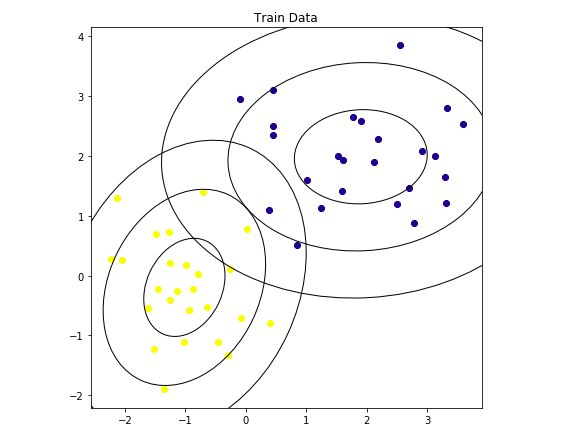
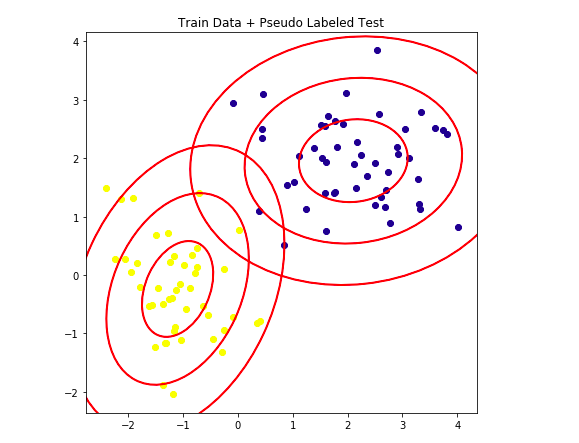
- Synthetic data, 528 columns
- Participants discovered that the data was generated using Gaussian Mixture Models
- Per group, only 33‑47 features had noticeably larger variance; the rest looked like pure N(0, 1) noise
- wheezy-copper-turtle-magic has 512 unique values
- Train 512 GMM models with 3 clusters per class
Conclusions
- Create domain-based features
- Think what additional information could be useful
- Find patterns in the behavior
- Build a robust validation approach
- Try to reformulate the problem
- Think on how was the data collected
Contacts
kaggle_data
By Andrey Lukyanenko



