История разработки медицинского чат-бота
Андрей Лукьяненко
Senior DS @ Careem

Содержание
- Предыстория
- Структура проекта
- Сбор и разметка данных
- Machine Learning
- Идеи, которые не сработали
- Что пошло не так
Предыстория
- Рынок телемедицины растёт
- На рынке уже есть решения
- Наше решение - чат-бот для первичного опроса
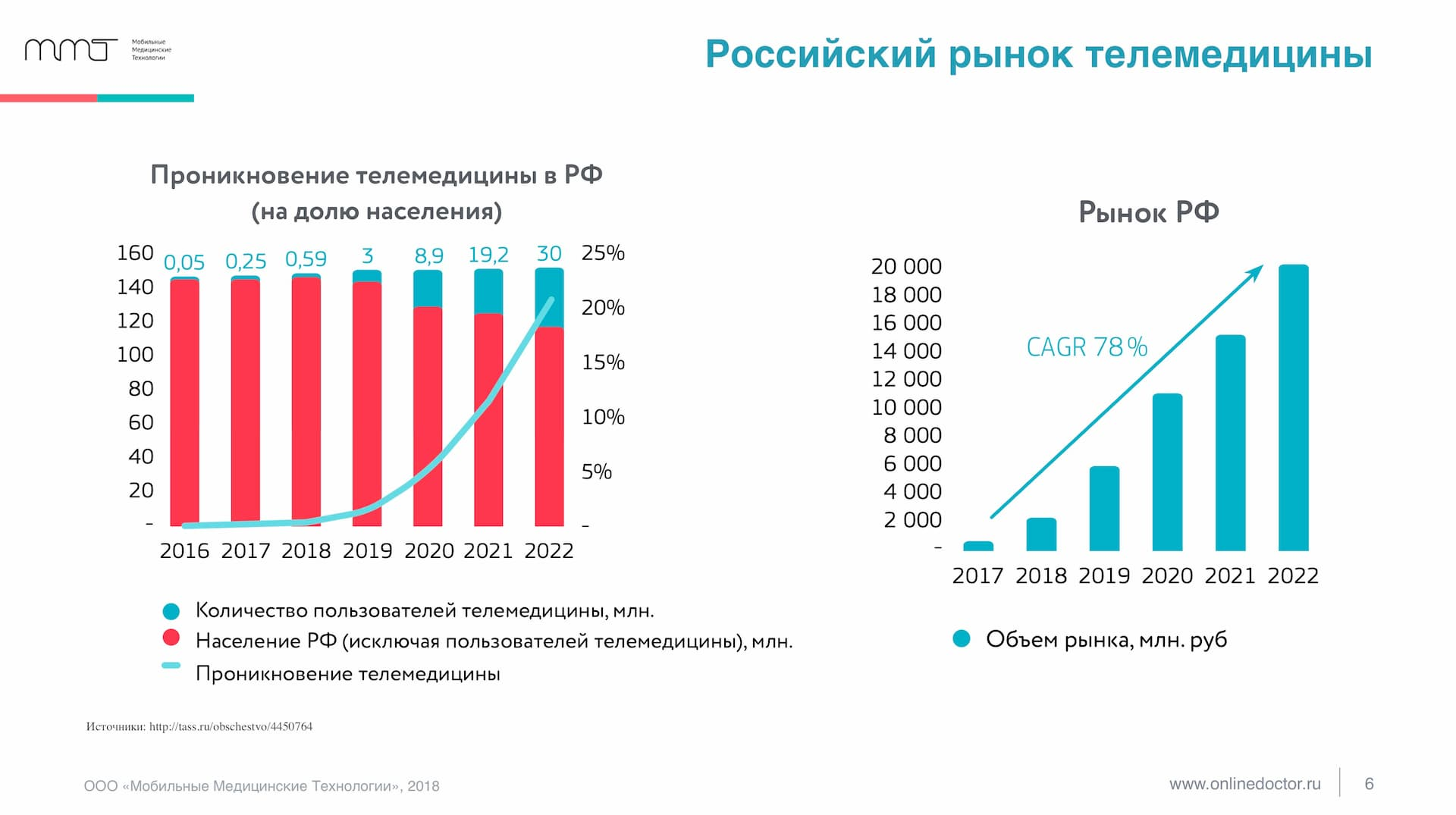
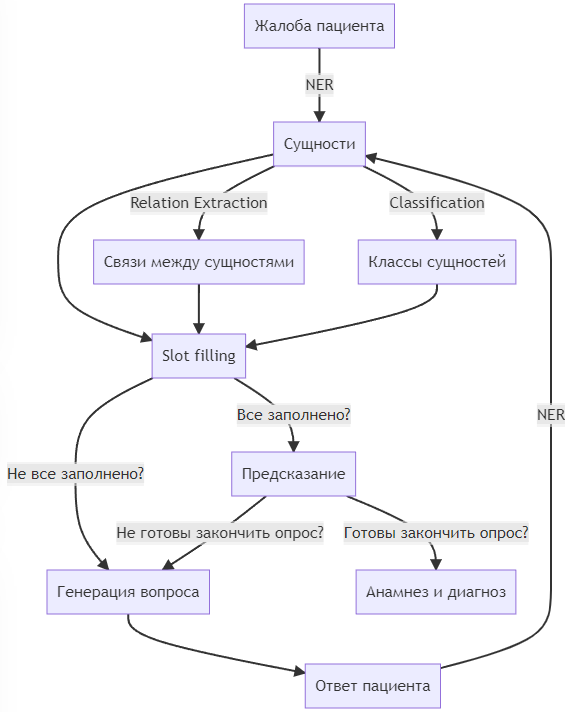
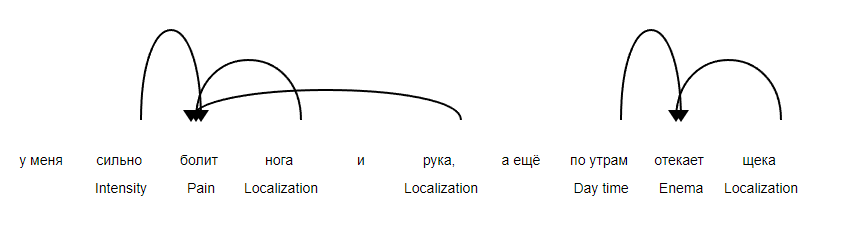
Работа с данными
- Сложно собрать релевантные данные
- Нет публичных датасетов и претренированных моделей
- Составление инструкций по разметке
- Кросс-разметка очень помогает
- Очень важно управлять качеством разметки
- Баланс качества и трудозатрат

Обработка текста
- Расшифровка аббревиатур
- Пре- и Пост-процессинг
from spacy.tokenizer import Tokenizer
from spacy.util import compile_infix_regex, compile_suffix_regex, compile_prefix_regex
def custom_tokenizer(nlp):
suf = list(nlp.Defaults.suffixes) # Default suffixes
# Удаление suffixes , чтобы spacy не разбивал слитно написанные слова по типу '140мм рт ст'
del suf[75]
suffixes = compile_suffix_regex(tuple(suf))
# remove №
inf = list(nlp.Defaults.infixes)
inf[2] = inf[2].replace('\\u2116', '')
infix_re = compile_infix_regex(inf)
pre = list(nlp.Defaults.prefixes)
pre[-1] = pre[-1].replace('\\u2116', '')
pre_compiled = compile_prefix_regex(pre)
return Tokenizer(nlp.vocab,
prefix_search=pre_compiled.search,
suffix_search=suffixes.search,
infix_finditer=infix_re.finditer,
token_match=nlp.tokenizer.token_match,
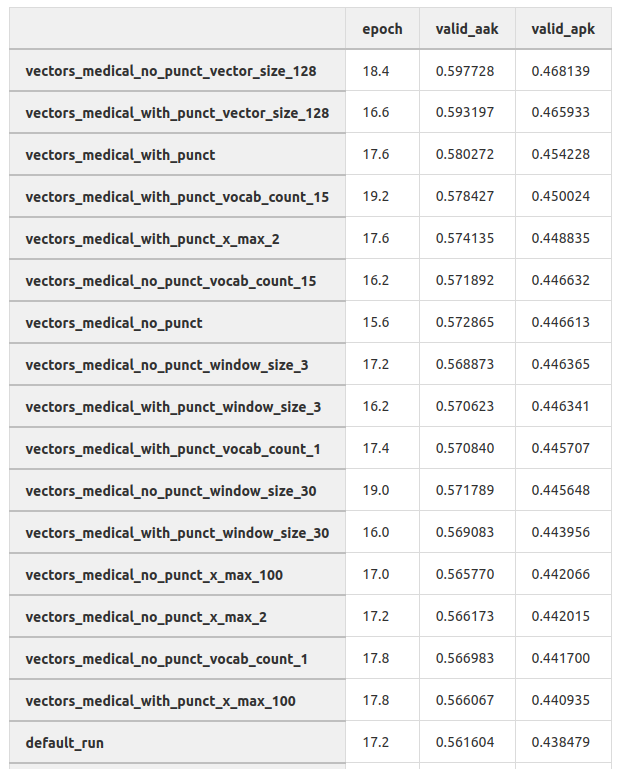
rules=nlp.Defaults.tokenizer_exceptions)Эмбеддинги
Модели NER
- Правила + RegEx
- Spacy
- BiLSTM
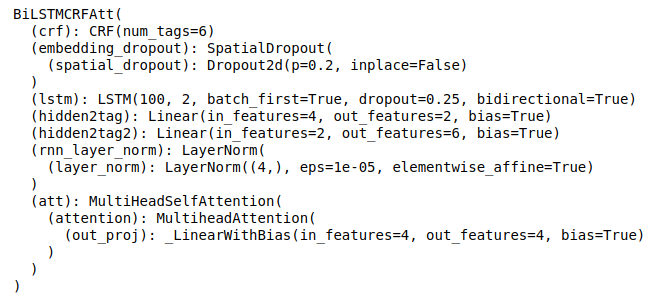
Модели классификации
combined_features = FeatureUnion([('tfidf', TfidfVectorizer(ngram_range=(1, 3))),
('tfidf_char', TfidfVectorizer(ngram_range=(1, 3),
analyzer='char'))])
pipeline = Pipeline([('features', combined_features),
('clf', LogisticRegression(class_weight='balanced',
solver='lbfgs',
n_jobs=10,
multi_class='auto'))])Relation Extraction
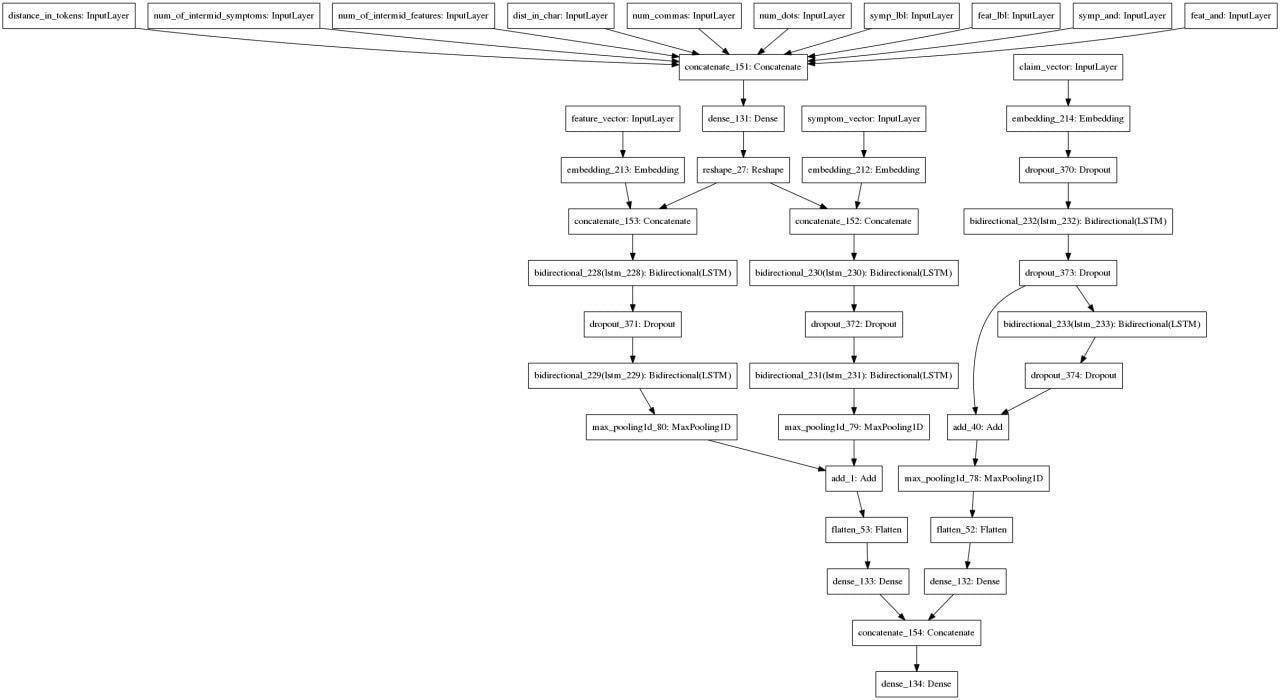
Аугментация текста
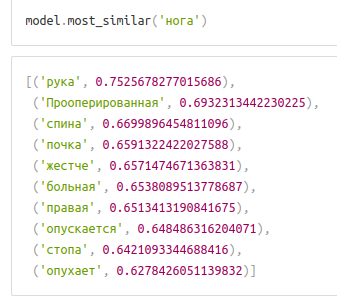
Мелкие технические моменты
- yaml-конфиги
- ci/cd для проверок стиля
- Проверка моделей на "золотом" датасете
- Оптимизация скорости и памяти
single_entities_models:
localization:
model_name: pytorch_ner.PytorchNerWrapper
params:
path: localization.pth
ner_name: localization
idx2label_path: idx2label.json
config_path: config.json
preprocessing: True
productivity:
model_name: pytorch_ner.PytorchNerWrapper
params:
path: productivity.pth
ner_name: productivity
idx2label_path: productivity_pytorch_220920/idx2label.json
config_path: productivity_pytorch_220920/config.json
preprocessing: TrueИдеи, которые не сработали
- Одна модель на все сущности
- Лемматизация
- Исправление опечаток
- ONNX
Что пошло не так
- Слишком сложная разметка данных
- Не было фидбека про качество моделей
- Изменения требований
- Не было критериев качества проекта
Польза от проекта
- Опыт
- Active learning
- Модели
- Пайплайны
- Проект заморожен, но не мёртв
Контакты
-
ods.ai @artgor
Medical chat bot
By Andrey Lukyanenko



