Writing reusable training pipelines for deep learning
Andrey Lukyanenko
DS TechLead, MTS AI
About me
- ~4 years as ERP-system consultant
- self-study for switching career
- DS since 2017
- NLP TechLead in medical chat-bot project
Content
- Styles of writing training code
- Reusable pipeline: why do it and how to start
- Functionality of training pipeline


Styles of writing code

Training pipeline







Reasons for writing pipeline
- Writing everything from scratch takes time and can have errors
- You have repeatable pieces of code anyway
- Better understanding how the things work
- Standardization among the team
My pipeline

My pipeline
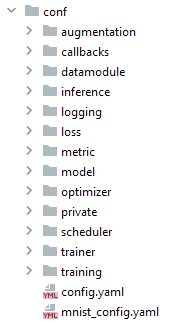
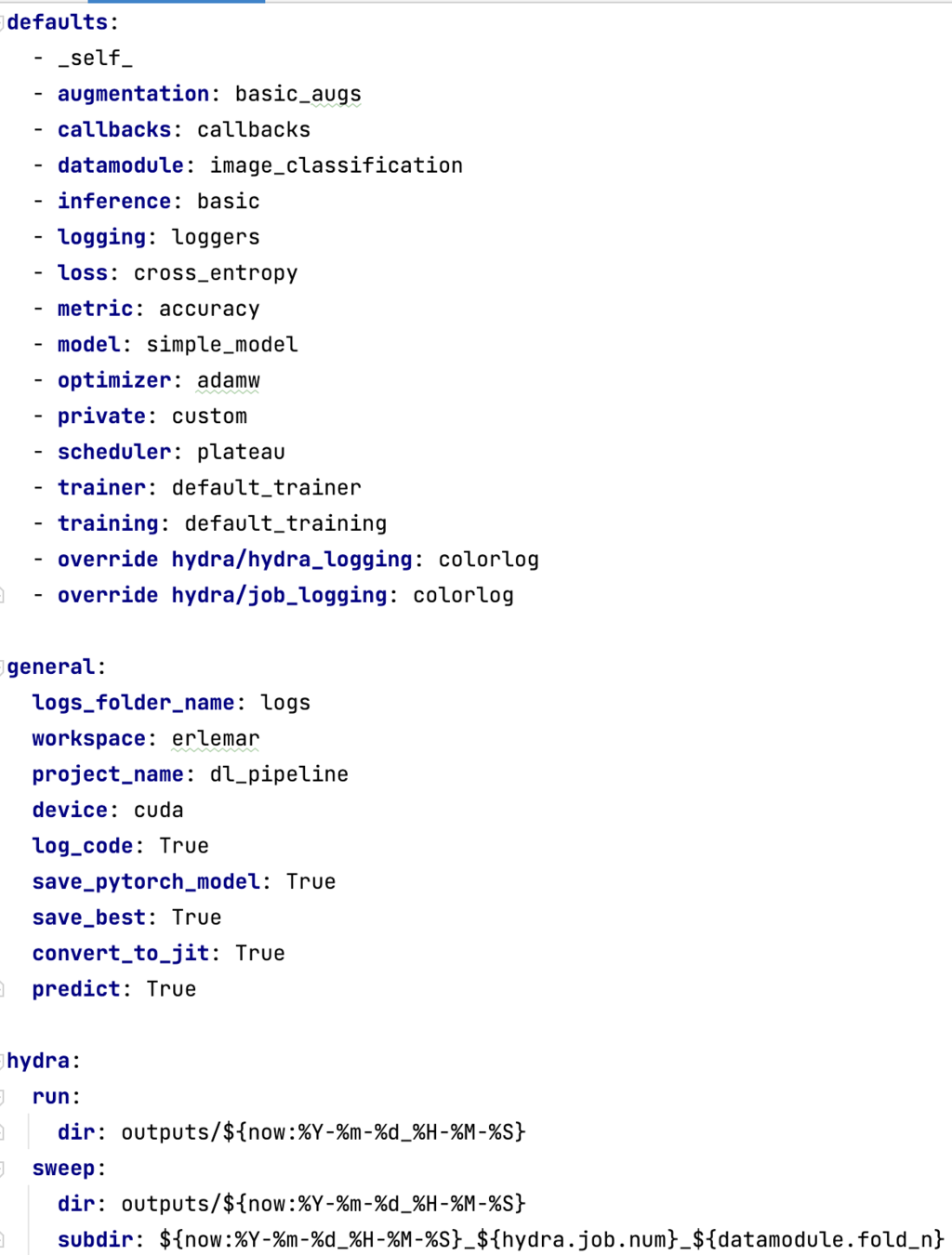
My pipeline
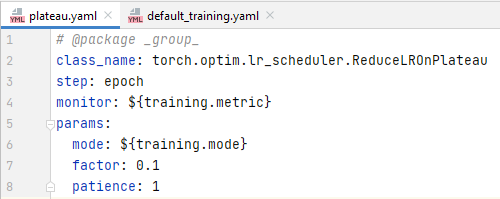

def configure_optimizers(self):
optimizer = load_obj(self.cfg.optimizer.class_name)(self.model.parameters(),
**self.cfg.optimizer.params)
scheduler = load_obj(self.cfg.scheduler.class_name)(optimizer,
**self.cfg.scheduler.params)
return (
[optimizer],
[{'scheduler': scheduler,
'interval': self.cfg.scheduler.step,
'monitor': self.cfg.scheduler.monitor}],
)
My pipeline
>>> python train.py
>>> python train.py optimizer=sgd
>>> python train.py model=efficientnet_model
>>> python train.py model.encoder.params.arch=resnet34
>>> python train.py datamodule.fold_n=0,1,2 -m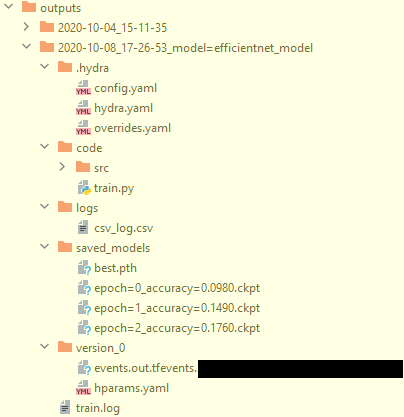
@hydra.main(config_path='conf', config_name='config')
def run_model(cfg: DictConfig) -> None:
os.makedirs('logs', exist_ok=True)
print(cfg.pretty())
if cfg.general.log_code:
save_useful_info()
run(cfg)
if __name__ == '__main__':
run_model()Training loop
def training_step(
self, batch: torch.Tensor, batch_idx: int
) -> Union[int, Dict[str, Union[torch.Tensor, Dict[str, torch.Tensor]]]]:
image = batch['image']
target = batch['target']
logits, loss = self(image, target)
score = self.metric(logits.argmax(1), target)
logs = {'train_loss': loss, f'train_{self.cfg.training.metric}': score}
return {
'loss': loss,
'log': logs,
'progress_bar': logs,
'logits': logits,
'target': target,
f'train_{self.cfg.training.metric}': score,
}
def training_epoch_end(self, outputs):
avg_loss = torch.stack([x['loss'] for x in outputs]).mean()
y_true = torch.cat([x['target'] for x in outputs])
y_pred = torch.cat([x['logits'] for x in outputs])
score = self.metric(y_pred.argmax(1), y_true)
logs = {'train_loss': avg_loss, f'train_{self.cfg.training.metric}': score}
return {'log': logs, 'progress_bar': logs}Reproducibility
def set_seed(seed: int = 42) -> None:
np.random.seed(seed)
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)Experiment tracking





Changing hyperparameters
>>> python train.py optimizer=sgd
>>> python train.py trainer.gpus=2Basic functionality
- Easy to modify for a similar problem
- Make predictions
- Make predictions without pipeline
- Changing isn't very complicated
Useful functionality
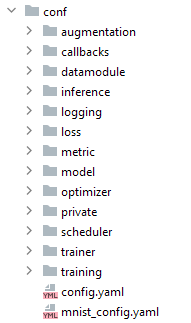
- Configs, configs everywhere
- Templates of everything
- Training on folds and hyperparameter optimization
- Training with stages
- Using pipeline for a variety of tasks
- Sharable code and documentation
- Various cool tricks
Links
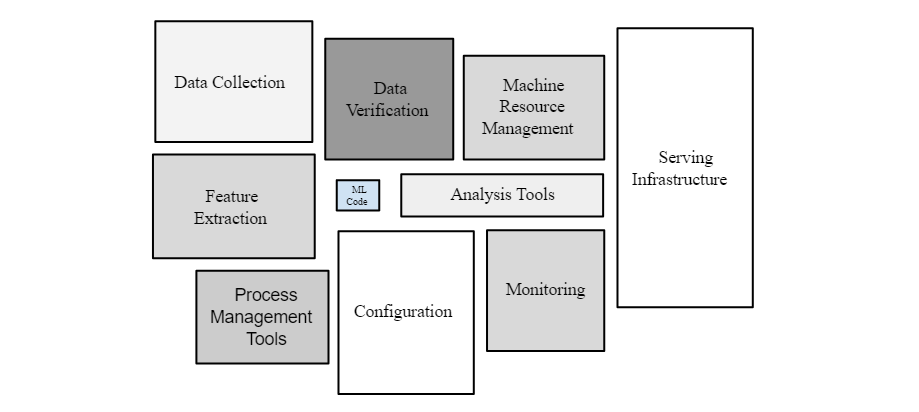
- https://developers.google.com/machine-learning/crash-course/production-ml-systems
- https://medium.com/@CodementorIO/good-developers-vs-bad-developers-fe9d2d6b582b
- https://towardsdatascience.com/the-pytorch-training-loop-3c645c56665a
- https://neptune.ai/blog/best-ml-experiment-tracking-tools
- https://github.com/Erlemar/pytorch_tempest
Contacts
Writing training pipelines for deep learning
By Andrey Lukyanenko



