Introduction to Task-Oriented Dialog Systems
What are Task-Oriented Dialog Systems?
Types of Task-Oriented Dialog Systems
- Pipeline-based
- End-to-end
- Joint systems
Characteristics of TOD systems
1. Domain, intent
2. Slot-value pairs
3. Data usually sourced via crowd-sourcing
4. Manual annotation a necessity
5. Retrieval-based and generative models
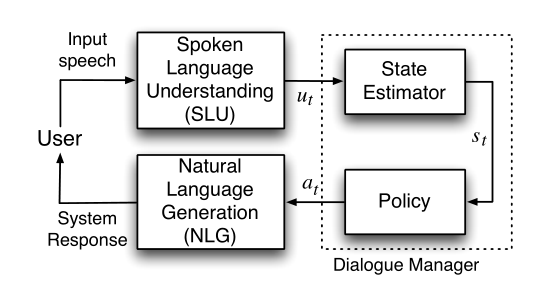
Pipeline-based systems
1. Usually consist of four components: NLU/ASR, DST, Policy, NLG
2. Traditional TOD systems were pipeline-based; recent move is towards end-to-end
End-to-end systems
Joint models
Evaluation of TOD systems
1. Metrics from other problems like machine translation commonly used
2. Component-wise vs full evaluation
3. Multiple responses?
4. Automatic vs human evaluation
Research areas
1. Zero-shot/few-shot learning
2. Transformers/pre-trained language models
3. Multi-response dialog systems
4. Multilinguility
5. Evaluation metrics
6. Dataset development
Ethical considerations
1. Data sourcing
2. Inherent bias
3. Privacy
4. Safety
Introduction to Task-Oriented Dialog Systems
By Anjali Bhavan




