Reproducibility
using open data and open source
Ann Gledson, Research Software Engineer
The University of Manchester
https://slides.com/anngledson/data-software-sustainability
Overview
- Open Science
- Open data, open source and open methodology
- Environment data-set example
Open Science
- Open Data
- Open Source
- Open Methodology
- Open Peer Review
- Open Access
- Open Educational Resources
For overview: see NERC 'Constructing a Digital Environment' channel: Open Science webinar by Helen Glaves (British Geological Survey)
The nature of research




- Research projects have short lifespans
- Long-term ideas and goals
- Non-continuous process
- Funding
- Loss of key developers / analysts
- Changes in scope or delays
- Changes in storage devices
- Difficult to plan resources
- Data storage
- Code re-use
Open Data
- Reduce repetition of data cleaning and wrangling tasks
- Focus more on key research questions
- Reproducibility -> Trust!
- Visibility:
- E.g. Nature Scientific Data journal
- Citations
- Collaboration, communities and networking
- Funding opportunities
Data wrangling

FAIR data principles
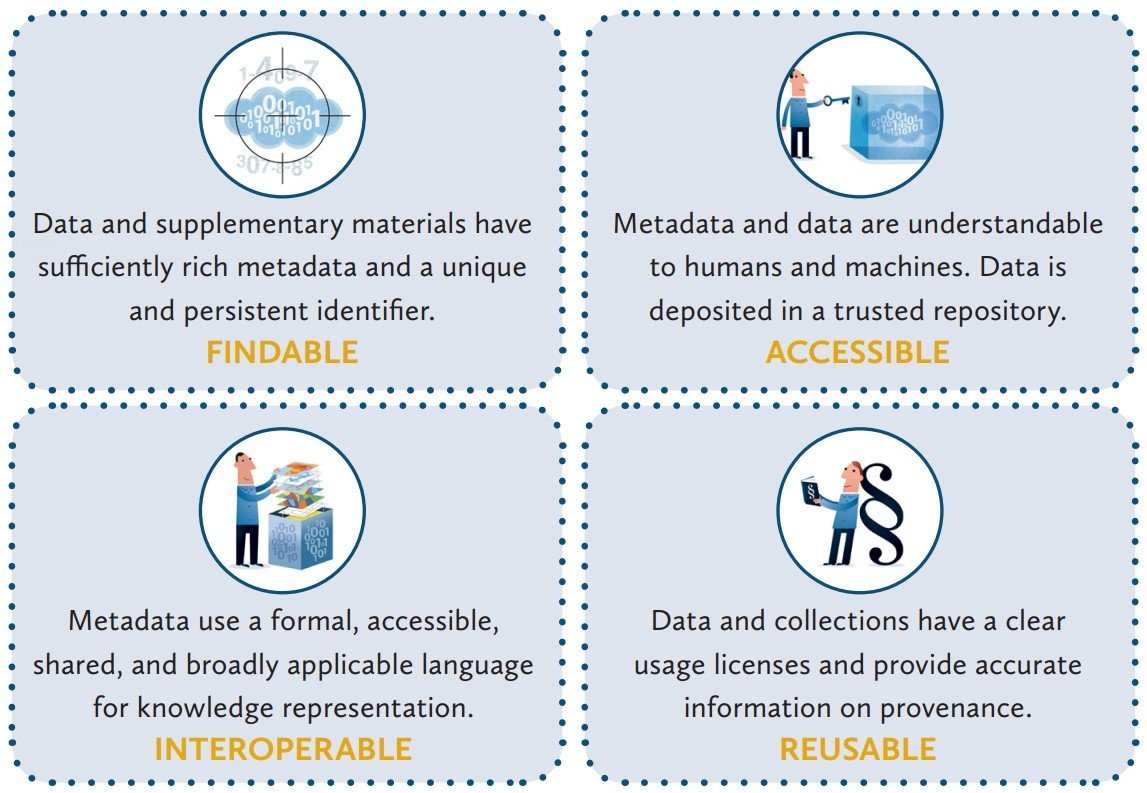
Nature Scientific Data: principles
Credit: Scientists who share their data in a FAIR manner deserve appropriate credit.
Re-use: Standardized and detailed descriptions make data easier to find and reuse.
Quality: Critical evaluation is needed to verify experimental rigour.
Discovery: Scientists should be able to easily find datasets that are relevant.
Open: Scientists work best when they can easily connect and collaborate.
Service: Committed to providing excellent service to both authors and readers.
(Full version: https://www.nature.com/sdata/about/principles)
Open Source
- Reduce repetition of coding effort
- Community of developers
- Testing
- Issue tracking
- Pull requests
- Reproducibility
- Github releases: Snapshots of code
- Visibility:
- Software Citation in Github
- Findability
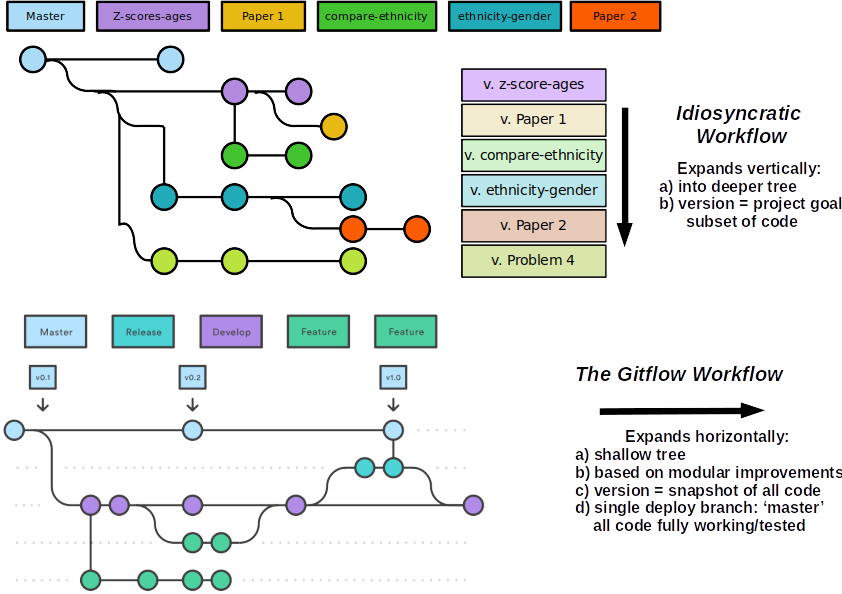
- Master branch is public release code – each version on master is tagged with a semantic version number (https://semver.org/). Code in master works.
- Release branch (if present) is temporary. Preparation for version release. (Or use develop)
- Commits on develop are stable and should work but some unanticipated unexpected behaviour may be present.
- Feature branches are temporary*. Commits on these may be broken/unstable.
Gitflow branch types
Gitflow release process
- Tests run on develop branch – before making a release, make sure that all tests are passing (can be run as a CI job).
- (optional) Create an issue that describes what changes have been made since last release version. Make sure everyone agrees that behaviour is as expected. Link to passing tests.
- Merge develop into master and tag with the version number.
Open Methodology
- Data analysis apps
- R-Shiney Apps
- Jupyter Notebook
- Streamlit
- Plotly Dash
- Bokeh
- Computational Workflows
- FAIR workflows
- Carole Goble UoM work (see links)
Example
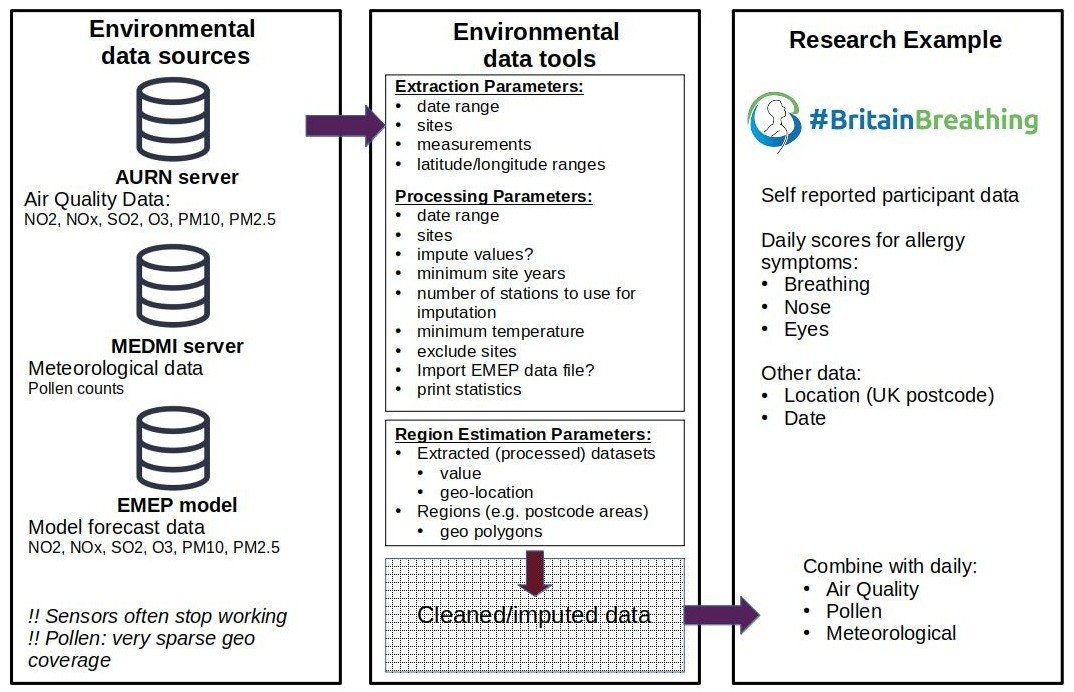
Environment data
-
Automatic Urban and Rural Network (AURN)
- NOx, SO2, O3, NO2, PM10, PM2.5
-
Medical and Environmental Data (Mash-up) Infrastructure (MEDMI)
- Meteorological: temp, pressure, dewpoint temp, relative humidity
- Pollens: alnus, ambrosia, artemesia, ..., urtica
-
European Monitoring and Evaluation Programme (EMEP)
- Model forecast data
- NOx, NO2, SO2, O3, PM10, PM2.5
-
Complex extraction process:
- Multiple data sources
- Missing data (e.g. sensor down-time)
- Variable UK area coverage
Cleaning and Imputation
- Remove duplicate/unphysical values
- Select sites by minimum temporal data coverage
- scikit-learn (python) used to impute missing data using hourly time series
-
Imputation method
- Bayesian Ridge
- Quantile Transformer preprocessing
- Final data: daily mean / maximum values (or simple daily count)

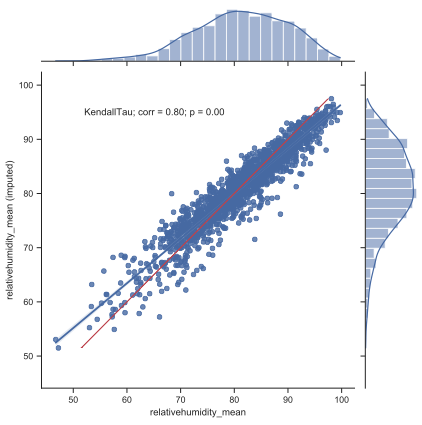
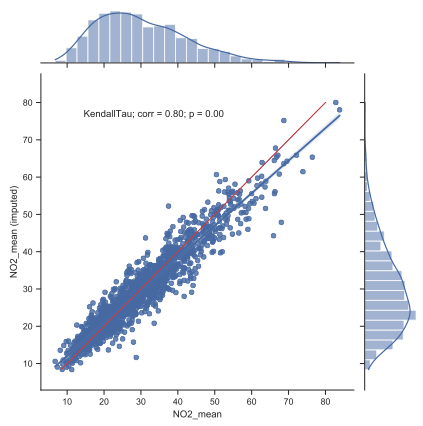
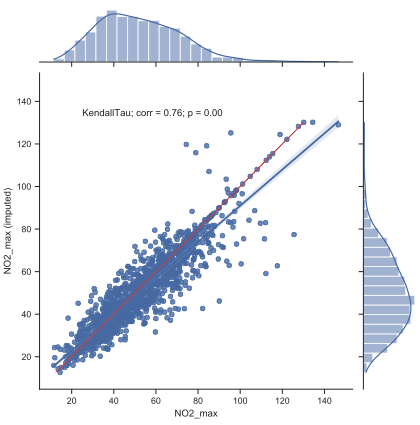
Regional estimations
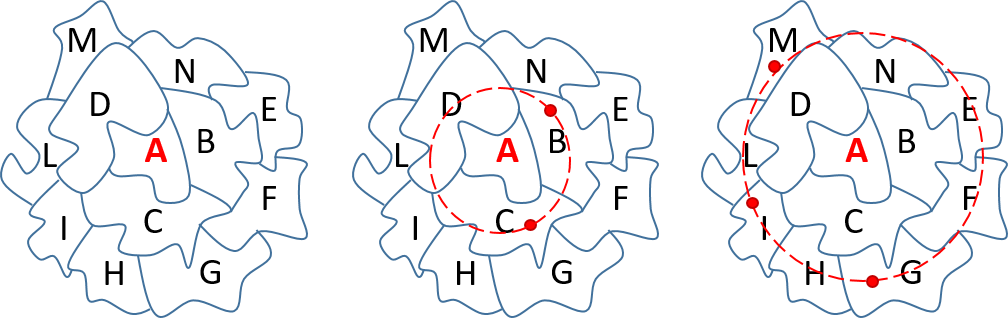
Diffusion method illustrated on fictional postcode regions
- Regions where sensors exist: take mean
- Regions with no sensors: take mean of surrounding regions
- Working outwards until sensors found
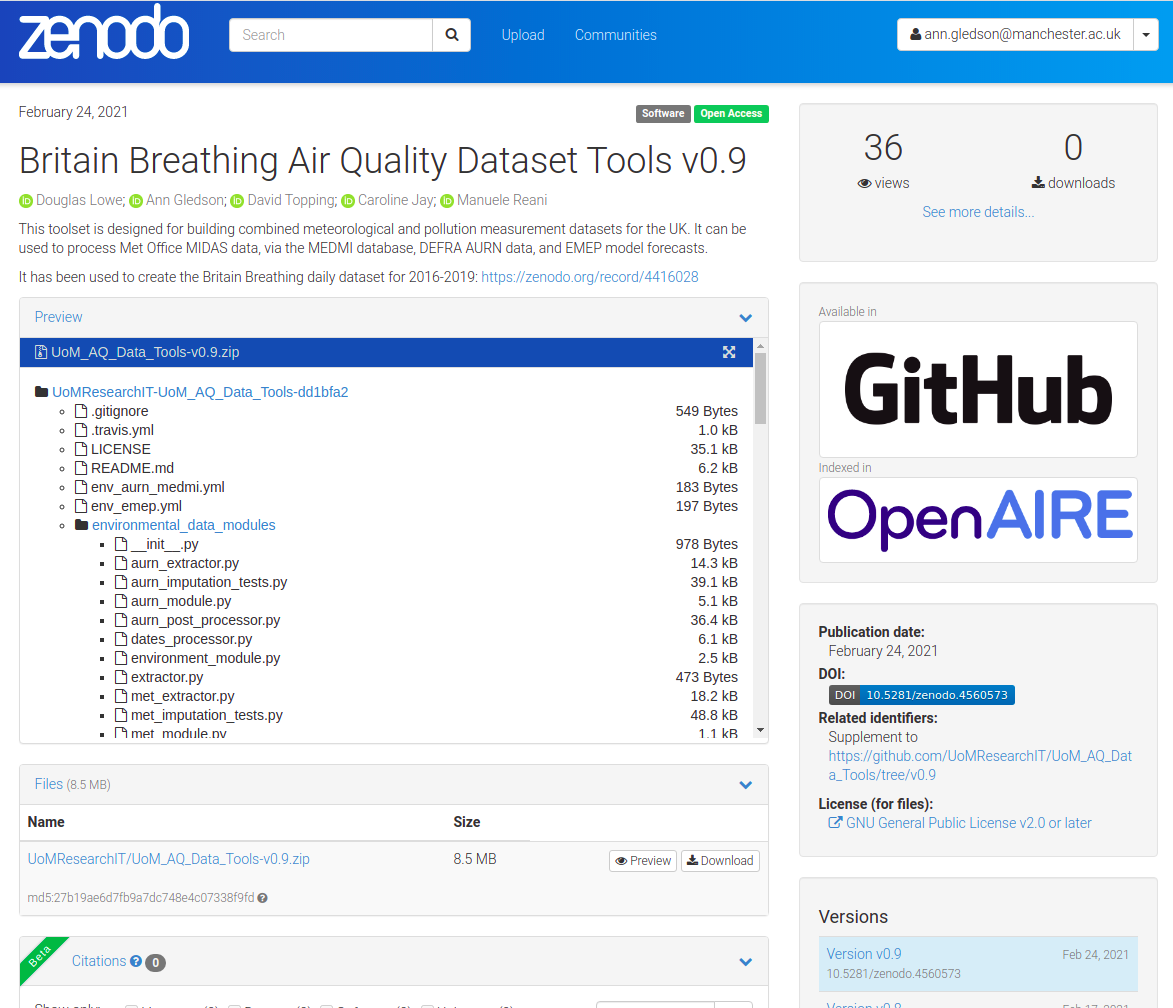
Linking GitHub version to DOI

Shared Data
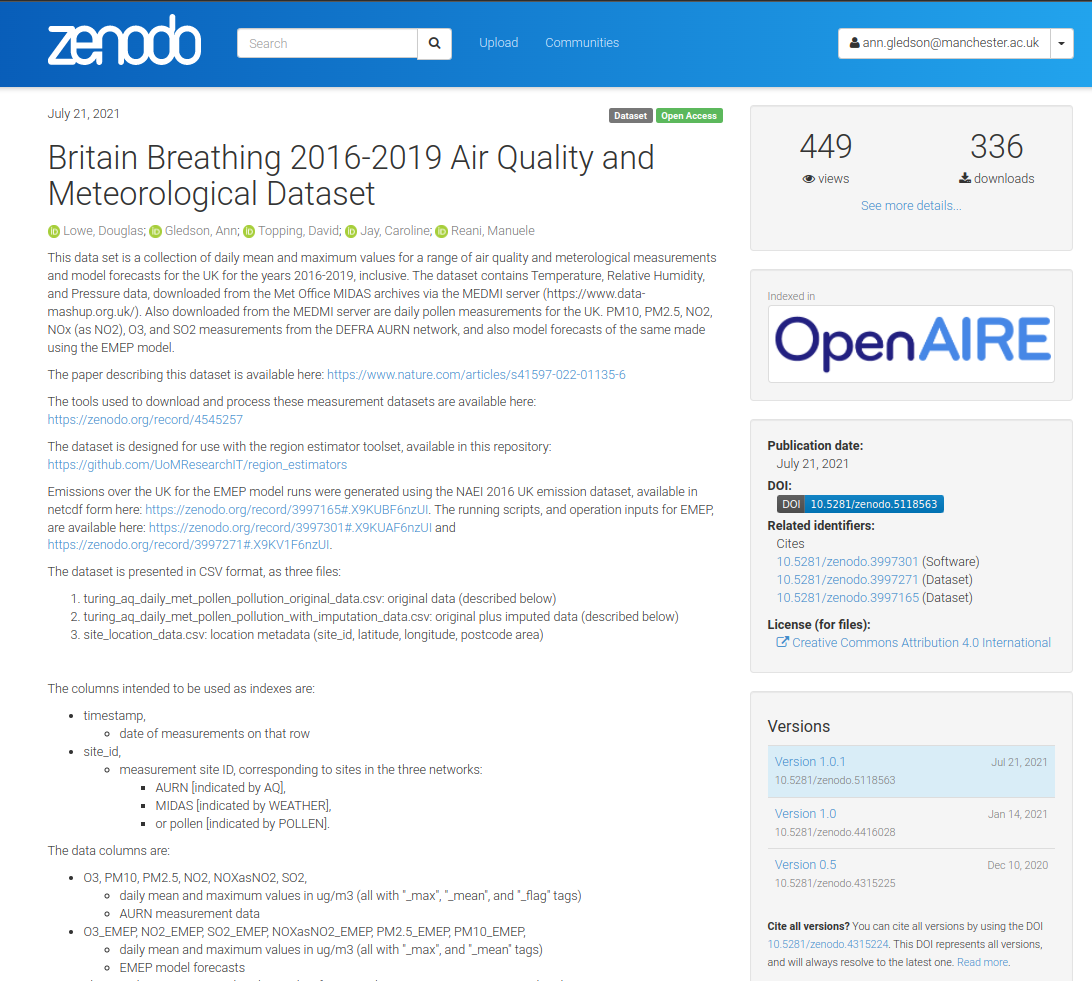
Links
-
FAIR Data: https://www.go-fair.org/fair-principles/
-
Git/GitHub Tutorial: http://gcapes.github.io/git-course/
-
Gitflow Workflow: https://www.atlassian.com/git/tutorials/comparing-workflows/gitflow-workflow
-
Semantic version numbers: https://semver.org/
-
Zenodo (DOIs) https://zenodo.org/
-
Linking GitHub to DOI: https://guides.github.com/activities/citable-code/
-
Open data webinar - Helen Glaves (BGS):
-
https://www.youtube.com/channel/UCv8vRIuTxCP-DgNMCq9KxqA/videos
-
-
Computational Workflows
-
www.slideshare.net/carolegoble/fair-computational-workflows-249721518
-
Environment Dataset Links
- 2016-2019 environment datasets:
- measurements (original and imputed)
- https://zenodo.org/record/4416028
- includes link to extraction and imputation tool set
- regional estimations (from original and imputed)
- https://zenodo.org/record/4475652
- includes link to region_estimators tool
- Scientific Data paper:
- https://www.nature.com/articles/s41597-022-01135-6
- measurements (original and imputed)
- Visualisation Tool:
- http://minethegaps.manchester.ac.uk/
- https://github.com/UoMResearchIT/mine-the-gaps
Data and Software Sustainability
By Ann Gledson




