Benjamin Roth
@apneadiving
🇫🇷
Case Study
how we made our core process
100 times faster
(at least)
💫 ⭐️ 🌟 ✨ ⚡️
What are we talking about?
Input
-
advertising related data in database
Output
-
data pushed to adwords
-
ids of adwords entities saved in database
-
errors saved in database
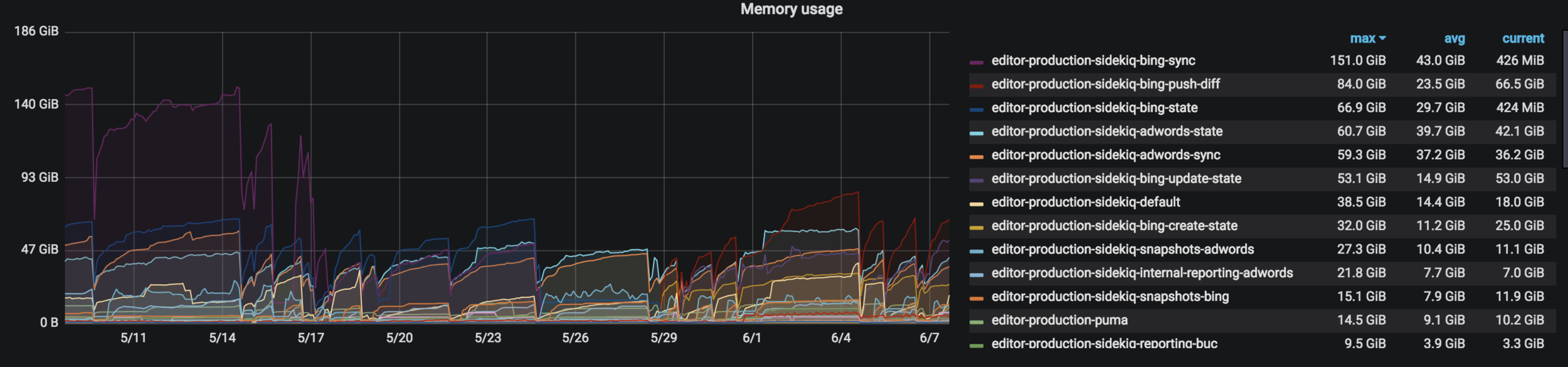
| Before | After | |
|---|---|---|
| RAM Used | 180 GB | 10 GB |
| RAM per thread | 3 GB | 500Mo |
| Average time | 10 minutes | 10 seconds |
| Synchronisation tracking | no info available | all timestamps in database |
And YES, we kept Ruby ❤️
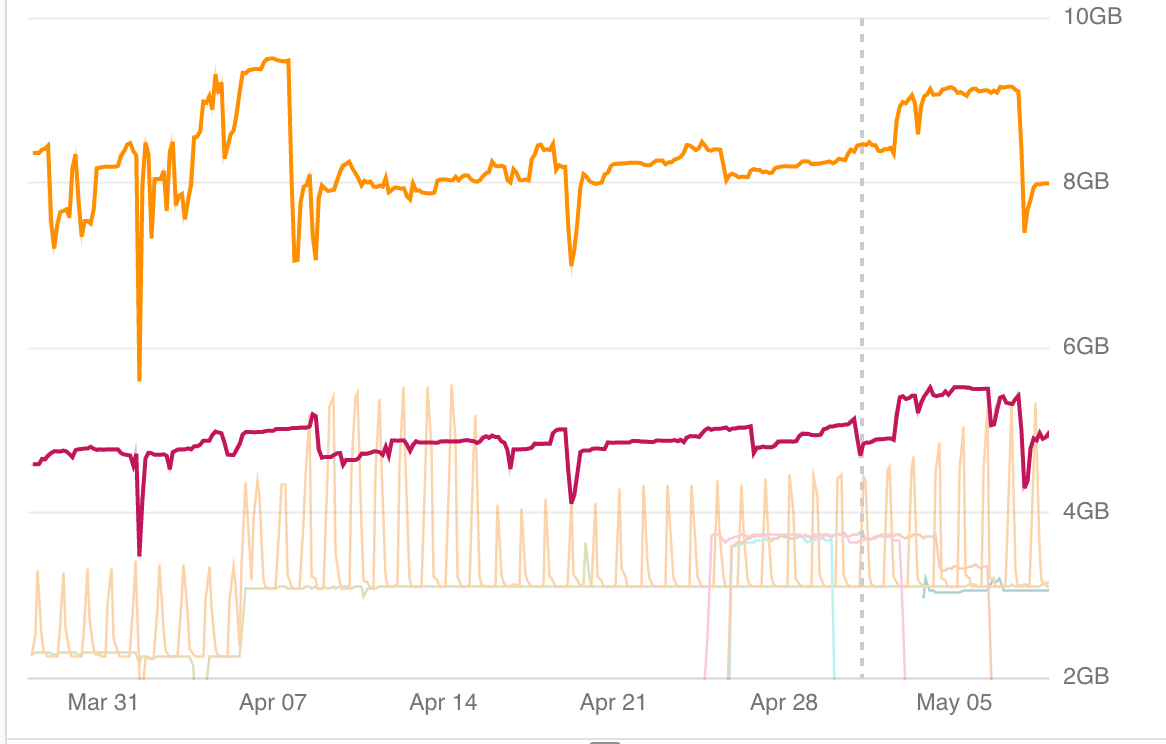
first refactoring
Before
After
Optimization 1
Dealing with small chunks
The STATE
The advertising data was bundled in some huge object known as the state.
Every single problems was supposed to come from it

The State?
Account
Campaigns (~100)
Ad Groups (~25k)
Ads (~100k)
Keywords (~100k)
(around 700Mo of JSON)
So what about the state?
- lots of database queries to generate the full object
- huge object to keep in memory
-
on update, the previous state was loaded from database as well to make a diff: 2 huge objects to keep in memory
🏋️♂️
Feedback 1
Account
Campaigns (~100)
Ad Groups (~25k)
Ads (~100k)
Keywords (~100k)
- No need to build the entire tree
- Deal with data layer by layer
Optimization 2
A decent datamodel
State Storage
The whole state object was saved in database, in some byte column:
compressed JSON.
🗜
🦛
Feedback 2
SQL is pretty well designed for storing data.
Do not store blobs. 🙄
We use a table per kind of entity:
campaigns, ads, keywords...
Optimization 3
Only store what you need
Keyword Example
First, we sync
Later we have to sync
{
"reference_id": "124",
"text": "Eat my short",
"match_type": "EXACT"
}{
"reference_id": "124",
"text": "Eat my belt",
"match_type": "EXACT"
}No diff
nothing to push on API
Even later we have to sync
{
"reference_id": "124",
"text": "Eat my short",
"match_type": "EXACT"
}there is a diff
something to push on API
Keyword Example
{
"reference_id": "124",
"text": "Eat my short",
"match_type": "EXACT"
}{
"reference_id": "124",
"text": "Eat my belt",
"match_type": "EXACT"
}Does this mean we have to store all properties of each object in database?
🙅♂️
MD5
Some String
MD5
Some other String
Feedback 3
Store the minimum relevant data you need
🐣
Optimization 4
Synchronisation tracking
Synchronisation?
triggering a synchronisation is telling the app to push data of a product to adwords
Was a matter of enqueuing some worker
CreateStateWorker.perform_async(product_id)Enqueuing blindly
- What if you want to ensure the same product is not enqueued twice?
- What if you want to prioritize some products over some others?
- What if you want to know if/when some product's sync was triggered?
- What if you want to know how long it took? on average?
😖
CreateStateWorker.perform_async(product_id)Sidekiqing sideways
CreateStateWorker.perform_async(product_id)Synchronisation.create!(
status: 'pending',
product_id: product_id
)⚙️
and have a cron handle pushing jobs to queues
Feedback 4
Whenever you are talking a lot about some concept (Synchronisation in our case),
It could be that there is an object crying for you to create it.

Optimization 5
Sidekiq workers
👷♂️
Workers
Full sync process was a cascade of workers
CreateStateWorker.perform_async(synchronisation_id)CreateDiffWorker.perform_async(synchronisation_id)At the end of the worker,
it triggered the next step
PushDiffWorker.perform_async(synchronisation_id)Which in turn triggered
(there were actually a few more steps)
Hardware concerns
- assign = queues to sync workers: more hardware required / 💸 to have machines idly waiting
- assign the same queue to all sync workers: less hardware required. Flaws all synchronisation stats:
Queue
Processing
Sync2 - step 1
T0
T1
T2
Time
Sync1 - step 2
Sync2 - step 2
Sync1 - step 1
Sync2 - step 1
Sync2 - step 2
Feedback 5
Hardware matters, idle hardware is a waste of money.
We did regroup under one queue (then only one worker).
Still doesnt help having a synchro exiting the pipeline as fast as possible.
🤔
Optimization 6
Optimizing the pipeline
Queue for SynchronisationWorker has:
2 processes, 2 threads - 4 jobs can run in //
Say you push 10 jobs:
- 4 would be handled right away
- 6 would end up waiting for free room
Queues
- Enqueuing 4 jobs max is ok. More is irrelevant.
- Enqueing 0 is the way to go if all the slots are still filled.
we had a cron pushing jobs, it was instructed to push as many as:
Queues
MAX_CONCURRENT_PROCESSES - Synchronisation.in_progress.countFeedback 6
Enqueuing the right amount of jobs:
- lets Sidekiq focus on its worker handling responsibilities.
- allows you to prioritize the remaining jobs to go each time the cron is executed
🤸♀️
| Problem 🚱 | Solution ✅ |
|---|---|
| ensure the same product is not enqueued twice | DB constraint on Synchronisation Status |
| ensure synchronisation is dealt with as fast as possible once enqueued | cron controls what is in the queue. |
| prioritize some products? | Scope in the cron which is responsible for pushing jobs to queue |
| synchronisation stats? | carried by each Synchronisation object in database |
| Hardware usage optimization? | One only queue we can adjust depending on the load |
| Problem 🚱 | Solution ✅ |
|---|---|
| Memory issues | No more blob MD5 comparison only |
| Speed concerns | Workers setup |
Prequels
Various rushed and vain attempts of improvement
aka
the pointless
micro-optimization
☠️ 🧟♂️
Strange love for bang methods
- map!
- merge!
- strip!
- ...
It could be useful, but let's face it, it's not a priority.
Chill...
🥶
So called FP style
Hatred of objects
Obsession for functions on hashes instead
🧘♂️
Entity.full_name(
first_name: 'Mo',
last_name: 'Fo'
)Callbacks
nasty by nature
waiting to bite you in the back...
🦖
Desperate moves
☯️
GC.startStop the Madness
obsession of micro optimization
=
Shitty code
+
no real time to fix it
STEP BACKWARDS to see
the in the room
🐘
That’s all!
🙃🙏🙇♂️
case-study
By Benjamin Roth




