Self-Healing Systems

Ashish Pandey
@ashishapy
blog.ashishapy.com

Meet-up on 18th Sep 2016
@ Thoughtworks Pune
In the modern era, software is commonly delivered as a service: called web apps, or software-as-a-service. The twelve-factor app is a methodology for building software-as-a-service apps that:
- Use declarative formats for setup automation, to minimize time and cost for new developers joining the project;
- Have a clean contract with the underlying operating system, offering maximum portability between execution environments;
- Are suitable for deployment on modern cloud platforms, obviating the need for servers and systems administration;
- Minimize divergence between development and production, enabling continuous deployment for maximum agility;
- And can scale up without significant changes to tooling, architecture, or development practices.
The Twelve Factors
One codebase tracked in revision control, many deploys
Explicitly declare and isolate dependencies
Store config in the environment
Treat backing services as attached resources
Strictly separate build and run stages
Execute the app as one or more stateless processes
Export services via port binding
Scale out via the process model
Maximize robustness with fast startup and graceful shutdown
Keep development, staging, and production as similar as possible
Treat logs as event streams
Run admin/management tasks as one-off processes
The Twelve Factors

-
Introduction of Self-Healing Systems -
Introduction of Docker & Microservices -
Demo:-
Create Infrastructure -
Create Services -
Demonstrate Self-Healing -
Effortless Scaling -
Effortless Rolling Update
-
-
Questions
Let's face it!

The systems
We are creating, are


Perfect
Not
Sooner or Later
One of our application will fail.
One of our application will not be able to handle the increased load.
One of our commits will introduce fatal bug.
A piece of hardware will fail.
Something entirely unexpected will happen.
What we should do?
Nothing is perfect, can’t design a perfect system.
Embrace the inevitable, design system which is able to recover from failures.
System should be able to predict likely future.
Design for failure.
Hope for the best, but be prepare for the worst.

Self-Healing Systems

Discover, what is not working correctly
without any human intervention, make the necessary changes to restore itself to the normal or designed state
Three Levels of Self-Healing Systems
Application Level
System Level
Hardware Level



Exception & logging
Developer to take care
failures of processes & response time
Restart/redeploy && scale/descale services
No such a thing as hardware self-healing
Redeployment on healthy one && Preventive healing

Okey!
Do self-Healing systems can be applied to Microservies only?

humm...
Self-Healing systems can be applied to any architecture








Packaging
Server
Virtual Machines
VM Images
Image Layers
Container







. . . 3 2 1
Quick Demo


$ docker run -d -p 8000:8080 <image-name>
<image-name> = tomcat:7/8/9
$ docker exec -it <container_name/id> bash

Microservices

Services are small - fine-grained to perform a single function.
Services are easy to replace and deploy independently
One service fails, then the whole application does not have to fail
Services can be implemented using different programming languages, databases, hardware and software environment, depending on what fits best
Service
One service managed by two pizza team
Comes with complexity and new challenges
Principles of Microservices
Microservices
Modeled around business concept
Small autonomous services
Culture of automation
Highly Observable
Isolate failure
Deploy independently
Decentralize all the things
Hide internal implementation details



Showtime
Logistics


Infrastructure
Service/Application
*Not actual representation of demo
Amazon Web Services
Docker Images
*Node: A physical or virtual-machine that hosts services
*Service: Executing a software that provide utility via a interface
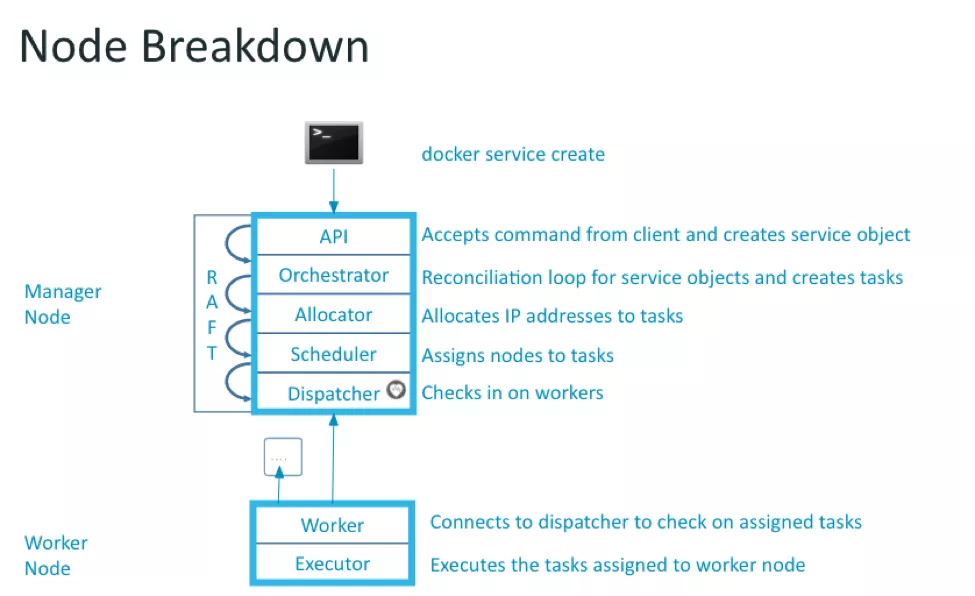
- SSH to Manager:
$ ssh -i <AWS_Pvt_Key> <ManagerSSHLoadBalancer>
- Check all nodes/VMs. Identify Manager & Worker nodes/VMs
$ docker node ls
- Login to docker registry/hub
$ docker login
- Create new service and validate
$ docker service create -p 80:4000 --with-registry-auth --name blogapy ashishapy/blog
$ docker service ls
$ docker service ps blogapy
- Open browser and enter external load balancer in URL. Check application is running.Remember: Three Levels of Self-Healing
Application Level
System Level
Hardware Level
Exception & logging
Developer to take care
failures of processes & response time
Restart/redeploy && scale/descale services
No such a thing as hardware self-healing
Redeployment on healthy one && Preventive healing
- Two aim with one shot :)
-> Terminate VM which has service running.
$ docker node ls
- Check service is rescheduled to healthy node
$ docker service ls
$ docker service ps blogapy
- After some time, when another VM is up and joined the cluster
$ docker node ls
- Scale up the service
$ docker service scale blogapy=12
$ docker service ls
$ docker service ps blogapy -f "desired-state=Running"
- Rolling updates
$ docker service update --update-delay=10s --update-parallelism=3 \
--image ashishapy/blog:v2 blogapy
$ docker service ps blogapyApplication Cluster (Docker 1.12.x)

Docker Swarm Mode (Docker 1.12.x)
Infrastructure

AWS Services:
-
EC2 Instances + Autoscaling Group -
IAM Profiles -
DynamoDB Tables -
SQS Queue -
VPC + Subnets -
ELB
*Simplified Diagram



Self-Healing Systems
By Ashish Pandey
Self-Healing Systems
Self-Healing Systems using Docker 1.12 in Swarm mode




