Curriculum Learning with Dynamic Instance Hardness (DIH)
Paper by
Tianyi Zhou*, Shengjie Wang*, Jeff A. Bilmes
Neurips 2020 paper
Intuition
-
A curriculum plays an important role in human learning.
-
Given different curricula of the same training materials, students’ learning efficiency and performance can vary drastically.
-
A good teacher is able to choose the contents of the next stage of learning according to a student’s past performance.
Analogously, in machine learning,
-
Instead of training the model with a random sequence of data,
-
recent work in curriculum learning (CL) shows that manipulating the sequence of training data can improve both training efficiency and model accuracy.
-
- In each epoch, CL selects a subset of training samples based on the difficulty and/or the informativeness of each sample — this is usually measured using instantaneous feedback from the model (e.g., the loss).
CL then uses only these samples to update the model.
Inspired by human learning curricula,
- a schedule of training samples is constructed (e.g., usually from easy to hard), sometimes combining with other criteria (e.g., diversity).
As exhibited in previous work, CL can help to avoid local minima, improve the training efficiency, and can lead to better generalization performance.
Sample selection criteria
r_{t+1}(i) = \left\{
\begin{array}{ c l }
\gamma a_t(i) + (1 - \gamma) r_t(i) & \quad \textrm{if } i \in S_t \\
r_t(i) & \quad \textrm{otherwise}
\end{array}
\right.
Instantaneous hardness
Sample index
Sample subset for time \(t\)
Time
DIH
Discount factor \(\gamma \in [0, 1]\)
(1) Loss
(2) dLoss (change in loss)
(3) Prediction flip
|l(y_i, h_{w_t}(x_i)) - l(y_i, h_{w_{t-1}}(x_i))|
|\mathbf{1}[\hat{y}_i^{(t)} = y_i] - \mathbf{1}[\hat{y}_i^{(t-1)} = y_i]|
l(y_i, h_{w_t}(x_i))
DIH vs Instantaneous hardness
DIH is more smooth/consistent over training epochs than instantaneous hardness.
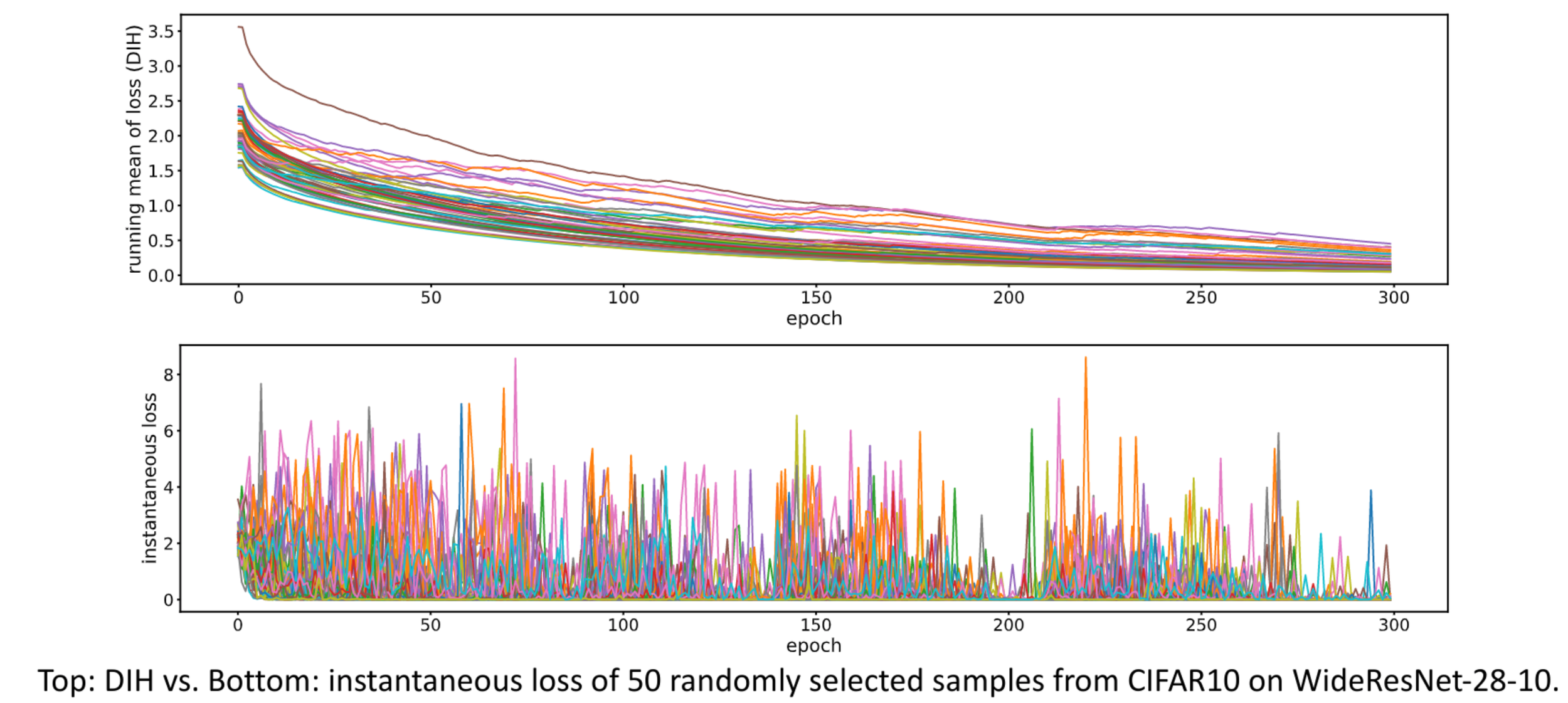
DIH identifies forgettable and memorable samples
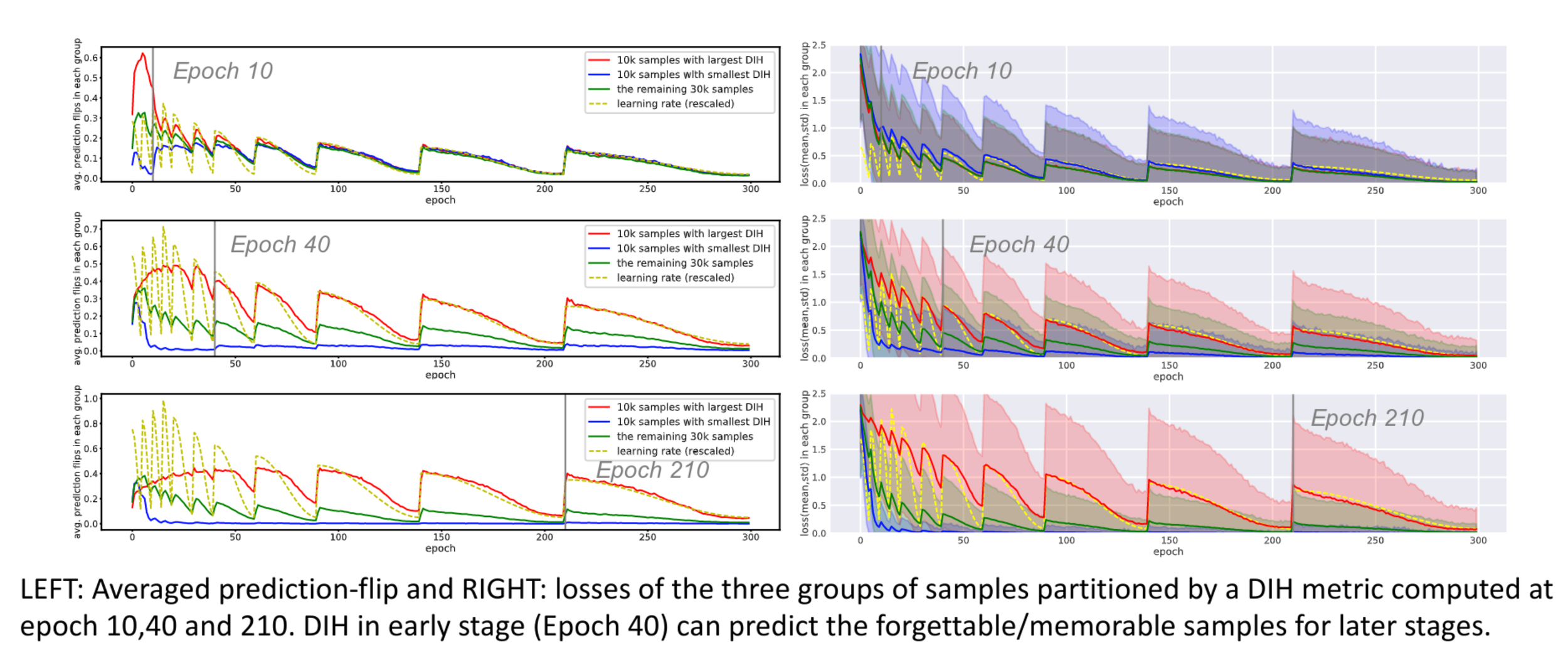
Training set up: WideResNet-28-10 on CIFAR-10 with random mini-batch SGD with cosine annealing learning rate schedule

Curriculum Learning with DIH
Prefers harder samples to train model in each step.
Since the model is trained on a subset of samples and DIH is updated only for selected samples, computation to achieve given accuracy is reduced.
Curriculum Learning with DIH
1. Training data \(\{(x_i, y_i)\}_{i=1}^{n}\)
2. Optimization method: \(\pi(.; \eta)\)
3. Loss: \(l(.,.)\)
4. Model: \(F(., ; w)\)
5. \(\eta_{1:T}\): Learning rate schedule for \(T\) iterations
6. \(T_0\): # epochs for warm starts
7. \(\gamma_k\) is a subset size reduction rate
Curriculum Learning with DIH
\(S_t\) has samples with top \(k_t\) DIH values
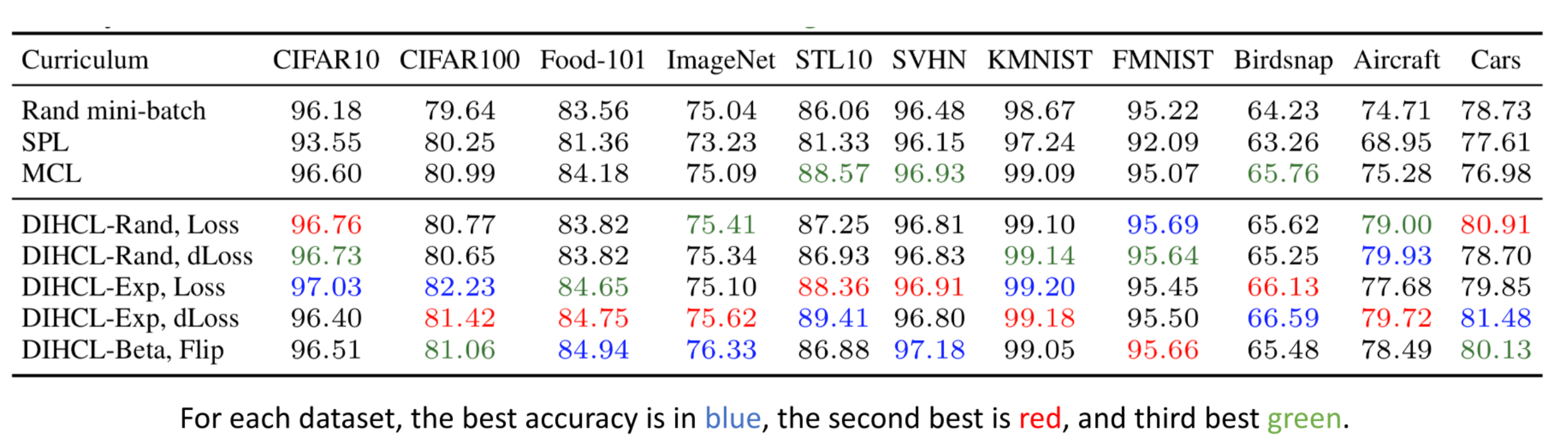
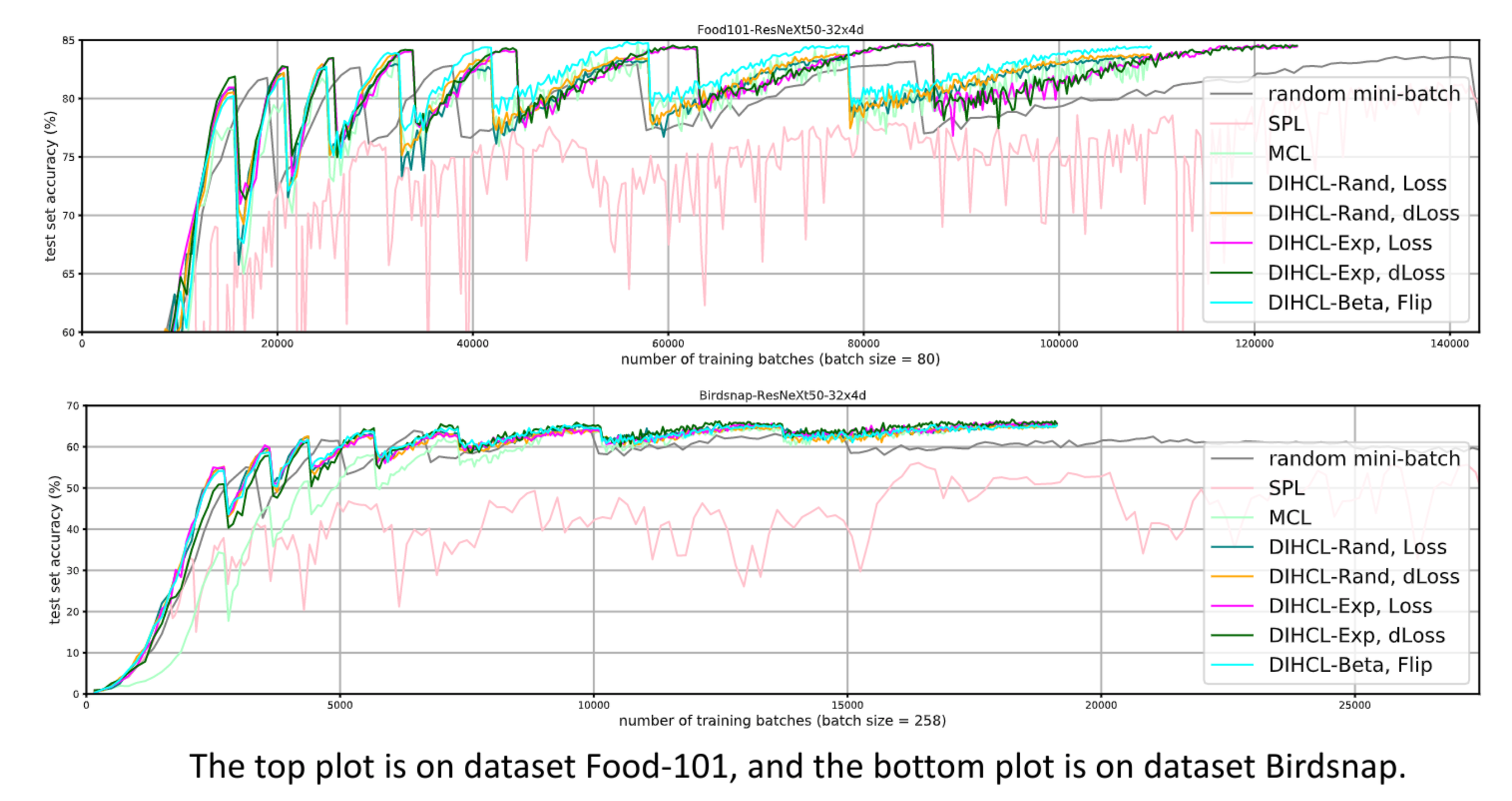
Experimental results
DIHCL outperforms baseline curriculum learning methods on multiple baselines.
-
Self-paced learning (SPL) selects samples with smaller loss, and gradually increases the subset size over time to cover all the training data.
-
Minimax CL (MCL) argues that the diversity of samples is more critical in early learning since it encourages exploration, while completeness becomes more useful later.
DIHCL reaches the best performance faster than other methods.
Dynamic Instance Hardness
By ashishtendulkar



